领域适应在视频理解中的应用(行为识别与定位)
来源:Video Intelligence - 知乎专栏
对这个方向一直很感兴趣,而且这方面工作还很少,所以最近打算对视频分析中的弱监督方法做一个总结。所以前面通过讲述两篇论文,对零样本学习用于视频行为识别和视频行为定位,领域适应帮助细粒度分类的问题做了一些深入的探讨。我自己也在做相关实验,并验证一些idea,然而。。。
今天在扫arxiv时,无意间看到Li Fei-Fei组放出了他们新的工作 Graph Distillation for Action Detection with Privileged Information(链接:https://arxiv.org/pdf/1712.00108.pdf),他们已经有了一些尝试了orz,太快。。于是读了一下,这篇report记录一下一些阅读细节,同时会有一些自己的思考。(以下内容都是出于我自己的思考,如果对作者的意思产生误解,还望轻拍)
内容
在图像识别,目标检测等问题上CNN取得了很大的成功,但具有同等contribution的还有大规模的带标注数据集(large scale labeled dataset)。视频角度上,一些尚无足够好表现的topic,比如MOT(Multi-Object Tracking),IS( Video-level instance-level segmentation),TAL(Temporal Action Localization) 都存在的问题就是dataset量少且存在分布偏差(不能涵盖所有的“特殊”情况),人们在收集,标注干净,海量,且与任务相关的数据上面的消耗非常大。前不久参加了林元庆在北大的报告会,里面就提到了他在百度时的一些3D slam和video instance segmentation的数据标注工作,总之是非常麻烦(time-consuming)的。
视频分析常需要multi-modality的融合,才能得到很好的结果。比如常见有如下modality:
RGB images
depth
optical flow
skeleton feature
audio spectrum
很多任务里的训练数据集很有限,通过其他数据源提供的信息还能带来非常大的提升。比如UCF101, HMDB51。有相当多的经典工作在尝试提高这两个数据集的performace,但是一直到现在我们几乎可以看到如果不使用其他数据源的信息,UCF101 3splits mean top1 accuracy 达到了0.940~0.950之间后,几乎无法再提高(PS: 在这些工作里面,我个人觉得TSN是最优美的,方法简单模型不复杂,效果也好,且其他方法可以借TSN ensemble)。再有模型上的升级或者multi-modality的融合,都几乎跨不过0.95的坎。而使这一个瓶颈真正突破的是 Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset(论文链接:http://openaccess.thecvf.com/content_cvpr_2017/papers/Carreira_Quo_Vadis_Action_CVPR_2017_paper.pdf) , UCF101在经过kinetics pretrain之后,可以让精度提高到0.98。HMDB可以提高到0.80。
以上可以见到domain transfer的重要作用。
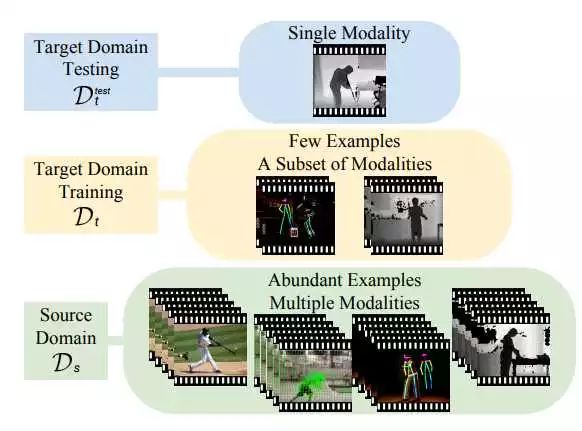
source domain指,我们构建的丰富modality的已经获得的知识(prior knowledge),简单理解成各种train好的model吧:)
target domain的训练数据集是该数据集自己能训练的modality(用于finetune)。target的测试,甚至只有面对一个(或极少数量的)modality。从这个图能直观的看出作者的思路:测试集的数据能使用所有source data 里的modality。需要解决的问题有两个:怎么让source data中的信息被整合,怎么找到modality之间的关系,以使得训练集中modality缺失,但是却能被source data中的各个prior modality提高。
用source data, source modality 帮助target modality分类/定位,总的来说包含两个步骤:
a)怎么有效利用source modality
b)怎么迁移source modality到target
文中提出了解决办法:
a)图蒸馏(graph based distillation),这个表述看起来不太好理解。蒸馏(distill)技术平时用的还比较多,上周在元培班的深度学习课上就简单提过一下,工业界因为考虑到运算性能和硬件问题常常不能把训练的大模型直接用于真实场景,所以通过metric learning监督训练一个小模型。比如mimic network等。我简单提炼(distill)一下:就是把abundant multiple modalities提出有用部分。有些样本容易被光流分辨出来,有些样本更容易被skeleton分辨出来,通过训练已知的modality-specific prior和example-specific likelihood来找到一个自动从信息源获取complementary information。
b)这篇文章没有使用特别的领域适应算法,只用了最简单的transfer learning:直接把source 可用的modality放到target中一起训练,然后测试 target test samples。当然,在这里做创新也不是他文章的卖点。(和在ImageNet上pretrain,然后在自己数据集上finetune一个意思)
同时作者还对比了传统的transfer learning思路,缺陷是指定了distill的方向,和固定的modality,这样对视频任务并不合适,因为modality-category-data_scale等是非常敏感的。他提出的新方法(图蒸馏)则是自动学习distill的方向。下面深入介绍。
总的来说,图蒸馏包含两个步骤:先在source domain data上train,然后固定base model(visual encoder,即生成feature map/vec的网络)在target domain data上 finetune,很直观的过程。
第一步在source data上训练的时候,loss包含两部分。因为intuition是要在这上面train出visual encoder的效果以外,还需要它做到对modality的整合。
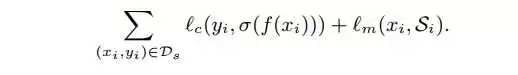
左边部分是对label训练的cross entropy loss,右边是imitation loss,是Hinton在nips15做的distill工作里的方法。这里作者做了一些改进,如下:
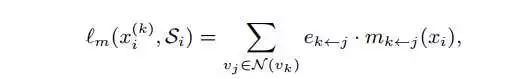
这里的图蒸馏是采用的有向图,v表示点(每个点是一个modality),e表示边。e_k<-j 表示由点j指向k的边,为一个[0,1]的notation,表示关系的强弱,在训练过程中是可被学习的。v_j为某一个指向k的modality,N(v_k)则表示所有指向k的modality的集合。所以对第i个样本而言,modality k的imitation loss为 所有指向该modality的其他modality对它的影响的求和。具体的影响为:
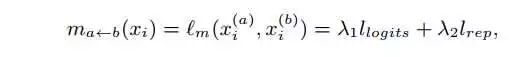
这个公式是graph edge里面的,后面也会提到。这里m_a<-b表示由b modality转移到a的message 量。
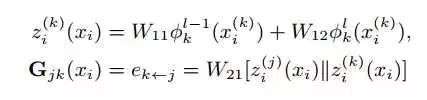
上面的公式表示x_i样本的第k个modality的feature representation,由第l层的输出和l-1层的输出联合表示。W11和W12可被学习。G_jk是一个邻接矩阵表示的matrix,W21右边表示第j个和第k个modality的feature representation,这是整个图被更新学习的过程。其中||表示两个向量的concat。
每次前向计算,能得到一个G∈|R ( |S|x|S| ),然后能得到message matrix M∈|R ( |S|x|S| ),imitation loss以两者点对点相乘得到:
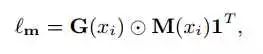
整个过程是E2E的,在如下的pipeline里面能看到。之后作者做了一个很有趣的尝试,intuition很简单,即每个modality的表现其实能通过交叉验证在source data上面计算出一个linear weight(比如TSN的modality RGB: optical flow表现最好的融合比例是1:1.5,是在三个split上面算出来的),所以作者把这一部分加了进去:
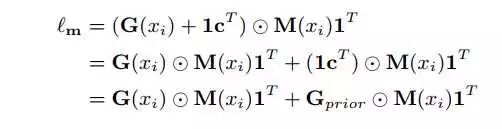
1_c.T即为这个prior信息。这样把图分解下来,就成了两部分:一个由example-specific 学习出来的图,一个是由modality-specific 得到的已知信息图(对specific example independent)。实验表明,加上了这一部分后训练效率更高,收敛的更快。结论我把作者一段话贴出来:Our model learns a graph based on the likelihood of observed examples to exploit complementary information in S. Meanwhile, it imposes a prior to encourage accurate modalities to provide more contribution. The graph is dynamically learned according to the posterior distribution。目的和intuition我前面已经表述过了。
第二部分是在target data上面finetune,因为target data也有一些modality,所以可以照搬上面的framework继续训练。测试时只使用在target train data中finetune过的modality来训练,注意,此时的modality已经包含了其他modality的信息(被增强)。
顺带提一下graph edge,即modality被限制成两个,上面的一些表达式比如|S|=2。
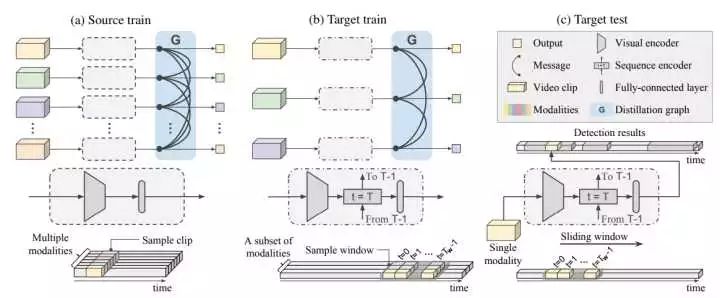
这是该工作的pipeline,右边的图例对于每部分细节说的比较清楚了。(a)是一个action classification的流程,source modality在进行训练的时候,每个modality都会采样video clip进行训练(encoding),各个modality在输出feature vector/ map之后便是通过Distillation graph来整合这些modality。(b)是一个action detection的流程,由于涉及到temporal的连续性,他的训练是输入的连续clip,所以在虚线框内能看到timeline。(c)基于sliding window做检测,同样是输入连续的clip,然后用(b)中训练的model来给一个分数。
实验设定细节非常多,想看细节还是建议读原文。实验效果当然意料之中的会比较好。
简单介绍下数据集:NTU RGB+D, PKU-MMD。前者包含56880个video,60个类别(每个视频只有一个label),提供了RGB,depth sequence, 3D joint positions和infrared frames。后者包含1076个长视频,51个类别。和前者包含同样的modality。这个数据集是我所另一个组发布的 @宋思捷。 实验设定前者NTU作为source data,后者为target data。肯定有同学和我一样期待THUMOS,Activity-Net等数据集的表现,然而他们的labeled modality太少,暂时能直接用的仅有RGB,OpticalFlow。这属于graph edge的情况,后面作者对UCF101也有实验,验证Graph edge。
因为C3D不太好train,为了控制模型大小,使得多个modality方便同时一起train,所以作者实验部分采用了ResNet18。
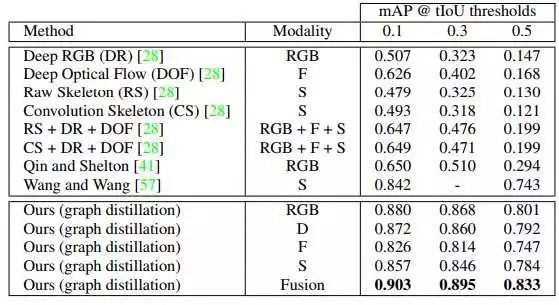
这是temporal action detection任务的表现,数据集是PKU-MMD。几乎所有source modality的引入都能带来提升。需要关注的是图蒸馏后的RGB高出 同样[41] 仅使用RGB一大截。所以modality融合后能提升6点。
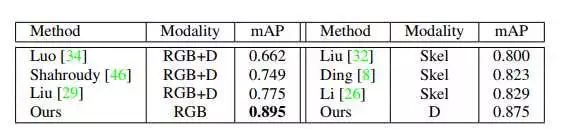
这是NTU RGB+D的测试结果,训练测试在一个数据集。训练使用多个modality,测试只使用一个modality,RGB的提升非常大。。
后面有一张对图蒸馏技术的可视化,反映了两个动作falling和brushing teesh,其他modality对于depth modality的信息转移(增强)。
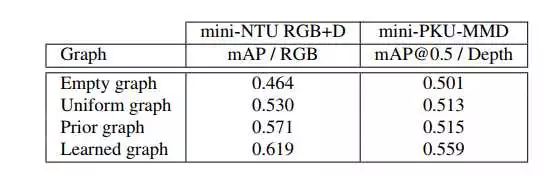
以及对于图蒸馏的训练是否在学习modality之间关系的ablation study
然后是graph edge在ucf101上面的情况。
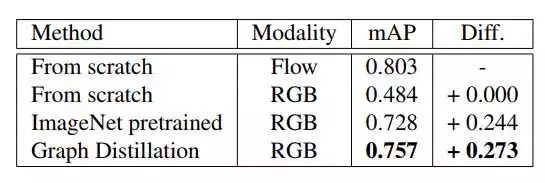
不清楚作者有没有使用data augmentation,效果没有理想中好,不过也有提升。
总结
Li Fei-Fei组在视频分析方向一直起着开拓者的作用,从large-scale video classification with convolutional neural networks,到end-to-end learning of action detection from frame glimpses in videos,然后到后来一些video dense captioning的工作,又到看到这篇。我认为视频领域的弱监督/无监督学习才刚刚开始。会有很多新的方法延伸到视频分析领域,以解决其目前存在的各种问题。
领域适应是一个很重要的棋子,虽然我想到这里没多久就被大佬做好并发了文章orz,不过欣慰的是,这是一声号角,论文实验中依然存在不足,这个方向仍然有很多坑值得我们去挖,值得我们去尝试。我自己一直在这块比较关注,最近有一些想法,欢迎有同样兴趣的同学一起讨论,还请大牛不吝赐教。
*推荐文章*
Video Analysis 相关领域解读之Temporal Action Detection(时序行为检测)
沈志强 | 如何让计算机自动生成稠密的视频描述(视频+PPT)
*注*:如有想加入极市专业CV开发者微信群(项目需求+分享),请填写申请表(链接:http://cn.mikecrm.com/wcotd9)或者在本公众号后台回复”加群“申请入群




