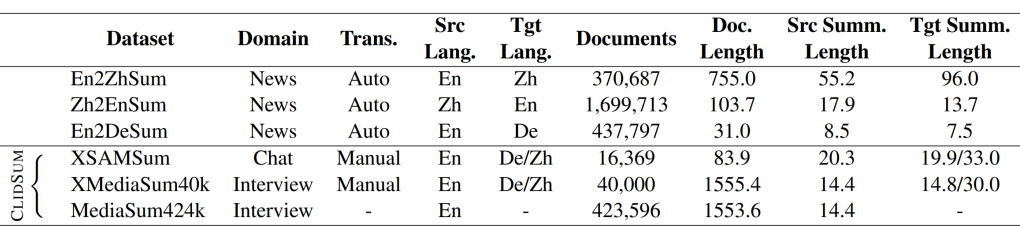
©作者 | 王佳安
学校 | 苏州大学硕士生
研究方向 | 文本生成
跨语言摘要(Cross-Lingual Summarization)旨在为一种语言的文档生成另一种语言的摘要。目前已有的跨语言摘要研究主要关注在新闻报道
[1,2]
,生活指南
[3]
以及百科文章
[4]
上,缺乏针对于对话文档的研究。不同于其他文档,对话文档记录了由多名参与者所提供的结构化对话信息,有着信息分散、话题转移频率高等特点。
为了推进针对于对话文档的跨语言摘要研究,我们与微信模式识别中心展开合作,共同提出了跨语言对话摘要任务并构建了第一个大规模的
跨语言对话摘要基准数据集 ClidSum
。在此基础上,我们制定了不同的预训练策略来提升已有多语言预训练模型(即 mBART-50)在跨语言对话摘要上的适应力,并提出了
mDialBART 跨语言对话摘要预训练模型
。目前该工作已被 EMNLP 2022 主会接收。相关链接如下:
论文标题:
ClidSum: A Benchmark Dataset for Cross-Lingual Dialogue Summarization
https://arxiv.org/abs/2202.05599
https://github.com/krystalan/ClidSum
以往的跨语言摘要数据集主要通过两种方式构建:1)将单语摘要数据集中的摘要部分从源语言翻译至目标语言,这样原始文档与翻译后的摘要便可构成跨语言摘要样本;2)从多语言网站上直接收集跨语言摘要对,例如在维基百科中,将某一词条的主体部分当作源语言文档,并将该词条在其余语言版本中的首段当作目标语言摘要。
通过调研,我们发现目前没有公开的网络资源提供多语言对话数据,因此我们采用方法(1)来构建跨语言对话摘要数据集,即选择已有的单语对话摘要数据集,并翻译其中的摘要部分。
在比较了已有的单语对话摘要数据集
[5]
后,我们选择了 SAMSum 数据集 [6] 以及 MediaSum 数据集
[7]
。SAMSum 和 MediaSum 有着较高的质量,包含了真实世界中或人工标注的单语言对话-摘要对,涉及到人们生活的多种场景。这两个数据集也在近几年的单语对话摘要研究中也备受关注
[5]
。
▲ 图1 SAMSum(左)与MediaSum(右)单语摘要数据集中的样例
在确定单语对话摘要数据集之后,我们采用人工翻译的方式将 SAMSum 的全部摘要(约16K)以及 MediaSum 的部分摘要(40K)从英文分别翻译至汉语与德语。
在翻译过程中,我们采用了严格的质量控制流程,所有英汉译员均通过了英文专八(TEM-8)的资格认定,所有英德译员均通过了英文专八(TEM-8)与德语专八(PGH)的资格认定。除此之外,还有数据审查人员与数据专家对翻译结果进行抽查与评定,确保所得到的汉语/德语摘要的质量。
我们将翻译后的 SAMSum 数据集称为 XSAMSum,将 MediaSum 被翻译的部分称为 XMediaSum40k,没翻译的部分称为 MediaSum424k。
![]()
▲ 表1 先前跨语言摘要数据集与ClidSum数据集的统计对比
如上表所示,ClidSum 一共包含了约 56K 英中跨语言对话摘要对,以及 56K 英德跨语言对话摘要对。其中约 16K 来自 SAMSum,40K 来自 MediaSum。此外,SAMSum 的文档平均长度为 83.9,而 MediaSum 则长达上千单词。因此,ClidSum 对短文本与长文本均有涉及。
现有的多语言预训练生成模型(例如 mBART 和 mT5)在预训练阶段仅学习到了底层的语言建模能力,并没有建模跨语言能力以及理解对话文档的能力。为了帮助多语言预训练生成模型更好地完成跨语言对话摘要任务,我们在 mBART 的基础上提出了 mDialBART 预训练生成模型。
如上图所示,为了提升模型理解对话文档的能力,我们采用了 action infilling 和 utterance permutation 预训练任务。其中 action infilling 随机掩码了对话文档中的重要信息,并让模型恢复原始对话文档,受启发于 S-BART
[8]
,我们将对话文档中的 who-doing-what 信息视为重要信息。Utterance permutation 打算了一篇对话文档中的 utterance 顺序,并让模型进行恢复。
除此之外,我们还采用了单语对话摘要(monolingual dialogue summarization)任务以及机器翻译(machine translation)任务同时让模型学习摘要和翻译的能力。
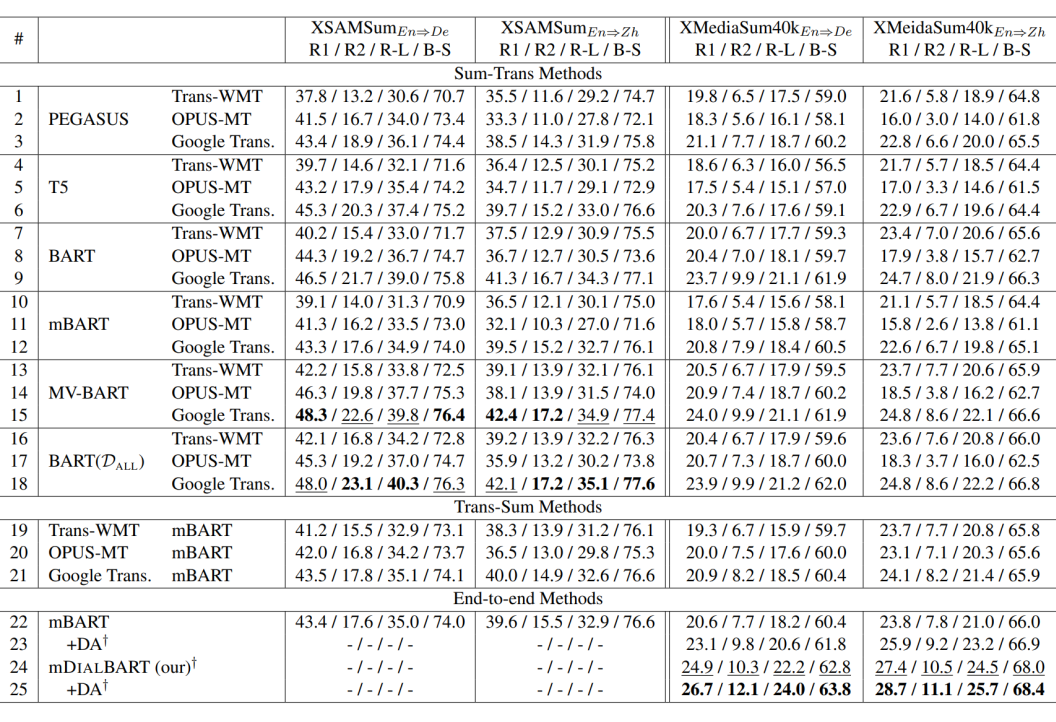
如上表所示,我们在 XMediaSum40k 上对比了 mDialBART 和众多基线模型,发现该预训练生成模型能够更好地用于跨语言对话摘要任务。
我们已将 mDialBART 的模型参数开源在 Huggingface 社区,你可以通过下面的方式进行调用:
from transformers import MBartForConditionalGeneration
mdialbart_de = MBartForConditionalGeneration.from_pretrained('Krystalan/mdialbart_de')
mdialbart_zh = MBartForConditionalGeneration.from_pretrained('Krystalan/mdialbart_zh')
在本文中,我们提出了跨语言对话摘要任务并构建了第一个大规模的跨语言摘要对话基准数据集 ClidSum。在构建过程中,我们采用了人工翻译已有单语对话摘要数据集的方式合成了跨语言对话摘要数据集,并进行了严格的质量控制流程。除此之外,为了让已有多语言预训练生成模型更好地完成该任务,我们在 mBART 的基础上提出了 mDialBART,利用四个预训练任务进一步提升模型理解对话、摘要和翻译的能力。实验结果证明了 mDialBART 的有效性。
[1] Junnan Zhu, Qian Wang, Yining Wang, Yu Zhou, Jiajun Zhang, Shaonan Wang, Chengqing Zong. NCLS: Neural Cross-Lingual Summarization. In Prof. EMNLP 2019.
[2] Tahmid Hasan, Abhik Bhattacharjee, Wasi Uddin Ahmad, Yuan-Fang Li, Yong-Bin Kang, Rifat Shahriyar. CrossSum: Beyond English-Centric Cross-Lingual Abstractive Text Summarization for 1500+ Language Pairs. ArXiv preprint, abs/2112.08804.
[3] Faisal Ladhak, Esin Durmus, Claire Cardie, Kathleen McKeown. WikiLingua: A New Benchmark Dataset for Cross-Lingual Abstractive Summarization. In Findings of EMNLP 2020.
[4] Laura Perez-Beltrachini and Mirella Lapata. Models and Datasets for Cross-Lingual Summarisation. In Prof. EMNLP 2021.
[5] Xiachong Feng, Xiaocheng Feng, Bing Qin. A Survey on Dialogue Summarization: Recent Advances and New Frontiers. In Prof. IJCAI 2022 (survey track).
[6] Bogdan Gliwa, Iwona Mochol, Maciej Biesek, Aleksander Wawer. SAMSum Corpus: A Human-annotated Dialogue Dataset for Abstractive Summarization. In Prof. of the 2nd Workshop on New Frontiers in Summarization.
[7] Chenguang Zhu, Yang Liu, Jie Mei, Michael Zeng. MediaSum: A Large-scale Media Interview Dataset for Dialogue Summarization. In Prof. NAACL 2021.
[8] Jiaao Chen and Diyi Yang. Structure-Aware Abstractive Conversation Summarization via Discourse and Action Graphs. In Prof. NAACL 2021.
![]()
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿
![]()
△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
![]()