复旦大学张奇组:对话摘要数据不足?对话数据、文档摘要数据,我全都要!



对话摘要任务,是从一段对话中抽取或生成一段总结。
对话摘要任务面临的其中一个重要问题是:训练数据不足, 但同时对话摘要数据很难获取,人工标注代价很高。
那么我们从哪里获得训练数据呢?我们很自然地想到,能不能从其他领域获得数据来加强训练呢?既然是对话摘要领域,我们能不能从对话领域、文本摘要领域中的数据集获益呢?


本文尝试解决的核心问题是如果使用了多源的数据集,如拿对话数据集和文档摘要数据集进行预训练,会产生预训练阶段和 finetuning 阶段的 gap。
这个问题的产生的主要原因之一是因为对话的结构和文档具有显著差别:
对话具有特征不同的多个参与者;
对话过程中会出现口语化的非正式表达;
对话摘要的输出,尤其是长度和结构和其他摘要任务差别很大。
针对这个问题,本文的核心 Idea 就是:既然无法拿多源数据做端到端的训练,那可以将端到端的训练拆分成三部分:encoder 的训练、decoder 的训练、encoder 和 decoder 的联合训练。
拆成三部分之后,我们再看看这些部分的目的是什么?
仅独立地看 encoder 部分,encoder 的目的是去学习对话的表示;
仅独立地看 decoder 部分,decoder 的目的是去生成摘要文本;
encoder 和 decoder 的联合是为了为一个长输入生成意义接近的短输出。
既然 encoder 部分是为了学习对话的表示,对话数据适合去训练 encoder。
既然 decoder 部分是为了生成摘要文本,那么找一些概括性高的短句子训练 decoder 应该是有益的。
而 encoder 和 decoder 的联合是为了为一个长输入生成意义接近的短输出,因此使用文档摘要训练 encoder 和 decoder 的联合应该是有益的。

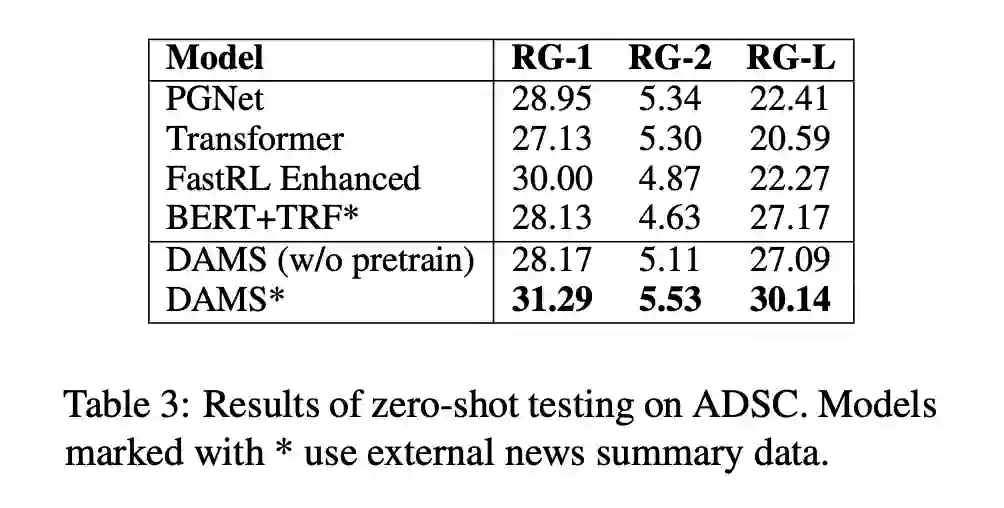
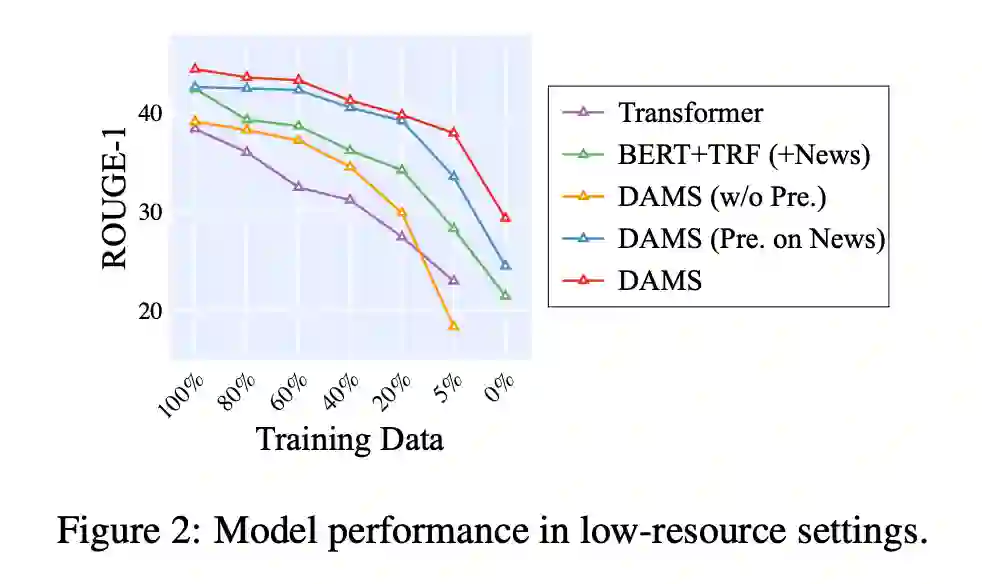
随着日常生活中对话数据量的快速增长,对话摘要的需求也越来越大。不幸的是,由于对话数据与注释摘要难以获取,训练一个大的摘要模型通常是不可行的。大多数现有的低资源对话摘要工作直接在其他领域进行预训练,如新闻领域,但他们通常忽略了对话和传统文章之间的巨大差异。
为了弥补域外预训练和域内微调之间的差距,在这项工作中,我们提出了一个多源预训练范式,以更好地利用外部汇总数据。具体来说,本文利用大规模的域内非摘要数据,分别预训练对话编码器和摘要解码器。然后使用对抗数据成对组合对解码模型进行域外摘要数据的预训练,以促进未知域摘要的生成。
在两个公开数据集上的实验结果表明,在训练数据有限的情况下,该方法能够获得较好的竞争性能,并且在不同的对话情景下具有较好的概括性。

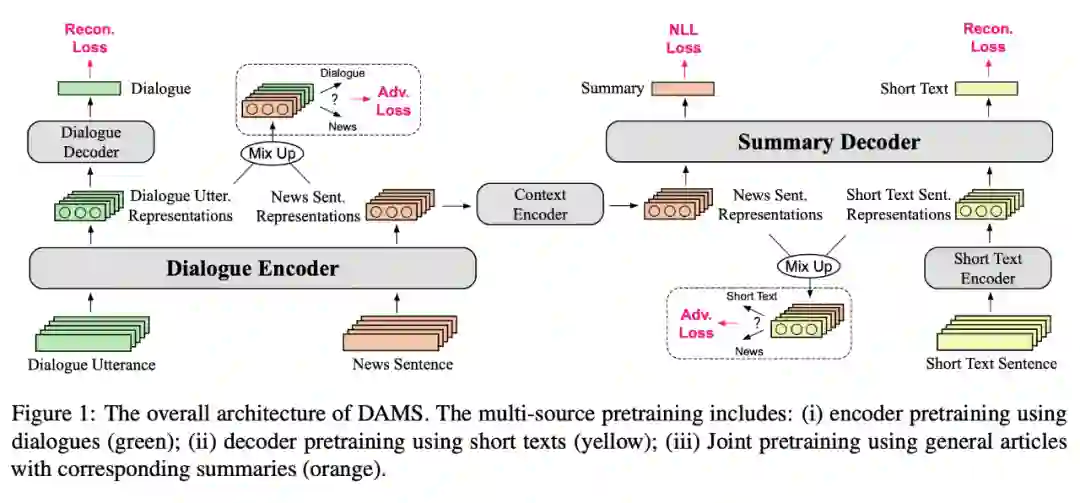
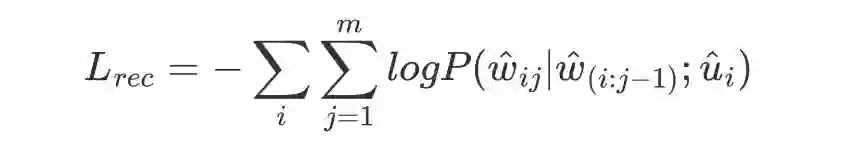
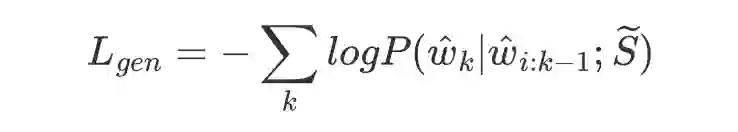
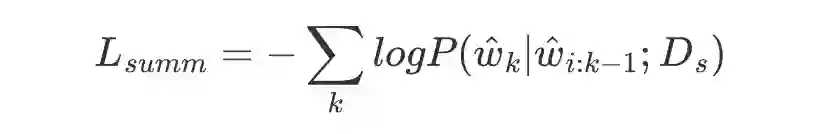
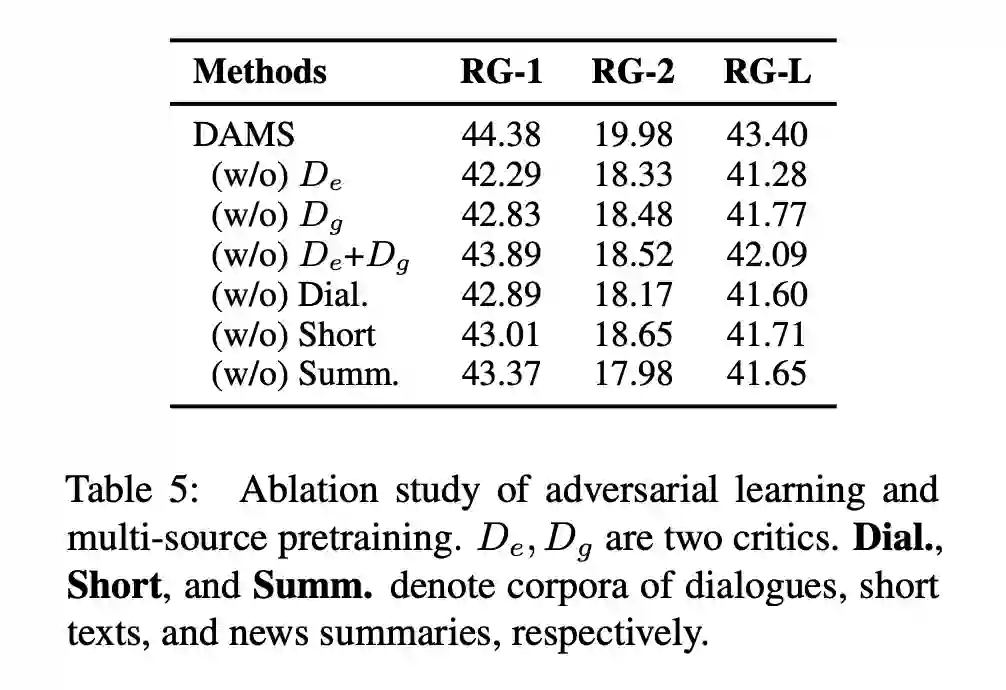
4.4 对抗学习模块
理想的目标是:让 DAE(去噪编码器)学习到对话的语言风格和表示。
但由于我们同时馈送到 encoder 中的不止是对话数据(非正式),还有一部分是文本摘要数据(这里是新闻数据)。同样地,decoder 中馈送的是短文本和文本摘要的 encode 结果。模型会学到这些特定域的归纳偏置。因此如果模型在一个新的领域中进行摘要将变得十分困难。我们如果想让模型泛化到一个新的域,需要学习这些域中表示的通用特征。
因此本文基于对抗学习的思想,使用了一个对抗鉴别器,努力地使鉴别器不能预测是哪个类,从而确保不同域上的特征分布是相似的,也即让模型更关注通用内容而不是特定域的属性。
这里使用的鉴别器是一个简单的多层感知机,后面加上一个 sigmoid 激活层。训练一个简单的二元分类器,使用 logistic loss function。
有两个这样的鉴别器,分别在 encoder 端试图区分对话和新闻数据,在 decoder 端试图区分短文本和新闻数据。
4.5 总结
最后的总 loss 如下式:
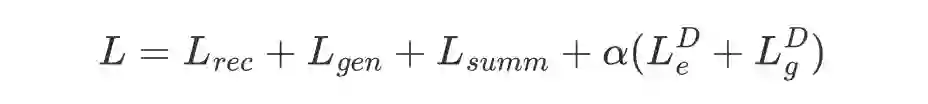

Experiment


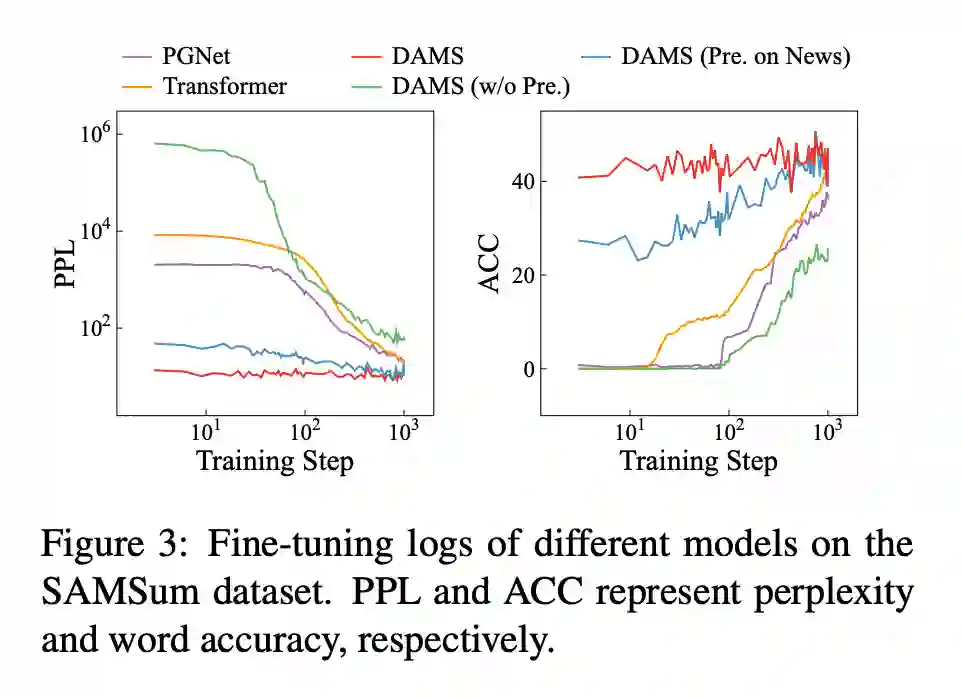



Conclusion
特别鸣谢
感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编


