这项研究旨在解决零样本下法语、德语、西班牙语、俄语和土耳其语等多语种的抽取式摘要任务,并在多语言摘要数据集 MLSUM 上大幅提升了基线模型的分数。
抽取式文本摘要目前在英文上已经取得了很好的性能,这主要得益于大规模预训练语言模型和丰富的标注语料。但是对于其他小语种语言,目前很难得到大规模的标注数据。
中国科学院信息工程研究所和微软亚洲研究院
联合提出一种是基于 Zero-Shot 的多语言抽取式文本摘要模型
。具体方法是使用在英文上预训练好的抽取式文本摘要模型来在其他低资源语言上直接进行摘要抽取;并针对多语言 Zero-Shot 中的单语言标签偏差问题,提出了
多语言标签(Multilingual Label)标注算法
和
神经标签搜索模型(Neural Label Search for Summarization, NLSSum)
。
实验结果表明,模型 NLSSum 在多语言摘要数据集 MLSUM 的所有语言上大幅度超越 Baseline 模型的分数。其中在俄语(Ru)数据集上,零样本模型性能已经接近使用全量监督数据得到的模型。
该研究发表在了 ACL 2022 会议主会长文上。
论文地址:https://aclanthology.org/2022.acl-long.42.pdf
随着 BERT 在自然语言处理领域的发展,在大规模无标注数据上进行预训练的模式得到了广泛的关注。
近些年,有很多研究工作在多种语言的无标签语料上进行训练,从而得到了支持多种语言的预训练模型。这些基于多语言文本的预训练模型能够在跨语言的下游任务上取得很好的性能,例如 mBERT、XLM 和 XLMR。对于基于 Zero-Shot 的多语言任务,上述的多语言模型也能取得不错的效果。其中,XLMR 模型的 Zero-Shot 效果在 XNLI 数据集上已经能够达到其他模型 Fine-tune 的水平。因此这为我们在抽取式文本摘要任务上进行基于 Zero-Shot 的探索提供了基础。
在单语言的抽取式文本摘要中,数据集通常只含有原始文档和人工编写的摘要,因此需要使用基于贪心算法的句子标签标注算法来对原文中的每句话进行标注。但这种算法是面向单语言的标注方法,得到的结果会产生单语言标签偏差问题,在多语言的任务上仍然需要优化。下面的图表展示的就是单语言标签偏差问题。
表 1. 多语言 Zero-Shot 中的单语言标签偏差问题。
如上表 1 样例所示,这个例子是摘要领域目前最常见的 CNN/DM 数据集中选取的部分文档。CNN/DM 是一个英文数据集,示例中上半部分的即为原始文档中的英文表示和人工编写的英文摘要;示例中的下半部分是使用微软开源的工业级翻译模型 Marian,将英文的文档和摘要全部翻译为德语。示例中的这句话和人工编写的摘要具有较高的相似性,因此会得到较高的 ROUGE 分数。
但是对于翻译成德语的文档句子和摘要,我们发现两者的相似性较低,对应的 ROUGE 分数也会较低。这种情况下,使用英语语言环境下标注的标签直接训练的多语言文本摘要模型,在其他语言的语言环境中并不是最优的。
上述实例表明同一个句子在不同语言环境下会存在标签偏差的问题,也就是目前的贪心算标注标签的方式无法满足基于 Zero-Shot 的多语言文本摘要任务。
为了解决上述基于 Zero-Shot 的多语言抽取式文本摘要中单语言标签偏置的问题,我们提出了一种多语言标签算法。在原来单语言标签的基础上,通过使用翻译和双语词典的方式在 CNN/DM 数据集上构造出另外几组多语言交互的句子标签。对于这几组语言标签,设计出神经语言标签搜索模型 (NLSSum) 来充分利用它们对抽取式摘要模型进行监督学习。
在 NLSSum 模型中,使用层次级的权重来对这几组标签进行句子级别 (Sentence-Level) 和组级别 (Set-Level) 的权重赋值。在抽取式模型的训练期间, Sentence-Level 和 Set-Level 权重预测器是和摘要抽取器一起在英文标注语料上进行训练的。模型推断测试的时候,在其他语言上只使用摘要抽取器来进行摘要抽取。
我们针对基于 Zero-Shot 多语言摘要任务中的单语言标签偏移问题,提出了
神经标签搜索模型来对多语言标签使用神经网络搜索其权重,并使用加权后的标签监督抽取式摘要器
。具体的流程分为以下五步:
-
多语言数据增强
:这里的目前是将原始英文文档用翻译、双语词典换等方式来减少和目标语言之间的偏差;
-
多语言标签
:我们的抽取式摘要模型最终是通过多语言标签来进行监督的,其中多语言标签总共包含 4 组标签,这 4 组标签都是根据不同的策略来标注的;
-
神经标签搜索
:在这步中为不同组标签设计了层次级的权重预测,包括句子级别 (Sentence-Level) 和组级别 (Set-Level),最终使用加权的标签来对抽取式摘要模型进行监督;
-
微调训练 / Fine-Tunig
:使用增强的文档数据和加权平均的多语言标签来 Fine-Tune 神经摘要抽取模型;
-
基于 Zero-Shot 的多语言摘要抽取
:使用在英文标注数据上训练完的模型可以直接在低资源语言的文档上进行摘要句子抽取。
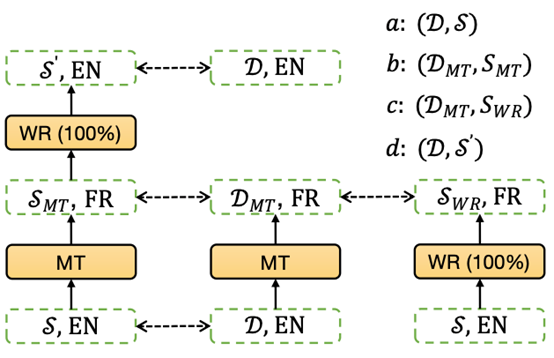
如上图 1 所示,在原始英文文档 D 和人工编写摘要 s 上设计出四组多语言标签 (Ua,Ub,Uc,Ud),具体的构造方法如下所示:
1. 标签集合 Ua
:定义 Ua=GetPosLabel (D,s) 为使用文档 D 和人工编写摘要 s 使用贪心算法得到的抽取为摘要的句子集合,其中 GetPosLabel 返回的是标签为 1 的句子的索引。使用 (D,s) 得到的是英文文档上的到的摘要句子,这个结果对于其他语言来说并不是最优的,因此我们还设计了另外三组标签。
2. 标签集合 Ub
:首先将英文原始文档和人工编写摘要都使用机器翻译模型 MarianMT 将其翻译为目标语言,标记为 DMT 和 sMT,然后使用 Ub=GetPosLabel (DMT,sMT) 的方式得到翻译后文档上摘要句子的索引集合。这种借助于机器翻译模型的方法相当于使用目标语言的句法结构来表达原始英文的语义,因此得到的摘要句子能反应出目标语言句法结构对摘要信息的偏重。
3. 标签集合 Uc
:在这组标签的构造中,首先将原始英文文档自动翻译为目标语言 DMT,然后将人工编写的英文摘要使用双语词典替换为目标语言 SWR (将所有摘要中的词都进行替换),然后我们使用 Uc=GetPosLabel (DMT,SWR) 的方式得到翻译和词替换方式交互的摘要句子索引集合。这种方法将原始文档使用机器翻译来替换句法结构,摘要使用双语词典翻译来保留原始语言句法结构同时和文档语言保持一直,因此能够得到目标语言和原始语言之间句法结构在抽取摘要句子上的交互。
4. 标签集合 Ud
:这个方法中,文档使用的是原始英文文档 D;摘要先经过机器翻译转换到目标语言,然后经过双语词典进行词替换转换回英语,使用 S′来表示。最终我们使用 Ud=GetPosLabel (D,S′) 来得到抽取式摘要句子标签集合。在这种方法中,原始文档保持不变,摘要则是使用目标语言的句法结构,因此能够再次得到目标语言和原始语言之间句法结构在抽取摘要句子上的交互。
需要注意的是,使用 GetPosLabel (D,S) 的时候,要保证 D 和 S 是同种语言的表示,因为基于贪心算法的标签标注算法本质上是对词语级别进行匹配。另外,还有很多种构造多语言标签的方法,我们只是选取了几组有代表性的方法。这些方法中使用的机器翻译模型和双语词典替换可能会引入额外的误差,因此需要为这几组标签学习合适的权重。
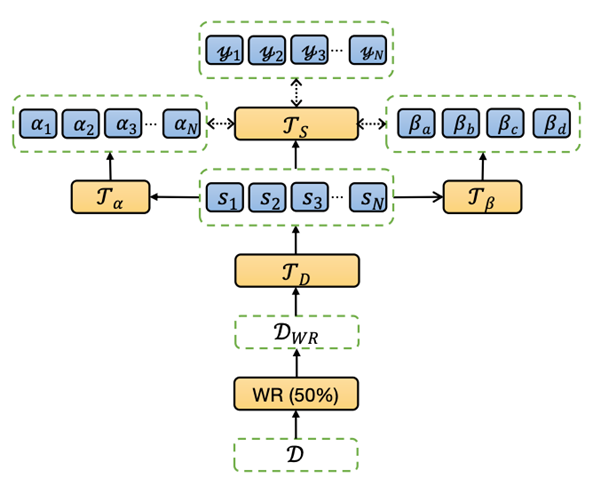
如下图 2 所示,对于已经得到的几组多语言标签 (Ua,Ub,Uc,Ud),需要设计神经标签搜索的模型来对不同组的标签设置权重。权重包含两部分,句子级别 (Sentence-Level) 和组级别 (Set-Level)。对应这两个级别的权重,我们分别定义两个权重预测器,句子级别权重预测 Transformeralpha 和组级别权重预测 Transformerbeta。
NLSSum 是通过神经搜索的方式来对 MultilingualLabel 中不同标签集合赋予不同的权重,并最终得到加权平均的标签。使用这种最终的标签在英文数据集上训练抽取式摘要模型。和单语言标签相比,多语言标签中存在更多的跨语言语义和语法信息,因此本文的模型能够在 Baseline 基础上获得较大的提升。
如下表 2 所示,
实验使用的数据集包括 CNN/DM 和 MLSUM
,具体数据集描述如表 6.2 所示。MLSUM 是第一个大规模的多语言文本摘要数据集,它从新网网站上爬取了 150 万条文档和摘要,包含五种语言:法语 (French,Fr)、德语 (German,De)、西班牙语 (Spanish,ES)、俄语 (Russian,Ru) 和土耳其语 (Turkish,Tr)。MLSUM 是在测试推断的时候验证 Zero-Shot 多语言模型的跨语言迁移能力。在训练阶段使用的是文本摘要领域最常见的 CNN/DM 英文数据集。
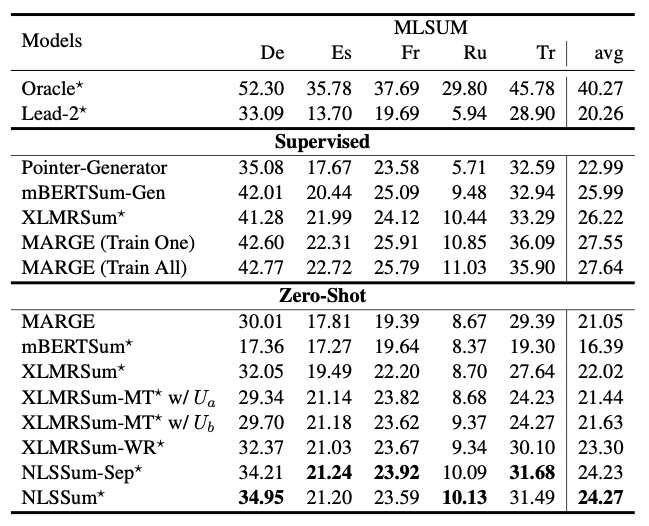
表 2:MLSUM 数据集上的 ROUGE 结果。
这里对 MLSUM 数据集上各个基线模型的的 ROUGE 结果进行对比。表格总共分为三部分。
-
第一部分
展示的是 Oracle 和 Lead 这些简单的基线模型;
-
第二部分
展示的是基于监督学习的一些基线模型,其中 (TrainAll) 是在所有语言的数据集上进行训练,(TrainOne) 是在每个语言的数据集上单独训练;
-
第三部分
展示的是无监督学习的结果,所有的模型都是只在英文数据集上进行训练。
其中,根据第二部分的结果很容易发现,在监督学习中,基于生成式的摘要方式比抽取式的更加合适。在第三部分中,基线模型 XLMRSum 的性能能够超越生成式模型的 MARGE,这说明无监督学习中使用抽取式方法更加合适。
另外,当使用机器翻译和双语词典替换来对原始文档进行数据增强的时候 (基线模型 XLMRSum-MT 和 XLMRSum-WR),可以发现 XLMRSum-MT 模型会带来模型性能下降,而 XLMRSum-WR 会带来性能的提升,因此最终的模型中数据增强选择的是基于双语词典的词替换方式。
因此对于我们 NLSSum 模型,我们同样有两种配置,
NLSSum-Sep
是将 CNN/DM 单独词替换为对应的一种目标语言并进行微调训练;
NLSSum
是 CNN/DM 词分别替换为所有的目标语言并在所有语言的替换后的数据集上进行微调训练。
最终结果显示,在所有语言上进行训练的 NLSSum 效果更好。从表格中我们可以总结出以下结论:
-
基于翻译模型的输入数据增强会引入误差,所以应该避免在输入中使用翻译模型;相反,双语词典的词替换方式是一个不错的数据增强方法;
-
标签的构造过程中不涉及模型输入,所以可以使用机器翻译模型来辅助标签生成。
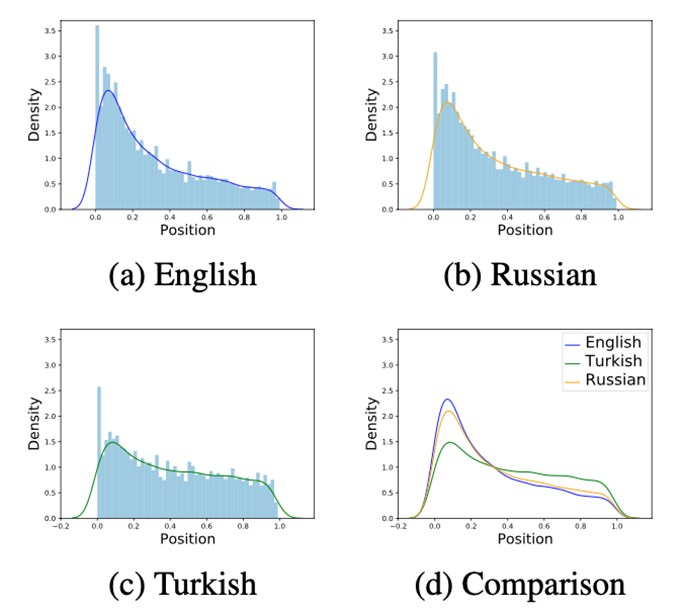
如下图 3 所示,通过可视化分析进一步研究不同语言间重要信息的分布位置,从中可以看出英文语言中重要信息分布较为靠前,而其他语言中的重要信息则比较分散,这也是多语言标签能够提升模型性能重要原因。
未来研究将关注于:1. 寻找更加合理的多语言句子级别标签标注算法;2. 研究如何提升低资源语言摘要结果,同时不降低英语语料上的结果。
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com