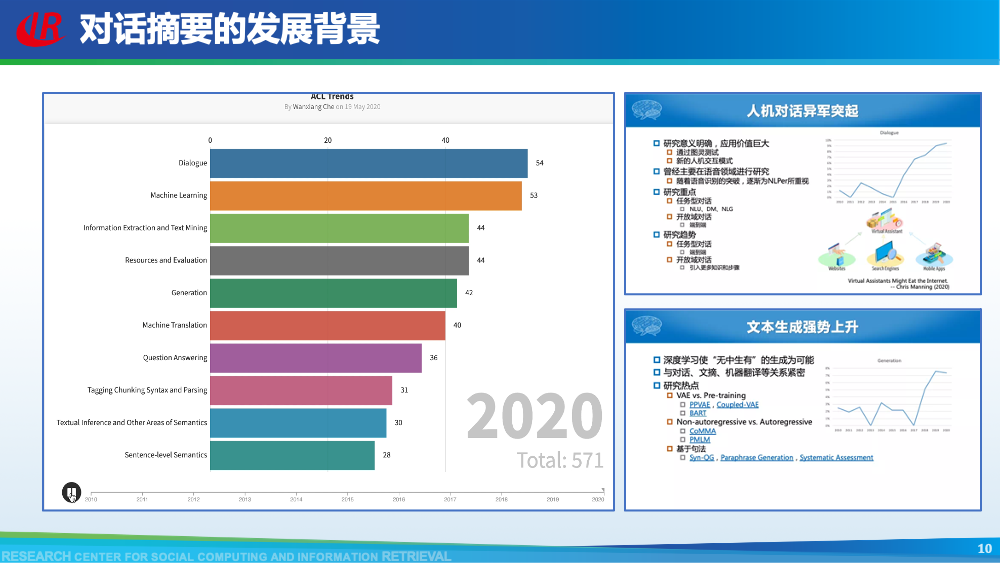
ACL 2020:摘要的事实一致性研究异军突起,共出现了7篇论文,主要关注(1)如何评价生成摘要的事实一致性和(2)如何提升生成摘要的事实一致性。摘要的事实一致性研究也成为了从2020年至今最火热的研究方向之一,如果对于该方向感兴趣,可以参考我们的综述论文《The Factual Inconsistency Problem in Abstractive Text Summarization: A Survey》和Blog:事实感知的生成式文本摘要。
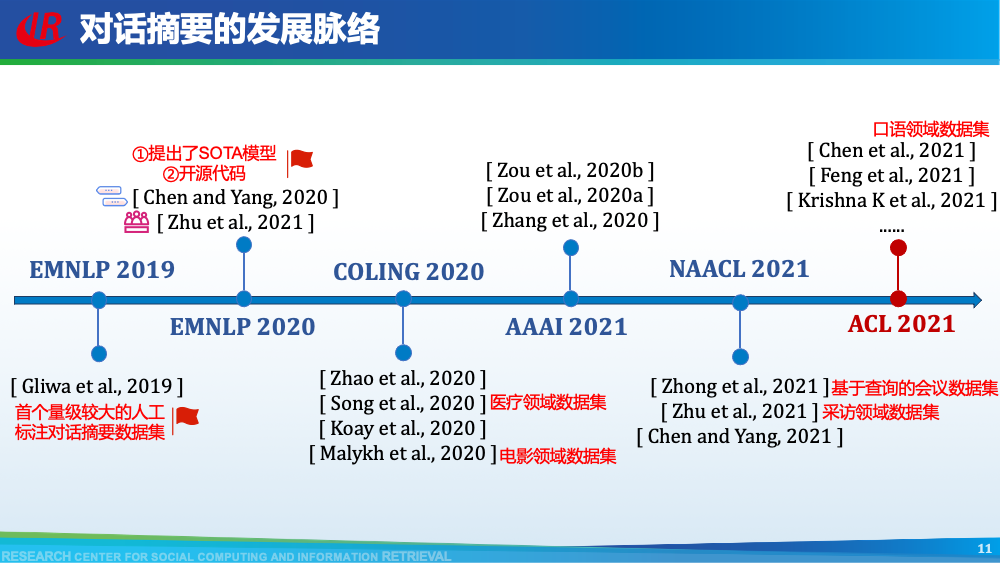
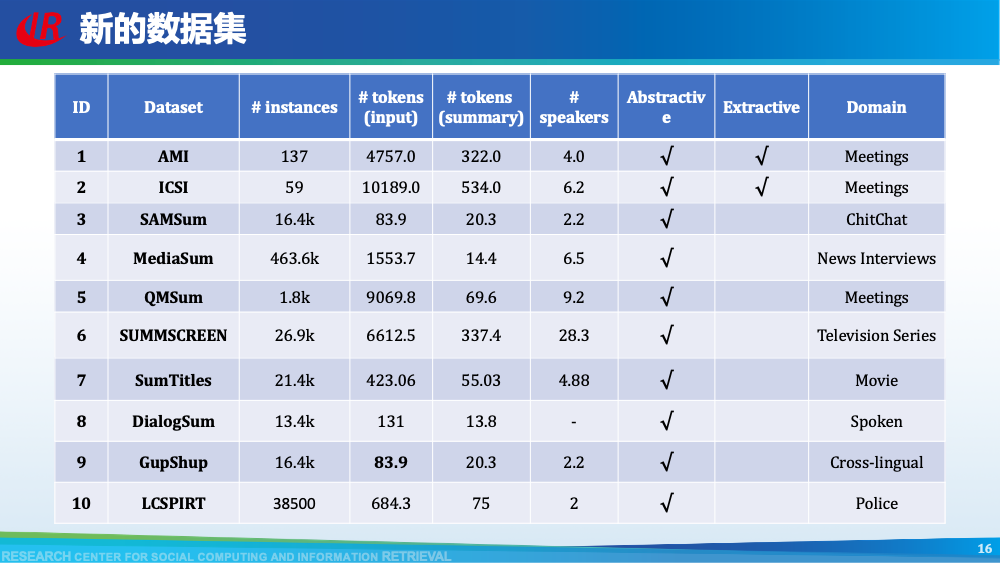
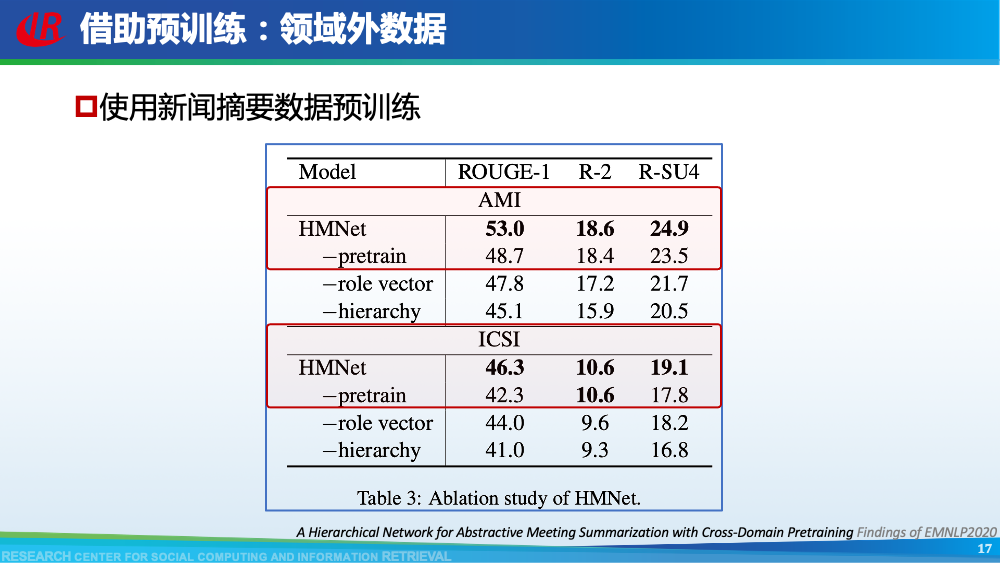
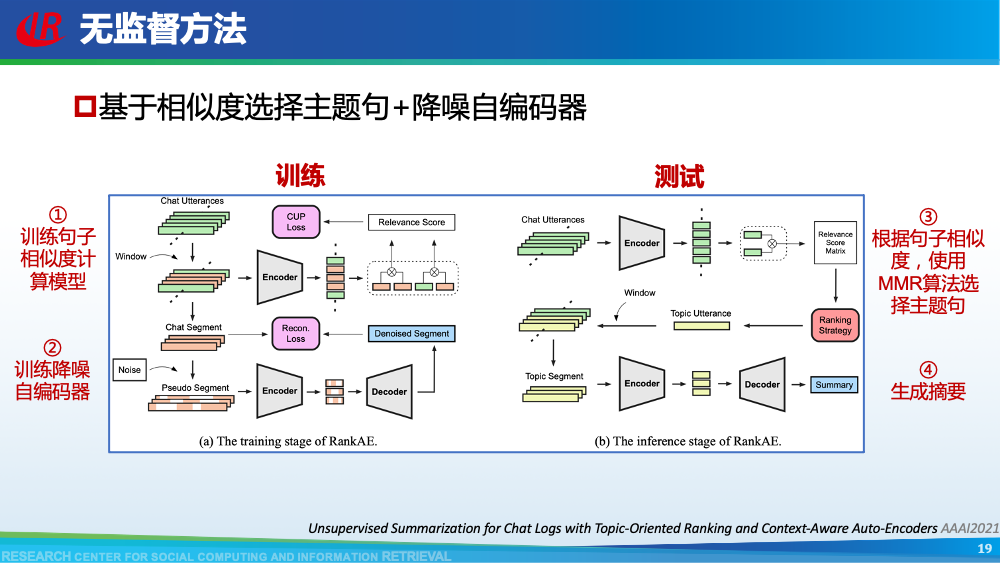
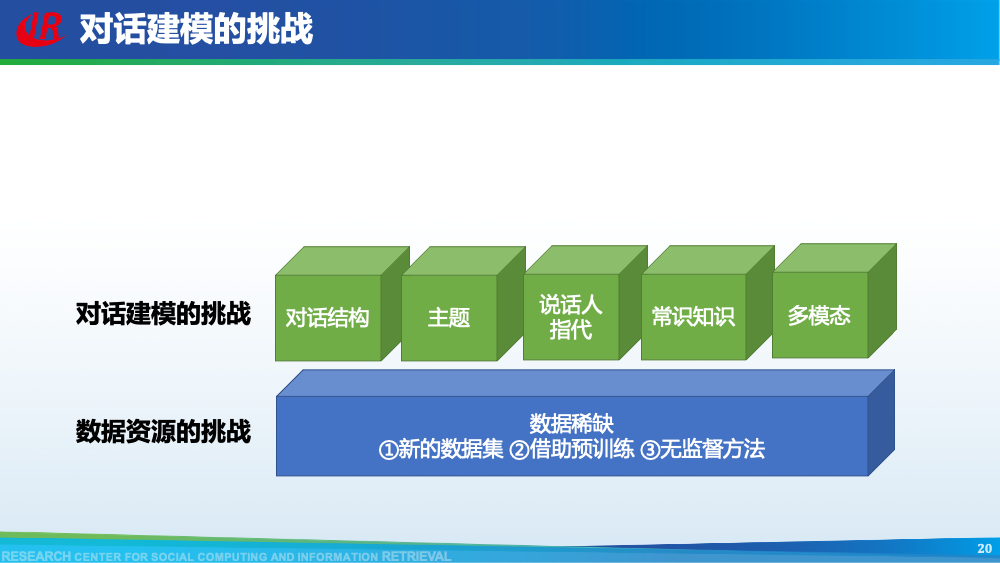
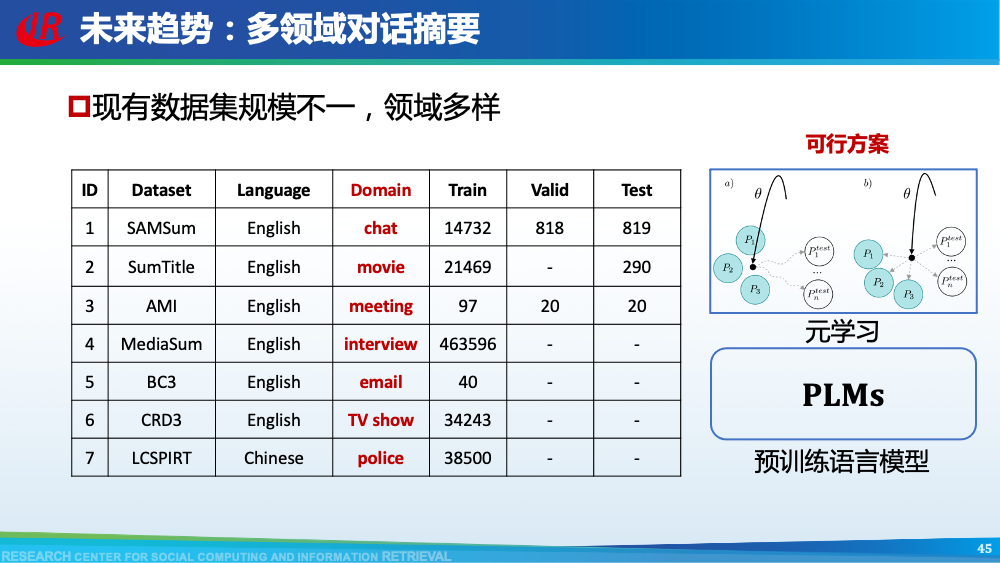
我们首先介绍针对第一层挑战的相关工作。主要分为三类:(1)构造新的对话摘要数据集;(2)借助预训练的思想缓解数据不足的问题;(3)使用无监督方法。如图所示,我们总结了现有大部分对话摘要数据集。其中AMI和ICSI是2003年左右提出的小规模会议摘要数据集,也是研究会议摘要任务的标准数据集。除了上述两个数据集以外,其余所有数据集均是近两年提出,覆盖了众多的领域,其中也不乏一些大规模数据集,例如在NAACL 2021,Chenguang Zhu等人提出的MediaSum。这些数据集中也包括了一些新颖的数据集,例如GupShuo是一种输入为两种语言的对话摘要数据集,LCSPIRT为中文报警对话摘要数据集。众多数据集的提出为这一方向奠定了扎实的基础,也为很多研究提供了机会。虽然对话摘要数据比较稀缺,但是新闻摘要是一个研究长久的方向。例如新闻摘要常用数据集CNNDM便具有近30w的规模。因此Chenguang Zhu等人首先使用新闻数据预训练摘要模型,然后再使用会议数据进行微调。通过他们的消融实验可以看出,预训练起到了一定的作用。上述方法使用新闻数据,可以视为一种领域外的数据。我们设计了一种数据增强策略,来构造伪造的领域内数据用于预训练模型。简单来讲,我们认为在会议中,一个问题往往会引起一段讨论,问题通常包含了讨论的核心要点内容,因此我们将问题视为伪造的摘要,讨论视为伪造的会议,从原始的会议数据集中构造了伪造摘要数据集。从表格可以看出,我们构造的数据集是原始数据集的20倍大小,一定程度上可以用于预训练我们的模型。更多细节可以参考我们的论文Dialogue Discourse-Aware Graph Model and Data Augmentation for Meeting Summarization和Blog:会议摘要有难度?快来引入对话篇章结构信息。解决数据不足的常见方法就是采用无监督的方式。Yicheng Zou等人在AAAI 2021发表了两篇工作研究无监督方式在对话摘要任务中的可行性,这里选取其中一篇进行介绍。该方法的核心是基于相似度选择对话主题句,然后借助降噪自编码器生成对话摘要。在训练部分,一方面,采用对比学习的思想训练句子相似度计算模型,另一方面,训练降噪自编码器用于后续生成对话摘要。在测试部分,基于MMR的想法,综合考虑重要性和冗余度选取对话主题句,然后使用降噪自编码器生成最终摘要。
提到对比学习,在AAAI 2019,刘知远老师已经采用了对比学习的思想训练摘要模型:DeepChannel: Salience Estimation by Contrastive Learning for Extractive Document Summarization。在ACL 2021,Pengfei Liu博士也探究了对比学习在摘要任务中的使用《SimCLS: A Simple Framework for Contrastive Learning of Abstractive Summarization》。
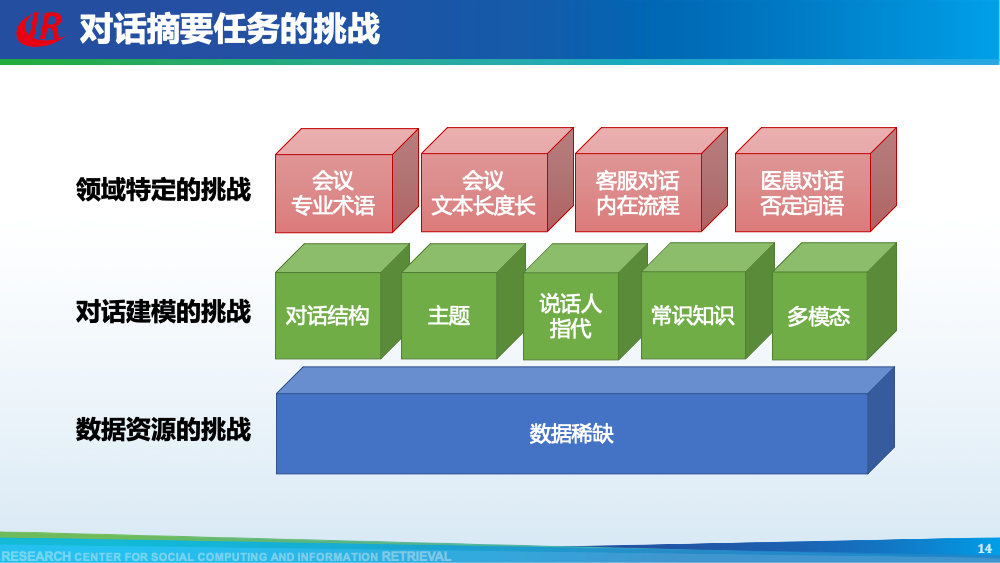
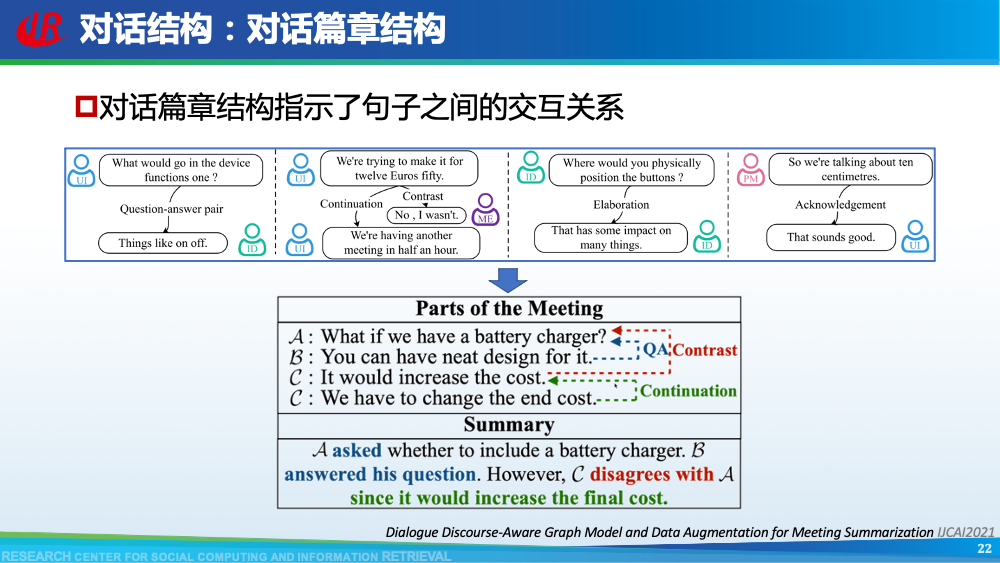
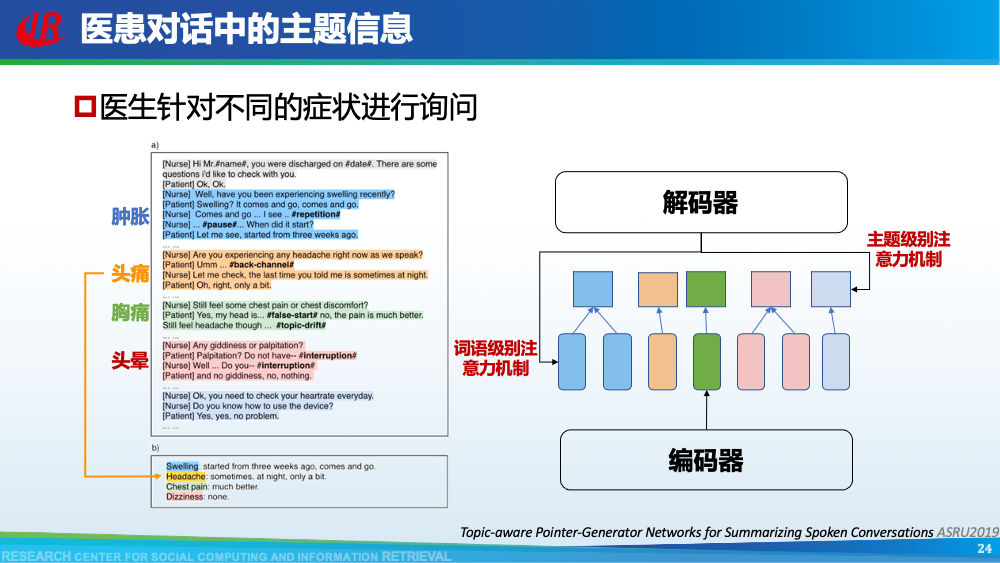
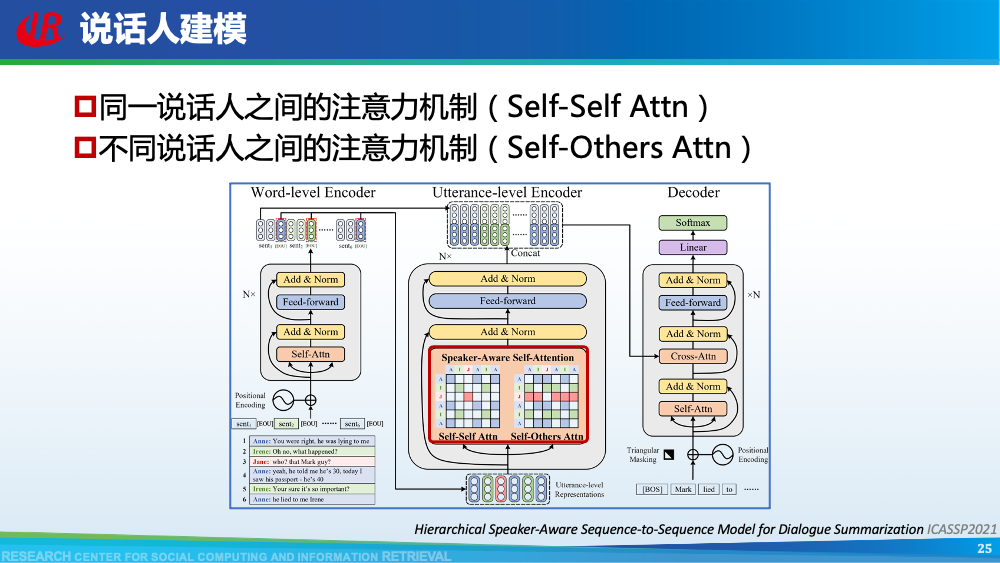
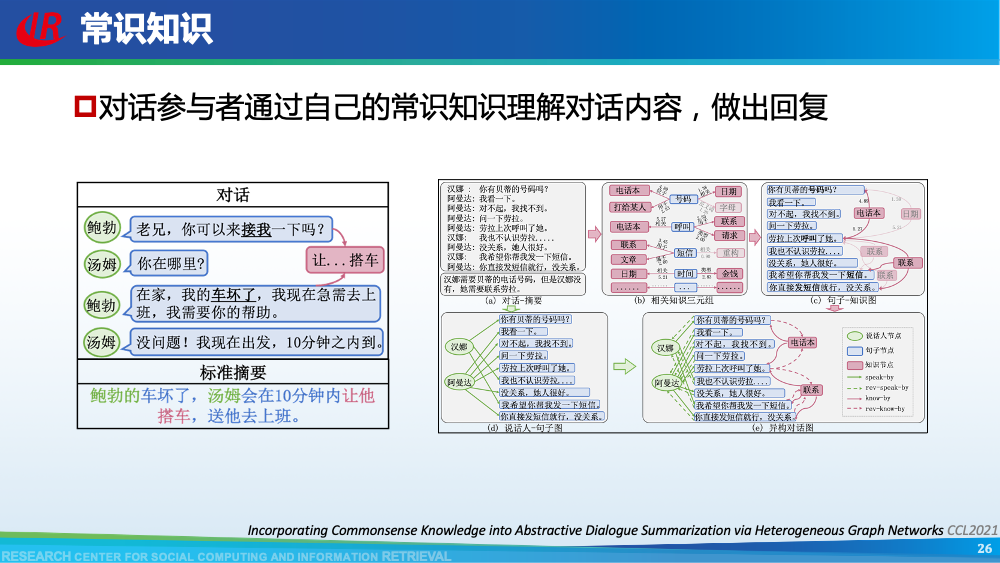
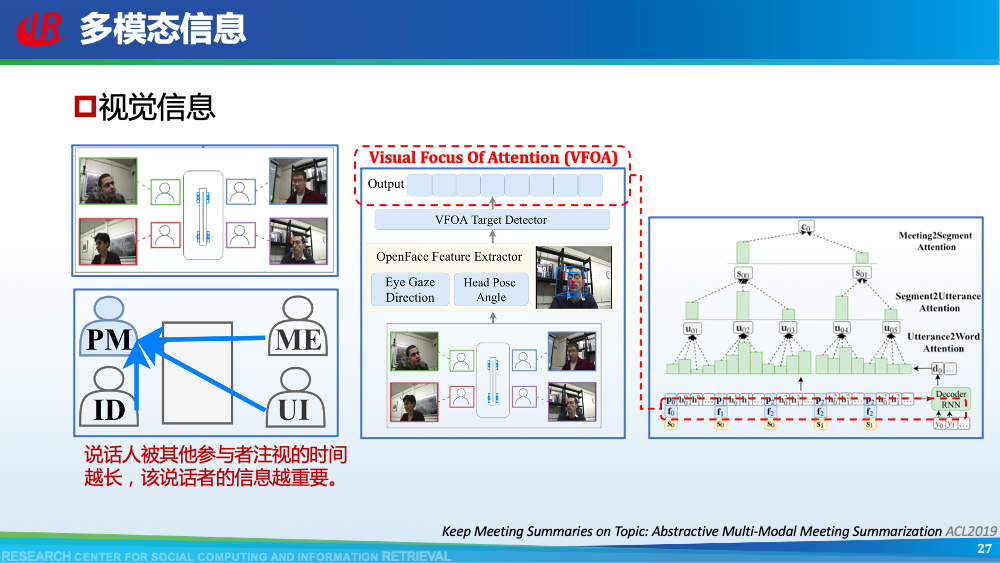
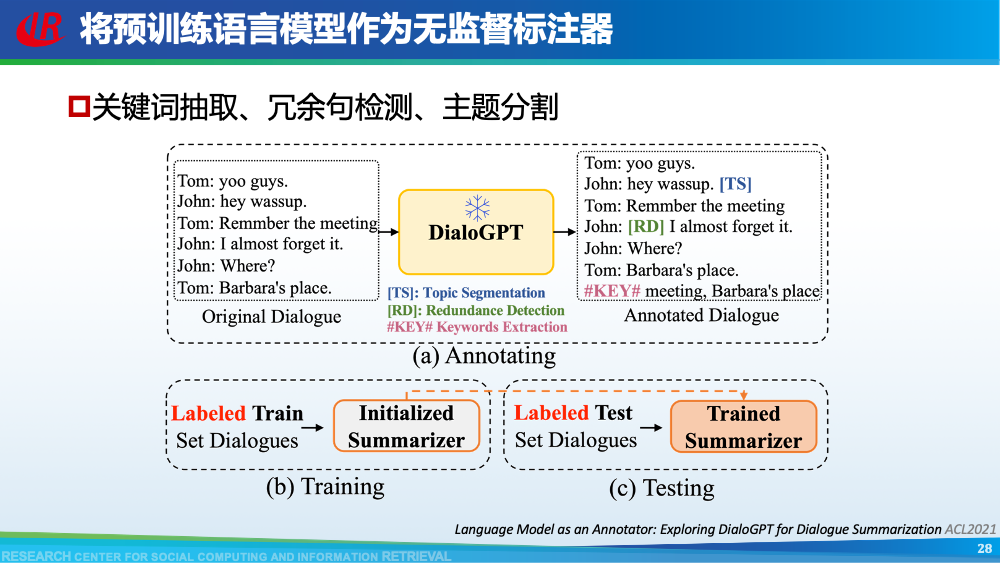
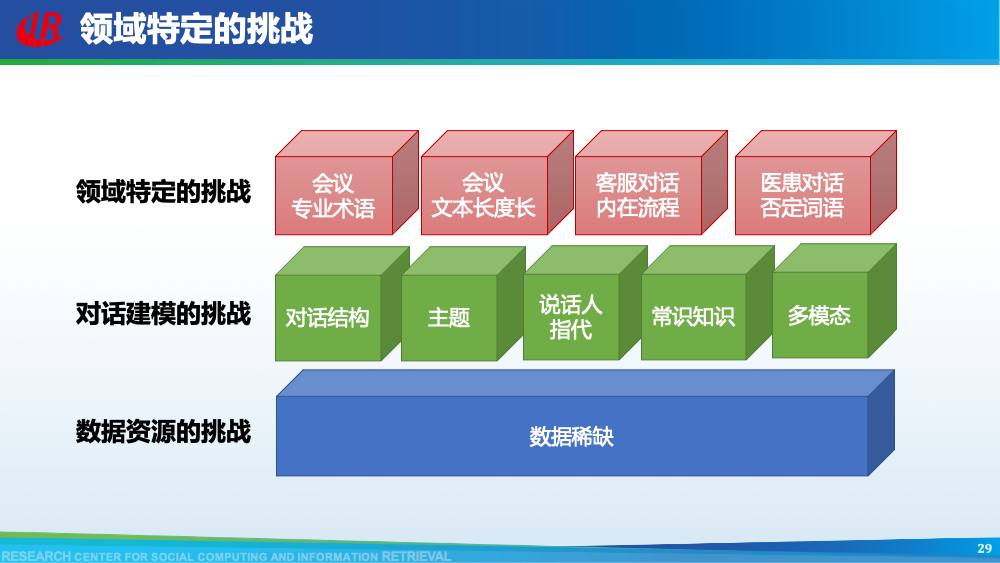
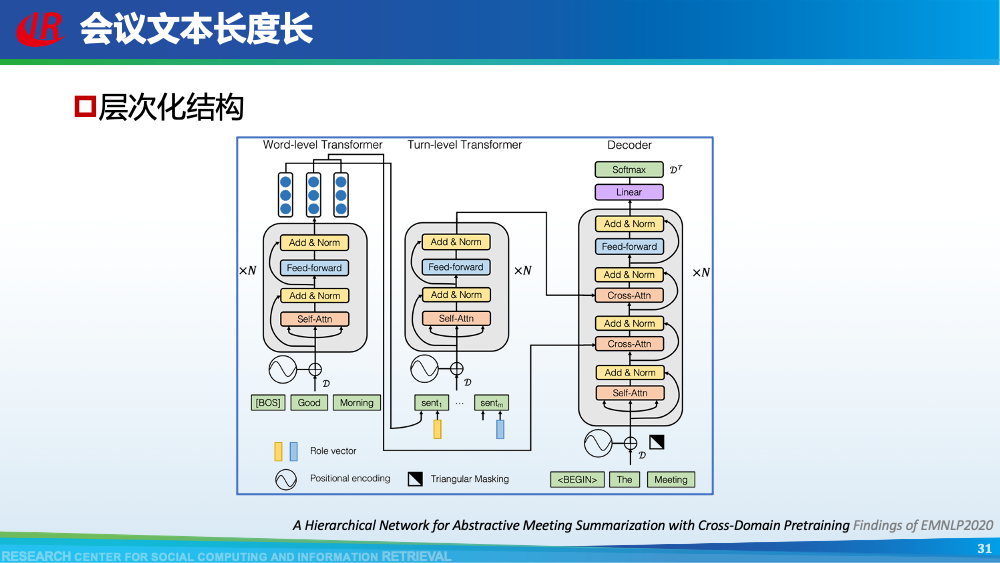
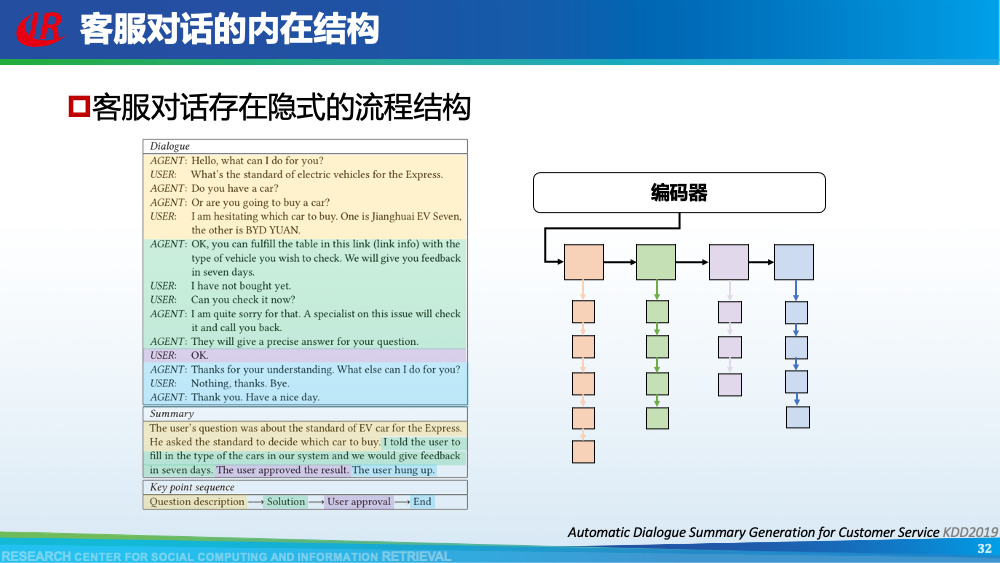
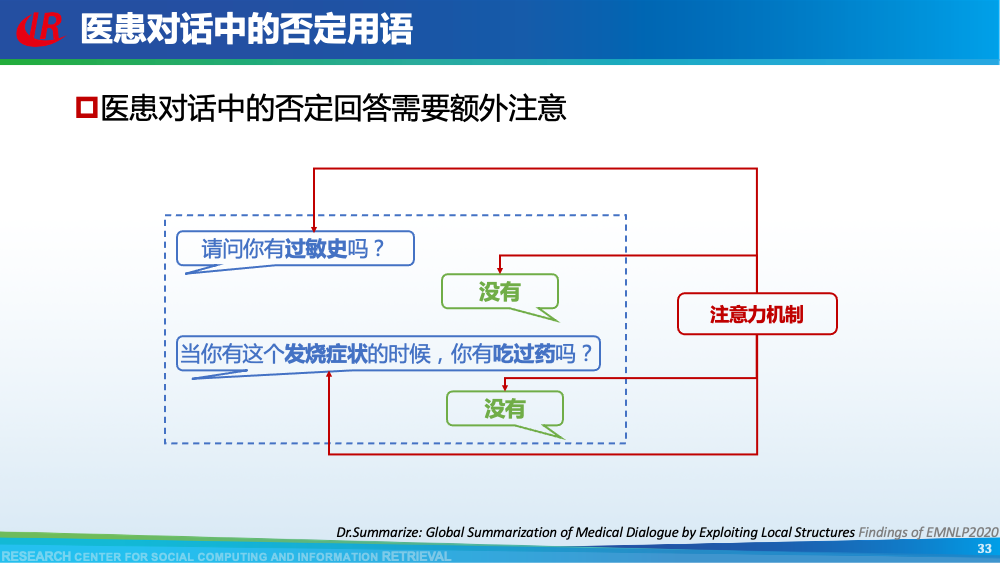
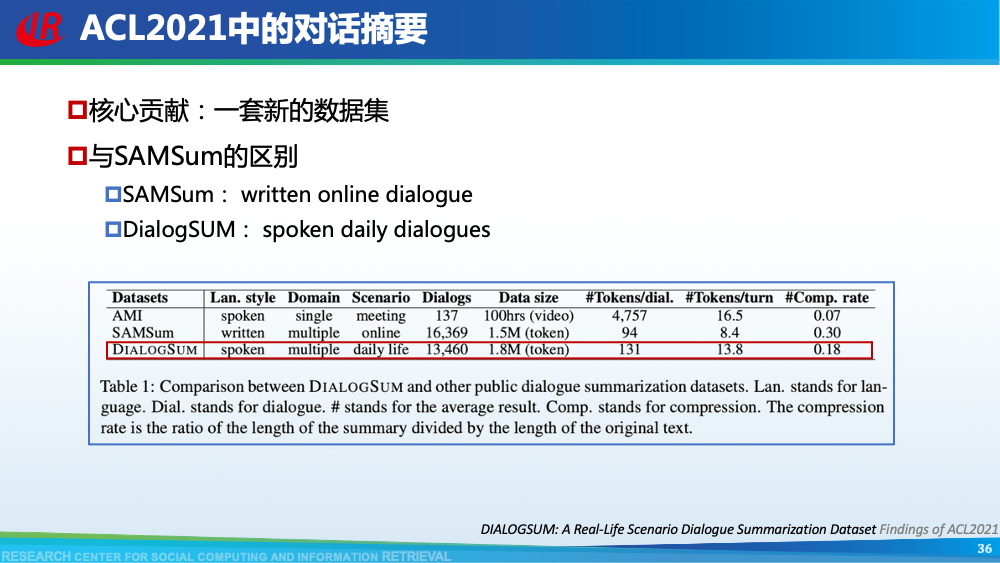
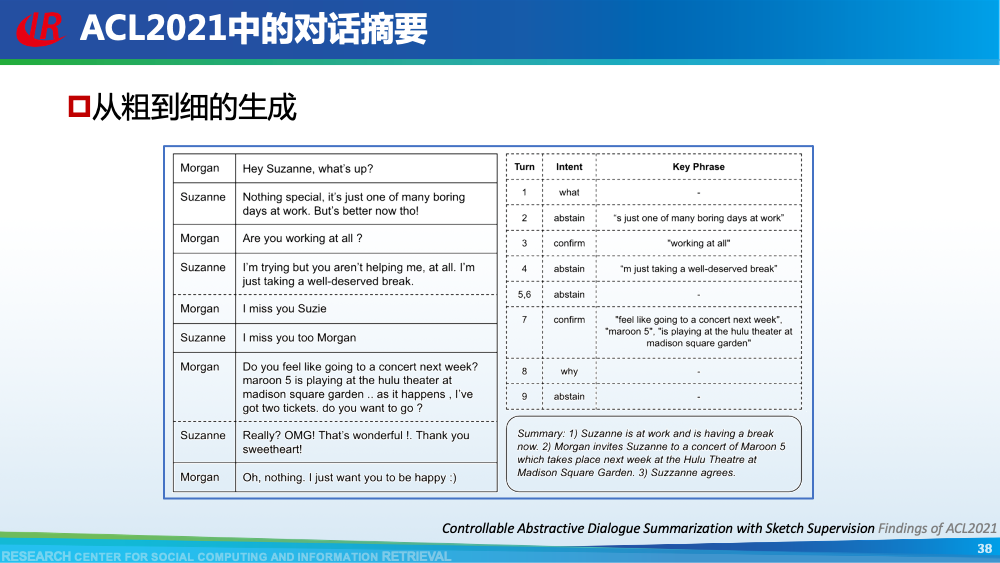
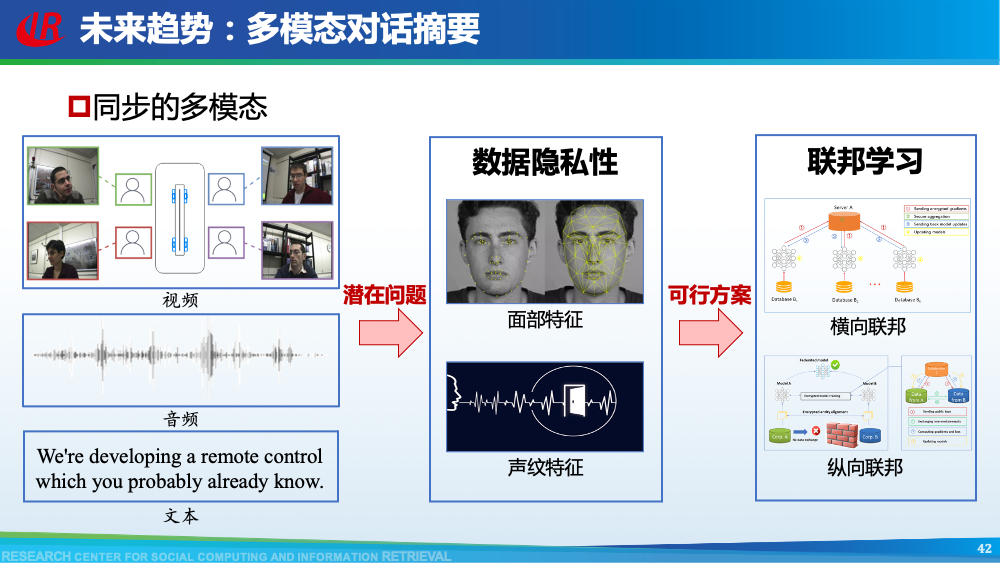
第二层挑战是对话建模的挑战。为了更好地理解对话,现有工作往往通过引入外部信息来更好的建模对话,例如:对话结构信息,主题信息等等。第一种对话结构信息是:对话行为。对话行为指示了句子在对话中的作用与影响。Goo等人采用多任务学习的框架,一方面进行句子级别的对话行为标注任务,另一方面进行摘要生成任务,通过注意力机制,利用对话行为信息辅助摘要生成任务。值得一提的是,Goo等人将主题信息作为摘要,而不是采用真实的摘要。另一种对话结构信息是:对话篇章结构信息。对话篇章结构信息指示了句子之间的交互关系,例如:问答、支持、反驳等。这种句子之间的交互关系是对话类型数据的显著特征。我们首先使用对话篇章结构解析器得到会议的对话篇章结构,然后我们借助图神经网络去显式的建模会议句子与篇章关系,整个摘要器为从图到序列的架构。更多细节可以参考我们的论文。主题信息是对话摘要任务中研究较为广泛的一种信息,因为主题漂移是对话类数据的显著特征。一个对话往往会包含多个主题,对话摘要需要去捕捉每一个主题的核心内容。针对闲聊对话,Jiaao Chen等人从四个方面去建模对话文本,分别是:对话级别(将对话视为一个词语序列),句子级别(讲对话视为一个句子序列),主题级别(将对话视为多个主题段)和阶段级别(将对话视多个演化段)。除了主题级别建模,阶段级别代表了一个对话的演化过程。结合四种建模方式,最终完成摘要生成。在医患对话中,主题往往体现为某一症状相关的内容,例如:头疼、肿胀等。Zhengyuan Liu等人在解码端采用两种注意力机制。一种是常见的词语级别的注意力机制,另一种是主题级别的注意力机制。其中,主题级别的注意力机制可以帮助模型在生成当前摘要句的时候关注于当前症状内容。区别于其他类型的文本,对话类文本包括了说话人(参与者)。更好的建模说话人可以帮助模型理解对话类文本。Yuejie Lei等人设计了两种注意力机制,一种是同一说话人之间的注意力机制,另一种是不同说话人之间的注意力机制,然后通过超参结合两种表示。从而获得考虑说话人信息之后的增强表示。在一段对话中,参与者往往通过自己的背景知识、常识知识去理解对话上文,从而做出回复。因此有很多工作已经证明了常识知识在对话回复生成和对话上下文建模中的有效性。我们探索了常识知识在对话摘要任务中应用。如图所示,通过“接我”和“车坏了”,可以推理得到“搭便车”这一背后蕴含的知识。因此引入常识知识可以帮助我们理解对话文本,生成更加抽象和凝练的摘要。我们通过ConceptNet引入知识,并将说话人,句子和知识视为三种不同类型的数据进行建模,最后实验证明了引入常识知识和异构性建模的有效性。更多细节可以参考我们的论文Incorporating Commonsense Knowledge into Abstractive Dialogue Summarization via Heterogeneous Graph Networks和Blog:融入常识知识的生成式对话摘要。除了文本模态的信息,多模态的信息也可以帮助我们更全面的理解对话数据。Manling Li等人研究了多模态会议摘要任务。其核心想法在于“当一个说话人在说话时,如果被其他人注视的时间越长,该说话人的信息越重要”,该特征被称为VFOA特征。因此首先训练一个VFOA特征抽取模型,然后将该视觉模态的表示与文本模态的表示相结合最终完成摘要任务。通过以上工作可以发现,前人工作往往通过引入外部信息来增强模型对于对话的理解,其中关键词,冗余句和主题分割是三种被证明有效的信息。然而之前的工作往往通过一个开放域工具获得这些标注,或者采用人工标注的方式。为了缓解这个问题,我们提出了一种基于预训练语言模型的、无监督的对话标注器。通过该标注器,我们可以为现有对话补充额外的信息。然后利用标注之后的对话训练摘要模型。更多细节可以参考我们的论文《Language Model as an Annotator: Exploring DialoGPT for Dialogue Summarization》。第三层挑战是领域特定的挑战,这部分主要关注不同类型的对话数据。会议往往具有专业性,因此在会议用语中“领域术语”常常出现。例如在计算机NLP学术会议中,常常出现预训练语言模型等术语,在医学会议中,常常出现药物等术语。通常这些术语又是数据集中的低频词汇,因此很难被有效建模。Koay等人经过实验发现,会议中的领域术语对于摘要生成非常重要。会议文本的另一特点是文本长度长,例如ICSI数据集的会议,平均长度为1w个词语。直接将所有输入词语视为平滑词语序列将耗费大量的内存,同时模型也无法很好地捕捉长距离依赖信息。因此Chenguang Zhu等人采用层次化Transformer架构,设计词语级别编码器和句子级别编码器来缓解这一问题。除此以外,Koay等人设计了一种滑动窗口机制来应对文本过长的挑战。将可以处理长序列的预训练模型(例如:Longformer,Big Bird等)应用于会议文本也是一种可行的方式。客服对话属于一种面向任务的对话,它往往内含了一种特定的逻辑结构:用户提出问题,客服给予解答,用户表示赞同与否,对话结束。Chunyi Liu等人设计了一种从粗粒度到细粒度的生成模型,首先生成关键词语序列代表对话的内在逻辑,然后再生成详细的摘要。在医患对话中,医生往往询问患者的病情情况。如图中所示,如果患者做出否定回答,那么只有将问题”请问你有过敏史“和回答”没有“同时考虑,才能生成正确的摘要,否则,如果忽略否定回答,现有的语言模型极有可能将问题解读为正向回答。Anirudh Joshi等人设计了一种注意力机制要求同时关注问题与否定回答,帮助生成更加精确的摘要。虽然ACL 2021的论文接收列表还未放出,但是我们已经从arXiv和Github上看到了一些对话摘要相关的论文,在这里简要概述一下。Yulong Chen等人提出了一个新的数据集,不同于之前的SAMSum是一种侧重于”书面“对话的摘要数据集,其核心点在于”口语“对话。Kundan Krishna等人提出了一种”抽取-聚类-生成“的框架来生成医疗对话的摘要。
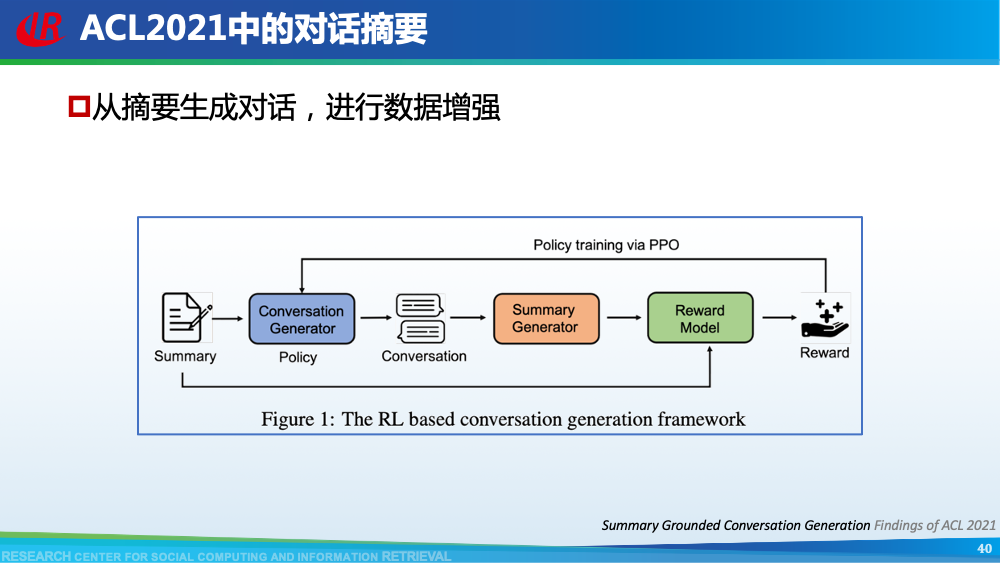
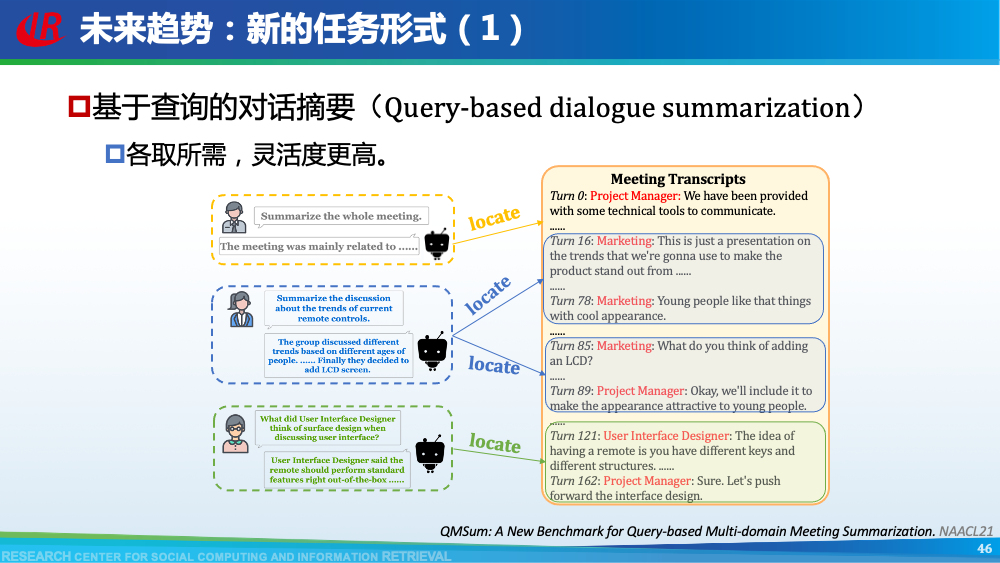
Chien-Sheng Wu等人提出了一种由粗粒度到细粒度的对话摘要生成方式,其首先生成对话梗概,然后再生成最终摘要。Alexander R. Fabbri等人提出了四套数据集,分别涉及四个领域,并且整理了之前的工作作为未来研究的benchmark。Chulaka Gunasekara等人提出从摘要生成对话,从而为对话摘要进行数据增强。