在TensorFlow中对比两大生成模型:VAE与GAN(附测试代码)

来源:机器之心
本文长度为3071字,建议阅读6分钟
本文在 MNIST 上对VAE和GAN这两类生成模型的性能进行了对比测试。
项目链接:https://github.com/kvmanohar22/ Generative-Models
变分自编码器(VAE)与生成对抗网络(GAN)是复杂分布上无监督学习最具前景的两类方法。
本项目总结了使用变分自编码器(Variational Autoencode,VAE)和生成对抗网络(GAN)对给定数据分布进行建模,并且对比了这些模型的性能。你可能会问:我们已经有了数百万张图像,为什么还要从给定数据分布中生成图像呢?正如 Ian Goodfellow 在 NIPS 2016 教程中指出的那样,实际上有很多应用。我觉得比较有趣的一种是使用 GAN 模拟可能的未来,就像强化学习中使用策略梯度的智能体那样。
本文组织架构:
变分自编码器(VAE)
生成对抗网络(GAN)
训练普通 GAN 的难点
训练细节
在 MNIST 上进行 VAE 和 GAN 对比实验
在无标签的情况下训练 GAN 判别器
在有标签的情况下训练 GAN 判别器
在 CIFAR 上进行 VAE 和 GAN 实验
延伸阅读
VAE
变分自编码器可用于对先验数据分布进行建模。从名字上就可以看出,它包括两部分:编码器和解码器。编码器将数据分布的高级表征映射到数据的低级表征,低级表征叫作本征向量(latent vector)。解码器吸收数据的低级表征,然后输出同样数据的高级表征。
从数学上来讲,让 X 作为编码器的输入,z 作为本征向量,X′作为解码器的输出。
图 1 是 VAE 的可视化图。
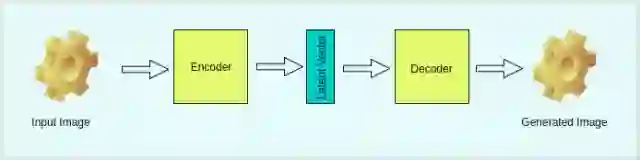
图 1:VAE 的架构
这与标准自编码器有何不同?关键区别在于我们对本征向量的约束。如果是标准自编码器,那么我们主要关注重建损失(reconstruction loss),即:

而在变分自编码器的情况中,我们希望本征向量遵循特定的分布,通常是单位高斯分布(unit Gaussian distribution),使下列损失得到优化:

p(z′)∼N(0,I) 中 I 指单位矩阵(identity matrx),q(z∣X) 是本征向量的分布,其中
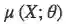
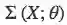
由于损失函数中还有其他项,因此存在模型生成图像的精度,同本征向量的分布与单位高斯分布的接近程度之间存在权衡(trade-off)。这两部分由两个超参数λ_1 和λ_2 来控制。
GAN
GAN 是根据给定的先验分布生成数据的另一种方式,包括同时进行的两部分:判别器和生成器。
判别器用于对「真」图像和「伪」图像进行分类,生成器从随机噪声中生成图像(随机噪声通常叫作本征向量或代码,该噪声通常从均匀分布(uniform distribution)或高斯分布中获取)。生成器的任务是生成可以以假乱真的图像,令判别器也无法区分出来。也就是说,生成器和判别器是互相对抗的。判别器非常努力地尝试区分真伪图像,同时生成器尽力生成更加逼真的图像,目的是使判别器将这些图像也分类为「真」图像。
图 2 是 GAN 的典型结构。
图 2:GAN
生成器包括利用代码输出图像的解卷积层。图 3 是生成器的架构图。

图 3:典型 GAN 的生成器图示(图像来源:OpenAI)
训练 GAN 的难点
训练 GAN 时我们会遇到一些挑战,我认为其中最大的挑战在于本征向量/代码的采样。代码只是从先验分布中对本征变量的噪声采样。有很多种方法可以克服该挑战,包括:使用 VAE 对本征变量进行编码,学习数据的先验分布。这听起来要好一些,因为编码器能够学习数据分布,现在我们可以从分布中进行采样,而不是生成随机噪声。
训练细节
我们知道两个分布 p(真实分布)和 q(估计分布)之间的交叉熵通过以下公式计算:
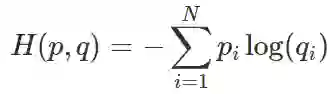
-
对于二元分类:

-
对于 GAN,我们假设分布的一半来自真实数据分布,一半来自估计分布,因此:

训练 GAN 需要同时优化两个损失函数。
按照极小极大值算法:

这里,判别器需要区分图像的真伪,不管图像是否包含真实物体,都没有注意力。当我们在 CIFAR 上检查 GAN 生成的图像时会明显看到这一点。
我们可以重新定义判别器损失目标,使之包含标签。这被证明可以提高主观样本的质量。如:在 MNIST 或 CIFAR-10(两个数据集都有 10 个类别)。
上述 Python 损失函数在 TensorFlow 中的实现:
def VAE_loss(true_images, logits, mean, std): """ Args: true_images : batch of input images logits : linear output of the decoder network (the constructed images) mean : mean of the latent code std : standard deviation of the latent code """ imgs_flat = tf.reshape(true_images, [-1, img_h*img_w*img_d]) encoder_loss = 0.5 * tf.reduce_sum(tf.square(mean)+tf.square(std) -tf.log(tf.square(std))-1, 1) decoder_loss = tf.reduce_sum(tf.nn.sigmoid_cross_entropy_with_logits( logits=logits, labels=img_flat), 1) return tf.reduce_mean(encoder_loss + decoder_loss)def GAN_loss_without_labels(true_logit, fake_logit): """ Args: true_logit : Given data from true distribution, `true_logit` is the output of Discriminator (a column vector) fake_logit : Given data generated from Generator, `fake_logit` is the output of Discriminator (a column vector) """ true_prob = tf.nn.sigmoid(true_logit) fake_prob = tf.nn.sigmoid(fake_logit) d_loss = tf.reduce_mean(-tf.log(true_prob)-tf.log(1-fake_prob)) g_loss = tf.reduce_mean(-tf.log(fake_prob)) return d_loss, g_lossdef GAN_loss_with_labels(true_logit, fake_logit): """ Args: true_logit : Given data from true distribution, `true_logit` is the output of Discriminator (a matrix now) fake_logit : Given data generated from Generator, `fake_logit` is the output of Discriminator (a matrix now) """ d_true_loss = tf.nn.softmax_cross_entropy_with_logits( labels=self.labels, logits=self.true_logit, dim=1) d_fake_loss = tf.nn.softmax_cross_entropy_with_logits( labels=1-self.labels, logits=self.fake_logit, dim=1) g_loss = tf.nn.softmax_cross_entropy_with_logits( labels=self.labels, logits=self.fake_logit, dim=1) d_loss = d_true_loss + d_fake_loss return tf.reduce_mean(d_loss), tf.reduce_mean(g_loss)
在 MNIST 上进行 VAE 与 GAN 对比实验
1. 不使用标签训练判别器
我在 MNIST 上训练了一个 VAE。代码地址:https://github.com/kvmanohar22/Generative-Models
实验使用了 MNIST 的 28×28 图像,下图中:
左侧:数据分布的 64 张原始图像
中间:VAE 生成的 64 张图像
右侧:GAN 生成的 64 张图像
第 1 次迭代:

第 2 次迭代:

第 3 次迭代:

第 4 次迭代:

第 100 次迭代:

VAE(125)和 GAN(368)训练的最终结果:

根据GAN迭代次数生成的gif图:

显然,VAE 生成的图像与 GAN 生成的图像相比,前者更加模糊。这个结果在预料之中,因为 VAE 模型生成的所有输出都是分布平均。为了减少图像的模糊度,我们可以使用 L1 损失来代替 L2 损失。
在第一个实验后,作者还将在近期研究使用标签训练判别器,并在 CIFAR 数据集上测试 VAE 与 GAN 的性能。
使用
下载 MNIST 和 CIFAR 数据集
使用 MNIST 训练 VAE 请运行:
python main.py --train --model vae --dataset mnist
使用 MNIST 训练 GAN 请运行:
python main.py --train --model gan --dataset mnist
想要获取完整的命令行选项,请运行:
python main.py --help
该模型由 generate_frq 决定生成图片的频率,默认值为 1。
GAN 在 MNIST 上的训练结果
MNIST 数据集中的样本图像:

上方是 VAE 生成的图像,下方的图展示了 GAN 生成图像的过程:
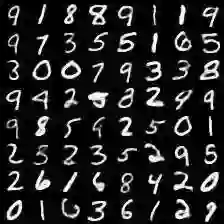
延伸阅读
Tutorial on Variational Autoencoders by Carl Doersch
NIPS 2016 Tutorial: Generative Adversarial Networks (pdf) by Ian Goodfellow
NIPS 2016 - Generative Adversarial Networks (video) by Ian Goodfellow
NIPS 2016 Workshop on Adversarial Training - How to train a GAN by Soumith Chintala
原文链接:https://kvmanohar22.github.io/Generative-Models/
校对:朱江华峰
为保证发文质量、树立口碑,数据派现设立“错别字基金”,鼓励读者积极纠错。
若您在阅读文章过程中发现任何错误,请在文末留言,或到后台反馈,经小编确认后,数据派将向检举读者发8.8元红包。
同一位读者指出同一篇文章多处错误,奖金不变。不同读者指出同一处错误,奖励第一位读者。
感谢一直以来您的关注和支持,希望您能够监督数据派产出更加高质的内容。




