资源 | NIPS 2017 Spotlight论文Bayesian GAN的TensorFlow实现
选自GitHub
作者:Andrew Gordon Wilson
机器之心编译
参与:路雪、刘晓坤
用生成模型学习高维自然信号(比如图像、视频和音频)长期以来一直是机器学习的重要发展方向之一。来自 Uber AI Lab 的 Yunus Saatchi 等人今年五月提出了 Bayesian GAN——利用一个简单的贝叶斯公式进行端到端无监督/半监督 GAN 学习。该研究的论文已被列入 NIPS 2017 大会 Spotlight。最近,这篇论文的另一作者 Andrew Gordon Wilson 在 GitHub 上发布了 Bayesian GAN 的 TensorFlow 实现。
项目链接:https://github.com/andrewgordonwilson/bayesgan/
论文:Bayesian GAN

论文链接:https://arxiv.org/abs/1705.09558
摘要:生成对抗网络(GAN)可以隐性地学习难以用显性似然(explicit likelihood)建模的图像、音频和数据的丰富分布。我们展示了一种实际的贝叶斯公式,用 GAN 进行无监督和半监督学习。在该框架下,我们使用随机梯度哈密尔顿蒙特卡罗(Hamiltonian Monte Carlo)来边缘化生成器和判别器的权重。得到的方法很直接,且可在没有标准干预(如特征匹配或小批量判别)的情况下达到不错的性能。通过探索生成器参数具有表达性的后验,贝叶斯 GAN 避免了模式崩溃(mode-collapse),输出可解释的多种候选样本,在 SVHN、CelebA 和 CIFAR-10 等多个基准数据集上取得了顶尖的半监督学习量化结果,优于 DCGAN、Wasserstein GAN 和 DCGAN。
介绍
在贝叶斯 GAN 中,我们提出了生成器和判别器权重的条件后验,通过随机梯度哈密尔顿蒙特卡罗边缘化这些后验。贝叶斯 GAN 的主要特性有:(1)在半监督学习问题上的准确预测;(2)对优秀性能的最小干预;(3)响应对抗反馈的推断的概率公式;(4)避免模式崩溃;(5)展示多个互补的生成和判别模型,形成一个概率集成(probabilistic ensemble)。
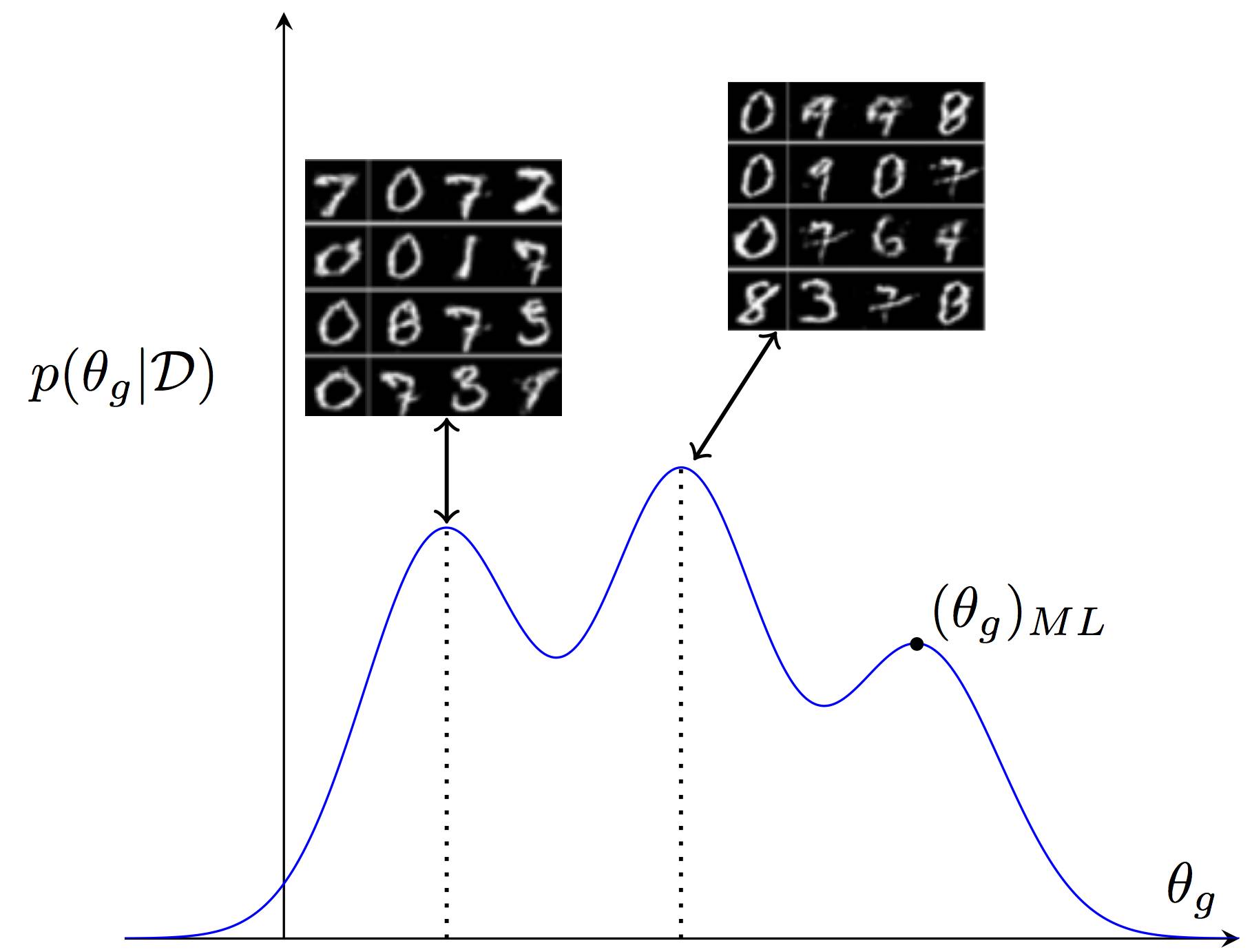
我们介绍了一个生成器参数的多模态后验。这些参数的每个设置对应数据的不同生成假设。这里我们将展示两种权重向量设置下生成的样本,不同的权重向量设置对应不同的写作风格。贝叶斯 GAN 保留该参数分布。相反,标准 GAN 用点估计(类似最大似然解决方案)来展示整个分布,降低了数据的可解释性。
环境需求
该代码有以下依赖项(版本号很关键)
python 2.7
tensorflow==1.0.0
在 Linux 上安装 TensorfFow 1.0.0,请按照 https://www.tensorflow.org/versions/r1.0/install/说明进行操作。
scikit-learn==0.17.1
你可以使用下列命令安装 scikit-learn 0.17.1:
pip install scikit-learn==0.17.1
或者,使用提供的 environment.yml 文件创建 conda 环境,并进行设置:
conda env create -f environment.yml -n bgan
然后,使用下列命令加载环境:
source activate bgan
训练选项
bayesian_gan_hmc.py 具备以下训练选项。
--out_dir:文件夹路径,用于存储输出
--n_save: 每 n_save 次迭代存储的样本和权重;默认值 100
--z_dim: 生成器 z 向量的维度;默认值 100
--data_path:数据路径;具体讨论详见 https://github.com/andrewgordonwilson/bayesgan/#data-preparation;该参数是必需的
--dataset:可以是 mnist、cifar、svhn 或 celeb;默认 mnist
--gen_observed: 生成器「观察到」的数据;影响噪声变量和先验的缩放;默认值 1000
--batch_size:训练的批量大小;默认值 64
--prior_std:权重先验分布的 std;默认值 1
--numz:和论文中的 J 一样; z 的样本数,实现整合;默认值 1
--num_mcmc: 和论文中的 M 一样;每个 z 的 MCMC NN 权重样本数;默认值 1
--lr: Adam 优化器使用的学习率;默认值 0.0002
--optimizer:使用的优化方法:adam (tf.train.AdamOptimizer) 或 sgd (tf.train.MomentumOptimizer);默认 adam
--semi_supervised:进行半监督学习
--N:半监督学习所需标注样本数量
--train_iter:训练迭代次数;默认值 50000
--save_samples:保存训练过程中生成的样本
--save_weights:训练过程中,保存权重
--random_seed:随机种子;如果使用 GPU,那么注意设置该种子不会引起 100% 的可复现结果
你还可以用--wasserstein 运行 WGAN,或用--ml_ensemble <num_dcgans> 训练 <num_dcgans> DCGAN 的集成。尤其是,你可以使用--ml_ensemble 1 训练一个 DCGAN。
使用
安装
1. 安装所需依赖项
2. 复制该 repository
合成数据
你可以使用 bgan_synth 脚本运行论文中的合成实验。例如,以下命令用于训练贝叶斯 GAN(D=100,d=10),进行 5000 次迭代,并把结果保存在<results_path>。
./bgan_synth.py --x_dim 100 --z_dim 10 --numz 10 --out <results_path>
运行以下命令使用相同的数据运行 ML GAN:
./bgan_synth.py --x_dim 100 --z_dim 10 --numz 1 --out <results_path>
bgan_synth 的参数有 --save_weights、--out_dir、--z_dim、--numz、--wasserstein、--train_iter 和 --x_dim。x_dim 控制观测数据(论文中的 x)的维度。通过这个链接查看其它参数的说明:https://github.com/andrewgordonwilson/bayesgan/#training-option。
运行了上面的两个命令之后,你可以在<results_path>里查看每 100 次迭代后的输出。例如,第 900 次迭代的贝叶斯 GAN 的输出结果如下:
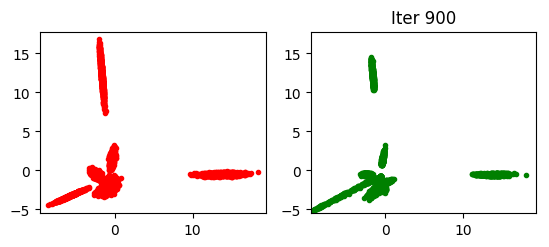
相对地,标准 GAN(numz=1,强制执行 ML 评估)的输出结果如下:
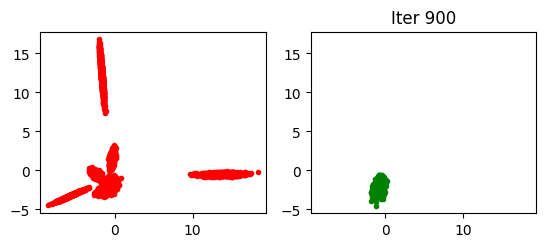
可以清晰地看到在这个合成数据的例子中,标准 GAN 出现了模式崩溃的趋势,而贝叶斯 GAN 完全没有这样的问题。
你可以查看 synth.iptnb,进一步探索合成实验,并生成詹森-香农差异图。
MNIST、CIFAR10、CELEBA、SVHN
bayesian_gan_hmc 脚本允许在标准和自定义数据集上训练模型。下面,我们将介绍如何使用该脚本。
数据准备
为了重现在 MNIST、CIFAR10、CelebA 和 SVHN 数据集上的实验,你需要准备这些数据,并使用一个正确的——data_path。
对于 MNIST,你不需要准备数据,并可以提供任意的——data_path;
对于 CIFAR10,请从该地址(https://www.cs.toronto.edu/~kriz/cifar.html)下载和获取数据的 Python 版本;然后使用包含 cifar-10-batchs-py 的目录的路径作为——data_path;
对于 SVHN,请从该地址(http://ufldl.stanford.edu/housenumbers/)下载 train_32x32.mat 和 test_32x32.mat 文件,并使用包含这些文件的目录的路径作为——data_path;
对于 CelebA,你需要安装 OpenCV。数据下载地址:http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html。你需要创建 celebA 文件夹,该文件夹包含 Anno 和 img_align_celeba 子文件夹。其中 Anno 必须包含 list_attr_celeba.txt,img_align_celeba 必须包含.jpg 文件。你还需要通过在——data_path <path>(其中<path>是包含了 celebA 的文件夹的路径)中运行 datasets/crop_faces.py 脚本对图像进行剪裁。训练模型的时候,你需要在——data_path 中使用相同的<path>。
无监督学习
你可以在没有 -- semi 参数的情况下通过运行 bayesian_gan_hmc 脚本对模型进行无监督训练。例如,使用以下命令:
./bayesian_gan_hmc.py --data_path <data_path> --dataset svhn --numz 1 --num_mcmc 10 --out_dir
<results_path> --train_iter 75000 --save_samples --n_save 100
在 SVHN 数据集上训练模型。该命令会使用这个方法执行 75000 次迭代,每 100 次迭代保存样本。这里<results_path>必须是保存结果的目录。可查看数据准备部分,了解如何设置<data_path>。可查看训练选项部分,了解其它训练选项。

半监督训练
你可以使用--semi 选项来运行 bayesian_gan_hmc,对模型进行半监督训练。使用-N 参数设置训练所用标注样本的数量。例如,使用
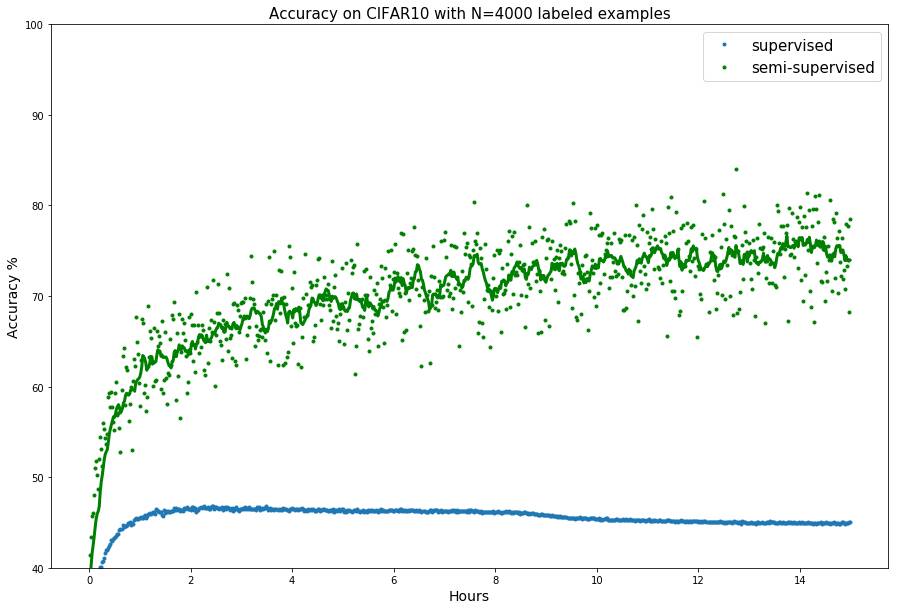
./bayesian_gan_hmc.py --data_path <data_path> --dataset cifar --numz 1 --num_mcmc 10
--out_dir <results_path> --train_iter 75000 --N 4000 --semi --lr 0.00005
在 CIFAR10 数据集上用 4000 个标注样本训练该模型。该命令使训练经历 75000 次迭代,输出结果储存在<results_path> 文件夹中。
要想在 MNIST 数据集上使用 200 个标注样本训练该模型,你需要使用以下命令:
./bayesian_gan_hmc.py --data_path <data_path>/ --dataset mnist --numz 5 --num_mcmc 5
--out_dir <results_path> --train_iter 30000 -N 200 --semi --lr 0.001
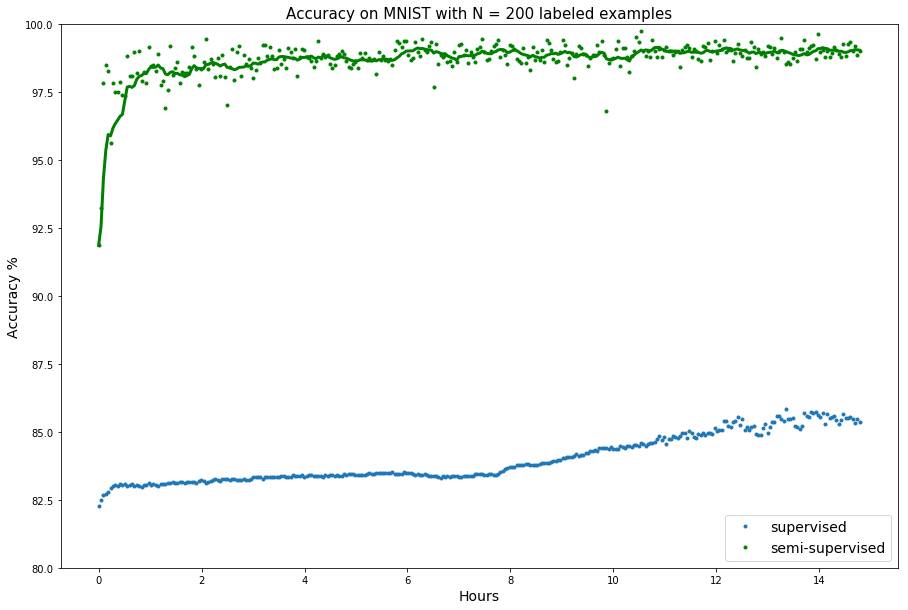
自定义数据
要想在自定义数据集上训练该模型,你需要用特定的接口定义类别。假设我们想在 digits 数据集上训练模型。该数据集包含 8x8 数字图像。假设数据的储存格式为 x_tr.npy、y_tr.npy、x_te.npy 和 y_te.npy。我们假设 x_tr.npy 和 x_te.npy 的形态为 (?, 8, 8, 1)。然后在 bgan_util.py 中定义该数据集对应的类别,如下所示:
class Digits:
def __init__(self):
self.imgs = np.load('x_tr.npy')
self.test_imgs = np.load('x_te.npy')
self.labels = np.load('y_tr.npy')
self.test_labels = np.load('y_te.npy')
self.labels = one_hot_encoded(self.labels, 10)
self.test_labels = one_hot_encoded(self.test_labels, 10)
self.x_dim = [8, 8, 1]
self.num_classes = 10
@staticmethod
def get_batch(batch_size, x, y):
"""Returns a batch from the given arrays.
"""
idx = np.random.choice(range(x.shape[0]), size=(batch_size,), replace=False)
return x[idx], y[idx]
def next_batch(self, batch_size, class_id=None):
return self.get_batch(batch_size, self.imgs, self.labels)
def test_batch(self, batch_size):
return self.get_batch(batch_size, self.test_imgs, self.test_labels)
该类别必须具备 next_batch 和 test_batch,以及 imgs、labels、test_imgs、test_labels、x_dim 和 num_classes。
现在,我们可以把 Digits 类输入到 bayesian_gan_hmc.py:
from bgan_util import Digits
将下列行添加至处理--dataset 参数的代码中:
if args.dataset == "digits":
dataset = Digits()
准备过程完成后,我们可以使用以下命令训练模型:
./bayesian_gan_hmc.py --data_path <any_path> --dataset digits --numz 1 --num_mcmc 10
--out_dir <results path> --train_iter 5000 --save_samples
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com




