为让AI同时读懂图与文,微信搞起了多模态认知和推理


语用层面的隐蔽。即具体场景下,语言背后的“真实意图”。例如,“屋里太冷了”真实意图其实是“把窗户关一下”。
语义层面的抽象。例如,“红色”是抽象概念,而非实际物质,我们可以在现实世界中找到各种红色的实体物质,而找不到“红色”这种物质。
语法/符号层面的歧义。例如,“苹果”可以是水果,也可以是手机;“武汉市长江大桥”是经典的切分歧义例子。

探索一:视频场景中的多轮对话生成技术
问题定义
问题输入
问题输出
具体示例
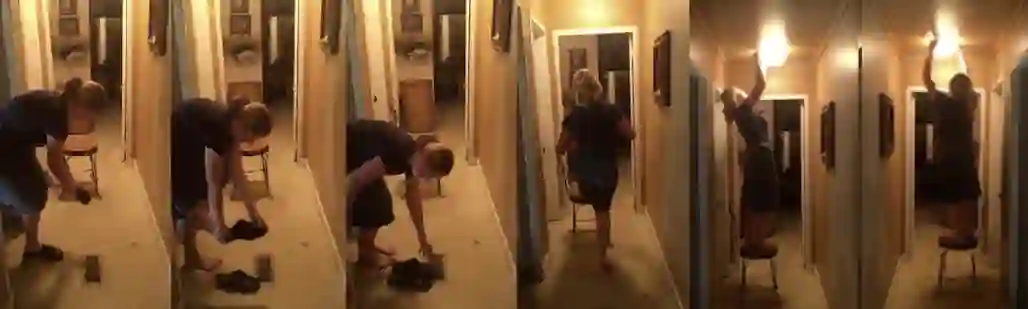
Caption: A woman standing in a hallway takes off her slippers. Shethen climbs on a chair and starts doing something with the ceiling light.
Summary: A woman about 30 years old wearing a jean skirt and top is standing on a stool and fixing something in the hallway next to a door. The hallway has linoleum floors.
Q1: where is the video happening ?
A1: it is happening inside in the hallway.
Q2: are there any people in the video ?
A2: yes there is one person in the video.
…
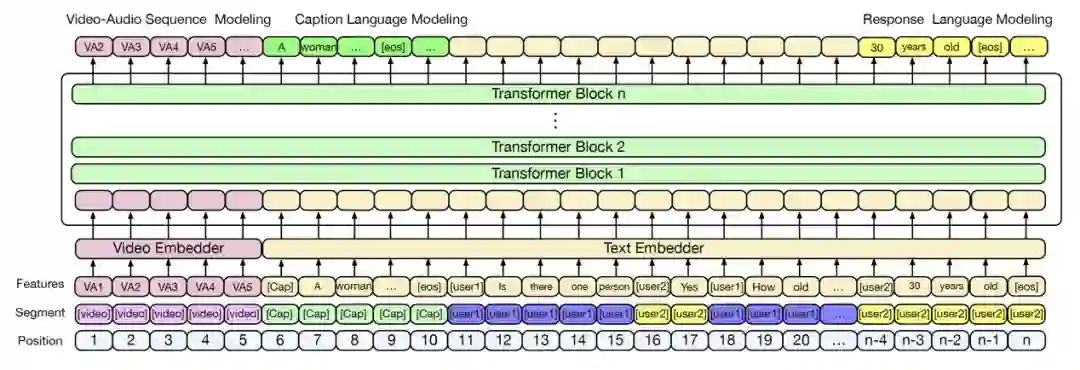
技术方法
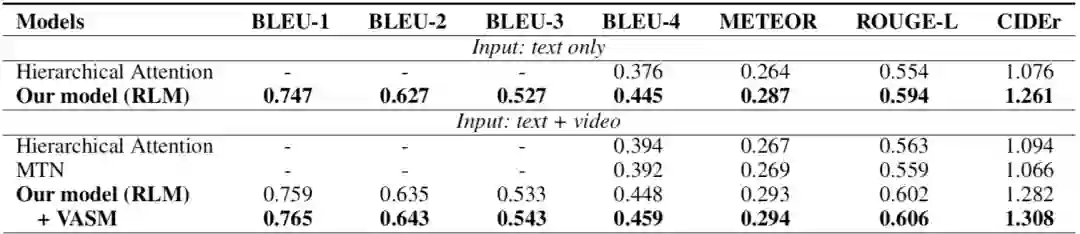
实验结论

探索二:设计对偶通道的多跳推理机制提升视觉对话性能
问题定义
问题输入
问题输出
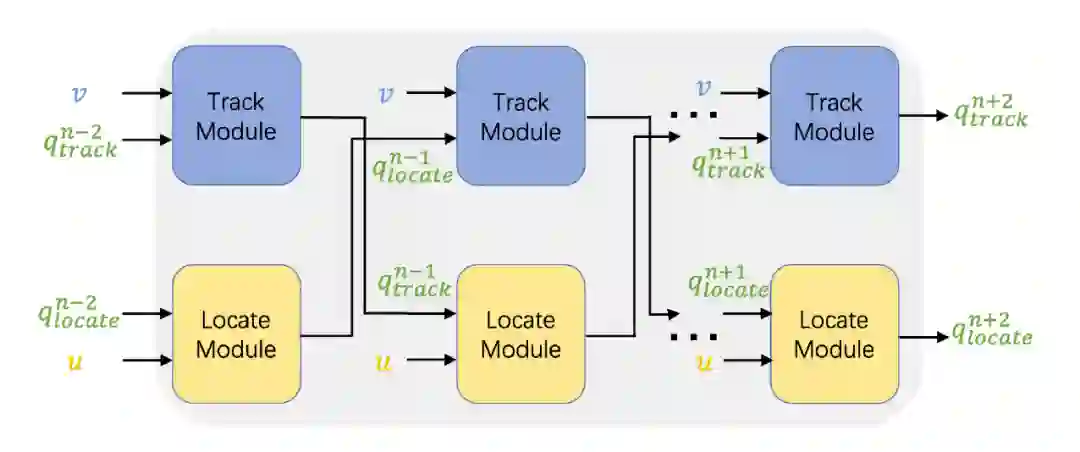
技术方法
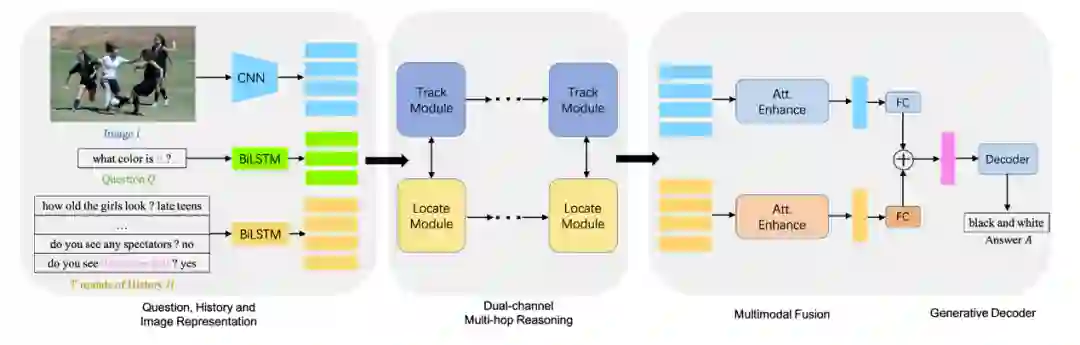
使用CNN和Bi-LSTM分别对视觉模态的图片和文字模态的对话历史及问题,进行特征表示。
所有的模态特征表示会经过一个对偶通道的多步推理模块进行迭代的多跳交互。
多模态的特征经过多跳交互后,会通过一个注意力机制进行模态融合,最后输入到解码器里生成对话回复。
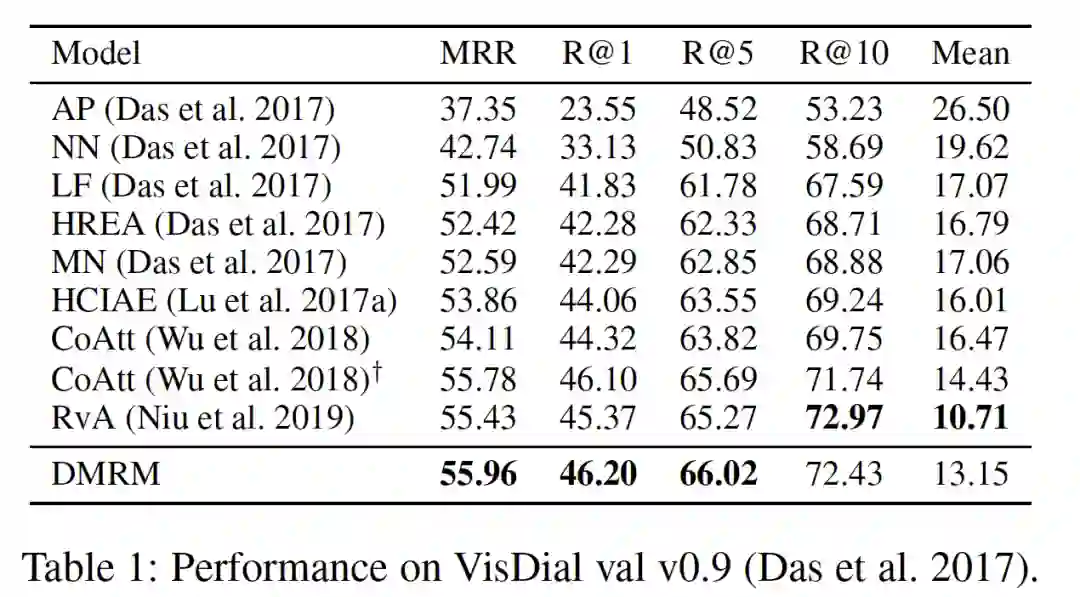
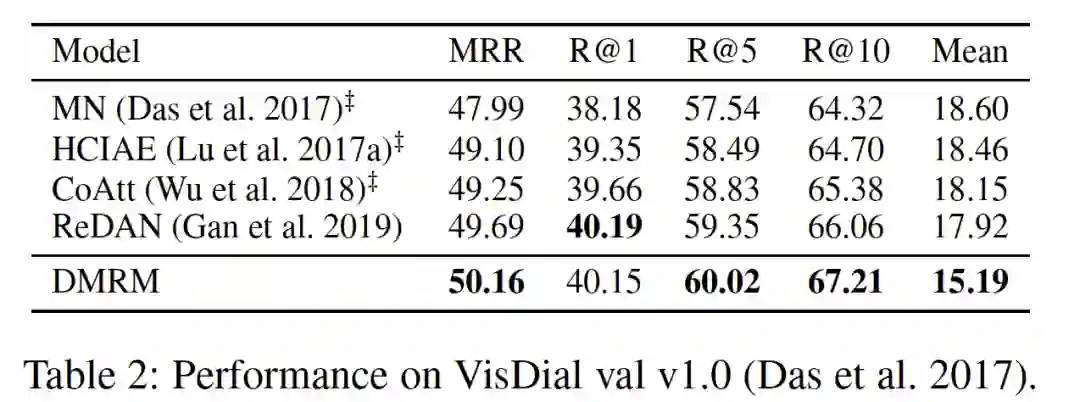
实验结论

探索三:基于胶囊神经网络的多模态机器翻译
问题定义
问题输入
问题输出
技术方法
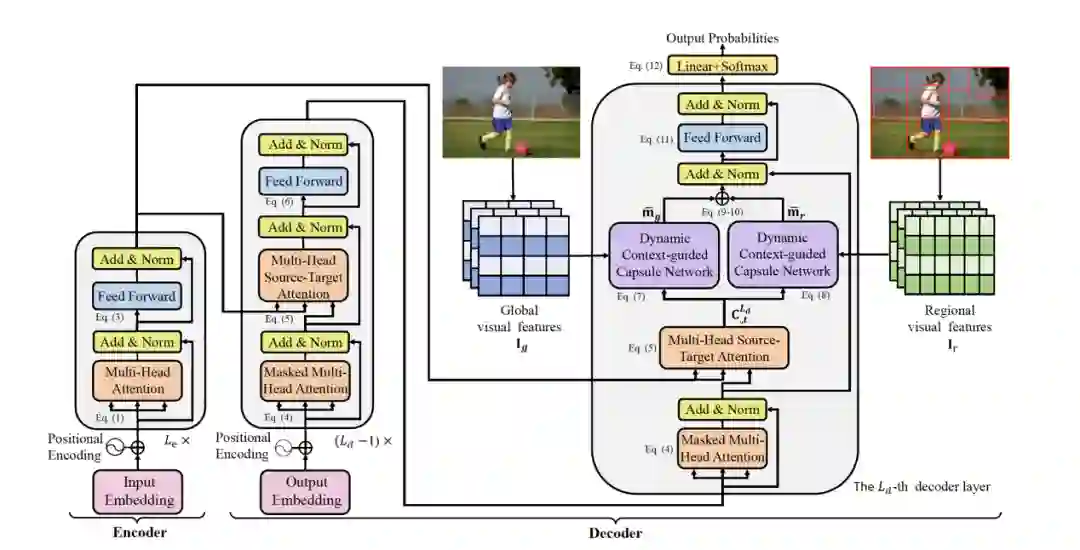
timestep-specific:在解码的不同时间步,关注图片中的不同部分。
两个DCCN,分别负责处理图片的全局特征和局部特征(如上图中的两张照片所示),是传统胶囊网络的改良版,保留了传统capsule的迭代特征提取的优势。
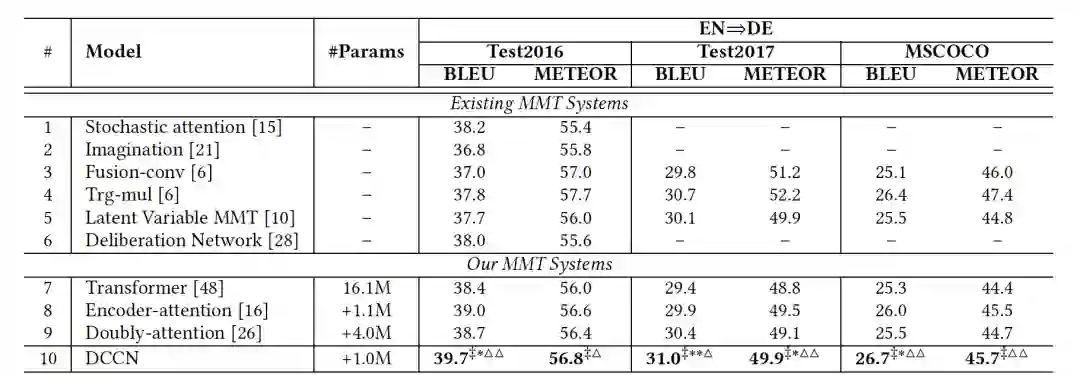
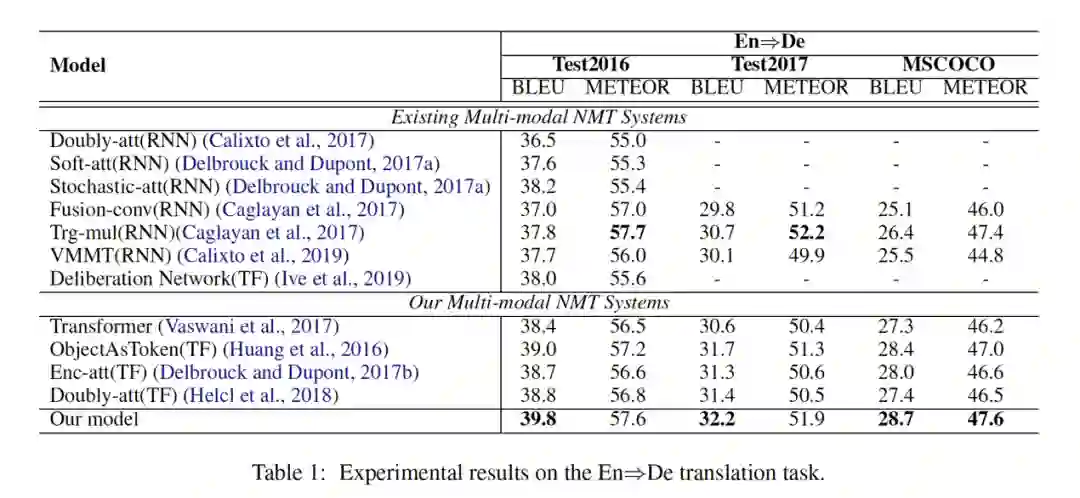
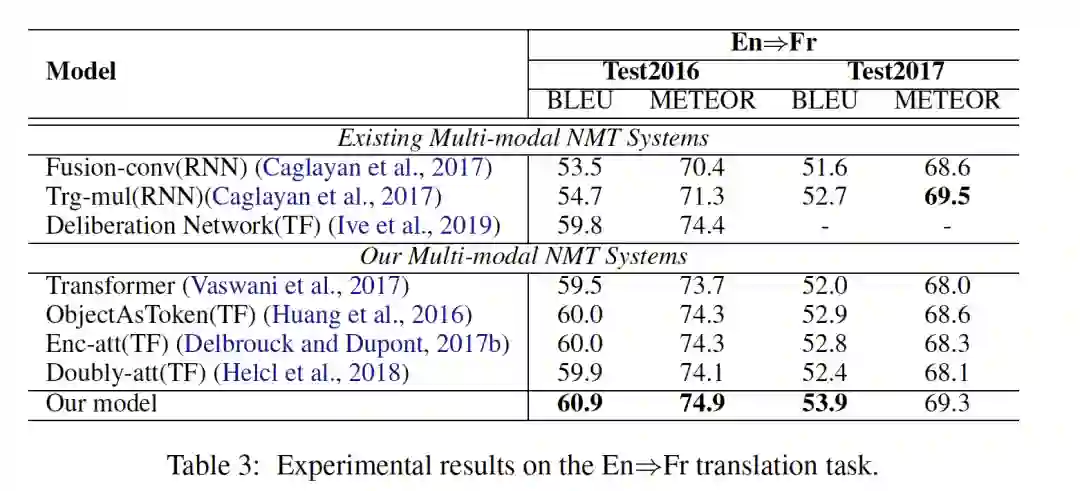
实验结论
探索四:基于图神经网络的多模态机器翻译
问题定义
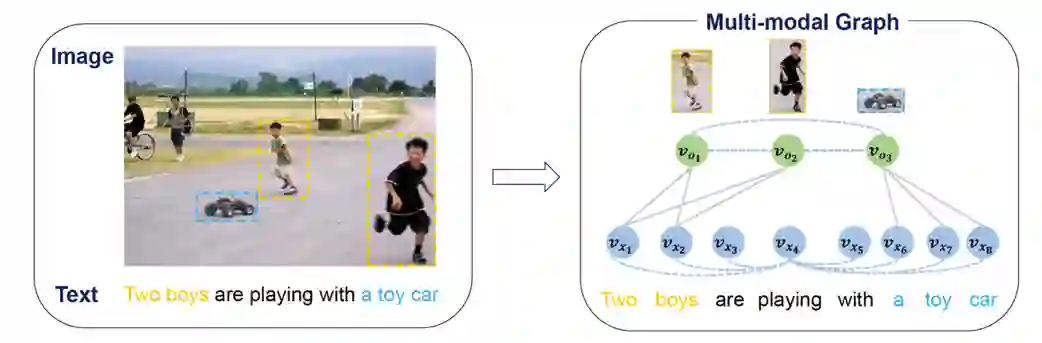
问题输入
问题输出
技术方法
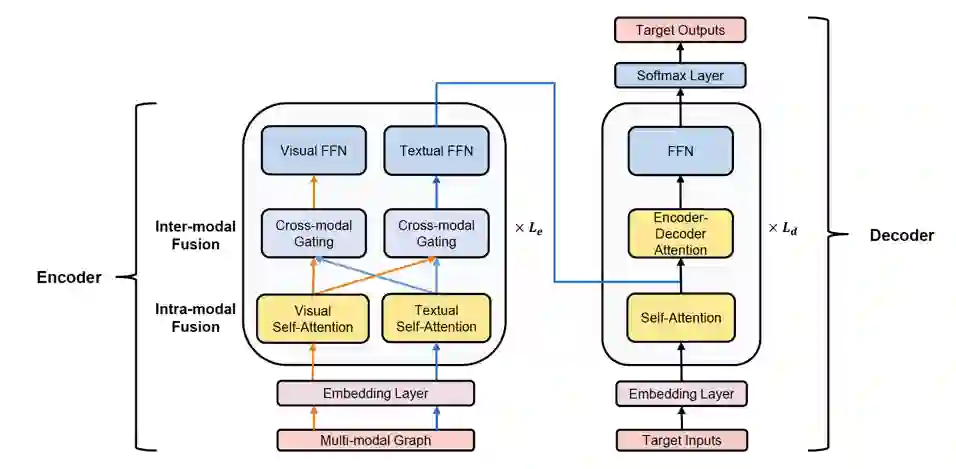
实验结论
结束语
微信AI
不描摹技术的酷炫,不依赖拟人的形态,微信AI是什么?是悄无声息却无处不在,是用技术创造更高效率,是更懂你。
微信AI关注语音识别与合成、自然语言处理、计算机视觉、工业级推荐系统等领域,成果对内应用于微信翻译、微信视频号、微信看一看等业务,对外服务王者荣耀、QQ音乐等产品。