《科技日报》专访 | 我国研发首个千亿参数三模态大模型“紫东太初”

近日,中国科学院自动化研究所展示了自动化所研发的业内首个千亿参数三模态大模型“紫东太初”。
大模型在人工智能发展中的方位是什么?大模型为什么要做开源开放?……
针对这些问题,科技日报记者专访了中国科学院自动化研究所所长徐波。
记者:大模型在人工智能发展中的方位是什么?
徐波:人类智能是人与环境不断交互并通过几百万到几千万年进化而成。因此从智能生成角度看,人工智能目前主要有三条路径在不断快速发展中。大脑是人类智能进化的主体,研究受脑结构和功能启发的类脑智能,是人工智能路径之一;从智能进化客体环境出发,研究智能体与环境通过奖赏性交互、并实现对环境认知和适应的博弈智能,是人工智能路径之二,如AlphaGo等。
智能主体与环境客体交互过程中,会产生大量数据产生和知识沉淀,尤其是从信息化、数字化时代产生的大数据中学习内在关联,即为我们最为熟悉的第三条路径即数据智能。目前人工智能发展最为迅速、应用最为广泛的为数据智能。图灵奖得主Yann LeCun认为 “自监督学习是通过观察发现世界内在结构的过程,是人类(以及动物)最主要的学习形式,是‘智力的本质’”。
目前数据智能正从高度依赖标注数据的有监督学习,向不依赖注释、自动学习数据间的关系的自监督范式发展。在形成智能表征能力基础上,通过适量标注数据进一步产生推理和生成能力。通过大数据自监督锤炼的大模型具备很强大的多任务泛化能力。
自动化所与武汉东湖高新区共同打造新一代通用人工智能平台,以全栈国产化基础软硬件昇腾AI平台为基础,依托武汉人工智能计算中心,研发了面向超大规模的高效分布式人工智能训练框架,在图、文、音三个基础模型上加入跨模态编码和解码网络,基于昇思MindSpore框架,打造了业内首个千亿参数三模态大模型“紫东太初”。该大模型首次贯通了语音、图像、文字,并自动学习跨模态数据之间的关系,通过自监督学习和知识嵌入来解决小数据泛化和理解问题,形成了完整的智能的表示、推理和生成能力,是当前数据智能领域的最新发展。紫东太初不但具有很大的产业应用价值,也为探索人类智能本质提供了一个极佳的平台。

记者:大模型为什么要做开源开放?
徐波:现在产业都在讲算法开源,但算法的维护成本很高,尤其是在现在人工智能人才十分稀缺的情况下。而未来,人工智能领域开放的可能将会是模型,客户获得大模型的接口,再稍微加一点数据就能解决问题,即“大模型+小数据”,这是我们希望看到的大模型对产业带来的赋能。开源开放有利于推动新一代人工智能生态体系发展,有利于更好地培养和输出新一代人工智能人才,更有利于加速推动人工智能应用规模化落地。
自动化所目前已经开源“紫东太初”三个基础模型:语言预训练、语音预训练和视觉预训练三大基础模型。在多模态模型中开源了中文图文理解模型和中文图文生成模型。后续将陆续开源多模态训练十亿、百亿模型,并开放千亿模型。
记者:有语音加入的三模态大模型紫东太初将带来哪些变革?
徐波:当前的预训练模型,仍以单模态(文本、图像)或者图像-文本联合学习的双模态为主,忽略了我们周边存在大量的声音信息。针对这一问题,紫东太初大模型首次将语音信息引入,形成多模态统一知识表示。一个大模型就可以灵活支撑图、文、音的全场景AI应用,能更加接近人类真正的感情和思考,灵活性更高,通用性更强。我们可以看图生音教孩子们学习拼音;也可以通过语音识别远程操作智能装备来执行任务。
在华为全联接大会上,自动化所依托紫东太初研发的虚拟人“小初”也展示了在实际工业场景通过语音图像融合提升生产力的技术亮点。以纺织工业生产为例,“小初”能够通过摄像头看纺织机织出来布来判断质量是否有缺陷,通过听纺织机运行过程中的声音判断是否存在经纬线断的情况发生,验布速度达到人工的4倍,且精度大于90%(人工验布精度约为70-80%)。
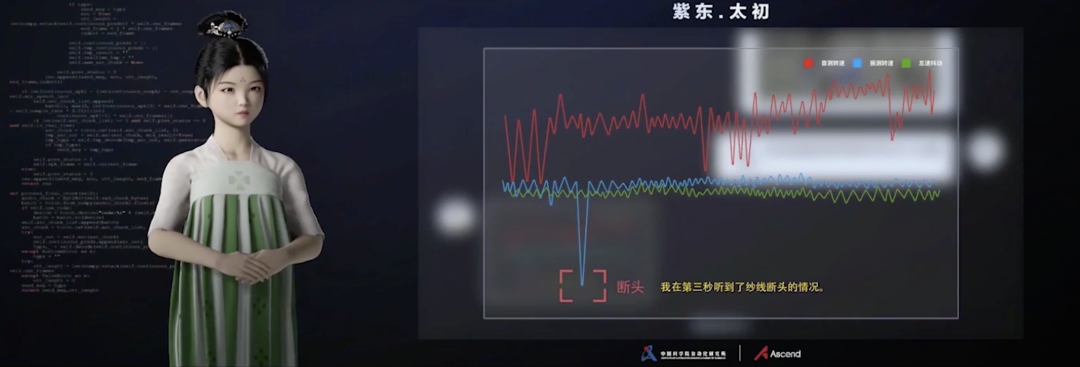
记者:“视频生成”为什么时至今日才变成现实?
徐波:我们研发的紫东太初大模型通过多模态大数据自监督学习已形成图、文、音的共性特征表达,并可根据任务难度用适量数据产生推理能力和生成能力,可实现多任务、跨模态持续学习。
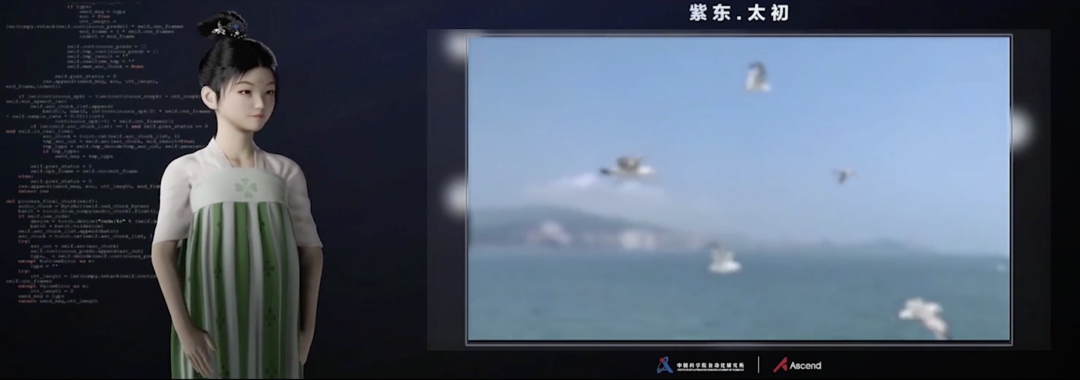
更为突破的是,紫东太初大模型通过有效编码语音、文本和目标区域之间的时空关系,首次实现了“语音生成视频”的功能。此前,OpenAI发布的模型DALL·E通过文字创建绘画、照片、草图等图像,展示了大模型在以文生图方面具有了一定类人的艺术想象力和创造性。而现在,紫东太初大模型打通语音与图像、文本间的阻隔,成功通过语音生成视频,进一步提升了人工智能的创造力,迈出朝向人工智能通用化的关键一步。
在华为全联接2021上,自动化所展示了紫东太初大模型的视频生成能力,生成了一段具有大海、蓝天和海鸥的视频。其中,紫东太初大模型通过海量数据的学习,将海浪的声音、海鸥的叫声等进行了跨模态的编码,有效地提高生成视频的真实度,充分显示了紫东太初的类人的想象力和创造性。
记者:大模型能否解决AI应用的碎片化和落地难问题?如何赋能产业?
徐波:人工智能正处于从“可以用”逐渐走向“好用”的落地应用阶段,但目前仍处于商业落地早期,主要面临着场景需求碎片化、人力研发和应用计算成本高、模型算法从实验室场景到真实场景效果差距大等行业痛点。大部分AI项目落地还停留在“手工作坊”阶段。
为了应对这种挑战性问题,采用预训练大模型+推理部署端小模型的技术路线可有效解决这个问题。具体来说,经过海量多模态数据训练,大模型得以具备很强的基准性能,能够基于行业需求进行专家知识和少量样本微调,快速适配满足各种下游任务。对于计算资源受限的场景,我们可以将模型压缩出侧重不同功能属性的海量小模型,以便更快地推进企业在不同下游场景中实现AI模型落地应用。
人工智能由于行业数据壁垒高获取难、不同场景任务需求理解各不相同、复合型人才短缺等问题导致商业化落地难的问题,总体而言随着大模型技术发展,这方面的门槛会大大降低。我们预计大模型将在3-5年时间里开始真正深刻影响产业的变革和智能化升级的方向。
来源 |《科技日报》
记者 |马爱平
相关阅读
点击即可查看
自动化所千亿级三模态大模型“紫东太初” 首次实现语音生成视频等功能
观点 | 多模态大模型成为AI基础设施,模型研发从“手工作坊”迈入工业化生产时代
徐波所长专访:构建全球首个三模态大模型“紫东太初”,类人智能的大门正在打开
多模态大模型——通用人工智能路径的探索
自动化所研发全球首个图文音三模态预训练模型,让AI更接近人类想象力!
欢迎后台留言、推荐您感兴趣的话题、内容或资讯!
如需转载或投稿,请后台私信。






