十大深度学习热门论文(2018年版)
编者按:深度学习是机器学习和统计学的一个分支领域,在过去几年里,它因为一些突出成果开始出现在大众视野中,并给人们留下了深刻印象。对于这些技术突破,它背后的Robust开源工具、云计算以及大量可用的数据功不可没。本文依据academic.microsoft.com的论文引用次数列出了今年最热门的十大深度学习论文,希望能给读者提供有价值的阅读参考。
注:引用次数数值为2018年4月20日前数据。

在这份论文清单中,超过75%的文章涉及深度学习和神经网络,其中卷积神经网络(CNN)的比重格外出众,而计算机视觉论文的占比也有50%。在前人优秀论文的指引下,随着TensorFlow、Theano等开源软件库的日益完善和GPU等硬件的不断发展,相信未来数据科学家和机器学习工程师的学习工作之路将是一片坦途。
1. Deep Learning

作者:Yann L., Yoshua B. , Geoffrey H. (2015)
引用次数:5716
深度学习允许由多个处理层组成的计算模型来学习具有多个抽象级别的数据表示。这种方法极大地改进了语音识别、视觉对象识别、对象检测和诸如药物发现和基因组学等许多其他领域的最新技术。通过反向传播算法,深度学习能捕捉大型数据集中的复杂结构,并在前一个处理层的基础上改变内部参数获得一个能表示前者的全新处理层。深度卷积网络在处理图像、视频、语音和音频方面取得了突破,并点亮了连续数据处理,如文本和语音的发展道路。
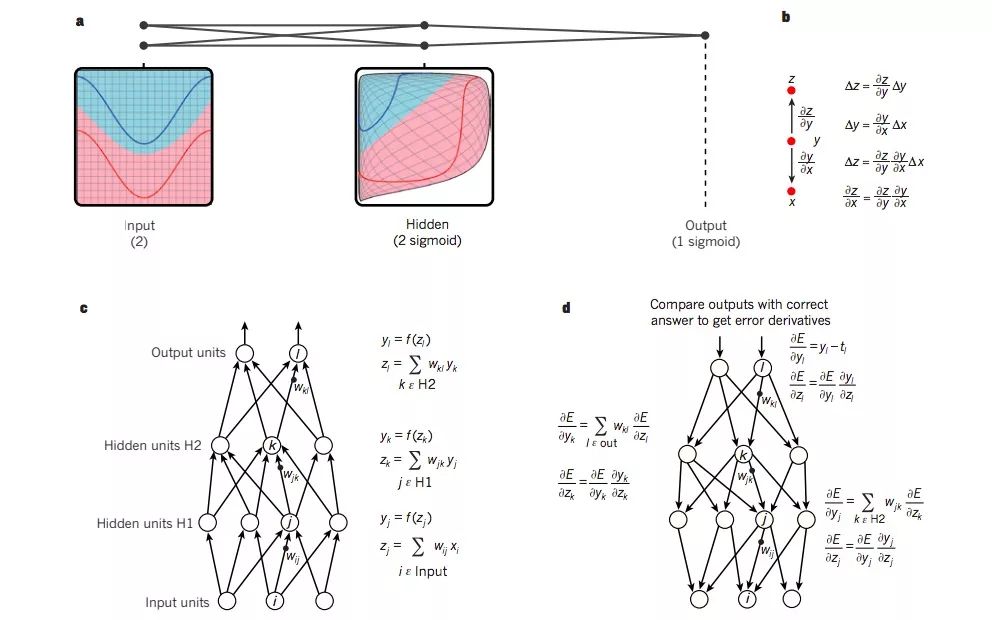
图a是一个普通的感知器(黑点表示神经元),它通过使输入空间失真,从而让数据的类别(红蓝曲线)实现线性分离。请注意输入空间中的网格(如左图所示)是如何通过隐藏节点进行变形的(如中间图所示)。该多层神经网络只包含两个输入、两个隐藏节点和一个输出,但在实践过程中,用于对象识别和自然语言处理的神经网络通常会包含数十或数十万个单元。
图c和图d是神经网络反向传播的具体计算过程。
PDF:www.cs.toronto.edu/~hinton/absps/NatureDeepReview.pdf
2. TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems

作者:Martín A., Ashish A. B., Eugene B. C., et al. (2015)
引用次数:2423
TensorFlow是一个机器学习算法的接口,它也是这些算法的实现平台。从移动设备(手机、平板电脑等)到数百台大型分布式系统,再到由数千个GPU构成的计算设备,仅需少量修改(甚至无需修改),用户就能轻松把在TensorFlow上实现的算法放到这些异构系统中执行。这个系统是非常灵活的,它可以表达包括深度神经网络模型的训练、推理算法在内的各种算法,并且已经在十几个计算机科学研究领域的机器学习系统中有了广泛应用,其中包括语音识别、计算机视觉、机器人技术、信息检索、自然语言处理、地理信息提取和计算药物发现等。

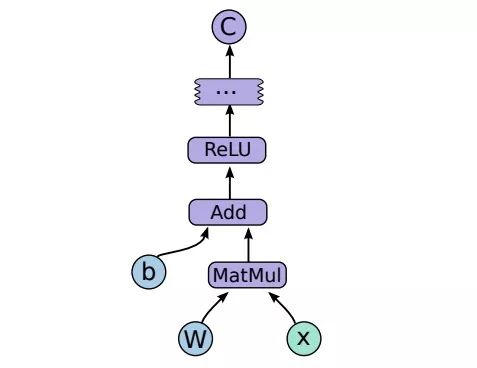
在上图中,每个节点都有0个/多个输入和0个/多个输出,表示箭头计算操作的结果。我们把那些顺着数据流图计算(从输入到输出)“流动”的值称为张量,这是一个N阶的数组,它的基础数据类型可以是一开始就指定好的,也可以是一开始推理的结果。
图中有一些叫control dependencies的特殊带箭头线段,没有数据沿着它们流动,但它们明确表示了源节点和目标节点的计算指定顺序。这反映了TensorFlow的灵活可变性,用户可以通过插入命令强制为各个独立操作排序,这也有助于控制峰值内存的使用情况。
PDF:download.tensorflow.org/paper/whitepaper2015.pdf
3. TensorFlow: a system for large-scale machine learning

作者:Martín A., Paul B., Jianmin C., Zhifeng C., Andy D. et al. (2016)
引用次数:2227
TensorFlow是一个可以在大规模和异构环境中运行的机器学习系统。它用数据流图表示计算、共享状态以及改变该状态的操作。通过把数据流图的节点映射到群集中的多台机器上,TensorFlow能跨越多个分布式设备调用多核CPU、GPU和TPU的算力,从而实现大规模的训练和推理。这种架构为开发者提供了便利:在之前的参数服务器中,共享状态管理内置在系统中,而TensorFlow则为用户提供了尝试新的优化和训练算法的可能性。它支持各种应用程序,尤其是深度神经网络的训练和推理。
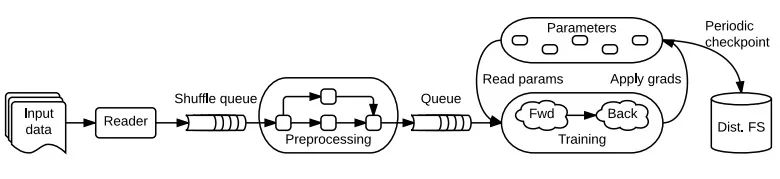
TensorFlow使用单个数据流图表来表示在机器学习算法中的所有计算和状态,包括各个数学运算、参数及其更新规则、输入处理(如上图所示)。 数据流使得子计算之间的通信变得明确,因此易于并行执行独立计算,并且将计算跨越多个分布式设备。
TensorFlow数据流与批处理系统有两个方面的不同:
支持重叠子图上的并发执行。
单个顶点可具有可变状态,这些状态在图的不同执行之间共享。
参数服务器架构中的关键—可变状态。因为当训练大模型时,可对大量参数就地更新,并快速将这些更新传播到并行训练中。具有可变状态的数据流使TensorFlow能够模拟参数服务器的功能,同时具有额外的灵活性,因为可在托管共享模型参数的机器上执行任意数据流子图。 因此,用户已经能够尝试不同的优化算法、一致性方案和并行化策略。
以上描述内容引用自:lib.csdn.net/article/aiframework/57886
PDF:www.usenix.org/system/files/conference/osdi16/osdi16-abadi.pdf
4. Deep learning in neural networks

作者:Juergen Schmidhuber (2015)
引用次数:2196
近年来,深层人工神经网络(包括循环网络)在模式识别和机器学习等方面赢得了众多竞赛。本综述简明扼要地总结了这一技术的相关工作,其中大部分来自上个世纪,从1940年到60-80年代,再到80-90年代。为了描述得更深入浅出,本文在常规分类之余又依据影响力做了划分,以便读者从行为和效果两方面建立学习的因果关系。深度监督学习(包括反向传播算法历史)、无监督学习、强化学习、进化策略等是本文的主要关注对象。
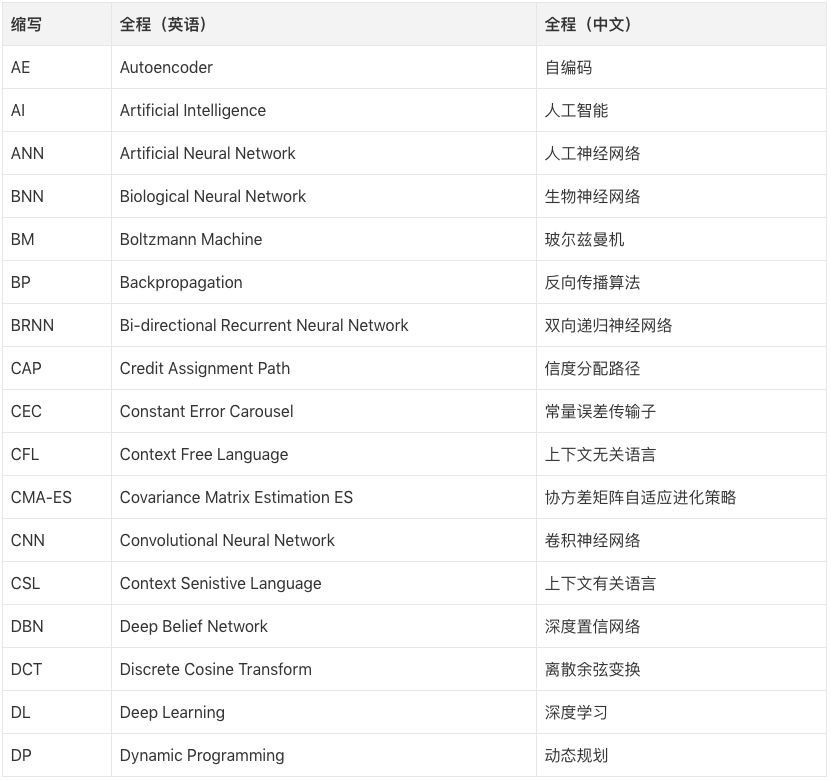
文中部分缩略词表:
PDF:arxiv.org/pdf/1404.7828.pdf
5. Human-level control through deep reinforcement learning(DQN)

作者:Volodymyr M., Koray K., David S., Andrei A. R., Joel V et al (2015)
引用次数:2086
这是DeepMind团队在2015年发表在science上的一篇文章,被誉为深度强化学习的开山鼻祖。
文章指出当强化学习智能体面对一个很难的任务时,它们必须从高维度的感知输入中提取出环境的高效描述。对于这种情况,人和动物一般会结合学习和有层次的感觉处理系统找出解决方案,但过去的强化学习算法智能应对全部可观测的、低维的特定任务,而无法扩展到未知的、高维的任务中。
本文提出了一种deep Q-network,它将强化学习和深度神经网络结合起来,使深度神经网络具有从裸数据中提取特征的能力。换句话说,就是它可以直接从高维输入中学习优秀策略,并进行端到端的强化学习。在Atari游戏实验中,DQN算法在只输入原始图像像素和游戏得分的情况下学会了玩游戏,并且达到了人类专业玩家的水平。
PDF:web.stanford.edu/class/psych209/Readings/MnihEtAlHassibis15NatureControlDeepRL.pdf
6. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks

作者:Shaoqing R., Kaiming H., Ross B. G. & Jian S. (2015)
引用次数:1421
目前最先进的目标检测网络需要先用区域建议算法推测目标位置,像SPPnet和Fast R-CNN这些网络已经减少了检测网络的运行时间,这时计算区域建议就成了瓶颈问题。本文介绍了一种区域建议网络(Region Proposal Network, RPN),它和检测网络共享全图的卷积特征,从而实现无时间成本的区域建议。RPN是一个全卷积网络,在每个位置同时预测目标边界和objectness得分。RPN是端到端训练生成高质量的区域建议框,用于Fast R-CNN检测。通过一种简单的交替运行优化方法,RPN和Fast R-CNN可以在训练时共享卷积特征。
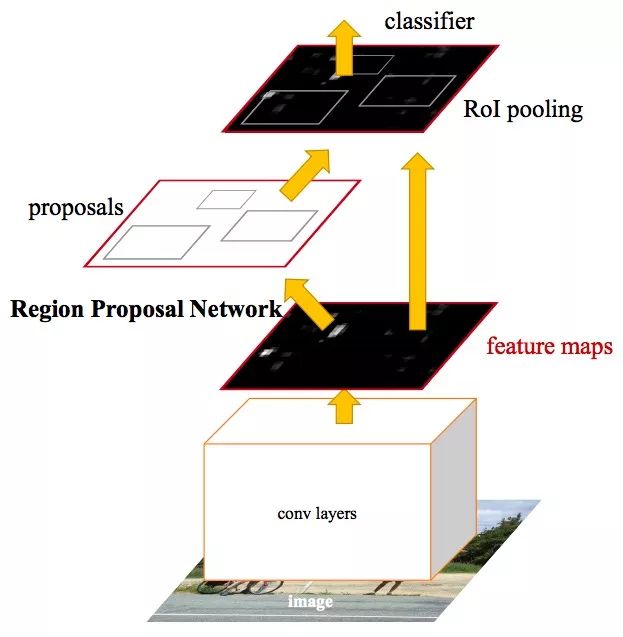
这个对象检测系统称为Faster R-CNN,它由两个模块组成。第一个模块是深度完全卷积网络的建议区域(RPN),它决定了模型“往哪里看”——它将一个任意大小图像作为输入,并输出一组矩形目标建议框,每个框有一个objectness得分。第二个模块是使用Fast R-CNN的建议区域,它利用输入将边界框里的内容分类(或标记成“背景”标签丢弃它),并调整边界框的坐标,使其更适合目标对象。整个系统是一个统一的物体检测网络,结合了最近流行的神经网络术语“注意力”机制。
论文中译版(摘要来源):blog.csdn.net/lwplwf/article/details/74906205
PDF:arxiv.org/pdf/1506.01497.pdf
7. Long-term recurrent convolutional networks for visual recognition and description

作者:Jeff D., Lisa Anne H., Sergio G., Marcus R., Subhashini V. et al. (2015)
引用次数:1285
近期深度卷积网络模型在图像说明任务中非常流行,因此本文测试了它在其他涉及序列、图像任务中的效果。本文介绍了一类可以端对端训练的、适用于大规模图片理解工作的递归卷积网络,证明它们可被用于行为识别、图片描述和视频描述。
对比于之前的假定一个固定的图片表示或者运用简单的时间序列来进行序列处的模型,递归卷积模型学习空间和时间的组合表示“倍增”了。当非线性被引入网络状态更新时,学习长时依赖成为可能。可微的递归网络之所以吸引人,是因为它们能直接将变长输入(视频)映射为变长输出(自然语言文本),能够模拟复杂的动态时序;目前能够通过反向传播进行优化。
本文的递归序列模型是直接和当前图片卷积网络连接的,能够联合训练以学习动态时序和卷积表征。本文结果显示这样的模型相对于现有模型在用于单独定义或优化的识别、生成任务上,有明显优势。
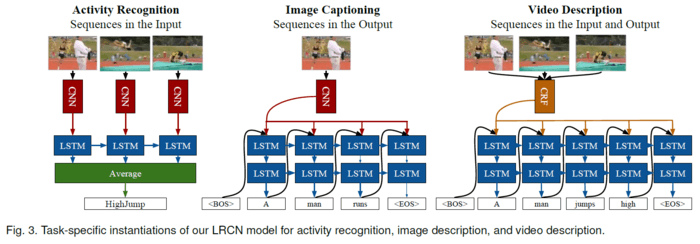
本文通过3个实验设置去实例化提出来的模型。第一,传统卷积模型直接和深LSTM网络向量,我们能够训练捕捉时态状态依赖项的视频识别模型。然而现有标记的视频行为数据集可能没有特定的复杂行为的时序动态,但是我们仍对传统benchmark进行了提升。
第二,我们研究了一个从图像到语义的端对端可训练的映射。机器翻译最近取得了很多成果,这类模型是基于LSTM的编码-解码对。我们提出了这个模型的多模型模拟,描述了一个结构,该结构利用图片的ConvNet去编码一个深度状态向量,一个LSTM解码该向量为一个自然语言字符串。最终模型能够用于大规模图片和文本数据集的端对端训练,即使是不完全训练,对比于现有方法,也能得到一个较好的生成结果。
第三,本文显示,LSTM解码器能直接从传统的预测高级标签的计算机视觉方法上加以运用,例如语义视频角色数组预测。这类模型在结构和性能上优于原来的基于统计机器翻译的方法。
描述来源(简书):www.jianshu.com/p/abe840207dbe
PDF:arxiv.org/pdf/1411.4389.pdf
8. MatConvNet: Convolutional Neural Networks for MATLAB

作者:Andrea Vedaldi & Karel Lenc (2015)
引用次数:1148
MatConvNet是一个可以实现CNN的MATLAB工具箱。它的设计注重简单性和灵活性,通过把CNN构件块转换为易于使用的MATLAB函数,并提供filter组件和特征池化等工具,MatConvNet能快速构建CNN模型,同时,它也支持在CPU、GPU高效计算基于大型数据集(如ImageNet ILSVRC)的复杂模型。本文档概述了CNN及其在MatConvNet中的实现方式,并给出了工具箱中每个计算块的技术细节。
PDF:arxiv.org/pdf/1412.4564.pdf
9. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks(DCGAN)

作者:Alec R., Luke M. & Soumith C. (2015)
引用次数:1054
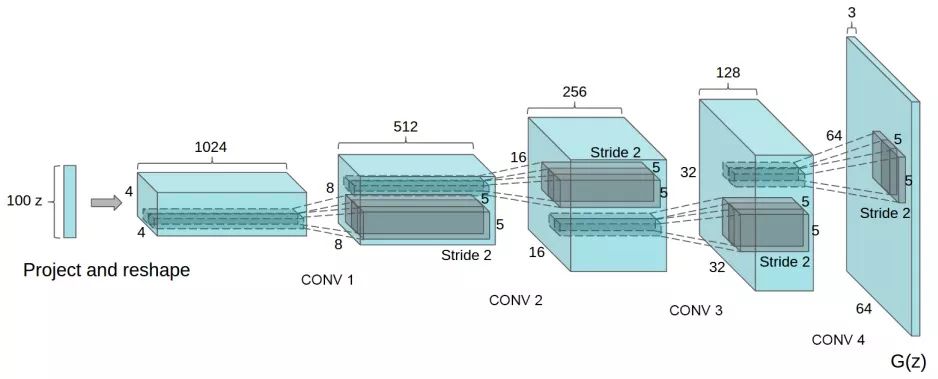
近年来,监督学习式的卷积神经网络(CNN)在计算机视觉任务中得到了广泛的应用,但相比之下,无监督学习的CNN受到的关注较少。因此本文希望能够探讨监督学习CNN和无监督学习CNN之间的差距。本文引入了一类名为深层卷积生成对抗网络(DCGAN))的CNN,它具有一定的架构约束,算得上是最好的无监督学习CNN。在各种数据集上完成训练后,实验证明DCGAN的生成器和判别器都捕捉到了对象、场景中的视觉信息表示层次,它在一般图像上也表现出了优秀的适用性。
论文中译版:blog.csdn.net/liuxiao214/article/details/73500737
PDF:arxiv.org/pdf/1511.06434.pdf
10. U-Net: Convolutional Networks for Biomedical Image Segmentation

作者:Olaf R., Philipp F. &Thomas B. (2015)
引用次数:975
相对ImageNet等通用数据集,医学图像数据集较小。如何在小数据集情况下训练出一个好的模型,是深度学习在医学图像方面的一个难点。本文提出了一种神经网络和训练策略,它依靠大量使用数据增强,能实现高效、充分利用标记样本。
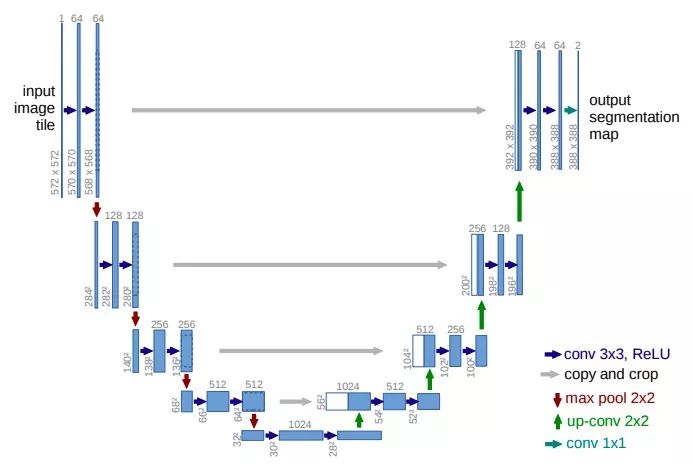
U-Net运用了与FCN相同的技巧,将浅层特征图与深层特征图结合(图中copy and crop箭头),这样可以结合局部“where”以及全局“what”的特征,生成更精准的图像。但它并不像FCN将特征相加,而是concatenate生成双倍通道的特征图,再卷积。
PDF:arxiv.org/pdf/1505.04597.pdf







