【AI-CPS】【深度学习】《Nature》纪念人工智能60周年专题:深度学习综述

文章是《Nature》杂志为纪念人工智能60周年而专门推出的深度学习综述,也是Hinton、LeCun和Bengio三位大神首次合写同一篇文章。该综述在深度学习领域的重要性不言而喻,可以说是所有人入门深度学习的必读作品。
本文上半部分深入浅出介绍深度学习的基本原理和核心优势,下半部分则详解CNN、分布式特征表示、RNN及其不同的应用,并对深度学习技术的未来发展进行展望。
原文链接:
https://www.cs.toronto.edu/~hinton/absps/NatureDeepReview.pdf
论文摘要
深度学习可以让那些拥有多个处理层的计算模型来学习具有多层次抽象的数据的表示。这些方法在许多方面都带来了显著的改善,包括较先进的语音识别、视觉对象识别、对象检测和许多其它领域,例如药物发现和基因组学等。深度学习能够发现大数据中的复杂结构。它是利用BP算法来完成这个发现过程的。BP算法能够指导机器如何从前一层获取误差而改变本层的内部参数,这些内部参数可以用于计算表示。深度卷积网络在处理图像、视频、语音和音频方面带来了突破,而递归网络在处理序列数据,比如文本和演讲方面表现出了闪亮的一面。
机器学习技术在现代社会的各个方面表现出了强大的功能:从Web搜索到社会网络内容过滤,再到电子商务网站上的商品推荐都有涉足。并且它越来越多地出现在消费品中,比如相机和智能手机。
机器学习系统被用来识别图片中的目标,将语音转换成文本,匹配新闻元素,根据用户兴趣提供职位或产品,选择相关的搜索结果。逐渐地,这些应用使用一种叫深度学习的技术。传统的机器学习技术在处理未加工过的数据时,体现出来的能力是有限的。
几十年来,想要构建一个模式识别系统或者机器学习系统,需要一个精致的引擎和相当专业的知识来设计一个特征提取器,把原始数据(如图像的像素值)转换成一个适当的内部特征表示或特征向量,子学习系统,通常是一个分类器,对输入的样本进行检测或分类。特征表示学习是一套给机器灌入原始数据,然后能自动发现需要进行检测和分类的表达的方法。
深度学习就是一种特征学习方法,把原始数据通过一些简单的但是非线性的模型转变成为更高层次的,更加抽象的表达。通过足够多的转换的组合,非常复杂的函数也可以被学习。
对于分类任务,高层次的表达能够强化输入数据的区分能力方面,同时削弱不相关因素。比如,一副图像的原始格式是一个像素数组,那么在第一层上的学习特征表达通常指的是在图像的特定位置和方向上有没有边的存在。第二层通常会根据那些边的某些排放而来检测图案,这时候会忽略掉一些边上的一些小的干扰。第三层或许会把那些图案进行组合,从而使其对应于熟悉目标的某部分。随后的一些层会将这些部分再组合,从而构成待检测目标。
深度学习的核心方面是,上述各层的特征都不是利用人工工程来设计的,而是使用一种通用的学习过程从数据中学到的。
深度学习正在取得重大进展,解决了人工智能界的尽较大努力很多年仍没有进展的问题。它已经被证明,它能够擅长发现高维数据中的复杂结构,因此它能够被应用于科学、商业和政府等领域。除了在图像识别、语音识别等领域打破了纪录,它还在另外的领域击败了其他机器学习技术,包括预测潜在的药物分子的活性、分析粒子加速器数据、重建大脑回路、预测在非编码DNA突变对基因表达和疾病的影响。
也许更令人惊讶的是,深度学习在自然语言理解的各项任务中产生了非常可喜的成果,特别是主题分类、情感分析、自动问答和语言翻译。我们认为,在不久的将来,深度学习将会取得更多的成功,因为它需要很少的手工工程,它可以很容易受益于可用计算能力和数据量的增加。目前正在为深度神经网络开发的新的学习算法和架构只会加速这一进程。
监督学习
机器学习中,不论是否是深层,最常见的形式是监督学习。
试想一下,我们要建立一个系统,它能够对一个包含了一座房子、一辆汽车、一个人或一个宠物的图像进行分类。我们先收集大量的房子,汽车,人与宠物的图像的数据集,并对每个对象标上它的类别。
在训练期间,机器会获取一副图片,然后产生一个输出,这个输出以向量形式的分数来表示,每个类别都有一个这样的向量。我们希望所需的类别在所有的类别中具有较高的得分,但是这在训练之前是不太可能发生的。通过计算一个目标函数可以获得输出分数和期望模式分数之间的误差(或距离)。然后机器会修改其内部可调参数,以减少这种误差。这些可调节的参数,通常被称为权值,它们是一些实数,可以被看作是一些“旋钮”,定义了机器的输入输出功能。
在典型的深学习系统中,有可能有数以百万计的样本和权值,和带有标签的样本,用来训练机器。为了正确地调整权值向量,该学习算法计算每个权值的梯度向量,表示了如果权值增加了一个很小的量,那么误差会增加或减少的量。权值向量然后在梯度矢量的相反方向上进行调整。我们的目标函数,所有训练样本的平均,可以被看作是一种在权值的高维空间上的多变地形。负的梯度矢量表示在该地形中下降方向最快,使其更接近于最小值,也就是平均输出误差低较低的地方。
在实际应用中,大部分从业者都使用一种称作随机梯度下降的算法(SGD)。它包含了提供一些输入向量样本,计算输出和误差,计算这些样本的平均梯度,然后相应的调整权值。通过提供小的样本集合来重复这个过程用以训练网络,直到目标函数停止增长。它被称为随机的是因为小的样本集对于全体样本的平均梯度来说会有噪声估计。这个简单过程通常会找到一组不错的权值,同其他精心设计的优化技术相比,它的速度让人惊奇。训练结束之后,系统会通过不同的数据样本——测试集来显示系统的性能。这用于测试机器的泛化能力——对于未训练过的新样本的识别能力。
当前应用中的许多机器学习技术使用的是线性分类器来对人工提取的特征进行分类。一个2类线性分类器会计算特征向量的加权和。当加权和超过一个阈值之后,输入样本就会被分配到一个特定的类别中。从20世纪60年代开始,我们就知道了线性分类器只能够把样本分成非常简单的区域,也就是说通过一个超平面把空间分成两部分。
但像图像和语音识别等问题,它们需要的输入-输出函数要对输入样本中不相关因素的变化不要过于的敏感,如位置的变化,目标的方向或光照,或者语音中音调或语调的变化等,但是需要对于一些特定的微小变化非常敏感(例如,一只白色的狼和跟狼类似的白色狗——萨莫耶德犬之间的差异)。在像素这一级别上,两条萨莫耶德犬在不同的姿势和在不同的环境下的图像可以说差异是非常大的,然而,一只萨摩耶德犬和一只狼在相同的位置并在相似背景下的两个图像可能就非常类似。
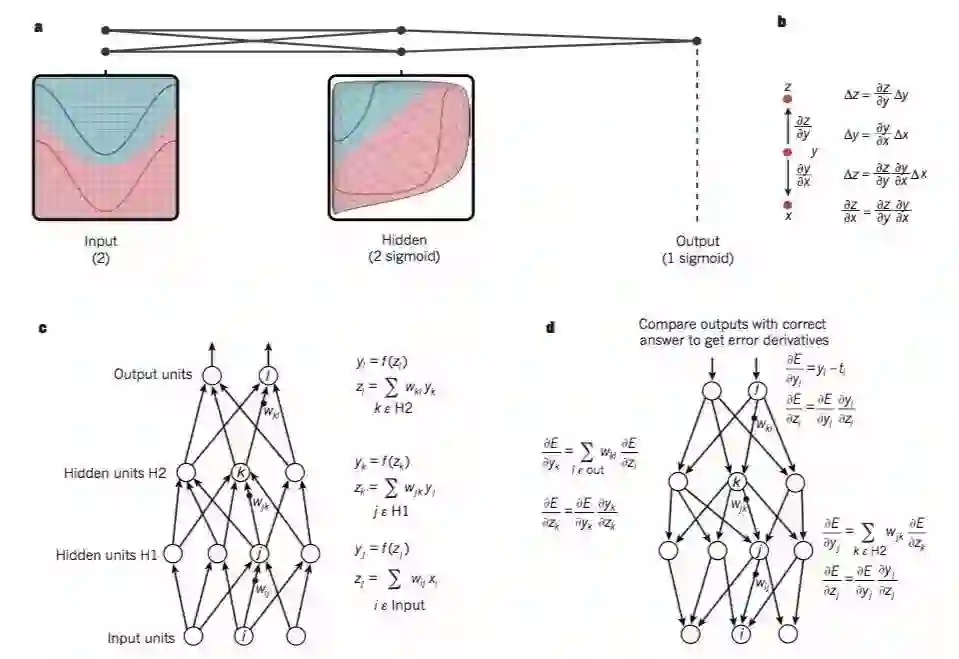
图1 多层神经网络和BP算法
多层神经网络(用连接点表示)可以对输入空间进行整合,使得数据(红色和蓝色线表示的样本)线性可分。注意输入空间中的规则网格(左侧)是如何被隐藏层转换的(转换后的在右侧)。这个例子中只用了两个输入节点,两个隐藏节点和一个输出节点,但是用于目标识别或自然语言处理的网络通常包含数十个或者数百个这样的节点。获得C.Olah(http://colah.github.io/) 的许可后重新构建的这个图。
链式法则告诉我们两个小的变化(x和y的微小变化,以及y和z的微小变化)是怎样组织到一起的。x的微小变化量Δx首先会通过乘以∂y/∂x(偏导数)转变成y的变化量Δy。类似的,Δy会给z带来改变Δz。通过链式法则可以将一个方程转化到另外的一个——也就是Δx通过乘以∂y/∂x和∂z/∂x得到Δz的过程。当x,y,z是向量的时候,可以同样处理(使用雅克比矩阵)。
具有两个隐层一个输出层的神经网络中计算前向传播的公式。每个都有一个模块构成,用于反向传播梯度。在每一层上,我们首先计算每个节点的总输入z,z是前一层输出的加权和。然后利用一个非线性函数f(.)来计算节点的输出。简单期间,我们忽略掉了阈值项。神经网络中常用的非线性函数包括了最近几年常用的校正线性单元(ReLU)f(z) = max(0,z),和传统的sigmoids,比如f(z) = (exp(z) − exp(−z))/(exp(z) + exp(−z)) 和f(z) = 1/(1 + exp(−z))。
计算反向传播的公式。在隐层,我们计算每个输出单元产生的误差,这是由上一层产生的误差的加权和。然后我们将输出层的误差通过乘以梯度f(z)转换到输入层。在输出层上,每个节点的误差会用成本函数的微分来计算。如果节点l的成本函数是0.5*(yl-tl)^2, 那么节点的误差就是yl-tl,其中tl是期望值。一旦知道了∂E/∂zk的值,节点j的内星权向量wjk就可以通过yj ∂E/∂zk来进行调整。
一个线性分类器或者其他操作在原始像素上的浅层分类器不能够区分后两者,虽然能够将前者归为同一类。这就是为什么浅分类要求有良好的特征提取器用于解决选择性不变性困境——提取器会挑选出图像中能够区分目标的那些重要因素,但是这些因素对于分辨动物的位置就无能为力了。为了加强分类能力,可以使用泛化的非线性特性,如核方法,但这些泛化特征,比如通过高斯核得到的,并不能够使得学习器从学习样本中产生较好的泛化效果。
传统的方法是手工设计良好的特征提取器,这需要大量的工程技术和专业领域知识。但是如果通过使用通用学习过程而得到良好的特征,那么这些都是可以避免的了。这就是深度学习的关键优势。
深度学习的体系结构是简单模块的多层栈,所有(或大部分)模块的目标是学习,还有许多计算非线性输入输出的映射。栈中的每个模块将其输入进行转换,以增加表达的可选择性和不变性。比如说,具有一个5到20层的非线性多层系统能够实现非常复杂的功能,比如输入数据对细节非常敏感——能够区分白狼和萨莫耶德犬,同时又具有强大的抗干扰能力,比如可以忽略掉不同的背景、姿势、光照和周围的物体等。
用反向传播训练多层神经网络
在最早期的模式识别任务中,研究者的目标一直是使用可以训练的多层网络来替代经过人工选择的特征,虽然使用多层神经网络很简单,但是得出来的解很糟糕。直到20世纪80年代,使用简单的随机梯度下降来训练多层神经网络,这种糟糕的情况才有所改变。只要网络的输入和内部权值之间的函数相对平滑,使用梯度下降就凑效,梯度下降方法是在70年代到80年代期间由不同的研究团队独立发明的。
用来求解目标函数关于多层神经网络权值梯度的反向传播算法(BP)只是一个用来求导的链式法则的具体应用而已。反向传播算法的核心思想是:目标函数对于某层输入的导数(或者梯度)可以通过向后传播对该层输出(或者下一层输入)的导数求得(如图1)。反向传播算法可以被重复的用于传播梯度通过多层神经网络的每一层:从该多层神经网络的最顶层的输出(也就是改网络产生预测的那一层)一直到该多层神经网络的最底层(也就是被接受外部输入的那一层),一旦这些关于(目标函数对)每层输入的导数求解完,我们就可以求解每一层上面的(目标函数对)权值的梯度了。
很多深度学习的应用都是使用前馈式神经网络(如图1),该神经网络学习一个从固定大小输入(比如输入是一张图)到固定大小输出(例如,到不同类别的概率)的映射。从第一层到下一层,计算前一层神经元输入数据的权值的和,然后把这个和传给一个非线性激活函数。当前最流行的非线性激活函数是rectified linear unit(ReLU),函数形式:f(z)=max(z,0)。过去的几十年中,神经网络使用一些更加平滑的非线性函数,比如tanh(z)和1/(1+exp(-z)),但是ReLU通常会让一个多层神经网络学习的更快,也可以让一个深度网络直接有监督的训练(不需要无监督的pre-train)。
达到之前那种有pre-train的效果。通常情况下,输入层和输出层以外的神经单元被称为隐藏单元。隐藏层的作用可以看成是使用一个非线性的方式打乱输入数据,来让输入数据对应的类别在最后一层变得线性可分。
在20世纪90年代晚期,神经网络和反向传播算法被大多数机器学习团队抛弃,同时也不受计算机视觉和语音识别团队的重视。人们普遍认为,学习有用的、多级层次结构的、使用较少先验知识进行特征提取的这些方法都不靠谱。确切的说是因为简单的梯度下降会让整个优化陷入到不好的局部最小解。
实践中,如果在大的网络中,不管使用什么样的初始化条件,局部最小解并不算什么大问题,系统总是得到效果差不多的解。最近的理论和实验表明,局部最小解还真不是啥大问题。相反,解空间中充满了大量的鞍点(梯度为0的点),同时鞍点周围大部分曲面都是往上的。所以这些算法就算是陷入了这些局部最小值,关系也不太大。
2006年前后,CIFAR(加拿大高级研究院)把一些研究者聚集在一起,人们对深度前馈式神经网络重新燃起了兴趣。研究者们提出了一种非监督的学习方法,这种方法可以创建一些网络层来检测特征而不使用带标签的数据,这些网络层可以用来重构或者对特征检测器的活动进行建模。通过预训练过程,深度网络的权值可以被初始化为有意思的值。然后一个输出层被添加到该网络的顶部,并且使用标准的反向传播算法进行微调。这个工作对手写体数字的识别以及行人预测任务产生了显著的效果,尤其是带标签的数据非常少的时候。
使用这种与训练方法做出来的第一个比较大的应用是关于语音识别的,并且是在GPU上做的,这样做是因为写代码很方便,并且在训练的时候可以得到10倍或者20倍的加速。2009年,这种方法被用来映射短时间的系数窗口,该系统窗口是提取自声波并被转换成一组概率数字。它在一组使用很少词汇的标准的语音识别基准测试程序上达到了惊人的效果,然后又迅速被发展到另外一个更大的数据集上,同时也取得惊人的效果。从2009年到到2012年底,较大的语音团队开发了这种深度网络的多个版本并且已经被用到了安卓手机上。对于小的数据集来说,无监督的预训练可以防止过拟合,同时可以带来更好的泛化性能当有标签的样本很小的时候。一旦深度学习技术重新恢复,这种预训练只有在数据集合较少的时候才需要。
然后,还有一种深度前馈式神经网络,这种网络更易于训练并且比那种全连接的神经网络的泛化性能更好。这就是卷积神经网络(CNN)。当人们对神经网络不感兴趣的时候,卷积神经网络在实践中却取得了很多成功,如今它被计算机视觉团队广泛使用。
卷积神经网络
卷积神经网络被设计用来处理到多维数组数据的,比如一个有3个包含了像素值2-D图像组合成的一个具有3个颜色通道的彩色图像。很多数据形态都是这种多维数组的:1D用来表示信号和序列包括语言,2D用来表示图像或者声音,3D用来表示视频或者有声音的图像。卷积神经网络使用4个关键的想法来利用自然信号的属性:局部连接、权值共享、池化以及多网络层的使用。
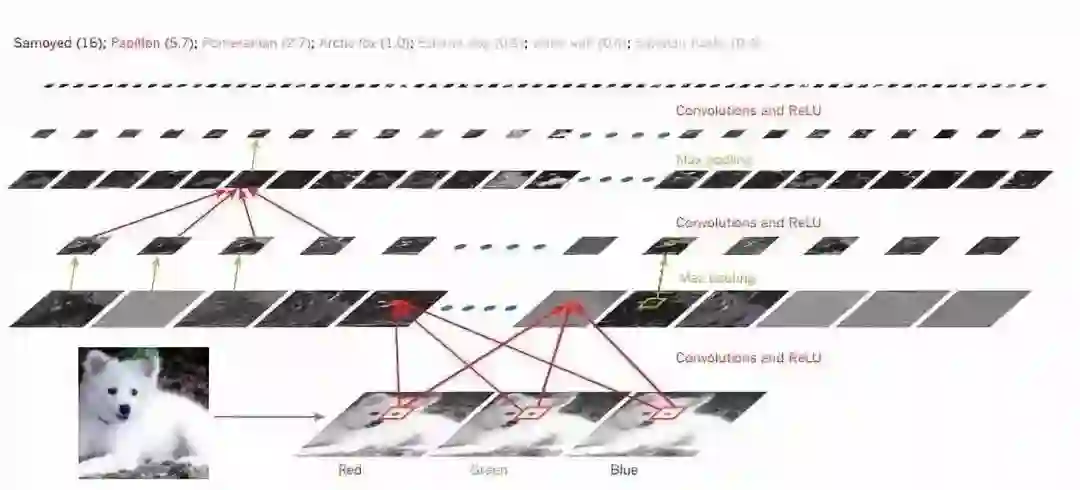
图2 卷积神经网络内部
一个典型的卷积神经网络结构(如图2)是由一系列的过程组成的。最初的几个阶段是由卷积层和池化层组成,卷积层的单元被组织在特征图中,在特征图中,每一个单元通过一组叫做滤波器的权值被连接到上一层的特征图的一个局部块,然后这个局部加权和被传给一个非线性函数,比如ReLU。在一个特征图中的全部单元享用相同的过滤器,不同层的特征图使用不同的过滤器。使用这种结构处于两方面的原因。
首先,在数组数据中,比如图像数据,一个值的附近的值经常是高度相关的,可以形成比较容易被探测到的有区分性的局部特征。其次,不同位置局部统计特征不太相关的,也就是说,在一个地方出现的某个特征,也可能出现在别的地方,所以不同位置的单元可以共享权值以及可以探测相同的样本。在数学上,这种由一个特征图执行的过滤操作是一个离线的卷积,卷积神经网络也是这么得名来的。
卷积层的作用是探测上一层特征的局部连接,然而池化层的作用是在语义上把相似的特征合并起来,这是因为形成一个主题的特征的相对位置不太一样。一般地,池化单元计算特征图中的一个局部块的较大值,相邻的池化单元通过移动一行或者一列来从小块上读取数据,因为这样做就减少的表达的维度以及对数据的平移不变性。两三个这种的卷积、非线性变换以及池化被串起来,后面再加上一个更多卷积和全连接层。在卷积神经网络上进行反向传播算法和在一般的深度网络上是一样的,可以让所有的在过滤器中的权值得到训练。
深度神经网络利用的很多自然信号是层级组成的属性,在这种属性中高级的特征是通过对低级特征的组合来实现的。在图像中,局部边缘的组合形成基本图案,这些图案形成物体的局部,然后再形成物体。这种层级结构也存在于语音数据以及文本数据中,如电话中的声音,因素,音节,文档中的单词和句子。当输入数据在前一层中的位置有变化的时候,池化操作让这些特征表示对这些变化具有鲁棒性。
卷积神经网络中的卷积和池化层灵感直接来源于视觉神经科学中的简单细胞和复杂细胞。这种细胞的是以LNG-V1-V2-V4-IT这种层级结构形成视觉回路的。当给一个卷积神经网络和猴子一副相同的图片的时候,卷积神经网络展示了猴子下颞叶皮质中随机160个神经元的变化。卷积神经网络有神经认知的根源,他们的架构有点相似,但是在神经认知中是没有类似反向传播算法这种端到端的监督学习算法的。一个比较原始的1D卷积神经网络被称为时延神经网络,可以被用来识别语音以及简单的单词。
20世纪90年代以来,基于卷积神经网络出现了大量的应用。最开始是用时延神经网络来做语音识别以及文档阅读。这个文档阅读系统使用一个被训练好的卷积神经网络和一个概率模型,这个概率模型实现了语言方面的一些约束。20世纪90年代末,这个系统被用来美国超过10%的支票阅读上。后来,微软开发了基于卷积神经网络的字符识别系统以及手写体识别系统。20世纪90年代早期,卷积神经网络也被用来自然图形中的物体识别,比如脸、手以及人脸识别(face recognition )。
使用深度卷积网络进行图像理解
21世纪开始,卷积神经网络就被成功的大量用于检测、分割、物体识别以及图像的各个领域。这些应用都是使用了大量的有标签的数据,比如交通信号识别,生物信息分割,面部探测,文本、行人以及自然图形中的人的身体部分的探测。近年来,卷积神经网络的一个重大成功应用是人脸识别。
值得一提的是,图像可以在像素级别进行打标签,这样就可以应用在比如自动电话接听机器人、自动驾驶汽车等技术中。像Mobileye以及NVIDIA公司正在把基于卷积神经网络的方法用于汽车中的视觉系统中。其它的应用涉及到自然语言的理解以及语音识别中。

图3 从图像到文字
尽管卷积神经网络应用的很成功,但是它被计算机视觉以及机器学习团队开始重视是在2012年的ImageNet竞赛。在该竞赛中,深度卷积神经网络被用在上百万张网络图片数据集,这个数据集包含了1000个不同的类。该结果达到了前所未有的好,几乎比当时较好的方法降低了一半的错误率。这个成功来自有效地利用了GPU、ReLU、一个新的被称为dropout的正则技术,以及通过分解现有样本产生更多训练样本的技术。这个成功给计算机视觉带来一个革命。如今,卷积神经网络用于几乎全部的识别和探测任务中。最近一个更好的成果是,利用卷积神经网络结合回馈神经网络用来产生图像标题。
如今的卷积神经网络架构有10-20层采用ReLU激活函数、上百万个权值以及几十亿个连接。然而训练如此大的网络两年前就只需要几周了,现在硬件、软件以及算法并行的进步,又把训练时间压缩到了几小时。
基于卷积神经网络的视觉系统的性能已经引起了大型技术公司的注意,比如Google、Facebook、Microsoft、IBM,yahoo!、Twitter和Adobe等,一些快速增长的创业公司也同样如是。
卷积神经网络很容易在芯片或者现场可编程门阵列(FPGA)中高效实现,许多公司比如NVIDIA、Mobileye、Intel、Qualcomm以及Samsung,正在开发卷积神经网络芯片,以使智能机、相机、机器人以及自动驾驶汽车中的实时视觉系统成为可能。
分布式特征表示与语言处理
与不使用分布式特征表示(distributed representations )的经典学习算法相比,深度学习理论表明深度网络具有两个不同的巨大的优势。这些优势来源于网络中各节点的权值,并取决于具有合理结构的底层生成数据的分布。首先,学习分布式特征表示能够泛化适应新学习到的特征值的组合(比如,n元特征就有2n种可能的组合)。其次,深度网络中组合表示层带来了另一个指数级的优势潜能(指数级的深度)。
多层神经网络中的隐层利用网络中输入的数据进行特征学习,使之更加容易预测目标输出。下面是一个很好的示范例子,比如将本地文本的内容作为输入,训练多层神经网络来预测句子中下一个单词。内容中的每个单词表示为网络中的N分之一的向量,也就是说,每个组成部分中有一个值为1其余的全为0。在第一层中,每个单词创建不同的激活状态,或单词向量(如图4)。在语言模型中,网络中其余层学习并转化输入的单词向量为输出单词向量来预测句子中下一个单词,可以通过预测词汇表中的单词作为文本句子中下一个单词出现的概率。网络学习了包含许多激活节点的、并且可以解释为词的独立特征的单词向量,正如第一次示范的文本学习分层表征文字符号的例子。这些语义特征在输入中并没有明确的表征。
而是在利用“微规则”(‘micro-rules’,本文中直译为:微规则)学习过程中被发掘,并作为一个分解输入与输出符号之间关系结构的好的方式。当句子是来自大量的真实文本并且个别的微规则不可靠的情况下,学习单词向量也一样能表现得很好。利用训练好的模型预测新的事例时,一些概念比较相似的词容易混淆,比如星期二(Tuesday)和星期三(Wednesday),瑞典(Sweden)和挪威(Norway)。这样的表示方式被称为分布式特征表示,因为他们的元素之间并不互相排斥,并且他们的构造信息对应于观测到的数据的变化。这些单词向量是通过学习得到的特征构造的,这些特征不是由专家决定的,而是由神经网络自动发掘的。从文本中学习得单词向量表示现在广泛应用于自然语言中。
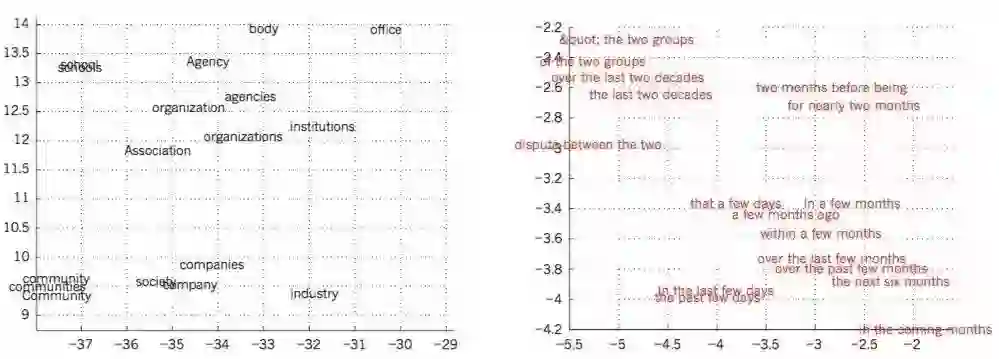
图4 词向量学习可视化
特征表示问题争论的中心介于对基于逻辑启发和基于神经网络的认识。在逻辑启发的范式中,一个符号实体表示某一事物,因为其的属性与其他符号实体相同或者不同。该符号实例没有内部结构,并且结构与使用是相关的,至于理解符号的语义,就必须与变化的推理规则合理对应。相反地,神经网络利用了大量活动载体、权值矩阵和标量非线性化,来实现能够支撑简单容易的、具有常识推理的快速“直觉”功能。
在介绍神经语言模型前,简述下标准方法,其是基于统计的语言模型,该模型没有使用分布式特征表示。而是基于统计简短符号序列出现的频率增长到N(N-grams,N元文法)。可能的N-grams的数字接近于VN,其中V是词汇表的大小,考虑到文本内容包含成千上万个单词,所以需要一个非常大的语料库。N-grams将每个单词看成一个原子单元,因此不能在语义相关的单词序列中一概而论,然而神经网络语言模型可以,是因为他们关联每个词与真是特征值的向量,并且在向量空间中语义相关的词彼此靠近(图4)。
递归神经网络
首次引入反向传播算法时,最令人兴奋的便是使用递归神经网络(recurrent neural networks,下文简称RNNs)训练。对于涉及到序列输入的任务,比如语音和语言,利用RNNs能获得更好的效果。RNNs一次处理一个输入序列元素,同时维护网络中隐式单元中隐式的包含过去时刻序列元素的历史信息的“状态向量”。如果是深度多层网络不同神经元的输出,我们就会考虑这种在不同离散时间步长的隐式单元的输出,这将会使我们更加清晰怎么利用反向传播来训练RNNs(如图5,右)。
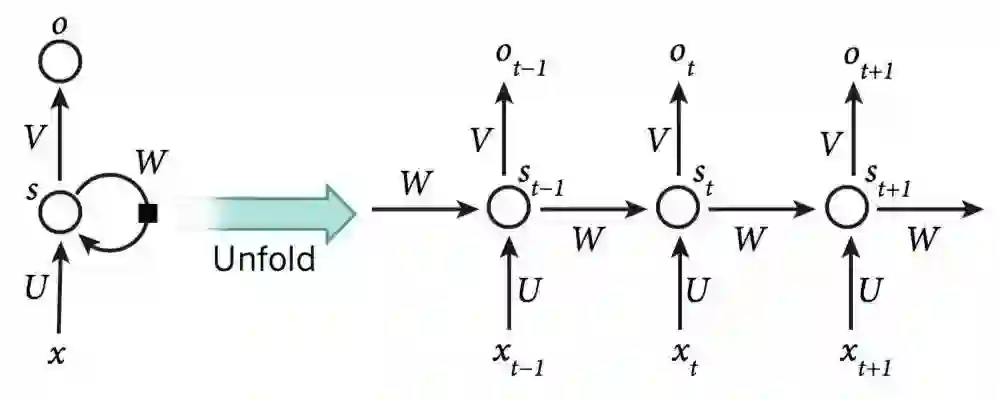
图5 递归神经网络
RNNs是非常强大的动态系统,但是训练它们被证实存在问题的,因为反向传播的梯度在每个时间间隔内是增长或下降的,所以经过一段时间后将导致结果的激增或者降为零。
由于先进的架构和训练方式,RNNs被发现可以很好的预测文本中下一个字符或者句子中下一个单词,并且可以应用于更加复杂的任务。例如在某时刻阅读英语句子中的单词后,将会训练一个英语的“编码器”网络,使得隐式单元的最终状态向量能够很好地表征句子所要表达的意思或思想。这种“思想向量”(thought vector)可以作为联合训练一个法语“编码器”网络的初始化隐式状态(或者额外的输入),其输出为法语翻译首单词的概率分布。
如果从分布中选择一个特殊的首单词作为编码网络的输入,将会输出翻译的句子中第二个单词的概率分布,并直到停止选择为止。总体而言,这一过程是根据英语句子的概率分布而产生的法语词汇序列。这种简单的机器翻译方法的表现甚至可以和较先进的(state-of-the-art)的方法相媲美,同时也引起了人们对于理解句子是否需要像使用推理规则操作内部符号表示质疑。这与日常推理中同时涉及到根据合理结论类推的观点是匹配的。
类比于将法语句子的意思翻译成英语句子,同样可以学习将图片内容“翻译”为英语句子(如图3)。这种编码器是可以在最后的隐层将像素转换为活动向量的深度卷积网络(ConvNet)。解码器与RNNs用于机器翻译和神经网络语言模型的类似。近来,已经掀起了一股深度学习的巨大兴趣热潮(参见文献[86]提到的例子)。
RNNs一旦展开(如图5),可以将之视为一个所有层共享同样权值的深度前馈神经网络。虽然它们的目的是学习长期的依赖性,但理论的和经验的证据表明很难学习并长期保存信息。
为了解决这个问题,一个增大网络存储的想法随之产生。采用了特殊隐式单元的LSTM(long short-termmemory networks)被首先提出,其自然行为便是长期的保存输入。一种称作记忆细胞的特殊单元类似累加器和门控神经元:它在下一个时间步长将拥有一个权值并联接到自身,拷贝自身状态的真实值和累积的外部信号,但这种自联接是由另一个单元学习并决定何时清除记忆内容的乘法门控制的。
LSTM网络随后被证明比传统的RNNs更加有效,尤其当每一个时间步长内有若干层时,整个语音识别系统能够完全一致的将声学转录为字符序列。目前LSTM网络或者相关的门控单元同样用于编码和解码网络,并且在机器翻译中表现良好。
过去几年中,几位学者提出了不同的提案用于增强RNNs的记忆模块。提案中包括神经图灵机,其中通过加入RNNs可读可写的“类似磁带”的存储来增强网络,而记忆网络中的常规网络通过联想记忆来增强。记忆网络在标准的问答基准测试中表现良好,记忆是用来记住稍后要求回答问题的事例。
除了简单的记忆化,神经图灵机和记忆网络正在被用于那些通常需要推理和符号操作的任务,还可以教神经图灵机“算法”。除此以外,他们可以从未排序的输入符号序列(其中每个符号都有与其在列表中对应的表明优先级的真实值)中,学习输出一个排序的符号序列。可以训练记忆网络用来追踪一个设定与文字冒险游戏和故事的世界的状态,回答一些需要复杂推理的问题。在一个测试例子中,网络能够正确回答15句版的《指环王》中诸如“Frodo现在在哪?”的问题。
深度学习的未来展望
无监督学习对于重新点燃深度学习的热潮起到了促进的作用,但是纯粹的有监督学习的成功盖过了无监督学习。在本篇综述中虽然这不是我们的重点,我们还是期望无监督学习在长期内越来越重要。无监督学习在人类和动物的学习中占据主导地位:我们通过观察能够发现世界的内在结构,而不是被告知每一个客观事物的名称。
人类视觉是一个智能的、基于特定方式的利用小或大分辨率的视网膜中央窝与周围环绕区域对光线采集成像的活跃的过程。我们期望未来在机器视觉方面会有更多的进步,这些进步来自那些端对端的训练系统,并结合ConvNets和RNNs,采用增强学习来决定走向。结合了深度学习和增强学习的系统正处在初期,但已经在分类任务中超过了被动视频系统,并在学习操作视频游戏中产生了令人印象深刻的效果。
在未来几年,自然语言理解将是深度学习做出巨大影响的另一个领域。我们预测那些利用了RNNs的系统将会更好地理解句子或者整个文档,当它们选择性地学习了某时刻部分加入的策略。
最终,在人工智能方面取得的重大进步将来自那些结合了复杂推理表示学习(representation learning )的系统。尽管深度学习和简单推理已经应用于语音和手写字识别很长一段时间了,我们仍需要通过操作大量向量的新范式来代替基于规则的字符表达式操作。
来源:三体智讯
深度学习与强化学习相结合,谷歌训练机械臂的长期推理能力
AI 科技评论按:机器人如何能够学到在多样且复杂的真实世界物体和环境中能够广泛使用的技能呢?如果机器人是设计用来在可控环境下进行高效的重复工作,那么这个任务就相对来说更加简单,比如设计一个在流水线上组装产品的机器人。但要是想要设计能够观察周围环境,根据环境决定最优的行动,同时还能够对不可预知的环境做出反应的机器人,那难度就会指数级的增长。目前,有两个有力的工具能够帮助机器人从试验中学习到这些技能,一个是深度学习,一个是强化学习。深度学习非常适合解决非结构化的真实世界场景,而强化学习能够实现较长期的推理(longer-term reasoning),同时能够在一系列决策时做出更好更鲁棒的决策。将这两个工具结合到一起,就有可能能够让机器人从自身经验中不断学习,使得机器人能够通过数据,而不是人工手动定义的方法来掌握运动感知的技能。
为机器人设计强化学习算法主要有几个挑战:首先真实世界中的物体通常有多样的视觉和物理特征,接触力(触觉)的细微差异可能导致物体的运动难以预测。于此同时机械臂可能会遮挡住视线而导致难以通过视觉识别的方法预测物体运动。此外,机器人传感器本身充满噪声,这也增加了算法的复杂性。所有这些因素结合到一起,使得设计一个能够学习到通用解决方案的算法变得异常困难,除非训练数据足够丰富,有足够多的不同种类的数据,但是这也使得构建数据集的时间成本变得很高。这些难点也激励着研究者探索能够复用过去经验的学习算法,比如之前 Google 设计的抓取学习算法,就能够从大型数据集中获益。但是该工作存在一个问题,就是机器无法推断出其行动的长期后果,而这这长期的推理对于学习如何抓取物体是非常重要的。比如,如果多个物体聚集在一起,先将它们中的一个分离出来(称作「单一化」),在进行抓取时会变得更加容易,但「单一化」这一步骤并不能直接导致抓取成功,而是有一个较为长期的成功率的提升。


「单一化」的例子
为了提高效率,使用离线策略强化学习(off-policy reinforcement learning)是必须的,即能够从之前几小时,几天或者几周的数据中学习。为了设计一个这样的能够从之前的交互中获得大量不同经验的离线策略强化学习算法,谷歌的研究人员将大规模分布式优化与一个新型拟合深度Q学习(new fitted deep Q-learning algorithm)算法相结合,名为 QT-Opt 。论文地址是 https://arxiv.org/abs/1806.10293
QT-Opt是一种分布式 Q 学习算法,支持连续行动空间,非常适合于机器人问题。为了使用 QT-Opt,研究人员首先使用之前收集的数据完全离线地训练了一个模型。这个过程并不需要运行实际的机器人,这点使得该算法更容易分布式的训练。之后,将该模型部署到真正的机器人上进行 finetune,这个阶段则使用全新的数据进行训练。在运行 QT-Opt 算法时,同时也在积累更多的离线数据,使得模型能够训练得更好,于是也能够得到更好的数据,这样就形成了一个正反馈循环。
为了将该方法应用到机器人抓取任务上,谷歌的研究人员们使用了 7 个真实的机器人,在四个月的时间里,运行了超过 800 个机器人小时。为了引导数据收集过程,研究人员开始时手动设计了一个抓取策略,大概有 15%-30% 的概率能够成功完成抓取任务。当算法学习到的模型的性能比手动设计的策略更好时,就将机器人的抓取策略换成该学习到的模型。该策略使用相机拍摄图像,之后返回机械臂和抓取器应该如何运动的数据。整个离线训练数据包含超过 1000 种不同物体的抓取数据。

一些用来训练抓取的物体
过去的研究表明,跨机器人的经验分享能够加速学习过程。研究人员将训练和数据收集的过程扩展到十块GPU,七个机器人和许多 CPU 上面,这最终收集并处理了一个超过 580,000 次抓取尝试的大型数据集。在最后,研究人员成功训练了一个能够在真实机器人上运行的抓取策略,它能够泛化到不同种类的物体的抓取上,即使这些物体并没有在训练时遇到过。
( AI 科技评论往期报道中,谷歌 AI 负责人 Jeff Dean 曾经谈到过他们用大量机械臂组成了一个「机械臂农场」,专门以大规模训练的方式解决机器人问题。这也就是一个例子)

七个正在采集数据的机器人
从定量的角度分析,QT-Opt 方法在训练集没有遇到过的物体的 700 次抓取尝试中,有 96% 的成功率。与之前的基于监督学习的抓取方法(成功率78%)相比,该方法将错误率降低了五倍以上。

值得注意的是,该抓取策略具有标准机器人抓取系统中不常见的各种闭环反应行为:
面对一组无法一起拾取的互锁在一起的物体时,该策略会在拾取之前将其中一块与其他块分开。
当抓住互相缠绕的杂乱物体时,该抓取策略会先探测不同的物体,直到手指牢牢握住其中一个,然后才抬起手臂
在机器人抓取到一个物体后,如果人故意将物体从夹具中拍打出来以扰乱机器人(训练时并没有这种场景),它会自动重新定位夹具,并进行另一次尝试。
最重要的是,这些行为都不是手动设计的,它们都是通过 QT-Opt 进行自监督训练而自动学习到的,因为这些行为能够从长期的角度提高模型抓取的成功率。


此外,研究人员还发现 QT-Opt 使用较少的数据就达到了更高的成功率,尽管可能需要更长时间才能收敛。这点对于机器人来说尤其令人兴奋,因为训练的瓶颈通常是如何收集到众多真实的机器人数据,而不是训练时间。将该方法与其他提高数据效率的技术相结合,可能会在机器人技术中开辟一些新的有趣的方向。谷歌的研究人员也正在将 QT-Opt 与最近的学习如何进行自校准(self-calibra)的工作相结合,想要进一步提高模型的泛化能力。
总体而言,QT-Opt 算法是一种通用的强化学习方法,可以为真实世界的机器人提供良好的性能。除了奖励函数的定义之外,QT-Opt 的任何内容都没有针对于机器人抓取做任何设计。这是迈向更通用的机器人学习算法的重要一步,并且也更期待该算法能够应用到什么其他的机器人任务中。
Via Google Bolg,AI 科技评论编译
如何通过深度学习轻松实现自动化监控?

作者 | Bharath Raj
译者 | 孤鸿
编辑 | Jane
出品 | AI 科技大本营(rgznai100 )
【导读】这是一篇关于使用基于深度学习的目标检测来实现监控系统的快速教程。在教程中通过使用 GPU 多处理器来比较不同目标检测模型在行人检测上的性能。
监控是安保和巡逻的一个组成部分,大多数情况下,这项工作都是在长时间去观察发现那些我们不愿意发生的事情。然而突发事件发生的低概率性无法掩盖监控这一平凡工作的重要性,这个工作甚至是至关重要的。
如果有能够代替我们去做“等待和监视”突发事件的工具那就再好不过了。幸运的是,这些年随着技术的进步,我们已经可以编写一些脚本来自动执行监控这一项任务。在深入探究之前,需要我们先考虑两个问题。
机器是否已经达到人类的水平?
任何熟悉深度学习的人都知道图像分类器的准确度已经赶超人类。图1显示了近几年来对于人类、传统计算机视觉 (CV) 和深度学习在 ImageNet 数据集上的分类错误率。
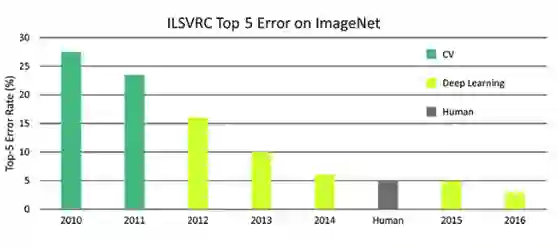
图 1 人类、深度学习和 CV 在 ImageNet 上分类错误率
与人类相比,机器可以更好地监视目标,使用机器进行监视效率更高,其优点可总结如下:
重复的任务会导致人类注意力的下降,而使用机器进行监视时并无这一烦恼,我们可以把更多的精力放在处理出现的突发事件上面。
当要监视的范围较大时,需要大量的人员,固定相机的视野也很有限。但是通过移动监控机器人 (如微型无人机) 就能解决这一问题。
此外,同样的技术可用于各种不受限于安全性的应用程序,如婴儿监视器或自动化产品交付。
那我们该如何实现自动化?
在我们讨论复杂的理论之前,先让我们看一下监控的正常运作方式。我们在观看即时影像时,如果发现异常就采会取行动。因此我们的技术也应该通过仔细阅读视频的每一帧来发现异常的事物,并判断这一过程是否需要报警。
大家可能已经知道了,这个过程实现的本质是通过目标检测定位,它与分类不同,我们需要知道目标的确切位置,而且在单个图像中可能有多个目标。为了更好的区分我们举了一个简单形象的例子如图2所示。
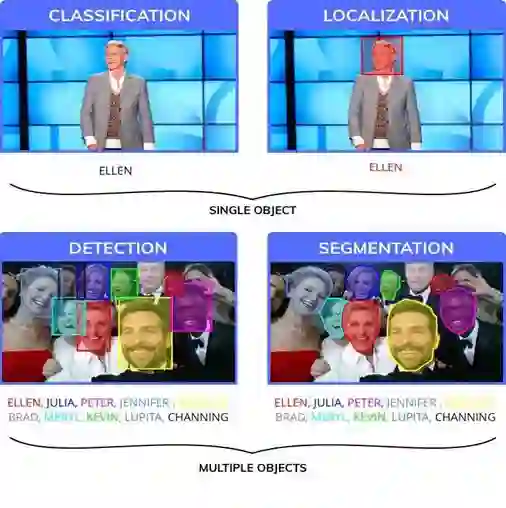
图2 分类、定位、检测和分割的示例图
为了找到确切的位置,我们的算法应该检查图像的每个部分,以找到某类的存在。自2014年以来,深度学习的持续迭代研究引入了精心设计的神经网络,它能够实时检测目标。图3显示了近两年R-CNN、Fast R-CNN 和 Faster R-CNN 三种模型的检测性能。
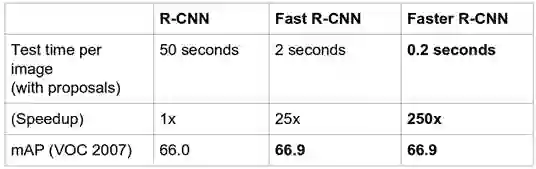
图3 R-CNN、Fast R-CNN 和 Faster R-CNN 性能
这里有几种在内部使用的不同方法来执行相同任务的深度学习框架。其中最流行的是 Faster-RCNN、YOLO 和 SSD。图4展示了 Faster R-CNN、R-FCN 和 SSD 的检测性能。
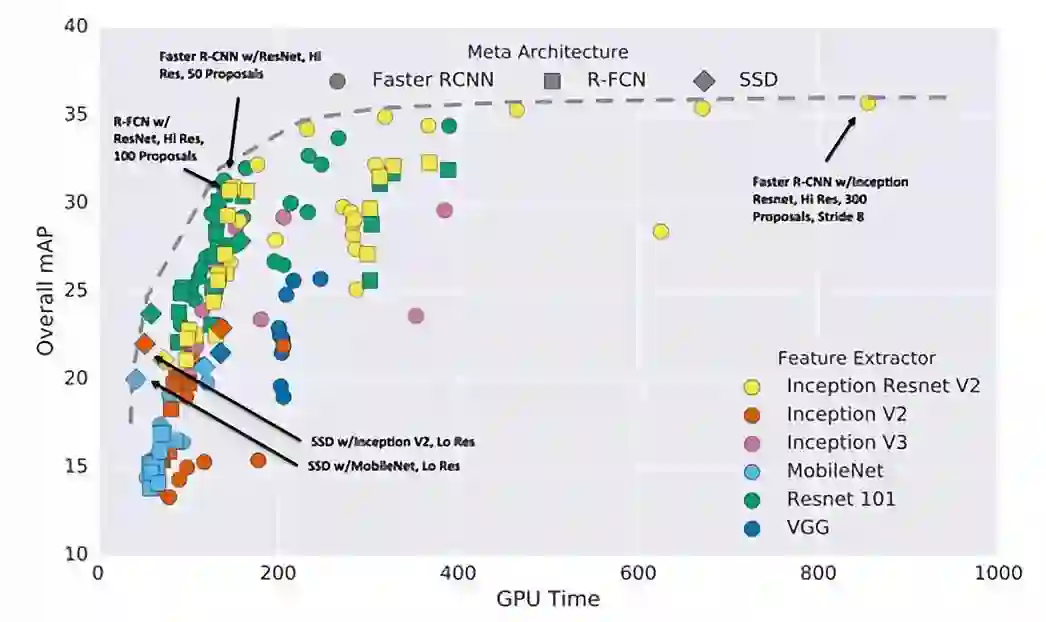
图4 Faster R-CNN、R-FCN 和 SSD 的检测性能,速度与准确性的权衡,更高的 mpA 和更低的 GPU 时间是最佳的。
每个模型都依赖于基础分类器,这极大影响了最终的准确性和模型大小。此外,目标检测器的选择会严重影响计算复杂性和最终精度。在选择目标检测算法时,速度、精度和模型大小的权衡关系始终存在着。
在有了上面的学习了解后,接下来我们将学习如何使用目标检测构建一个简单而有效的监控系统。
我们先从由监视任务的性质而引起的限制约束开始讨论起。
深度学习在监控中的限制
在实现自动化监控之前,我们需要考虑以下几个因素:
1.即时影像
为了在大范围内进行观察,我们可能需要多个摄像头。而且,这些摄像头需要有可用来存储数据的地方 (本地或远程位置)。图5为典型的监控摄像头。

图5 典型的监控摄像头
高质量的视频比低质量的视频要占更多的内存。此外,RGB 输入流比 BW 输入流大3倍。由于我们只能存储有限数量的输入流,故通常情况下我们会选择降低质量来保证最大化存储。
因此,可推广的监控系统应该能够解析低质量的图像。同时我们的深度学习算法也必须在低质量的图像上进行训练。
2.处理能力
在哪里处理从相机源获得的数据是另一个大问题。通常有两种方法可以解决这一问题。
集中式服务器处理
来自摄像机的视频流在远程服务器或集群上逐帧处理。这种方法很强大,使我们能够从高精度的复杂模型中获益。但这种方法的缺点是有延迟。此外,如果不用商业 API,则服务器的设置和维护成本会很高。图6显示了三种模型随着推理时间的增长内存的消耗情况。
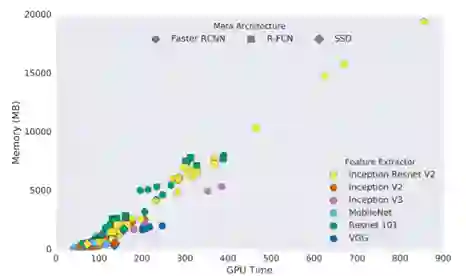
图6 内存消耗与推理时间(毫秒),大多数高性能模型都会占用大量内存
分散式边缘处理
通过附加一个微控制器来对相机本身进行实时处理。优点在于没有传输延迟,发现异常时还能更快地进行反馈,不会受到 WiFi 或蓝牙的限制 (如 microdrones)。缺点是微控制器没有 GPU 那么强大,因此只能使用精度较低的模型。使用板载 GPU 可以避免这一问题,但是太过于昂贵。图 7 展示了目标检测器 FPS 的性能。
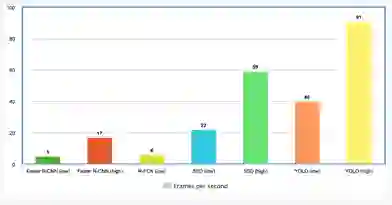
图 7 各类目标检测器 FPS 的性能
训练监控系统
在接下来的内容里我们将会尝试如何使用目标检测进行行人识别。使用 TensorFlow 目标检测 API 来创建目标检测模块,我们还会简要的阐述如何设置 API 并训练它来执行监控任务。整个过程可归纳为三个阶段 (流程图如图8所示):
数据准备
训练模型
推论
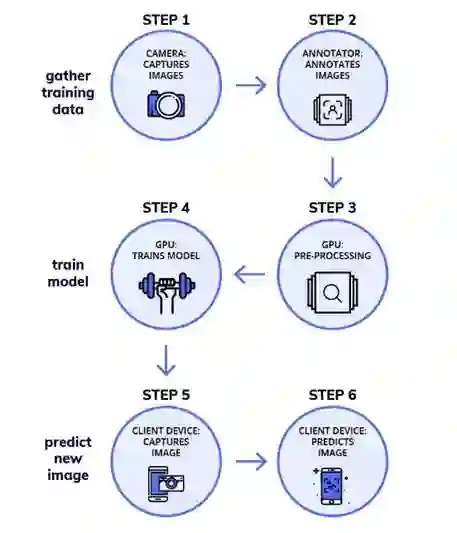
图8 目标检测模型的训练工作流程
▌第1阶段:数据准备
第一步:获取数据集
监控录像是获取最准确数据集的来源。但是,在大多数情况下,想要获取这样的监控录像并不容易。因此,我们需要训练我们的目标检测器使其能从普通图像中识别出目标。

图9 从数据集中提取出带标注的图像
正如前面所说,我们的图像质量可能较差,所以所训练的模型必须适应在这样的图像质量下进行工作。我们对数据集中的图像 (如图9所示) 添加一些噪声或者尝试模糊和腐蚀的手段,来降低数据集中的图片质量。
在目标检测任务中,我们使用了 TownCentre 数据集。使用视频的前3600帧进行训练,剩下的900帧用于测试。
第二步:图像标注
使用像 LabelImg 这样的工具进行标注,这项工作虽然乏味但也同样很重要。我们将标注完的图像保存为 XML 文件。
第三步:克隆存储库
运行以下命令以安装需求文件,编译一些 Protobuf 库并设置路径变量
pip install -r requirements.txt
sudo apt-get install protobuf-compiler
protoc object_detection/protos/*.proto --python_out=.
export PYTHONPATH=$PYTHONPATH:`pwd`:`pwd`/slim
第四步:准备所需的输入
首先,我们需要给每个目标一个标签,并将文件中每个标签表示为如下所示的 label_map.pbtxt
item {
id: 1
name: ‘target’
}
接下来,创建一个包含 XML 和图像文件名称的文本文件。例如,如果数据集中有 img1.jpg, img2.jpg, 和 img1.xml, img2.xml ,则 trainval.txt 文件的表示应如下所示:
img1
img2
将数据集分为两个文件夹 (图像与标注)。将 label_map.pbtx 和 trainval.txt放在标注文件夹中,然后在标注文件夹中创建一个名为 xmls 的子文件夹,并将所有 XML 文件放入该子文件夹中。目录层次结构应如下所示:
-base_directory
|-images
|-annotations
||-xmls
||-label_map.pbtxt
||-trainval.txt第五步:创建 TF 记录
API 接受 TPRecords 文件格式的输入。使用 creat_tf_record.py 文件将数据集转换为 TFRecords。我们应该在 base directory 中执行以下命令:
python create_tf_record.py \
--data_dir=`pwd` \
--output_dir=`pwd`
在该程序执行完后,我们可以获取 train.record 和 val.record 文件。
▌第2阶段:训练模型
第1步:模型选择
如前所述,速度与准确度两者不可得兼,从头开始创建和训练目标检测器是非常耗时的。因此, TensorFlow 目标检测 API 提供了一系列预先训练好的模型,我们可以根据自己的使用情况进行微调,该过程称为迁移学习,它可以大大提高我们的训练速度。
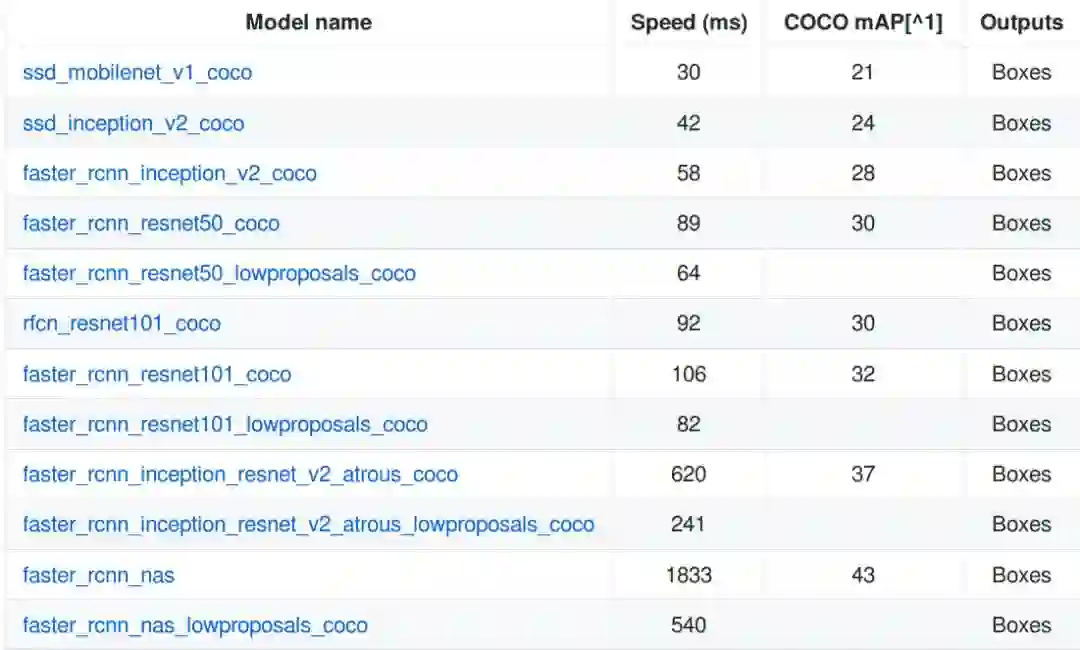
图10 MS COCO 数据集中一组预训练过的模型
从图 10 中下载一个模型,并将内容解压缩到 base directory 中。可获取模型检查点,固定推理图和 pipeline.config 文件。
第2步:定义训练工作
我们必须在 pipleline.config 文件中定义“训练工作”,并将该文件放到 base directory 中。该文件中最重要的是后几行——我们只需将突出显示的值放到各自的位置。
gradient_clipping_by_norm: 10.0
fine_tune_checkpoint: "model.ckpt"
from_detection_checkpoint: true
num_steps: 200000
}
train_input_reader {
label_map_path: "annotations/label_map.pbtxt"
tf_record_input_reader {
input_path: "train.record"
}
}
eval_config {
num_examples: 8000
max_evals: 10
use_moving_averages: false
}
eval_input_reader {
label_map_path: "annotations/label_map.pbtxt"
shuffle: false
num_epochs: 1
num_readers: 1
tf_record_input_reader {
input_path: "val.record"
}
}
第3步:开始训练
执行以下命令以启动训练工作,建议使用具有足够大的 GPU 计算机,以便加快训练过程。
python object_detection/train.py \
--logtostderr \
--pipeline_config_path=pipeline.config \
--train_dir=train▌第3阶段:推论
第1步:导出训练模型
在模型使用之前,需要将训练好的检查点文件导出到固定推理图上,实现这个过程并不困难,只需要执行以下代码 (用检查点替换“xxxxx”)
python object_detection/export_inference_graph.py \
--input_type=image_tensor \
--pipeline_config_path=pipeline.config \
--trained_checkpoint_prefix=train/model.ckpt-xxxxx \
--output_directory=output
该程序执行完后,我们可得到 frozen_inference_graph.pb 以及一堆检查点文件。
第2步:在视频流上使用
我们需要从视频源中提出每一帧,这可以使用 OpenCV 的 VideoCapture 方法完成,代码如下所示:
cap = cv2.VideoCapture()
flag = True
while(flag):
flag, frame = cap.read()
## -- Object Detection Code --
第一阶段使用的数据提取代码会使我们的测试集图像自动创建“test_images”文件夹。我们的模型可以通过执行以下命令在测试集上进行工作:
python object_detection/inference.py \
--input_dir={PATH} \
--output_dir={PATH} \
--label_map={PATH} \
--frozen_graph={PATH} \
--num_output_classes=1 \
--n_jobs=1 \
--delay=0
实验
正如前面所讲到的,在选择目标检测模型时,速度与准确度不可得兼。对此我们进行了一些实验,测量使用三种不同的模型检测到人的 FPS 和数量精确度。此外,我们的实验是在不同的资源约束 (GPU并行约束) 条件下操作的。
▌设置
我们的实验选择了以下的模型,这些模型可以在 TensorFlow 目标检测API 的Zoo 模块中找到。
Faster RCNN with ResNet 50
SSD with MobileNet v1
SSD with InceptionNet v2
所有的模型都在 Google Colab 上进行了 10k 步训练,通过比较模型检测到的人数与实际人数之间的接近程度来衡量计数准确度。在一下约束条件下测试 FPS 的推理速度。
Single GPU
Two GPUs in parallel
Four GPUs in parallel
Eight GPUs in parallel
结果
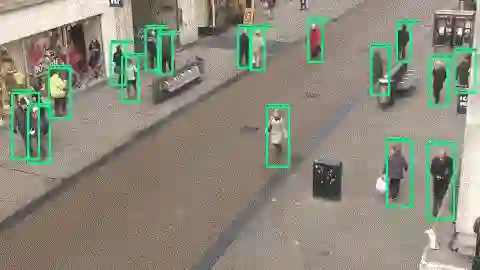
下面的 GIF 是我们在测试集上使用 FasterRCNN 输出的片段。
▌训练时间
图11展示了以10 k步 (单位:小时) 训练每个模型所需的时间 (不包括参数搜索所需要的时间)
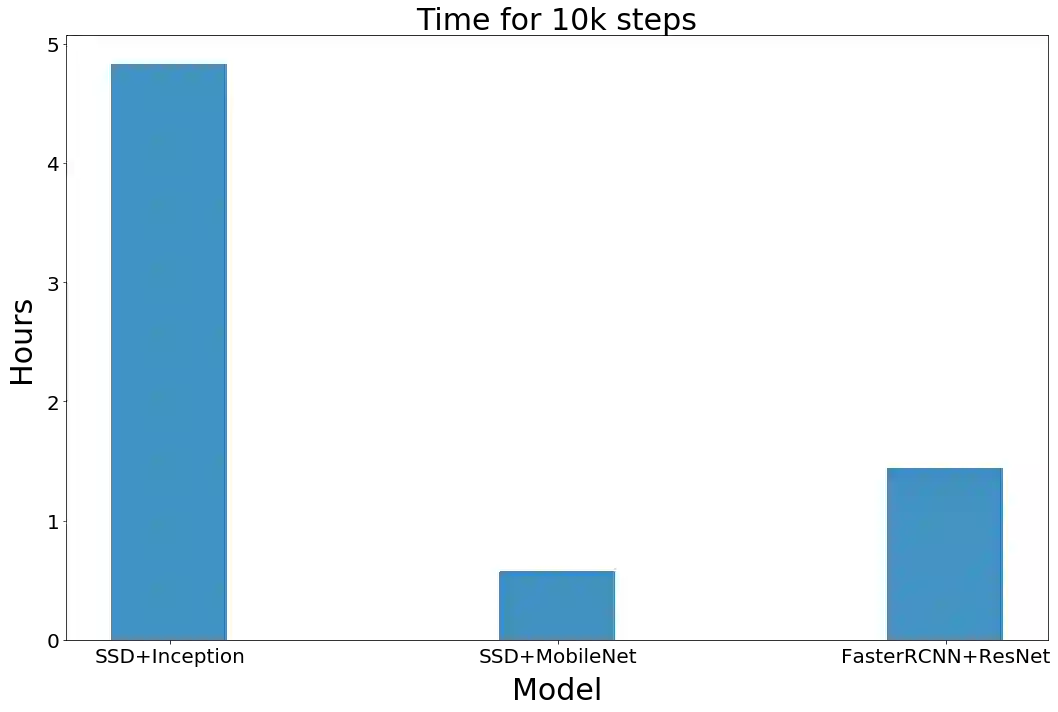
图11 各模型训练所需时间
▌速度 (每秒帧数)
在之前的实验中,我们测量了3种模型在5种不同资源约束下的 FPS 性能,其测量结果如图12所示:
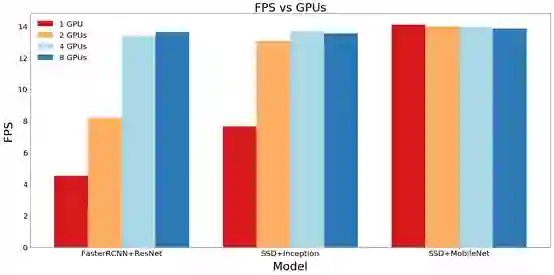
图12 使用不同 GPU 数量下的 FPS 性能
当我们使用单个 GPU 时,SSD速度非常快,轻松超越 FasterRCNN 的速度。但是当 GPU 个数增加时,FasterRCNN 很快就会追上 SSD 。
为了证明我们的结论:视频处理系统的速度不能高于图像输入系统的速度,我们优先读取图像。图13展示了添加延迟后带有 NobileNet +SSD 的 FPS 改进状况,从图13中可看出当我们加入延迟后,FPS 迅速增加。
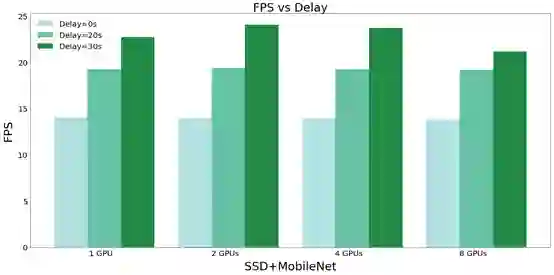
图13 增加不同延迟后模型的 FPS 改进状况
▌计数准确性
我们将计数准确度定义为目标检测系统正确识别出人脸的百分比。图14是我们每个模型精确度的表现,从图14中可看出 FasterRCNN 是准确度最高的模型,MobileNet 的性能优于 InceptionNet。
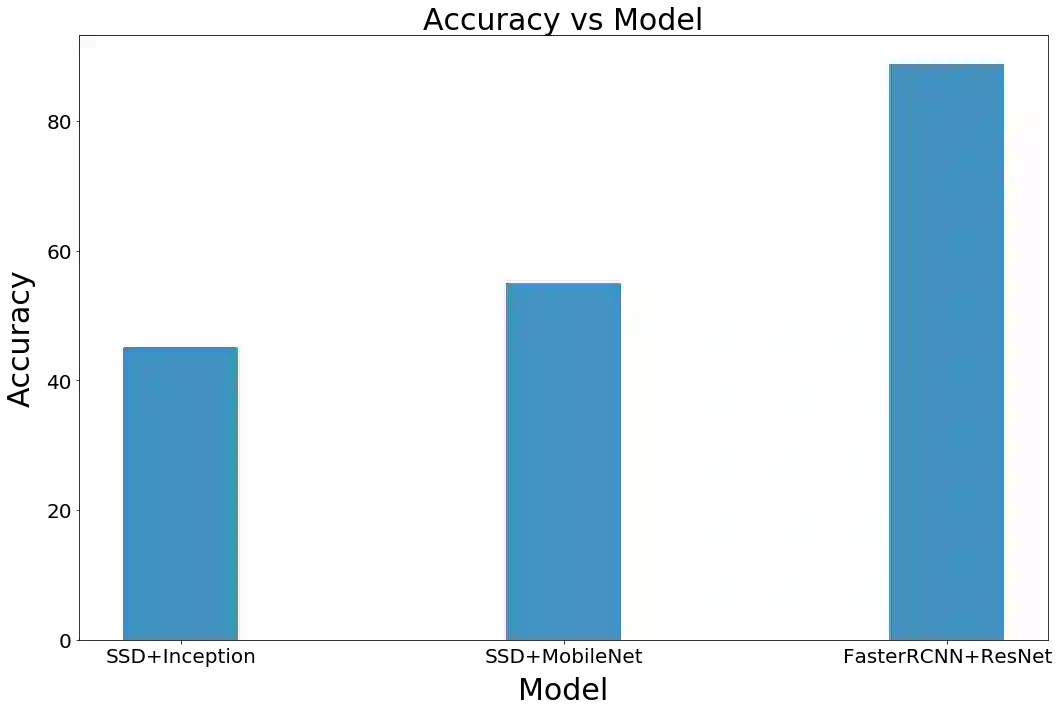
图 14 各模型计数精确度
Nanonets
看到这里相信大家都有一个共同的感受——步骤太多了吧!是的,如果是这样的一个模型在实际工作即繁重又昂贵。
为此,更好的解决方案就是使用已部署在服务器上的 API 服务。Nanonets 就提供了这样的一个 API,他们将 API 部署在带有 GPU 的高质量硬件上,以便开发者不用为性能而困扰。
Nanonets 可以减少工作的流程的方法在于:我将现有的 XML 注释转换成 JSON 格式并提供给 Nanonets API。所以当不想进行手动注释数据集时,可以直接请求 Nanonets API来为数据添加注释。
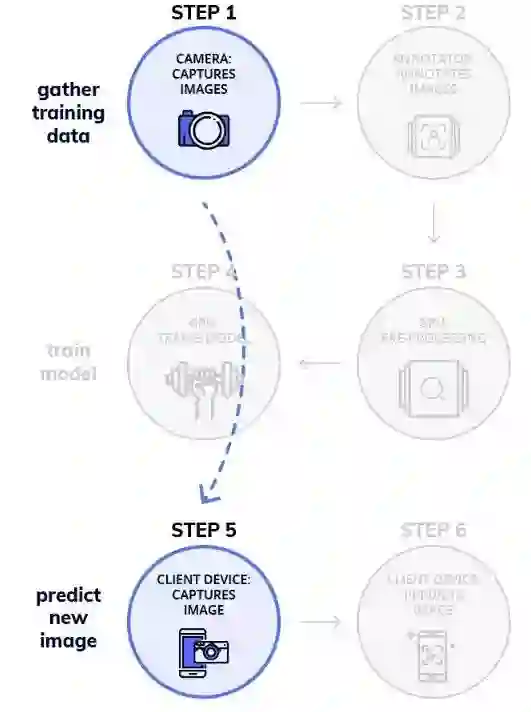
上图表示为减少后的工作流程
Nanonets 的训练时间大约花了 2 个小时,就训练时间而言,Nanonets 是明显的赢家,并且在准确性方面 Nanonets 也击败了 FasterRCNN。
FasterRCNN Count Accuracy = 88.77%
Nanonets Count Accuracy = 89.66%
下面的视频展现了我们的测试数据集中四个模型的性能。显然,两种 SSD 模型都有点不稳定并且精度较低。尽管 FasterRCNN 和 Nanonets 都有较高的精准度,但 Nanonets 具有更稳定的边界框。
自动监控的可信度有多高?
深度学习是一种令人惊叹的工具。但是我们在多大程度上可以信任我们的监控系统并自动采取行动?在以下几个情况下,自动化过程时需要引起注意。
▌可疑的结论
我们不知道深度学习算法是如何得出结论的。即使数据的馈送过程很完美,也可能存在大量虚假的成功例子。虽然引导反向传播在一定程度上可以解释决策,但是关于这方面的研究还有待我们进一步的研究。
▌对抗性攻击
深度学习系统很脆弱,对抗性攻击类似于图像的视错觉。计算出的不明显干扰会迫使深度学习模型分类失误。使用相同的原理,研究人员已经能够通过使用 adversarial glasses 来规避基于深度学习的监控系统。
▌误报
另一个问题是,如果出现误报我们该怎么做。该问题的严重程度取决于应用程序本身。例如边境巡逻系统的误报可能比花园监控系统更重要。
▌相似的面孔
外观并不像指纹一样独一无二,同卵双胞胎是最好的一个例子。这会带来恨大的干扰。
▌数据集缺乏多样性
深度学习算法的好坏和数据集有很大关联,Google 曾将一个黑人错误归类为大猩猩。
注:鉴于 GDPR 和以上原因,关于监控自动化的合法性和道德性问题是不可忽视的。此教程也是出于并仅用于学习分享目的。在教程中使用的公开数据集,所以在使用过程中有责任确保它的合法性。
原文链接
https://medium.com/nanonets/how-to-automate-surveillance-easily-with-deep-learning-4eb4fa0cd68d




工业互联网
产业智能官 AI-CPS
通过工业互联网操作系统(云计算+大数据+物联网+区块链+人工智能),在场景中构建:状态感知-实时分析-自主决策-精准执行-学习提升的机器智能和认知系统;实现产业转型升级、DT驱动业务、价值创新创造的产业互联生态链。
版权声明:产业智能官(ID:AI-CPS)推荐的文章,除非确实无法确认,我们都会注明作者和来源。涉权烦请联系协商解决。联系、投稿邮箱:erp_vip@hotmail.com




