CodeBERT: 面向编程语言和自然语言的预训练模型
论文名称:CodeBERT: A Pre-Trained Model for Programming and Natural Languages 论文作者:冯掌印,郭达雅,唐都钰,段楠,冯骁骋,公明,寿林钧,秦兵,刘挺,姜大昕,周明 原创作者:冯掌印 论文链接: https://arxiv.org/pdf/2002.08155.pdf 转载须标注出处:哈工大SCIR
摘要
1. 简介
2. 模型
我们采用了Transformer作为模型的基本网络结构。具体地,我们使用了和RoBERTa-base完全一样的结构,即都有12层,每层有12个自注意头,每个头的大小是64,隐层维度为768。模型参数的总数为125M。
在预训练阶段,将自然语言文本和编程语言的代码拼接起来作为输入,两部分内容均使用和RoBERTa-base一样的tokenizer。数据样例如图1所示。

图1 NL-PL数据对样例
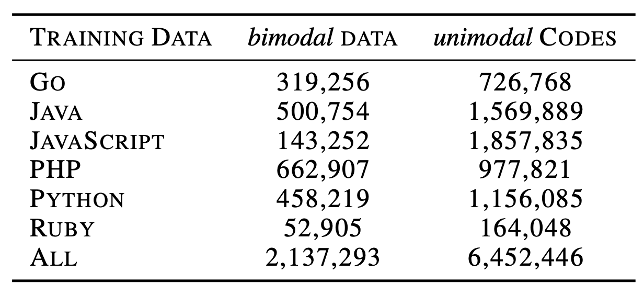
预训练数据集方面,我们使用了Husain等人在2019年提供的最新数据集CodeSearchNet,里面包括 2.1M双模数据和6.4M 单模数据,其中双模数据是指自然语言-代码对的并行数据,单模是指只有代码的数据。数据集中包括六种编程语言,具体数据统计结果见表1。
表1 预训练CodeBERT数据统计
为了同时利用双模数据和大规模的单模数据,我们提出了混合预训练目标:掩码语言模型(MLM) 和替换词检测(RTD)。
目标1:掩码语言模型。将NL-PL对作为输入,随机为NL和PL选择位置进行掩码,然后用特殊的掩码Token进行替换。掩码语言模型的目标是预测出原始的token。目标2:替换词检测。先分别用单模的自然语言和代码数据各自训练一个数据生成器,用于为随机掩码位置生成合理的备选方案。另外,还有一个判别器学习自然语言和代码之间的融合表示,来检测一个词是否为原词。判别器实际上一个二元分类器,如果生成器产生正确的Token,则该Token的标签为真,否则为假。模型架构如图2所示。
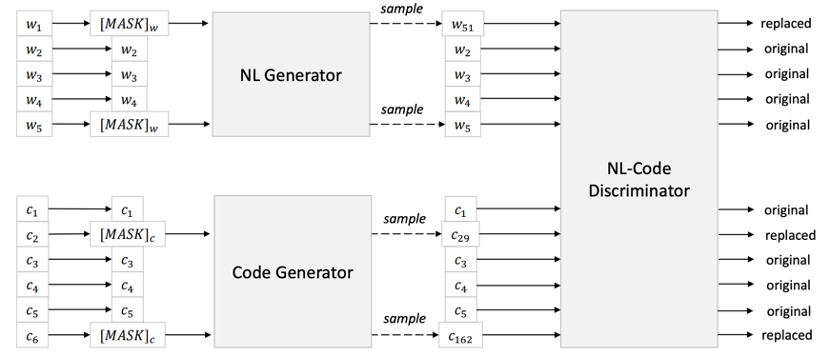
图2 替换词检测目标模型架构
最终,模型预训练目标为
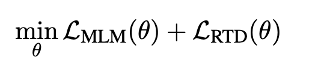
CodeBERT经过预训练之后,在下游任务使用时需要微调。例如在自然语言代码搜索中,会使用与预训练阶段相同的输入方式。而在代码到文本的生成中,使用编码器-解码器框架,并使用CodeBERT初始化生成模型的编码器。
3.实验
我们选了四个不同的设置来验证模型的有效性,分别是自然语言代码检索,NL-PL的probing,代码文档生成,在未经过预训练编程语言上模型的泛化性。
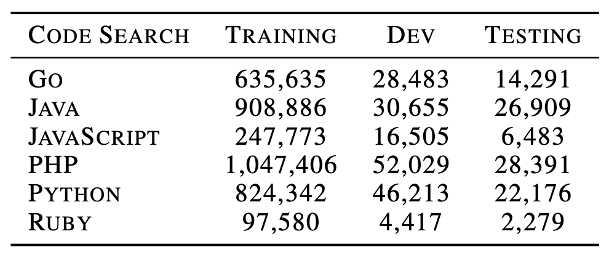
自然语言代码检索 给定一段自然语言作为输入,代码搜索的目标是从一组代码中找到语义上最相关的代码。为了进行比较,我们选择了Husain 等人在2019年发布的 CodeSearchNet 语料库进行训练,数据集中包括六种编程语言,各种语言的数据统计如表2所示。
表2 自然语言代码检索数据集统计
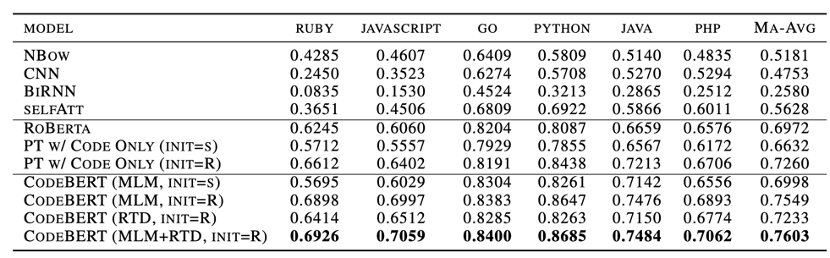
我们保持和官方一致,使用MRR作为评价指标。另外,我们计算了六种编程语言上的宏平均作为整体的评价指标。结果如表3所示,相比之前的模型,我们的模型取得了明显的提升。
表3 自然语言代码检索结果
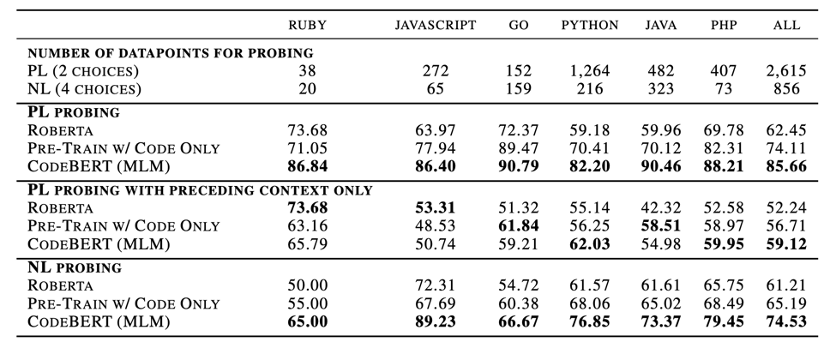
NL-PL Probing 这部分实验主要研究在固定模型参数的情况下,研究CodeBERT学习到了哪些类型的知识。目前学界还没有针对NL-PL Probing的工作,所以在这部分实验中,我们首先创建了数据集。具体地,我们将其构造成了多项选择题任务,给定输入,让模型选择正确的结果。根据输入和选项的不同,数据集又分为三个部分。模型比较结果如表4所示,结果显示,我们的模型在三个不同的设置下都能够达到最好的结果。
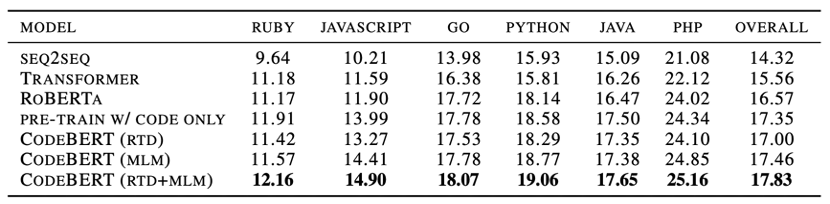
代码文档生成 我们研究了在预训练的六种编程语言上,代码到文档的生成问题。为了证明CodeBERT在代码到文档生成任务中的有效性,我们采用了各种预训练的模型作为编码器,并保持了超参数的一致性。实验结果如表5所示,我们的模型在所有编程语言类别上均获得最好的效果。
表5 代码文档生成结果
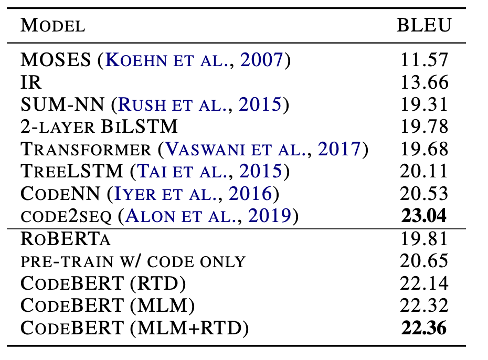
泛化能力 为了进一步研究模型的泛化性,我们在代码文档生成任务中,在C#编程语言上进行了测试。我们选择了Codenn数据集,这是一个包含Stack Overflow自动收集的66015对问题和答案的数据集,并采取了和原论文同样的设置进行实验。结果如表6所示,相比RoBERTa,我们的模型能够取得更好的结果。但是,我们的模型效果略低于Code2Seq,这可能是因为该模型有效使用了代码中的AST信息。
表6 C#生成结果
4.总结
在本工作中,我们提出了第一个面向编程语言和自然语言的预训练模型,并且在下游的自然语言代码检索,代码文档生成任务上,我们的模型均取得了SOTA的效果。另外,我们构造了第一个NL-PL Probing数据集来研究预训练模型学到了哪种类型的知识。虽然我们的模型已经取得了很好的效果,但也有很多潜在的方向值得进一步研究,比如在预训练过程加入与生成相关的目标函数,加入编程语言的AST结构信息等。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“CodeBERT” 可以获取《CodeBERT: 面向编程语言和自然语言的预训练模型》专知下载链接索引







