Maxout Network原理及其TensorFlow实现
Maxout Network原理及其TensorFlow实现
本文参考文献
Goodfellow I J, Warde-Farley D, Mirza M, et al. Maxout networks[J]. arXiv preprint arXiv:1302.4389, 2013.
被引次数:760
深度神经网络在语音识别、计算机视觉、自然语言处理等领域不仅胜过了传统的浅层机器学习算法,更在一些任务上超越了人类。相比于浅层的机器学习模型,深度神经网络更容易陷入过拟合的状态,而避免此状态的一个最成功的技巧无疑就是Dropout,Dropout通过在层与层之间随机添加一些噪声,从而使得神经网络的性能大幅提高。
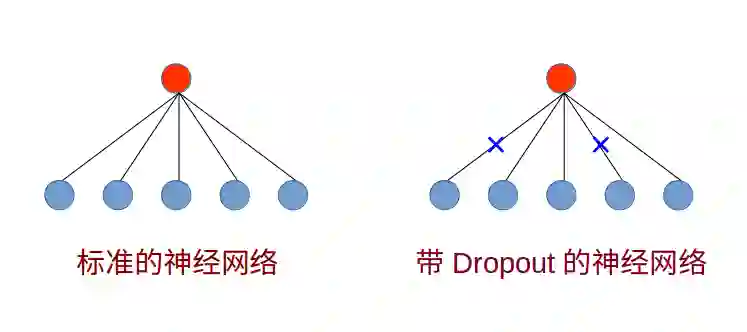
这里我要补充说明的是,Dropout是由Hinton提出的一个网络正则化技巧,Dropout在训练阶段和推理阶段的工作是不一样的,就训练阶段而言,Dropout允许神经元具有p的概率与下一层神经元相连;而在推理阶段,该层神经元始终是与下一层神经元相连的,只不过在原有权重因子的基础上要乘以Dropout比率p。
仿照Dropout的思想,在卷积神经网络中,如果下一层的feature map是对上一层多个feature map的Dropout,更严格说就是对上一层多个feature map的取最值,就得到了今天要讲的由Goodfellow提出的Maxout Network,值得注意的是,Goodfellow也是最近非常火热的GAN的发明者。
1.Maxout是一种内置MLP的激活函数
Maxout模型实际上也是一种新型的激活函数,在前馈式神经网络中,Maxout的输出即取该层的最大值,在卷积神经网络中,一个Maxout feature map可以是由多个feature map取最值得到。
我们知道,多层感知器(MLP)是一种通用的函数拟合器,也就是说它可以拟合任意复杂的函数,只不过有些函数使用MLP来训练比较麻烦而已。
而Maxout模型恰好是一种基于MLP的激活函数,因为每个Maxout模型内部可以包含任意的仿射变换,这就导致了Maxout模型也是一个通用的函数拟合器。
例如如下图所示,是一个包含4个神经元的Maxout网络,从输入层到Maxout的输出,是经过了三个仿射变换,我们可以认为这三个仿射变换就是三个特征提取器,此变换中没有任何非线性激活函数,完全是一个线性变换,最终由这三个变换取最大值得到Maxout的4个输出神经元。
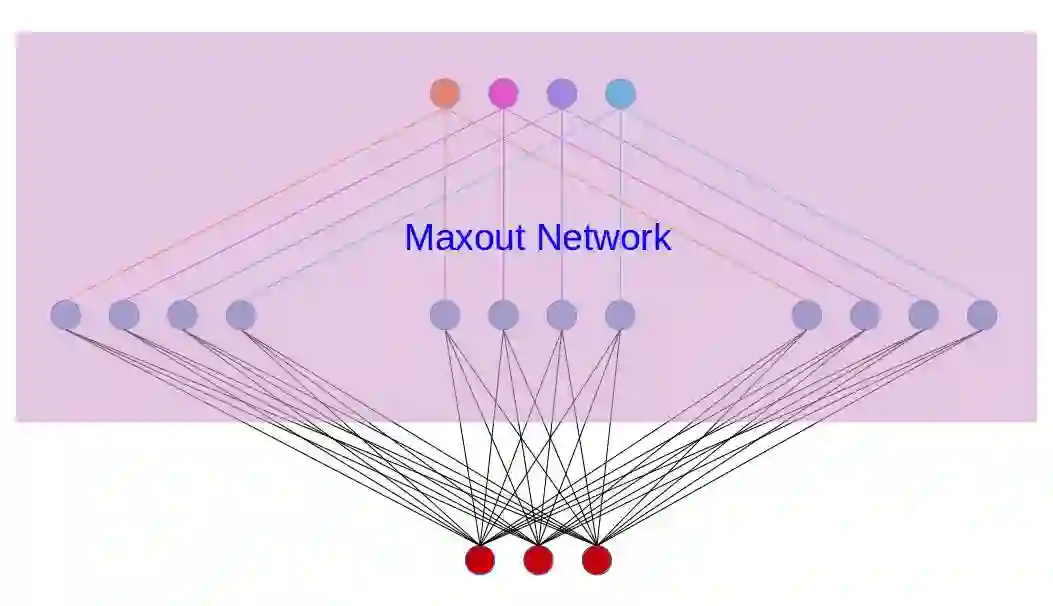
根据上图,我们可以看到,假如输入变量的维度是2,那么Maxout中的权重变量就是4维,因为多余的两个维度分别是Maxout自身神经元的个数以及特征提取器的个数。
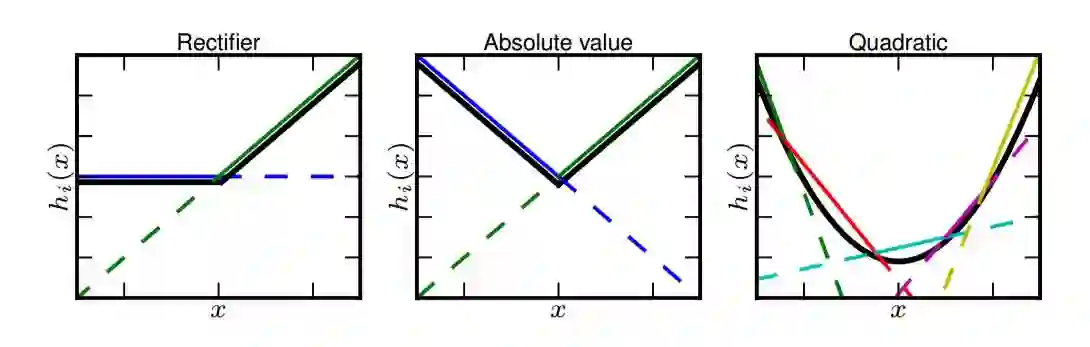
我们再回到前面所说的Maxout的通用拟合的功能,下图是原始论文中出现的一张图,其目的是告诉我们无论是ReLU函数,还是V型函数还是二次型函数,我们都可以通过构造多个仿射变换来对其进行逼近,并且在每个区间内取其最大值即可。这不就是Maxout的功能吗?虽然这里只给出了二维函数的逼近示意图,但是实际上Maxout可以拟合任意的凸函数。
2.Maxout可以与Dropout同时使用提升网络性能
Dropout是一种网络规则化技巧,其实它就是相当于在训练很多个不同的网络结构,尽管如此,推理阶段所有不同结构的参数依然是共享的,因为实际上只有一个网络存在。
在机器学习算法中,有一个概念叫做bagging,bagging就相当于提供了一种投票机制,对于一个任务,我们不是仅仅使用一个模型来做出决策,而是通过多个模型的平均来决定最终的决策。
由于在Dropout中仅仅只有一个模型,因此无法进行平均操作,取而代之的是将模型的权重乘以Dropout比率p,这个做法在线性激活函数中表现尚可,但是如果是经过非线性激活函数那就不准确了。而Maxout模型的仿射变换中没有非线性激活函数,因此我们也可以在此变换中引入Dropout技巧,并且实验表明Maxout与Dropout的结合效果比较好。
Maxout原理部分就介绍到这里了,接下来就是基于TensorFlow来实现CNN+Maxout网络的代码,仅供参考。
import tensorflow as tf
def maxout_cnn_layer(inputs, filter, bind_num,strides, padding, name=None):
conv = tf.nn.conv2d(input=inputs,
filter=filter,
strides=strides,
padding=padding,
name=name)
return maxout(conv, bind_num)
def maxout_weights(filter_shape,bind_num):
filter_shape[-1]=filter_shape[-1]*bind_num
return tf.Variable(tf.random_normal(filter_shape, stddev=0.01))
def maxout(inputs, bind_num):
shape = inputs.get_shape().as_list()
in_chan = shape[-1]
shape[-1] = in_chan//bind_num
shape += [bind_num]
shape[0]=-1
return tf.reduce_max(tf.reshape(inputs,shape),-1,keep_dims=False)题图:Pawel Kuczynski
你可能会感兴趣的文章有:
Network-in-Network原理及其TensorFlow实现
如何基于TensorFlow实现ResNet和HighwayNet
深度残差学习框架(Deep Residual Learning)
推荐阅读 | 如何让TensorFlow模型运行提速36.8%
推荐阅读 | 如何让TensorFlow模型运行提速36.8%(续)
深度学习每日摘要|坚持技术,追求原创




