从零开始深度学习第14讲:CNN经典论文研读之Le-Net5及其TensorFlow实现
在前几次笔记中,笔者基本上将卷积神经网络的基本原理给讲完了。从本次笔记开始,笔者在深度学习笔记中会不定期的对 CNN 发展过程中的经典论文进行研读并推送研读笔记。今天笔者就和大家一起学习卷积神经网络和深度学习发展历史上具有奠基性的经典论文之一的关于 LeNet-5 网络一文。LeNet-5 是由具有卷积神经网络之父之美誉的 Yann LeCun 在1998年发表在 IEEE 上面的一篇 Gradient-based learning applied to document recognition 上提出来的,所以直接由 LeCun 大佬名字命名了。
论文原文:
http://yann.lecun.com/exdb/publis/pdf/lecun-01a.pdf
LeNet-5 网络结构
该篇论文有 42 页,但关于 LeNet-5 网络的核心部分并没有那么多,我们直接定位第二章的B 小节进行阅读。LeNet-5 的网络结构如下:
LeNet-5 共有 7 层,输入层不计入层数,每层都有一定的训练参数,其中三个卷积层的训练参数较多,每层都有多个滤波器,也叫特征图,每个滤波器都对上一层的输出提取不同的像素特征。所以 LeNet-5 的简略结构如下:
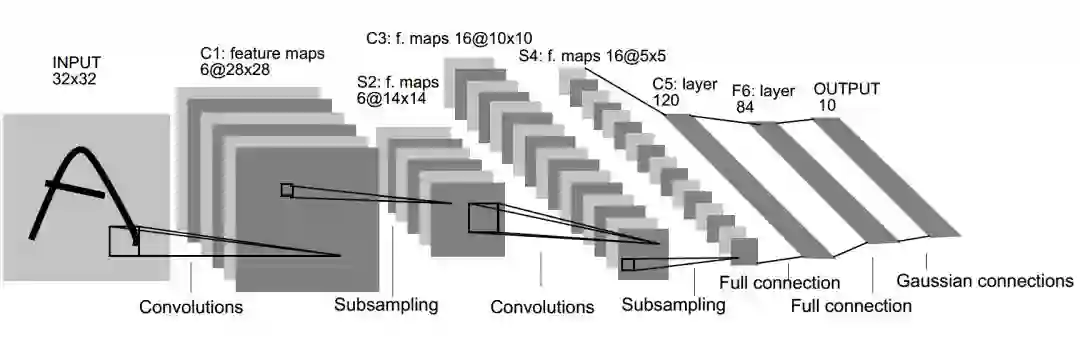
输入-卷积-池化-卷积-池化-卷积(全连接)-全连接-全连接(输出)
各层的结构和参数如下:
C1层是个卷积层,其输入输出结构如下:
输入: 32 x 32 x 1 滤波器大小: 5 x 5 x 1 滤波器个数:6
输出: 28 x 28 x 6
参数个数: 5 x 5 x 1 x 6 + 6 = 156
P2层是个池化层,其输入输出结构如下:
输入: 28 x 28 x 6 滤波器大小: 2 x 2 滤波器个数:6
输出: 14 x 14 x 6
参数个数:2 x 6 = 12
在原文中,P1池化层采用的是平均池化,鉴于现在普遍都使用最大池化,所以在后面的代码实现中我们统一采用最大池化。
C3层是个卷积层,其输入输出结构如下:
输入: 14 x 14 x 6 滤波器大小: 5 x 5 x 6 滤波器个数:16
输出: 10 x 10 x 16
参数个数: 5 x 5 x 6 x 16 + 16 = 2416
P2 池化之后的特征图组合计算得到C3的滤波器个数。
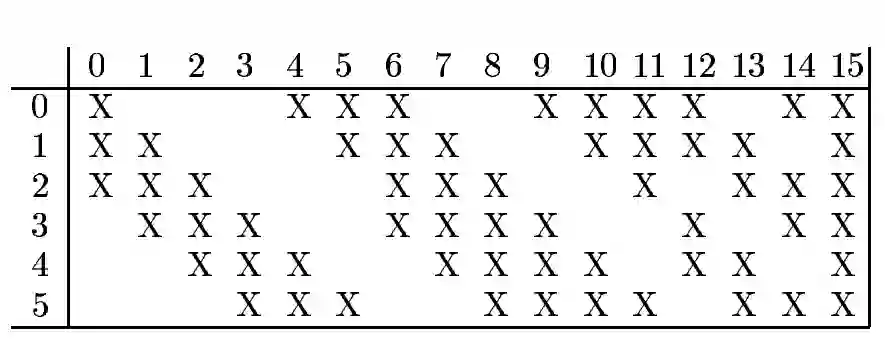
P4层是个池化层,其输入输出结构如下:
输入: 10 x 10 x 16 滤波器大小: 2 x 2 滤波器个数:16
输出: 5 x 5 x 16
参数个数: 2 x 16 = 32
C5层在论文中是个卷积层,但滤波器大小为 5 x 5,所以其本质上也是个全连接层。如果将5 x 5 x 16 拉成一个向量,它就是一个全连接层。其输入输出结构如下:
输入: 5 x 5 x 16 滤波器大小: 5 x 5 x 16 滤波器个数:120
输出: 1 x 1 x 120
参数个数: 5 x 5 x 16 x 120 + 120 = 48120
F6层是个全连接层,全连接的激活函数采用的是 tanh 函数,其输入输出结构如下:
输入:120
输出:84
参数个数:120 x 84 + 84 = 10164
F7层即输出层,也是个全连接层,其输入输出结构如下:
输入:84
输出:10
参数个数: 84 x 10 + 10 = 850
LeNet-5 的 Tensorflow 实现
我们前面关于如何使用 Tensorflow 搭建卷积神经网络的过程可以定下实现 LeNet-5 的基本思路。如果在 python 中写的时候我们需要定义创建输入输出的占位符变量模块、初始化各层参数模块、创建前向传播模块、定义模型优化迭代模型,以及在最后设置输入数据。
下面笔者用以上思路编写一个 LeNet-5 的简单实现代码。
导入相关库和创建输入输出的占位符变量:
import tensorflow as tf
import numpy as np
from tensorflow.examples.tutorials.mnist import input_data
def create_placeholder():
X = tf.placeholder(tf.float32, shape=(None, 28 * 28))
Y = tf.placeholder(tf.float32, shape=(None, 10))
keep_prob = tf.placeholder(tf.float32)
return X, Y, keep_prob初始化各层参数:
def initialize_parameters():
W1 = tf.get_variable('W1', [5,5,1,6], initializer=tf.contrib.layers.xavier_initializer())
b1 = tf.get_variable('b1', [6], initializer=tf.zeros_initializer())
W2 = tf.get_variable('W2', [5,5,6,16], initializer=tf.contrib.layers.xavier_initializer())
b2 = tf.get_variable('b2', [16], initializer=tf.zeros_initializer())
W3 = tf.get_variable('W3', [5, 5, 16, 120], initializer=tf.contrib.layers.xavier_initializer())
b3 = tf.get_variable('b3', [120], initializer=tf.zeros_initializer())
W4 = tf.get_variable('W4', [120, 84], initializer=tf.contrib.layers.xavier_initializer())
b4 = tf.get_variable('b4', [84], initializer=tf.zeros_initializer())
W5 = tf.get_variable('W5', [84, 10], initializer=tf.contrib.layers.xavier_initializer())
b5 = tf.get_variable('b5', [10], initializer=tf.zeros_initializer())
para = {'W1': W1,
'b1': b1,
'W2': W2,
'b2': b2,
'W3': W3,
'b3': b3,
'W4': W4,
'b4': b4,
'W5': W5,
'b5': b5}
return para创建 LeNet-5 的前向计算:
def forward_propagation(X, para, dropout):
X = tf.reshape(X, [-1, 28, 28, 1])
X = tf.pad(X, [[0,0],[2,2],[2,2], [0,0]])
c1 = tf.nn.conv2d(X, para['W1'], strides=[1, 1, 1, 1], padding='VALID') + para['b1']
p2 = tf.nn.max_pool(c1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='VALID')
c3 = tf.nn.conv2d(p2, para['W2'], strides=[1, 1, 1, 1], padding='VALID') + para['b2']
p4 = tf.nn.max_pool(c3, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='VALID')
c5 = tf.nn.conv2d(p4, para['W3'], strides=[1, 1, 1, 1], padding='VALID') + para['b3']
c5 = tf.contrib.layers.flatten(c5)
f6 = tf.nn.tanh(tf.add(tf.matmul(c5, para['W4']), para['b4']))
f7 = tf.nn.tanh(tf.add(tf.matmul(f6, para['W5']), para['b5']))
f7 = tf.nn.dropout(f7, dropout)
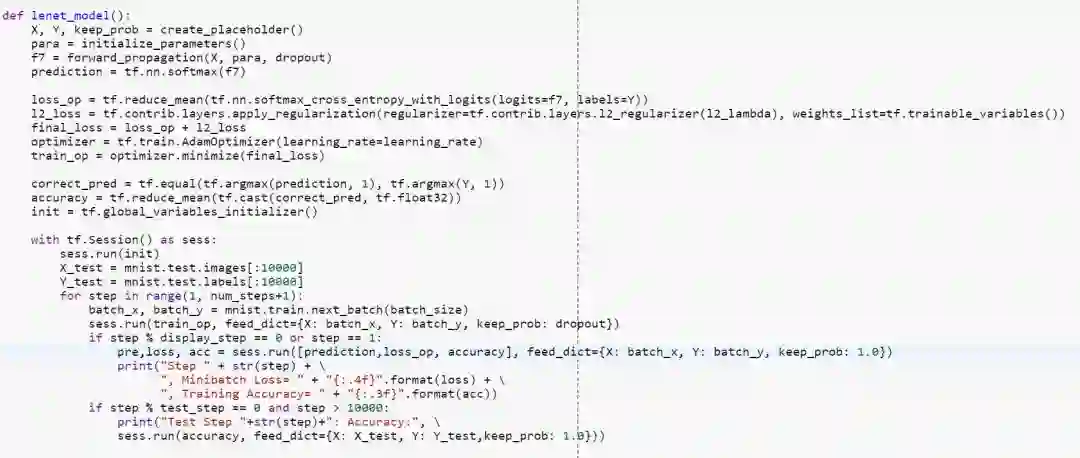
return f7创建模型优化计算函数:
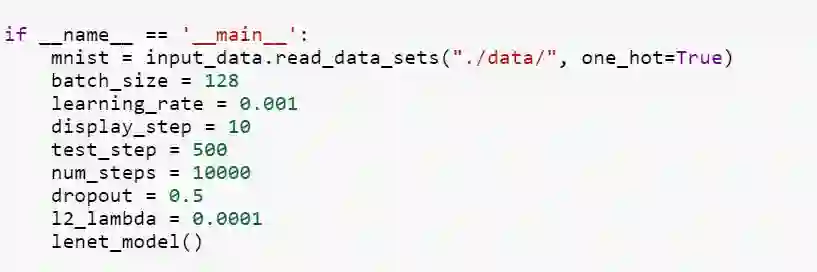
最后传入 mnist 数据和相关超参数:
注:本深度学习笔记系作者学习 Andrew NG 的 deeplearningai 五门课程所记笔记,其中代码为每门课的课后assignments作业整理而成。
参考资料:
https://www.coursera.org/learn/machine-learning
https://www.deeplearning.ai/
http://yann.lecun.com/exdb/publis/pdf/lecun-01a.pdf
https://github.com/xiao-data/lenet/blob/master/lenet.py
推荐阅读
从零开始深度学习第13讲:Tensorflow实战之mnist手写数字识别
从零开始深度学习第12讲:卷积神经网络的Tensorflow实现
从零开始深度学习第11讲:利用numpy搭建一个卷积神经网络
从零开始深度学习第8讲:利用Tensorflow搭建神经网络



