何以为猫?可解释AI从语义层面理解CNN的识别机制
机器之心专栏
来自北京大学、东方理工、南方科技大学和鹏城实验室等机构的研究团队提出了一种语义可解释人工智能(semantic explainable AI, S-XAI)的研究框架,该框架从语义层面解释了 CNN 的学习机制。
近年来,CNN 因其优异的性能,在计算机视觉、自然语言处理等各个领域受到了研究者们的青睐。但是,CNN 是一个 「黑盒」 模型,即模型的学习内容和决策过程很难用人类能够理解的方式提取和表达,这限制了它的预测可信度和实际应用。因此,CNN 的可解释性受到了越来越多的关注,研究者们试图采用特征可视化,网络诊断和网络架构调整等方式辅助解释 CNN 的学习机制,从而将这一 「黑盒」 透明化,使人类更容易理解、检测和改进其决策过程。
近日,北京大学,东方理工,南方科技大学和鹏城实验室等机构的研究团队提出了一种语义可解释人工智能(semantic explainable AI, S-XAI)的研究框架,从语义层面解释了 CNN 的学习机制,并以猫狗二分类问题为例,形象地揭示了模型是如何学习类别意义上的猫的概念,即「何以为猫」。

该研究聚焦于 CNN 从同一类别的样本中学习到的共性特征,并提取出人类可理解的语义概念,为 CNN 提供了语义层面的解释。基于此,研究首次提出了 「语义概率(semantic probability)」 的概念来表征语义要素在样本中的出现概率。实验表明,S-XAI 在二分类和多分类任务中均能成功地提取共性特征并抽象出超现实但可辨认的语义概念,在可信度评估和语义样本搜索等层面有着广泛的应用前景。
该研究以《Semantic interpretation for convolutional neural networks: What makes a cat a cat?》为题,于 2022 年 10 月 10 日发表于《Advanced Science》上。

论文链接:https://onlinelibrary.wiley.com/doi/10.1002/advs.202204723
代码链接:https://github.com/woshixuhao/semantic-explainable-AI
模型效果
不同于以往的单样本可视化研究,S-XAI能够提取并可视化群体样本的共性特征,从而获得全局可解释性。在进一步抽象出的语义空间与计算出的语义概率的基础上,S-XAI 可以为 CNN 的决策逻辑自动生成人类可理解的语义解释,并且从语义层面上评估决策的可信度。
如图 1 所示,在猫狗二分类问题中,对于同一只猫的三个角度的图片,S-XAI 自动生成了相应的语义概率雷达图和解释语句。虽然神经网络都以 90% 以上的概率将这些图片识别为猫,但是 S-XAI 从语义概率上提供了更多的解释信息,体现出这些图片之间的差异。例如,对于正面的图像,S-XAI 的解释是 「我确信它是一只猫,主要是因为它有着生动的眼睛和鼻子,显然是猫的眼睛和鼻子。同时,它有着栩栩如生的腿,有点像猫的腿。」 这个解释显示出很高的可信度。对于侧面角度的图像,S-XAI 的解释是 「它可能是一只猫,主要是因为它有眼睛,也许是猫的眼睛,但是它的腿是有点令人困惑。」 对于猫背面的图像,所有的语义概率均不明显,S-XAI 的解释是 「它可能是一只猫,但我不确定。」 同时,对于一张狗的图片,S-XAI 的解释为:「我确信它是一只狗,主要是因为它有生动的眼睛和鼻子,这显然是狗的眼睛和鼻子。虽然它的腿有点令人困惑。」
事实上,如果将这只狗的上半身遮盖住,只看腿部,即使是人类也很难判断这是猫还是狗。可以看出,S-XAI 提供的语义解释较为准确,且与人类的认知相一致,从语义层面让人类更好地理解神经网络的类别识别逻辑。
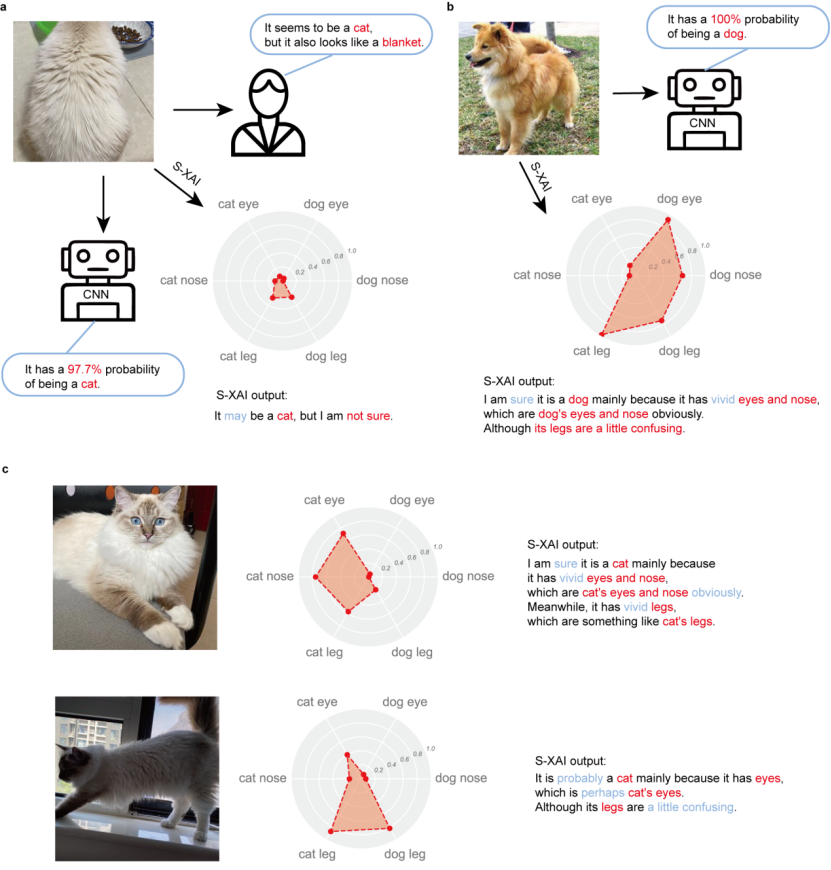
图 1. S-XAI 自动生成的语义概率雷达图和解释语句
同时,S-XAI 在语义样本搜寻中也有广阔的应用前景。如图 2 所示,当人们需要从大量图片中筛选出具有某些语义特征的图片时,S-XAI 提供了一种快捷且准确的方式,即通过语义概率进行筛选。考虑到计算语义概率只涉及神经网络的前向操作(即预测),该流程十分迅速。

图 2. 语义样本搜寻示例
在研究中,研究人员也证明了 S-XAI 在多分类任务上有着良好的拓展性。如图 3 所示,以 Mini-ImageNet 数据集(包含 100 种动物类别)为例,S-XAI 仍然能够从不同类别数据(如鸟,蛇,螃蟹,鱼等)中分别提取出清晰可辨认的共性特征和语义空间,并产生相应的语义解释。
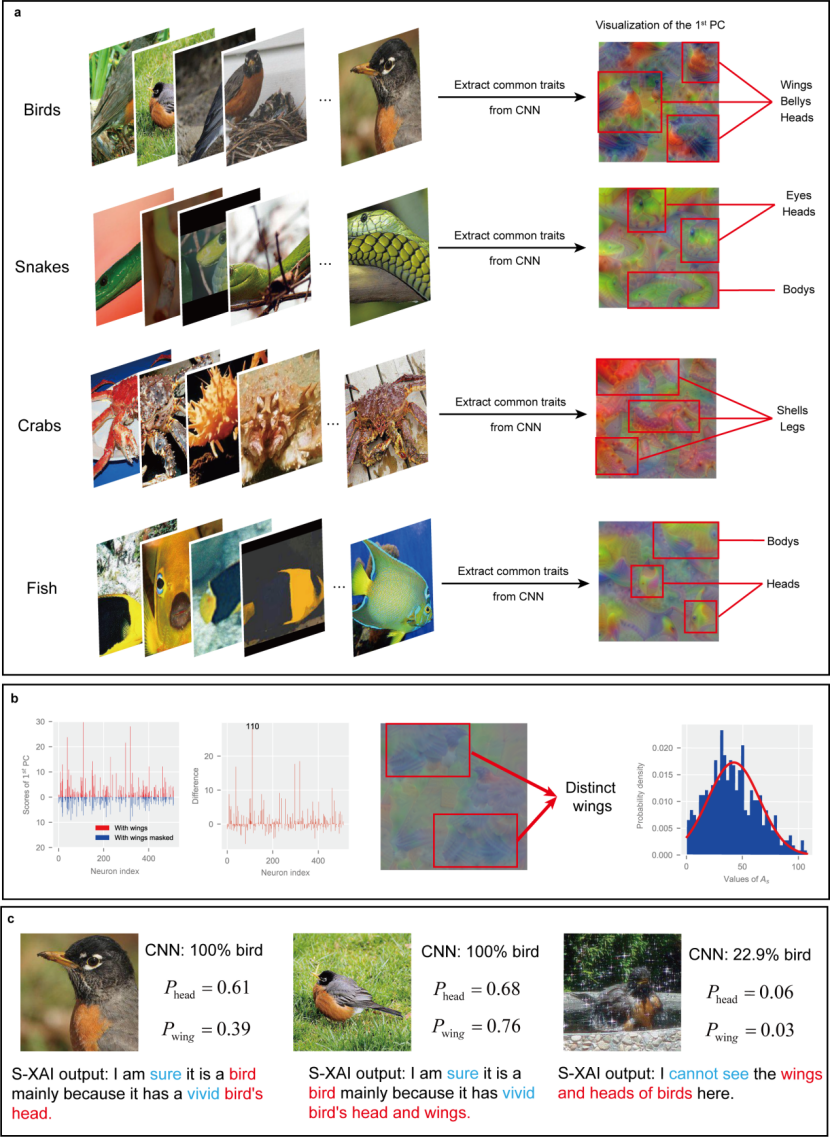
图 3. S-XAI 在多分类任务中的表现。
原理方法
目前常见的提高模型解释性的思路主要分为可视化和模型干预两大类。可视化方法将 CNN 内部的特征图,过滤器或热力图进行可视化,从而理解网络在面对给定样本时关注到的特征。该方法的局限性在于它只能从单个样本中提取个体特征以获得局部可解释性,无法帮助人们理解模型面对同一类数据时的整体决策逻辑。模型干预方法则将已有的一些解释性强的模型(如树模型等)融入到神经网络的架构中,以提升模型的可解释性能力。虽然此类方法具有全局可解释性的优势,但往往需要重新训练模型,解释成本较大,不利于推广和应用。
受人类认知模式的启发,在 S-XAI 中,研究人员采用了一种新的解释策略,从语义层面来解释 CNN 的类别学习机制(图 4)。在自然界中,相同种类的物体往往具有某些相似的共性特征,这些共性特征构成了类别认知的重要基础。例如,尽管猫的形态各异,但它们都具有一些共性特征(如胡须,鼻子和眼睛的相关特征),这使得人类能够快速地将它们判断为猫。在实验中,研究人员发现,CNN 的类别学习机制与人类有异曲同工之处。
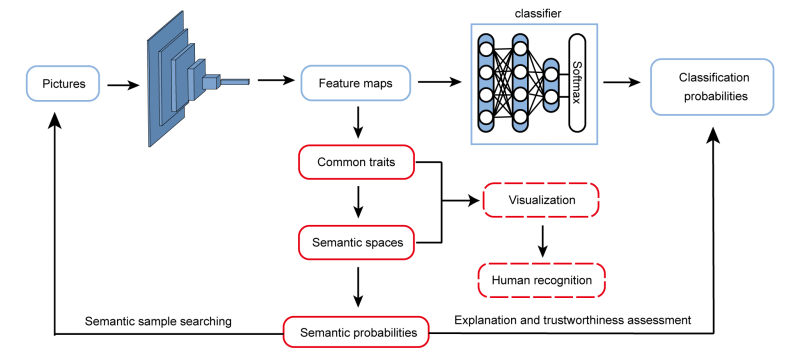
图 4. 语义可解释人工智能研究框架
研究中采用了一种名为行中心样本压缩(row-centered sample compression)的技术,从 CNN 中提取出了从同一类别样本中学习到的共性特征。不同于传统的主成分分析,行中心样本压缩将大量样本在 CNN 中得出的特征图在样本空间上进行降维,从而提取出少量主成分作为 CNN 学习到的共性特征。为了使提取出的共性特征更清晰,样本通过超像素分割和遗传算法找出了最优的超像素组合以降低干扰。提取出的共性特征则通过可视化的方式展现出来(图 5)。
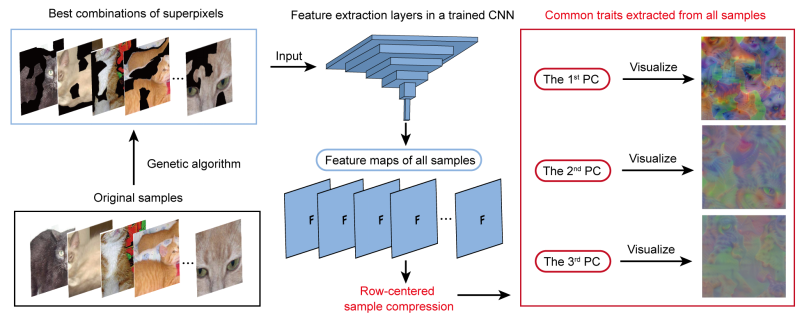
图 5. 共性特征的提取路径
以 VGG-19 网络架构上的猫狗二分类问题为例,对猫和狗的类别数据分别提取出的不同主成分如图 6 所示。图中可以清晰地看出不同主成分展现出了可辨认的,不同层次的特征。很明显,第一主成分显示出完整的脸部特征,第二主成分显示出零散的语义概念,如胡须、眼睛和鼻子等,第三主成分则主要呈现出毛皮的特质。值得一提的是,这些主成分展现出的特征是超自然的,即不属于任何样本,而是体现出了所有同类别样本的共同特征。

图 6. 对猫和狗的类别数据分别提取出的不同主成分的可视化结果
基于提取出的共性特征,研究人员通过对样本中的语义信息进行掩码 (mask) 处理,对比主成分的变化,进一步地将其中杂糅在一起的语义概念分离开来,从而提取出各语义概念对应的语义向量,抽象出语义空间。在这里,研究人员使用了眼睛,鼻子等人类理解的语义概念,并将抽象出的语义空间可视化。在成功提取语义空间后,研究人员定义了 「语义概率」 的概念以表征语义要素在样本中的出现概率,从而为 CNN 的语义层面的解释提供了定量分析的手段。
如图 7 所示,语义空间中出现了清晰可辨认的语义概念(明亮的眼睛,小巧的鼻子),这表明语义空间被成功地从 CNN 中提取出来,展示了 CNN 从类别数据中学习到的语义信息。同时,研究者发现 CNN 对语义的认知与人类存在一定的差异,它所学习到的 “语义” 并不一定是人类共识的“语义”,甚至可能神经网络的语义更加高效。例如,研究者发现,对于猫而言,CNN 经常会将猫的鼻子和胡须作为一个整体的语义,这或许是更有效的。同时,CNN 学习到了语义之间的一些联系,例如猫的眼睛和鼻子往往是同时出现的,这一方面值得后续深入的研究。
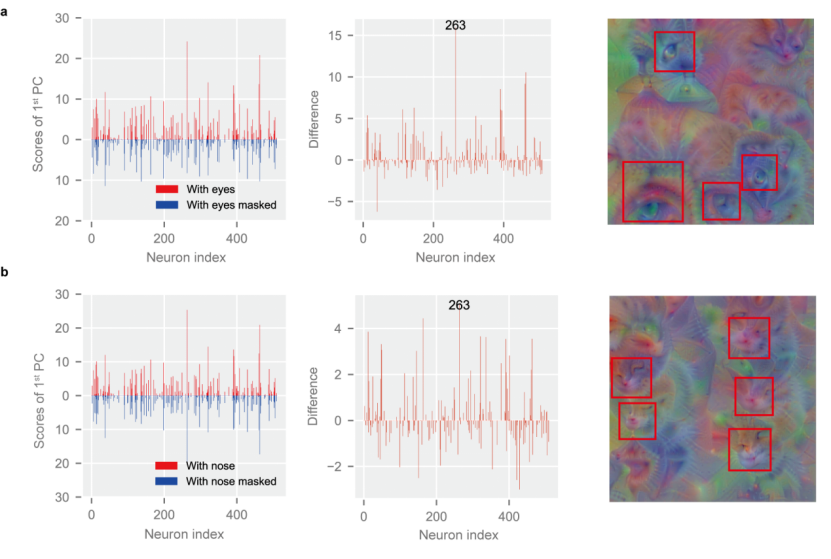
图 7. 从 CNN 中提取出的语义向量与可视化的语义空间(上:猫眼睛空间;下:猫鼻子空间)
总结展望
综上所述,研究中提出的语义可解释人工智能(S-XAI)通过提取共性特征和语义空间,从语义层面上为 CNN 的类别识别机制提供了解释。该研究框架无需改变 CNN 的架构即可获取一定的全局解释能力,由于不涉及网络的重新训练,S-XAI 具有响应速度较快的优势,在可信度评估和语义样本搜寻方面有着可观的应用潜力。
本质上而言,S-XAI 与知识发现有着异曲同工之处。知识发现意图从神经网络找出反映共性物理规律的函数项,S-XAI 则是从 CNN 中找出反映样本共性特征的语义空间,二者的核心思想均为寻找共性并将其表示出来,尽可能的让人类可以理解。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com

