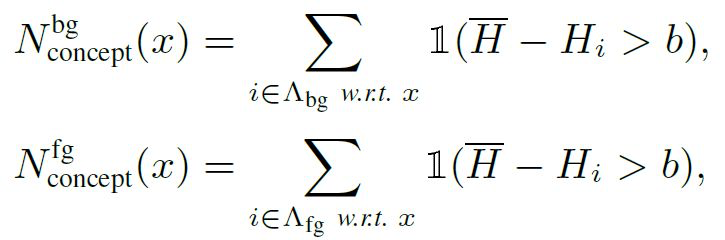加入极市专业CV交流群,与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
作者:Qs.Zhang张拳石
知乎链接:https://zhuanlan.zhihu.com/p/113811002
本文已由作者授权转载,未经允许,不得二次转载。
“Explaining Knowledge Distillation by Quantifying the Knowledge” in CVPR2020
论文链接:
https://arxiv.org/abs/2003.03622
本研究旨在从一个新的角度解释知识蒸馏算法,即通过量化神经网络所建模的“知识量”分析神经网络的性能。目前,神经网络可解释性的研究主要分为两个流派:一是从语义层面解释神经网络所建模的特征,譬如可视化中层特征,或是提取对结果影响显著的关键性像素;二是从数学层面分析神经网络的表达能力,例如评测神经网络的泛化能力或鲁棒性。但是学界尚未有理论工具打通神经网络语义解释与表达能力分析的连通壁垒,实现对二者的统一建模。
本研究核心在于通过定义并量化神经网络中层特征的“知识量”,从神经网络表达能力的角度来解释知识蒸馏算法的成功机理。我们提出并验证以下三个Hypotheses:
Hypothesis 1:比起直接从数据学习,蒸馏算法往往使得深度神经网络(DNN)学到更多的知识;
Hypothesis 2:比起直接从数据学习,蒸馏算法往往使得DNN更倾向于同时学到不同知识;
Hypothesis 3:比起直接从数据学习,蒸馏算法往往使得DNN的优化方向更为稳定。
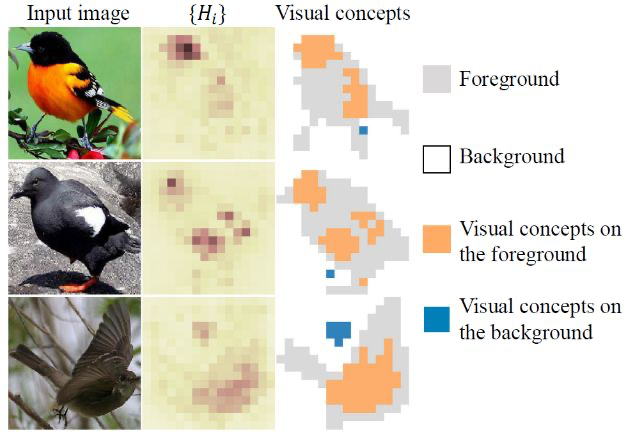
Fig.1. Explanation of knowledge distillation by quantifying visual concepts
那么如何定义并量化DNN所建模的“知识”?本研究中,知识指不依赖人为主观标注的,与任务相关的一块图像区域,如图1中的鸟头、鸟肚子等。依据information-bottleneck[1],DNN对输入信息是逐层遗忘的。因而我们利用输入信息的遗忘程度来衡量神经网络中层特征所建模的“知识量”,并借助条件熵来量化信息遗忘[2,3]。具体如下:
给定输入图片,以及DNN中层特征,则信息遗忘可转化为计算时,的信息损失的熵。我们假设神经网络往往用一个很小的特征范围去表示某一概念||f-f*|| < small constant。我们旨在量化“被神经网络视为表示同一概念的不同图片的概率分布的熵”。即,我们考虑对输入图片加入一个微小扰动,并计算满足||f-f*|| < small constant时,输入图片的熵。其中 控制第个像素的振幅。考虑到高斯分布的独立性,整个图片的熵可分解成像素级熵的加和,即。如图2所示,信息遗忘量越少,越小,则输入中蕴含的与任务相关的信息越多,“知识量”也越多。
Fig.2. Visualization of visual concepts.
考虑到不同像素上的熵是不一样的,一个图片上的“知识点”被定义为那些信息熵比较小的像素,即其信息损失比“平均背景信息熵”明显小很多的像素点。进一步,这些信息损失比较小的像素点的个数被认为是这个图片上的“知识量”。这里“平均背景信息熵”是一个参考值,用来大致衡量神经网络在与分类无关的图像区域的信息损失程度。
Hypothesis 1旨在证明相比仅从数据集训练而得的DNN(baseline network),知识蒸馏使得DNN学到更多的“知识点”,即更多的前景“知识量”和更少的背景“知识量”。分类任务中,相较于背景,前景信息与任务更为相关。从而,一个性能优越的教师网络会建模更多的前景“知识点”和更少的背景“知识点”,使得学生网络会学到更可靠的“知识点”,如图3所示,验证了Hypothesis 1的正确性。
Fig.3. Visualization of visual concepts.
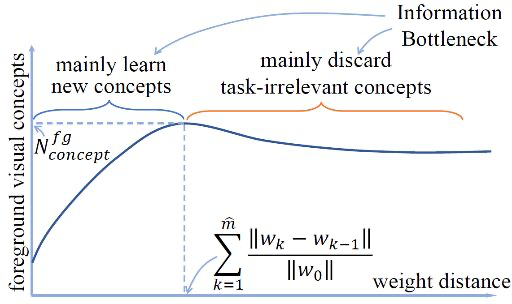
Hypothesis 2 意图证明蒸馏使得DNN能够同时学到不同的“知识点”,即较快的学习速率。考虑到DNN的优化过程并非“一马平川”,本研究选择计算网络优化的路径长度而非epoch数来刻画DNN的学习效果。如图4所示,在网络的优化过程中,DNN不断学习新“知识点”,同时遗忘旧“知识点”。因而,我们选择衡量在第 个epoch,即DNN获得最丰富前景知识量时,网络的学习效果(随输入图片的不同而变化)。
DNN的学习速率快体现在两个方面:1. 对于每个输入样本,DNN 能否快速学到不同“知识点”,即网络优化至epoch时,网络的优化路径长度是否短;2. 对于不同输入样本,DNN能否同时学到不同“知识点”。即,我们在考察对于不同的输入样本,DNN是否可以同时学习其前景知识点,并在同一训练阶段建模到各个图片的最丰富的前景知识量。所以,对于所有输入样本,当DNN的前景“知识量”最多时,网络优化的路径长度的均值 与方差 分别定量刻画了DNN是否快速、同时地学习“知识点”。均值和方差越小,代表DNN能够快速并同时学到不同知识。
Fig.4. Procedure of learning foreground visual concepts w.r.t. weight distances.
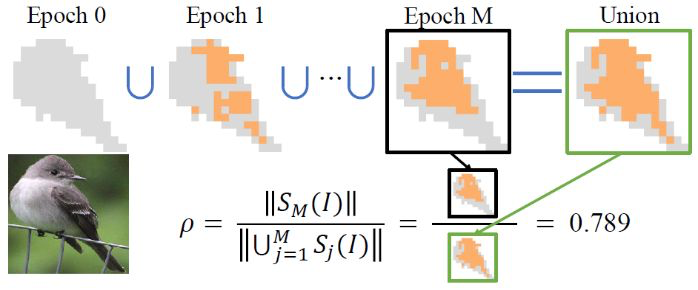
Hypothesis 3 意在证明由于教师网络的指导,知识蒸馏使得DNN的优化方向更为稳定,更少“绕弯路”。如图5所示,在优化前期,由于DNN的优化方向尚未确定,所建模的前景“知识点”不尽相同。就像狗熊掰棒子,神经网络早期学习的一些知识点是与任务无关的,并在优化过程后期被逐渐遗忘。因而DNN在优化过程中那些被遗忘的、错误建模的、与任务无关的“知识点”越少,优化方向也就越稳定。所以,我们利用DNN最终用于分类的“知识量”(黑框)与优化过程中学习到的所有“知识量” (绿框)的比值刻画网络优化方向的稳定性。比值越高,优化越稳定。
Fig.5. Detours of learning visual concepts.
实验结果
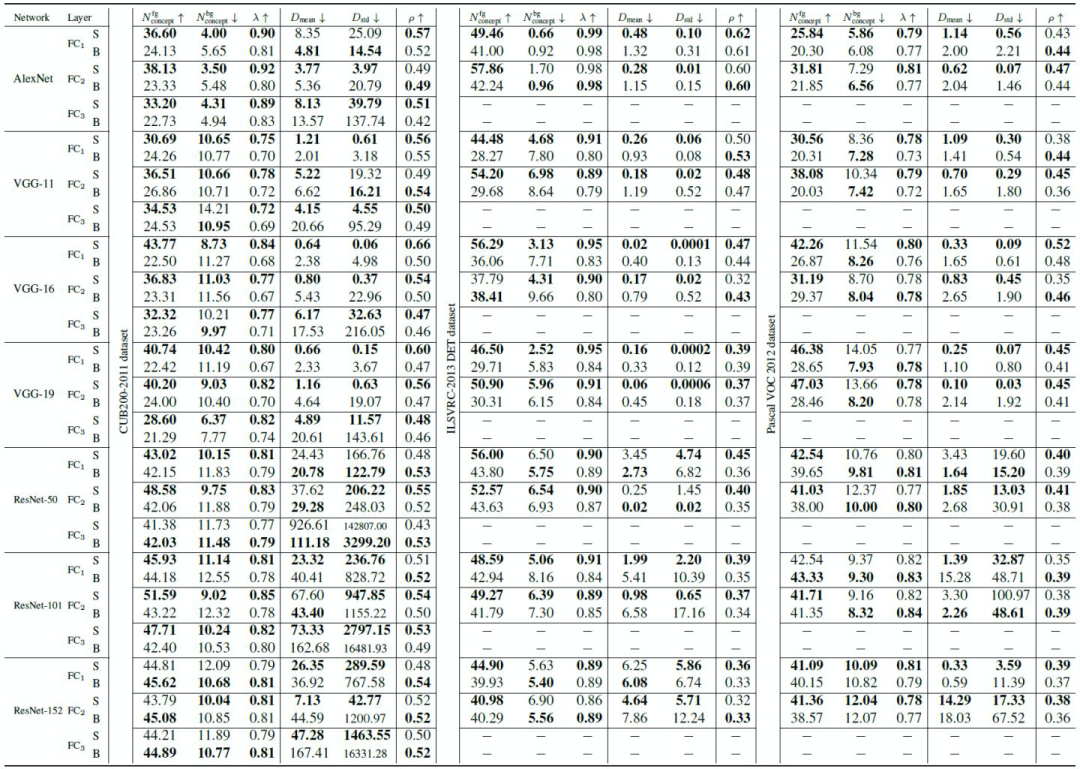
基于 ResNet-50/101/152、VGG-11/16/19和 AlexNet 等网络结构,在CUB200、VOC、ILSVRC-2013 DET等数据集上,评测不同全连接层上学生网络(S)与baseline网络的“知识量”。
如表1所示,实验结果验证了Hypotheses 1-3的正确性,即:相比于Baseline 网络,学生网络会建模更多的前景知识量,更少的背景知识量;优化路径长度的均值和方差更小;更高的稳定性比值,从而定量解释了知识蒸馏的成功性。
Table 1. Comparisons between the student network (S) and the baseline network (B).
作者:
程煦:上海交通大学直博生,师从张拳石副教授。研究领域:Explainable AI。
陈一览:毕业于西安交通大学,现在张拳石实验室进行实习研究。
饶哲凡:毕业于华中科技大学,现在张拳石实验室进行实习研究。
张拳石:上海交通大学副教授,博士生导师。http://qszhang.com
[1] Ravid Shwartz-Ziv and Naftali Tishby. Opening the black box of deep neural networks via information. arXiv preprint arXiv:1703.00810, 2017. 1, 2, 3, 5.
[2] Haotian Ma, Yinqing Zhang, Fan Zhou, and Quanshi Zhang. Quantifying layerwise information discarding of neural networks. In arXiv:1906.04109, 2019. 2, 3, 4.
[3] Chaoyu Guan, Xiting Wang, Quanshi Zhang, Runjin Chen, Di He, and Xing Xie. Towards a deep and unified understanding of deep neural models in nlp. In International Conference on Machine Learning, pages 2454–2463, 2019. 2, 3, 4.
为了方便大家阅读,小极已经将论文下载,极市平台公众号后台回复 知识蒸馏 即可获得论文下载链接。
推荐阅读:
极市平台视觉算法季度赛,提供真实应用场景数据和免费算力,特殊时期,一起在家打比赛吧!
![]()
添加极市小助手微信
(ID : cv-mart)
,备注:
研究方向-姓名-学校/公司-城市
(如:目标检测-小极-北大-深圳),即可申请加入
目标检测、目标跟踪、人脸、工业检测、医学影像、三维&SLAM、图像分割等极市技术交流群
,更有
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、
干货资讯汇总、行业技术交流
,
一起来让思想之光照的更远吧~
![]()
△长按添加极市小助手
![]()
△长按关注极市平台,获取最新CV干货
觉得有用麻烦给个在看啦~ ![]()