从莫扎特到披头士,Facebook 新 AI 轻松转换音乐风格

本文为 AI 研习社编译的技术博客,原标题 Understanding how Facebook’s new AI translates between music genres — in 7 minutes,作者为 Arya Vohra。
翻译 | 老赵 校对 | 酱番梨 审核 | 付腾

莫扎特 — 披头士
想象一下:你的朋友几周来一直在唠叨你听一首歌,尽管你已经告诉他你不喜欢 Ed Sheeran。 他们继续纠缠你,声称“旋律是伟大的”。 如果只有你能听到文明形式的那种旋律,就像巴赫管风琴协奏曲那样。
不要再等了。
Facebook的人工智能研究团队提出了一个音乐域名转移系统,声称能够翻译“乐器,流派和风格”。 您可以在下面看到结果。
让我们一探究竟吧!
我很震惊,这是非常令人印象深刻的东西。
本文的工作改进了两个空间的先前发展:域转移和音频合成。 域转移空间的最新进展在包含周期一致性(hehe)方面是一致的,如StarGAN(Choi等人,2017)(https://arxiv.org/abs/1711.09020),CycleGAN(Zhu等人,2017)(https://arxiv.org/abs/1703.10593),DiscoGAN(Kim等人,2017) (https://arxiv.org/abs/1703.05192),NounGAN。 使用周期一致性损失的关键目标是鼓励网络保留所有与内容相关的信息,并专注于更改与域相关的信息。
让我们先梳理一下 域名,内容,GAN,三轮车...所有的这些混乱的概念。 循环一致性概括了下面的陈述:F(G(X))≈X,函数G(X)应该具有大致返回输入X的相应的倒数F(X)。这可以通过引入a来促进循环一致性损失,如下所示:
这可以在下面看到:

基本上,在所有前向循环一致性 x→G(x)→F(G(x))≈ x 的误差和所有后向循环一致性y→F(y)→G(F(y))≈y 的误差。
现在,对于与域相关的信息与内容相关的信息...这个有点困难。 在GAN的上下文中,域信息是给定输入中确定其适合域的所有内容,而内容信息是关于图像的所有其他内容。 例如,如果我们有这样一辆汽车的图像:

我们有一组域,包括这样的汽车:{红色汽车,蓝色汽车,绿色汽车},我们得出结论,图像中所有与域相关的信息都是汽车的红色,而诸如汽车的形状之类的东西。 汽车,前照灯的数量,背景等都是与内容相关的信息。
看到FAIR团队的模型不是循环一致的,我们可能只是浪费了一些时间来研究这个问题,但是至少我们学到了什么。
由于使用了 Teacher forcing ,FAIR团队的模型不是循环一致的 — 让我们稍微绕道一下,看看这在实践中意味着什么。
Teacher forcing是强化学习的一种形式(ML技术源于心理学领域的研究。在这里了解更多:https://medium.freecodecamp.org/an-introduction-to-reinforcement-learning-4339519de419)。 在训练期间,模型输入包含先前时间步的地面实况输出。 在训练期间看到的序列是基本事实,因此是准确的,但对于生成的样本可能不是这种情况。 因此,生成的样本序列远离训练期间看到的序列。
虽然,如果他们真的想要,他们可能会实现循环一致性损失因子,如Kaneko等人。我没有使用自回归模型,这有一些非常有趣的含义,我将在稍后介绍。
该团队还为每个输出域使用了一个解码器,因为单个解码器显然无法令人信服地在输出域范围内执行。
来到这个更有趣的部分(论文中那些漂亮的扩张图已经很好了,我们就用它),FAIR团队使用了WaveNet。 具体来说,是对NSynth数据集的WaveNet变体背后的团队进行调整。 FAIR系统的不同之处在于:使用多个解码器,解析域混淆网络,以及使用音调增强来阻止网络懒惰地记忆数据。
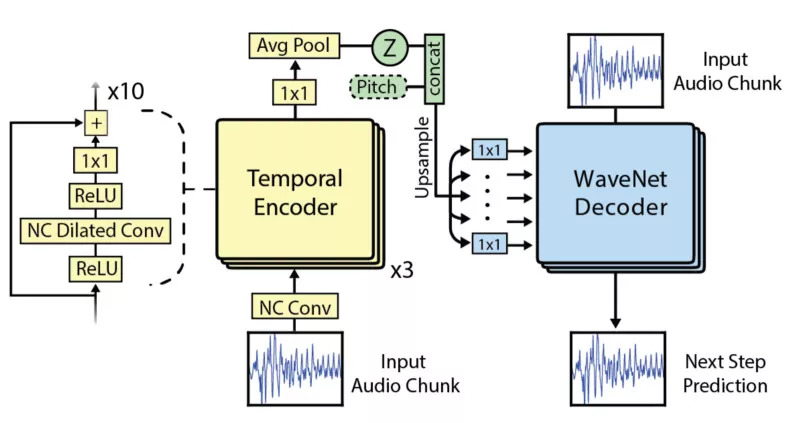
图1.Engel等人的“使用WaveNet自动编码器对音频音符进行神经音频合成”的WaveNet改编
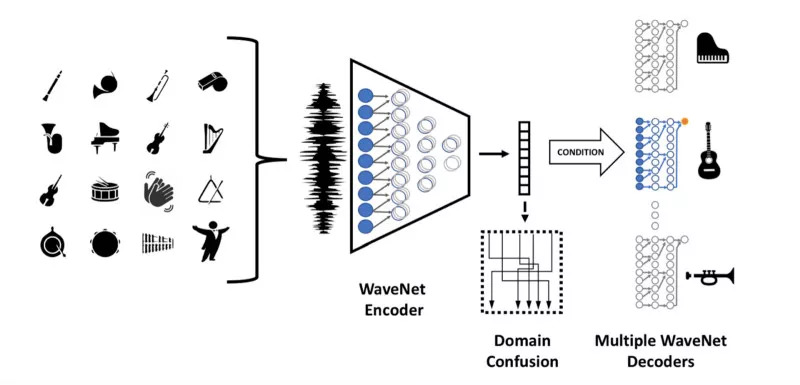
图2. FAIR团队使用的实际模型
让我们来看看 domain confusion 。
“ Domain-Adversarial Training of Neural Networks ”(Ganin et.al 2016)描述了高效的域转移 — 他们在当时达到了最先进的绩效 — 基于以下原则:“要实现有效的域转移,预测必须基于无法区分训练(来源)和测试(目标)领域的功能而制作。
该团队使用对抗训练来做到这一点。 WaveNet自动编码器是生成器,域分类网络是鉴别器。 将对抗性术语添加到自动编码器的损失中(查看下面的等式)可以鼓励自动编码器学习域不变的潜在表示。 这就是启用单个自动编码器的原因,这是使本文变得很酷的关键因素之一。
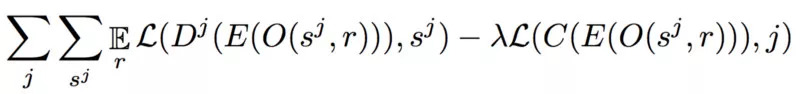
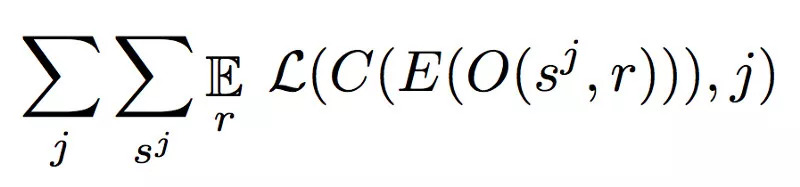
在上面的等式中可以看到很多东西 — 让我们快速分解它。
1. L(y,y)是分别对每个y ^和目标y元素对应的交叉熵损失。
2. 解码器Dj是一种自回归模型,它以共享编码器E的输出为条件。
3. O(s ^ j,r)是应用于具有随机种子r的样本的增强函数。
C是域混淆网络,其被训练以最小化分类丢失。
4. λ:lambda负责解开。 解缠结确保潜在表示中的所有神经元正在学习关于输入数据的不同事物。 这是解开变分自动编码器的一个关键特性,在本视频中对来自Arxiv洞察力的变分自动编码器进行了详细解释(跳到此时间戳以专门学习解缠结)
我认为现在开始走到一起了。要结束,让我们来看看他们是如何训练这件事的。
他们训练的领域代表了古典音乐中6种不同音色(音色:特定乐器的独特声音)和纹理(纹理:同时演奏的乐器和音符的数量)的传播。 其中一个特别突出的结果是自动编码器训练的嵌入和音高之间的相关性 - 相同音高的仪器对之间的余弦相似度在0.90-0.95范围内,这是非常了不起的。
它就是这样! 在音乐空间中进行深度学习是一个非常好的一步。 我真的很期待看到这会推动社区的发展。 我希望你喜欢这篇第一篇文章,在AI Journal上关注我们!
原文链接:https://medium.com/the-artificial-intelligence-journal/understanding-how-facebooks-new-ai-translates-between-music-genres-in-7-minutes-61d6cb1e5b4a
点击文末【阅读原文】即可观看更多精彩内容:
NLP 教程:词性标注、依存分析和命名实体识别解析与应用
想研究 NLP,不了解词嵌入与句嵌入怎么行?
手把手教你从零起步构建自己的快速语义搜索模型
文本分类又来了,用 Scikit-Learn 解决多类文本分类问题
CS224n斯坦福自然语言处理课程(中英双语字幕)
等你来译:
利用词向量和tsne算法来学习tensorflow
微软的TextWorld框架,NLP界的强化学习框架
深度学习的NLP工具






