你输文字,它生成视频:这款新模型让LeCun也开始转梗图了
机器之心报道
脸书的视频生成新模型实现了 SOTA,但不知道是不是人类给的提示太简单了,生成内容有点惊悚。
你输入文字,AI 就能生成视频,很长一段时间里只存在于人们想象中的事现在已经实现了。

昨天,Meta(脸书)研究人员发布了在 AI 艺术领域的新成果 Make-A-Video,这是一种创造性地新技术,结果令人印象深刻且多种多样。虽然画面目前看起来都有点惊悚,但在 AI 圈里人们已经开始尝试批量制造梗图了,图灵奖获得者 Yann LeCun 也在不停转推它制造的内容。
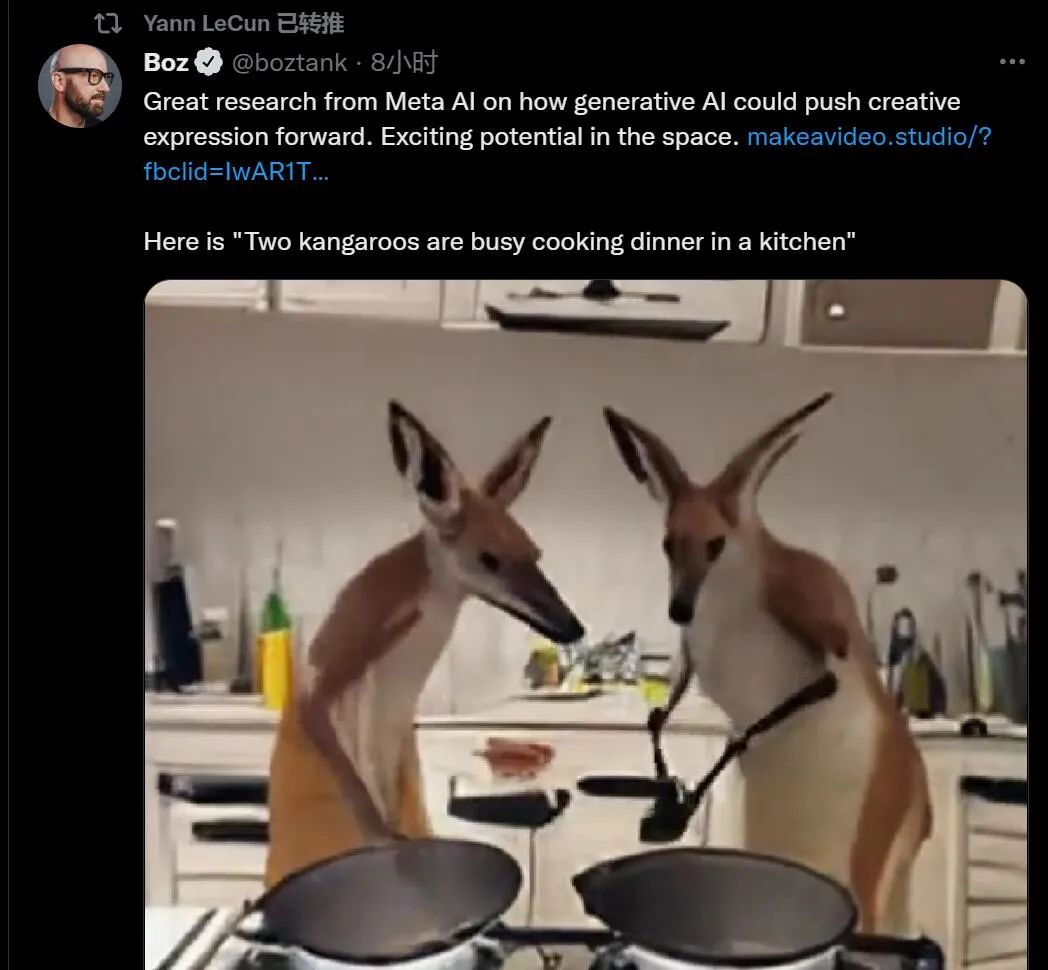
在此之前,我们以前见过文本到视频模型大多数利用文本生成图像(如 DALL-E),它们从人类的提示中输出静止图像。不过,虽然从静止图像到移动图像的概念跳跃对于人类大脑来说很小,但在机器学习模型中想要实现却绝非易事。
Make-A-Video 实际上并没有在后端对这套过程进行太大的改变——正如研究人员在论文中指出的那样,「一个只看到描述图像的文本的模型在生成短视频方面出奇地有效。」
例如输入「A teddy bear painting a portrait」,即「一只画自画像的泰迪熊」,Make-A-Video 生成的视频如下动图所示:

论文《Make-A-Video: Text-to-video Generation without text-video data》:

从格式看是 ICLR 大会的投稿。
论文链接:
https://makeavideo.studio/Make-A-Video.pdf
该 AI 模型使用现有且有效的扩散技术来创建图像,其本质上是从纯视觉静态「去噪」向目标提示的逆向工作。这里要注意的是,该模型还对一堆未标记的视频内容进行了无监督训练(即在没有人类仔细指导的情况下用数据进行训练)。
Make-A-Video 不需要从头开始学习视觉和多模态表示,从一开始就知道如何制作逼真的图像,也不需要成对的文本视频数据,同时生成的视频风格多样,继承了当今图像生成模型的可扩展性。Meta 研究人员表示,在空间和时间分辨率、对文本的还原忠实度和质量的所有方面,Make-A-Video 实现了文本到视频生成的最高水平。
无论是空间和时间分辨率、还是与文本描述的符合程度,Make-A-Video 都在文本到视频的生成中达到了 SOTA 水平。
相比于之前从文本生成视频的系统,Make-A-Video 使用了不同的方法,实现了与 18 个月前在原始 DALL-E 或其他上一代系统中一致的图像保真度。

T2V 生成的图像示例。Meta 提出的模型可以为各种视觉概念生成具有连贯运动的高质量视频。
值得注意的是,AI 模型生成的图像往往因为太高清而失去真实感,保留一点瑕疵的图像和视频才更贴合实际。
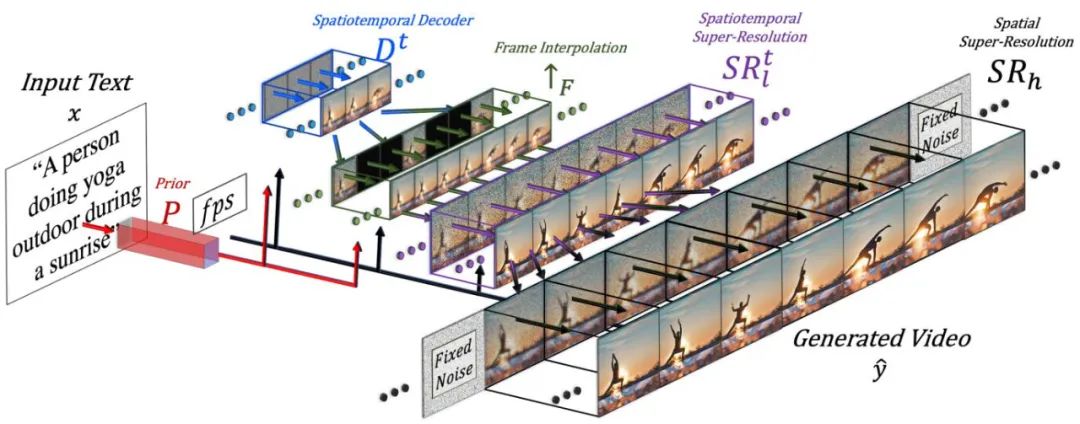
Make-A-Video 的高级架构。给定由先验 P 翻译成图像嵌入的输入文本 x 和所需的帧速率 f ps ,解码器 Dt 生成 16 个 64 × 64 分辨率的帧,然后通过 ↑F 将其插值到更高的帧速率,并提高分辨率到 SRt l 为 256 × 256,SRh 为 768 × 768,最后生成高时空分辨率的视频 y^。
作为一个脑补工具,Make-A-Video 也可以利用静止图像和其他视频转换为其变体或进行扩展,就像图像生成器也可以用图像本身作为提示一样。这样生成的结果就稍微没那么魔性了。
从文本、图像到视频,AI 工具的发展速度再次跨越了一个界限,不知在这项技术公开之后,人们会用它创造出哪些「艺术品」。Meta 表示,人们已经可以开始注册,并在近期获取开放的模型。
参考内容:
https://ai.facebook.com/blog/generative-ai-text-to-video/
https://techcrunch.com/2022/09/29/meta-make-a-video-ai-achieves-a-new-creepy-state-of-the-art/?guccounter=1&guce_referrer=aHR0cHM6Ly93d3cuZ29vZ2xlLmNvbS8&guce_referrer_sig=AQAAAB4gIQW9QJu8rwFfhRQVhojQ_bWREEj0nfCLOx79TjN1_V1X4KbLbrSuaQO09UOpAtXwxBAO99E6tFvVt8ohgLG_aujWfDmqmncpuKISvA6huYm_gAwVztePlcabeVjmeCqD3H8gXh9mVYeqg0CTP4TJn_TlJgmAKa5gMNtxIz9_
声纹识别:从理论到编程实战

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com


