一文帮你理解什么是深层置信网络(DBN)

翻译 | 林椿眄
编辑 | SuiSui
前言
随着机器学习的进步和深度学习的出现,一些工具和图形表示被逐渐用来关联大量的数据。深度置信网络(Deep Belief Networks)本质上是一种具有生成能力的图形表示网络,即它生成当前示例的所有可能值。
深度置信网络是概率统计学与机器学习和神经网络的融合,由多个带有数值的层组成,其中层之间存在关系,而数值之间没有。深层置信网络主要目标是帮助系统将数据分类到不同的类别。
深度信念网络如何演进?
第一代神经网络使用感知器,通过考虑“权重”或预先馈送的目标属性来识别特定的物体或其他物体。然而,感知器只能在更基本的层面上有效,并不能提高识别的技术。
为了解决这些问题,第二代神经网络引入了反向传播的概念,将得到的输出与期望的输出进行比较,最终目标是使误差值减小到零。支持向量机通过引用先前测试用例的输入来创建和理解更多的测试用例。
接下来是针对信念网络的非循环图。这种图能够帮助解决与推理那些和学习问题有关的问题。随后是深度置信网络,它帮助创建存储在叶节点中的无偏值。
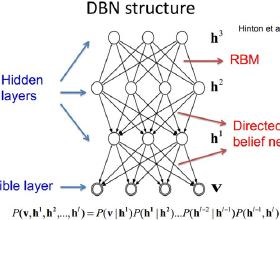
受限玻尔兹曼机
深度置信网络由诸如波尔兹曼机无监督网络组成。在这里,每个子网络的不可见层是下一层的可见层。隐藏层或不可见的层并不是相互连接,而是有条件互相独立的。
联合配置网络的可见层和隐藏层上的概率,取决于联合配置网络的能量与其他所有联合配置网络的能量。
训练深度置信网络
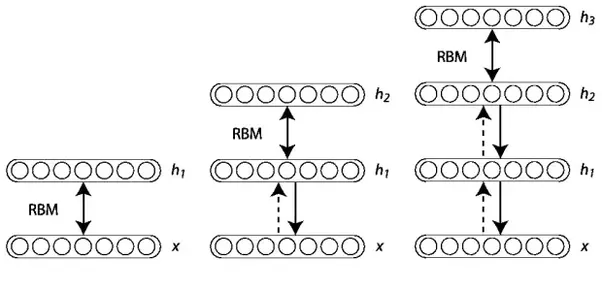
训练网络层属性的第一步是直接从像素获取输入信号。下一步是将此图层的值作为像素,并在第二个隐藏层从先前获取的特征中学习特征。每当另一层的属性或特征被添加到深度置信网络时,训练数据集的对数概率的下限就会有所改善。
例如:
实施
MATLAB可以很容易地将可见层,隐藏层和权重表示为矩阵形式并高效地执行矩阵算法。因此,我们选择MATLAB来实现深度置信网络。
选用这些MNIST9的手写数字,然后用作深度置信网络的计算,以便与其他分类器的性能进行比较。
MNIST9可以被描述为是一个手写数字的数据库,有6万个训练样本和1万个数字测试样本。手写数字是从0到9,并且在每个图像表现出各种的形状和位置特征。每一张图像都被标准化,并以28x28像素为中心被标记。
决定这些权重更新频率的方法是-在线学习,或采用小批量和全批量数据大小。
在线学习需要最长的计算时间,因为在每个训练数据实例之后,它才完成权重的更新。全批量处理通过训练数据并更新权重,但是,建议不要将其用于大数据集。
小批量处理是把数据集分成较小的数据块,并对每个数据块进行学习操作,这种方法需要更少的计算时间。因此,我们使用小批量学习来实现。
需要记住的一个重要的问题是,实现一个深层置信网络需要对每层波尔兹曼机进行训练。
为此,首先需要初始化网络单位和参数。其次是对比散度算法的两个阶段--正相和负相阶段。在正相阶段,隐藏层的二进制状态可以通过权重的计算和可见单位的概率来获得。由于增加了训练数据集的概率,因此称为正相。负相阶段会降低模型生成样本的概率。
贪婪学习算法被用来训练整个深度置信网络。它一次训练一个波尔兹曼机,直到所有的波尔兹曼机都被训练为止。
作者 | Icecream Labs
原文链接:
https://medium.com/@kaveri_53280/deep-belief-networks-all-you-need-to-know-cb708774ee3a
热文精选
亏本也要抢市场!谷歌亚马逊一路死磕到CES,争夺语音入口之路
2018年了,但愿你还有被剥削的价值!因为AI失业潮真的开始了...
不用数学也能讲清贝叶斯理论的马尔可夫链蒙特卡洛方法?这篇文章做到了
干货 | AI 工程师必读,从实践的角度解析一名合格的AI工程师是怎样炼成的
AI校招程序员最高薪酬曝光!腾讯80万年薪领跑,还送北京户口