社区分享|TensorFlow 在推荐场景中的推理性能优化


发布人:袁绍臣,AI Infrastructures 团队,来自 SmartNews


推荐系统是 SmartNews 在 Machine Learning 领域里最核心的应用场景,我们在新闻和广告推荐中运用了很多复杂的模型来通过用户的行为和标签找到更适合的新闻和广告。然而为了能够更精准的找到推荐内容,推荐模型所需要的用户特征也随之变得越来越多。在这样的情况下,对模型预测的性能的要求就显得愈加重要。
这篇文章会讨论我们是如何在不改变预测模型效果的前提下,通过模型本身和 TFServing 层面的优化从而尽可能的降低模型预测的时间开销。
由 Tensorflow 2.x 提供的 High-Level API Estimator API 导出的模型默认是用 tf.example 消息作为模型输入格式的。tf.example 消息的本质就是 key-value pairs,用于记录模型预测所需要的特征 (Feature) 名称和其内容。每一条 tf.example 消息里面就包含了用于模型预测一条输入的所有特征。
这样看似非常方便,在输入的 feature 非常多的时候可以将所有的 feature 放进一个消息里面用于预测。但有些细心的朋友可能已经发现了其中隐藏的问题,那就是在实际应用中,一次推荐模型预测的输入并不只有一条消息。为了提高模型预测的性能,我们往往会在一个请求里面放入批量的消息。这样一来,由于每条消息都是相对独立的存在 tf.example 格式中,模型在一个请求里接到多个消息的时候,就需要花更多的时间来把所有消息中的同样feature的内容聚合到一起,用于模型的一次预测。这一步在模型内部其实是由 ParseExampleV2 这个 operation 来完成的。随着推荐模型的请求内容的增加,ParseExampleV2 所花费的计算量与时间也随之水涨船高。从 Tensorboard Profiler [1] 里分析得出的下图就是一个很好的例子。
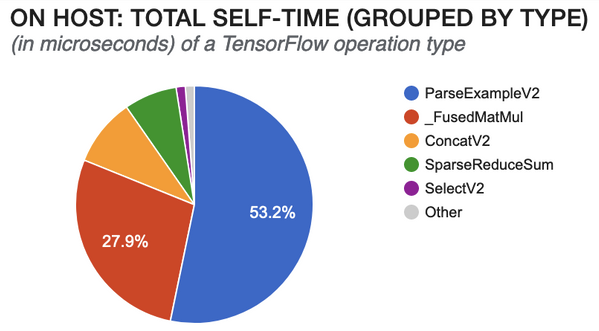
为了减少 Parse tf.example 消息所花的时间,我们就需要对模型预测输入格式进行一下调整。进一步分析 TFServing 预测输入的 protobuf 可以得知,预测请求是可以接受 key为feature 名称,value 为 tensor proto 的 map 的。所以我们就可以在发送预测请求时就将一个请求中所有消息里相同 feature 的内容聚合在一起,作为输入的其中一个 key value pair 发送给 TFServing。这样模型在接到消息之后就可以完全跳过 ParseExampleV2 这个 Operation,直接将传输过来的 feature 转换成相应的 tensor,用于模型预测。同样的,在模型导出时,我们也需要重新定义它的输入转换函数,对预测的输入不进行额外的处理,直接将输入放入相应的模型所需要 feature 里即可。
在经过这样的处理后,对相同的模型再进行一次 profiling 的结果如下所示。我们可以看到占用 CPU 时间最多的 ParseExampleV2 完全消失了,模型预测的时间也同时减少了。
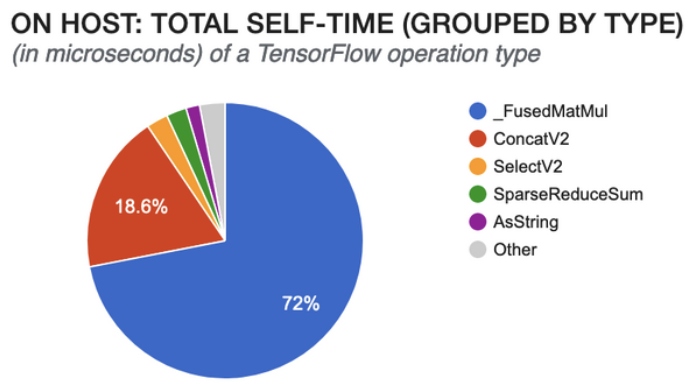
在解决模型输入的问题过程中,我们了解到一个请求里面包含了几十甚至上百条消息,再加上预测输入 feature 的繁多种类和内容,每条请求的大小其实已经达到了 MB 级别。所以传输如此大小数据的延迟就不容忽视了。
对于推荐模型来说,由于我们需要预测同一个用户于多个推荐内容之间的分数,而每一条消息又包含了用户和推荐内容的 feature,这样多条消息里面的用户 feature 其实是完全重复的。所以在减小请求大小的方案上,其实方向已经非常明确了,就是对于一个预测请求,重复的用户 feature 只传输一遍。在 TFServing 接收到请求之后,再将用户 feature 的部分复制与推荐内容 feature 对齐,这样就避免了大量的重复数据传输,减少了预测请求的大小。
TFServing 提供了一个 High Level API 来应对预测输入内容重复的问题。它允许客户端发送一个叫做 ExampleListWithContext (ELWC) 的结构 [2] 作为预测请求,其中包含了两个部分:每条消息独特的 tf.example list 和整个请求公共部分的 tf.example。在阅读 TFServing 的代码后得知,这两部分 tf.example 的拼接工作是在 ParseExampleV2 这个 operation 之前完成的。也就意味着即使减少了传输的内容,ParseExampleV2 还是要在拼接完成的全量消息基础上进行转换。所以如果我们使用了 ELWC 来传输模型的输入,在网络传输上也许可以节约一部分时间,但是在 TFServing 接收到请求后,反而要花更多的时间来处理。(因为多了拼接输入的步骤)
那么基于我们第一部分的优化,对于更新后的模型输入格式,怎样才能做到减少预测输入的大小呢?
由于新模型的输入不再是以每条消息为一个基本单位,而是以每个输入的 feature 作为基本单位的。所以拿出单独的一个feature 来看,如果它是用户的 feature,必然其内容一定是不停重复的,重复的次数就等于整个请求里面消息的数量。客户端这时候就只需要辨别哪些 feature 是用户 feature,然后对于这些用户 feature 只发送一次,把复制的工作交给 TFServing 来做就可以了。为了避免上面提到的 ELWC 的问题,复制的工作由底层 Tensorflow 在将输入转为 tensor 的时候进行,这样就可以最大化的减少处理输入的花销。
首先我们要在 Tensorflow 里面加入一个新的创建 tensor 的方法,这个方法传入的是 tensor 的 value 和 shape,而在 value 的内容不满足 shape 的情况下,自动复制 value 的内容进行填充。(value 可以是 tensor 支持的各种类型。)其次需要修改 TFServing,在接收到所有输入的 feature 之后判断是否有 feature 只接受到了一条,和其他输入 feature 的条数不符。如果发现这样的 feature,就调用刚创建的新 tensor 初始化方法,并将传入的 shape 设置为与其他输入 feature 相对应的条数。(目前自动复制只会在输入为一条的情况时发生,例如 feature_1 有两条,feature_2 有三条,则会返回输入错误,不会自动复制。)例如输入 feature_1 的内容为 [1], feature_2 的内容为 [1, 0, 2],则会自动补齐 feature_1 为 [1, 1, 1]。按照消息的角度来看三条输入分别是 [1,1],[1, 0],[1, 2]。
如果我们用一幅图来说明同一个预测请求的格式的变化就是这样。
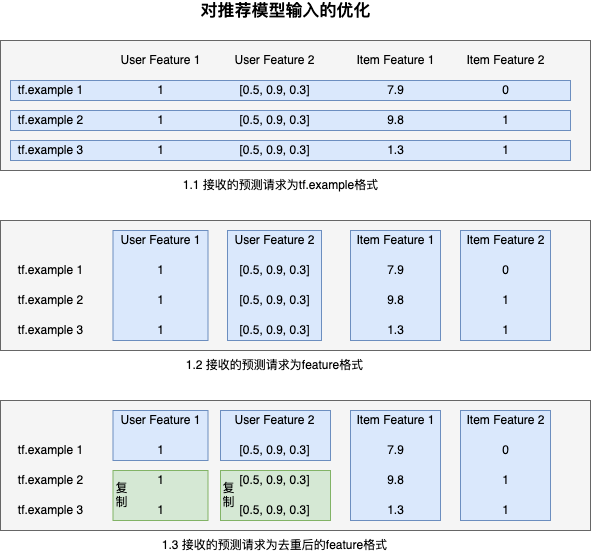
这里面需要特别注意的一点是,TFServing 本身可以设置 batch setting,如果将其开启,则 TFServing 在同时接到多个请求时会将他们自动合并为一个请求。在此改动后,须禁用 batch 的功能,否则将两个请求合并到一起时会出现某些输入 feature 条数不为一也不同于其他 feature 的条数,导致返回输入错误的情况。
本文介绍了 SmartNews 在遇到推荐模型预测性能问题时所尝试的解决方案。在经过以上的性能优化之后,推荐模型客户端的平均预测时间和 P90 都有 50% 以上的减少。除了以上提到的之外,我们也还在继续分析模型并寻找新的优化方向。如果读者对以上方案有任何疑问或者对模型预测性能优化有独到的见解,欢迎留言讨论。
— 参考文献 —
[1] Profile Inference Requests with TensorBoard:
https://www.tensorflow.google.cn/tfx/serving/tensorboard
[2] Example List With Context Protobuf:
https://github.com/tensorflow/serving/blob/master/tensorflow_serving/apis/input.proto

点击“阅读原文”填写相关信息,
分享自己的经验与案例

不要忘记“一键三连”哦~

分享

点赞

在看




