社区分享 | TensorFlow 在美团外卖推荐场景的 GPU 训练优化实践


转载自:美团技术团队
美团机器学习平台基于内部深度定制的 TensorFlow 研发了 Booster GPU 训练架构。该架构在整体设计上充分考虑了算法、架构、新硬件的特性,从数据、计算、通信等多个角度进行了深度的优化,最终其性价比达到 CPU 任务的 2~4 倍。本文主要讲述 Booster 架构的设计实现、性能优化及业务落地工作,希望能对从事相关开发的同学有所帮助或者启发。
1 背景
2 GPU 训练优化挑战
3 系统设计与实现
3.1 参数规模的合理化
3.2 系统架构
3.3 关键实现
4 系统性能优化
4.1 数据层
4.2 计算层
4.3 通信层
4.4 性能指标
5 业务落地
5.1 完备性
5.2 训练效果
6 总结与展望

在推荐系统训练场景中,美团内部深度定制的 TenorFlow(简称 TF)版本[1],通过 CPU 算力支撑了美团内部大量的业务。但随着业务的发展,模型单次训练的样本量越来越多,结构也变得越来越复杂。以美团外卖推荐的精排模型为例,单次训练的样本量已达百亿甚至千亿,一次实验要耗费上千核,且优化后的训练任务 CPU 使用率已达 90% 以上。为了支持业务的高速发展,模型迭代实验的频次和并发度都在不断增加,进一步增加了算力使用需求。在预算有限的前提下,如何以较高的性价比来实现高速的模型训练,从而保障高效率的模型研发迭代,是我们迫切需要解决的问题。
近几年,GPU 服务器的硬件能力突飞猛进,新一代的 NVIDIA A100 80GB SXM GPU 服务器(8 卡)[2],在存储方面可以做到:显存 640GB、内存 1~2TB、SSD10+TB,在通信方面可以做到:卡间双向通信 600GB/s、多机通信 800~1000Gbps/s,在算力方面可以做到:GPU 1248TFLOPS (TF32 Tensor Cores),CPU 96~128 物理核。如果训练架构能充分发挥新硬件的优势,模型训练的成本将会大大降低。但 TensorFlow 社区在推荐系统训练场景中,并没有高效和成熟的解决方案。我们也尝试使用优化后的 TensorFlow CPU Parameter Server[3](简称 PS)+GPU Worker 的模式进行训练,但只对复杂模型有一定的收益。NVIDIA 开源的 HugeCTR[4] 虽然在经典的深度学习模型上性能表现优异,但要在美团的生产环境直接使用起来,还需要做较多的工作。
美团基础研发机器学习平台训练引擎团队,联合到家搜推技术部算法效能团队、NVIDIA DevTech 团队,成立了联合项目组。在美团内部深度定制的 TenorFlow 以及 NVIDIA HugeCTR 的基础上,研发了推荐系统场景的高性能 GPU 训练架构 Booster。目前在美团外卖推荐场景中进行了部署,多代模型全面对齐算法的离线效果,对比之前,优化后的 CPU 任务,性价比提升了 2~4 倍。由于 Booster 对原生 TensorFlow 接口有较好的兼容性,原 TensorFlow CPU 任务只需要一行代码就可完成迁移。这样让 Booster 可以快速在美团多条业务线上进行初步验证,相比之前的 CPU 任务,平均性价比都提升到 2 倍以上。本文将重点介绍 Booster 架构的设计与优化,以及在美团外卖推荐场景落地的全过程,希望能对大家有所帮助或启发。
GPU 训练在美团内已经广泛应用到 CV、NLP、ASR 等场景的深度学习模型,但在推荐系统场景中,却迟迟没有得到大规模的应用,这跟场景的模型特点、GPU 服务器的硬件特点都有较强的关系。
推荐系统深度学习模型特点
读取样本量大:训练样本在几十 TB~几百 TB,而 CV 等场景通常在几百 GB 以内。
模型参数量大:同时有大规模稀疏参数和稠密参数,需要几百 GB 甚至上 TB 存储,而 CV 等场景模型主要是稠密参数,通常在几十 GB 以内。
模型计算复杂度相对低一些:推荐系统模型在 GPU 上单步执行只需要 10~100ms,而 CV 模型在 GPU 上单步执行是 100~500ms,NLP 模型在 GPU 上单步执行是 500ms~1s。
GPU 服务器特点
GPU 卡算力很强,但显存仍有限:如果要充分发挥 GPU 算力,需要把 GPU 计算用到的各种数据提前放置到显存中。而从 2016 年~2020 年,NVIDIA Tesla GPU 卡[5] 计算能力提升了 10 倍以上,但显存大小只提升了 3 倍左右。
其它维度资源并不是很充足:相比 GPU 算力的提升速度,单机的 CPU、网络带宽的增长速度较慢,如果遇到这两类资源负载较重的模型,将无法充分发挥 GPU 的能力,GPU 服务器相比 CPU 服务器的性价比不会太高。
总结来说,CV、NLP 等场景的模型训练属于计算密集型任务,而且大多模型单张卡的显存都可以装下,这和 GPU 服务器的优势非常好地进行了匹配。但在推荐系统场景中,由于模型相对没有那么复杂,远端读取的样本量大,特征处理耗费 CPU 多,给单机 CPU 和网络带来较大的压力。同时面对模型参数量大的情况,单机的 GPU 显存是无法放下的。这些 GPU 服务器的劣势,恰恰都被推荐系统场景命中。
好在 NVIDIA A100 GPU 服务器,在硬件上的升级弥补了显存、CPU、带宽这些短板,但如果系统实现和优化不当,依然不会有太高的性价比收益。在落地 Booster 架构的过程中,我们主要面临如下挑战:
数据流系统:如何利用好多网卡、多路 CPU,实现高性能的数据流水线,让数据的供给可以跟上 GPU 的消费速度。
混合参数计算:对于大规模稀疏参数,GPU 显存直接装不下的情况,如何充分利用 GPU 高算力、GPU 卡间的高带宽,实现一套大规模稀疏参数的计算,同时还需要兼顾稠密参数的计算。
面对上面的挑战,如果纯从系统的的角度去设计,难度较大。Booster 采用了“算法+系统”Co-design 的设计思路,让这代系统的设计大大得到简化。在系统实施路径上,考虑到业务预期交付时间、实施风险,我们并没有一步到位落地 Booster 的多机多卡版本,而是第一版先落地了 GPU 单机多卡版本,本文重点介绍的也是单机多卡的工作。另外,依托于 NVIDIA A100 GPU 服务器强大的计算能力,单机的算力可以满足美团绝大多数业务的单次实验需求。
3.1 参数规模的合理化
大规模稀疏离散特征的使用,导致深度预估模型的 Embedding 参数量急剧膨胀,数 TB 大小的模型一度流行于业界推搜的各大头部业务场景。但是业界很快意识到,在硬件成本有限的情况下,过于庞大的模型给生产部署运维和实验迭代创新增添了沉重的负担。学术研究表明[10-13],模型效果强依赖于模型的信息容量,并非参数量。实践证明,前者可以通过模型结构的优化来进行提升,而后者在保证效果的前提下,尚存有很大的优化空间。Facebook 在 2020 年提出了 Compositional Embedding[14],实现推荐模型参数规模数个量级的压缩。阿里巴巴也发表了相关工作[15],将核心业务场景的预估模型由数 TB 压缩至几十 GB 甚至更小。总的来看,业界的做法主要有以下几种思路:
去交叉特征:交叉特征由单特征间做笛卡尔积产生,这会生成巨大的特征 ID 取值空间和对应 Embedding 参数表。深度预估模型发展至今,已经有大量的方法通过模型结构来建模单特征间的交互,避免了交叉特征造成的 Embedding 规模膨胀,如 FM 系列[16]、AutoInt[17]、CAN[18] 等。
精简特征:特别是基于 NAS 的思路,以较低的训练成本实现深度神经网络自适应特征选择,如 Dropout Rank[19] 和 FSCD[20] 等工作。
压缩 Embedding 向量数:对特征取值进行复合 ID 编码和 Embedding 映射,以远小于特征取值空间的 Embedding 向量数,来实现丰富的特征 Embedding 表达,如 Compositional Embedding[14]、Binary Code Hash Embedding[21] 等工作。
压缩 Embedding 向量维度:一个特征 Embedding 向量的维度决定了其表征信息的上限,但是并非所有的特征取值都有那么大的信息量,需要 Embedding 表达。因此,可以每一个特征值自适应的学习精简 Embedding 维度,从而压缩参数总量,如 AutoDim[22] 和 AMTL[23] 等工作。
量化压缩:使用半精度甚至 int8 等更激进的方式,对模型参数做量化压缩,如 DPQ[24] 和 MGQE[25]。
美团外卖推荐的模型一度达到 100G 以上,通过应用以上方案,我们在模型预估精度损失可控的前提下,将模型控制在 10GB 以下。
基于这个算法基础假设,我们将第一阶段的设计目标定义到支持 100G 以下的参数规模。这可以比较好的适配 A100 的显存,存放在单机多卡上,GPU 卡间双向带宽 600GB/s,可以充分发挥 GPU 的处理能力,同时也可以满足美团大多数模型的需求。
3.2 系统架构
基于 GPU 系统的架构设计,要充分考虑硬件的特性才能充分发挥性能的优势。我们 NVIDIA A100 服务器的硬件拓扑和 NVIDIA DGX A100[6] 比较类似,每台服务器包含:2 颗 CPU,8 张 GPU,8 张网卡。Booster 架构的架构图如下所示:

图 1 系统架构
整个系统主要包括三个核心模块:数据模块,计算模块,通信模块:
数据模块:美团自研了一套支持多数据源、多框架的数据分发系统,在 GPU 系统上,我们改造数据模块支持了多网卡数据下载,以及考虑到 NUMA Awareness 的特性,在每颗 CPU 上都部署了一个数据分发服务。
计算模块:每张 GPU 卡启动一个 TensorFlow 训练进程执行训练。
通信模块:我们使用了 Horovod[7] 来做分布式训练的卡间通信,我们在每个节点上启动一个 Horovod 进程来执行对应的通信任务。
上述的设计,符合 TensorFlow 和 Horovod 原生的设计范式。几个核心模块可以相互解耦,独立迭代,而且如果合并开源社区的最新特性,也不会对系统造成架构性的冲击。
我们再来看一下整个系统的简要执行流程,每张 GPU 卡上启动的 TensorFlow 进程内部的执行逻辑如下图:
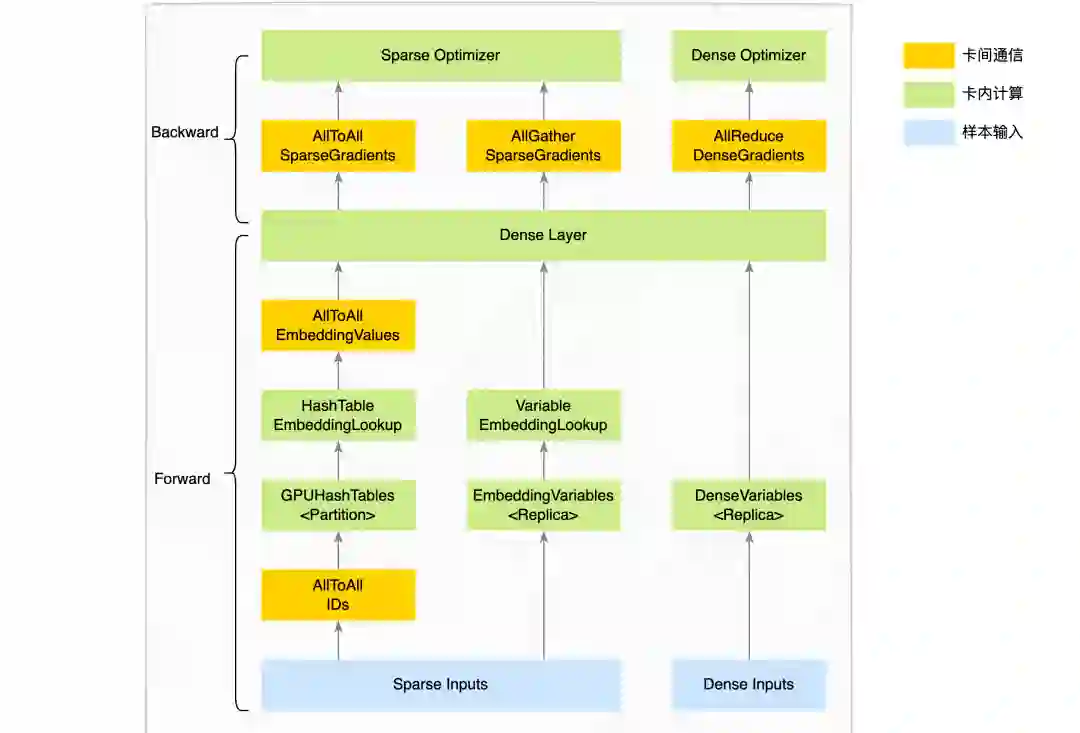
图 2 进程内部执行逻辑
整个训练流程涉及参数存储、优化器、卡间通信等几个关键模块。对于样本的输入特征,我们分为稀疏特征(ID 类特征)和稠密特征。在实际业务场景中,稀疏特征通常 IDs 总量较多,对应的稀疏参数使用 HashTable 数据结构存储更合适,而且由于参数量较大,GPU 单卡显存放不下,我们会通过 ID Modulo 的方式 Partition 到多张 GPU 卡的显存中存放。对于IDs总量较少的稀疏特征,业务通常使用多维矩阵数据结构表达(在 TensorFlow 里面的数据结构是 Variable),由于参数量不大,GPU 单卡显存可以放下,我们使用 Replica 的方式,每张 GPU 卡的显存都放置一份参数。对于稠密参数,通常使用 Variable 数据结构,以 Replica 的方式放置到 GPU 显存中。下边将详细介绍 Booster 架构的内部实现。
3.3 关键实现
3.3.1 参数存储
早在 CPU 场景的 PS 架构下,我们就实现了大规模稀疏参数的整套逻辑,现在要把这套逻辑搬到 GPU 上,首先要实现的就是 GPU 版本的 HashTable。我们调研了业界多种 GPU HashTable 的实现,如 cuDF、cuDPP、cuCollections、WarpCore 等,最终选择了基于 cuCollections 实现 TensorFlow 版本的 GPUHashTable。究其原因,主要是因为实际业务场景中,大规模稀疏特征的总量通常是未知的,并且随时可能出现特征交叉,从而致使稀疏特征的总量变化很大,这就导致“动态扩容”能力将成为我们 GPU HashTable 的必备功能,能够做到动态扩容的只有 cuCollections 的实现。我们在 cuCollections 的 GPU HashTable 基础上实现了特殊接口 (find_or_insert),对大规模读写性能进行了优化,然后封装到了 TensorFlow 中,并在其上实现了低频过滤的功能,能力上对齐 CPU 版本的稀疏参数存储模块。
3.3.2 优化器
目前,稀疏参数的优化器与稠密参数的优化器并不兼容,我们在 GPU HashTable 的基础上,实现了多种稀疏优化器,并且都做了优化器动量 Fusion 等功能,主要实现了 Adam、Adagrad、FTRL、Momentum 等优化器。对实际业务场景来说,这些优化器已经能够覆盖到绝大多数业务的使用。稠密部分参数可以直接使用 TensorFlow 原生支持的稀疏/稠密优化器。
3.3.3 卡间通信
实际训练期间,对于不同类型的特征,我们的处理流程也有所不同:
稀疏特征(ID 类特征,规模较大,使用 HashTable 存储):由于每张卡的输入样本数据不同,因此输入的稀疏特征对应的特征向量,可能存放在其他 GPU 卡上。具体流程上,训练的前向我们通过卡间 AllToAll 通信,将每张卡的 ID 特征以 Modulo 的方式 Partition 到其他卡中,每张卡再去卡内的 GPUHashTable 查询稀疏特征向量,然后再通过卡间 AllToAll 通信,将第一次 AllToAll 从其他卡上拿到的 ID 特征以及对应的特征向量原路返回,通过两次卡间 AllToAll 通信,每张卡样本输入的 ID 特征都拿到对应的特征向量。训练的反向则会再次通过卡间 AllToAll 通信,将稀疏参数的梯度以 Modulo 的方式 Partition 到其他卡中,每张卡拿到自己的稀疏梯度后再执行稀疏优化器,完成大规模稀疏特征的优化。详细流程如下图所示:
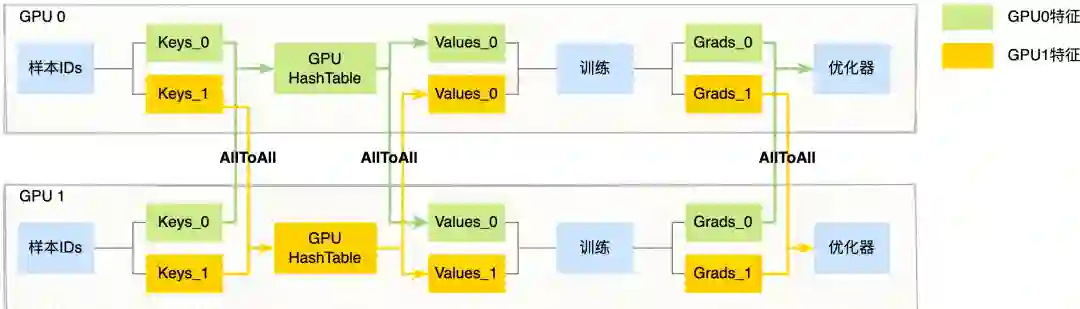
图 3 稀疏特征处理流程
稀疏特征(规模较小,使用 Variable 存储):相比使用 HashTable 的区别,由于每张 GPU 卡都有全量的参数,直接在卡内查找模型参数即可。在反向聚合梯度的时候,会通过卡间 AllGather 获取所有卡上的梯度求平均,然后交给优化器执行参数优化。
稠密特征:稠密参数也是每张卡都有全量的参数,卡内可以直接获取参数执行训练,最后通过卡间 AllReduce 聚合多卡的稠密梯度,执行稠密优化器。
在整个的执行过程中,稀疏参数和稠密参数全部放置在 GPU 显存中,模型计算也全部在 GPU 上处理,GPU 卡间通信带宽也足够快,能够充分发挥了 GPU 的强大算力。
这里小结一下,Booster 训练架构,与 CPU 场景 PS 架构的核心区别在于:
训练模式:PS 架构是异步训练模式,Booster 架构是同步训练模式。
参数分布:PS 架构下模型参数都存放在 PS 内存中,Booster 架构下稀疏参数 (HashTable) 是 Partition 方式分布在单机八卡中,稠密参数 (Variable) 是 Replica 方式存放在每张卡中,因此 Booster 架构下的 Worker 角色兼顾了 PS 架构下 PS/Worker 角色的功能。
通信方式:PS 架构下 PS/Worker 间通信走的是 TCP (Grpc/Seastar),Booster 架构下 Worker 间通信走的是 NVSwitch (NCCL),任意两卡间双向带宽 600GB/s,这也是 Booster 架构的训练速度取得较大提升的原因之一。
由于每张卡的输入数据不同,并且模型参数既有在卡间 Partition 存储的,也有在卡间 Replica 存储的,因此 Booster 架构同时存在模型并行、数据并行。此外,由于 NVIDIA A100 要求 CUDA 版本 >=11.0,而 TensorFlow 1.x 版本只有 NV1.15.4 才支持 CUDA11.0。美团绝大多数业务场景都还在使用 TensorFlow 1.x,因此我们所有改造都是在 NV1.15.4 版本基础上开发的。
以上就是 Booster 整体系统架构及内部执行流程的介绍。下文主要介绍在初步实现的 Booster 架构的基础上,我们所做的一些性能优化工作。
基于上述的设计实现完第一版系统后,我们发现端到端性能并不是很符合预期,GPU 的 SM 利用率(SM Activity 指标)只有 10%~20%,相比 CPU 并没有太大的优势。为了分析架构的性能瓶颈,我们使用 NVIDIA Nsight Systems(以下简称 nsys)、Perf、uPerf 等工具,通过模块化压测、模拟分析等多种分析手段,最终定位到数据层、计算层、通信层等几方面的性能瓶颈,并分别做了相应的性能优化。以下我们将以美团外卖某推荐模型为例,分别从 GPU 架构的数据层、计算层、通信层,逐个介绍我们所做的性能优化工作。
4.1 数据层
如前文所述,推荐系统的深度学习模型,样本量大,模型相对不复杂,数据 I/O 本身就是瓶颈点。如果几十台 CPU 服务器上的数据 I/O 操作,都要在单台 GPU 服务器上完成,那么数据 I/O 的压力会变得更大。我们先看一下在当前系统下的样本数据流程,如下图所示:
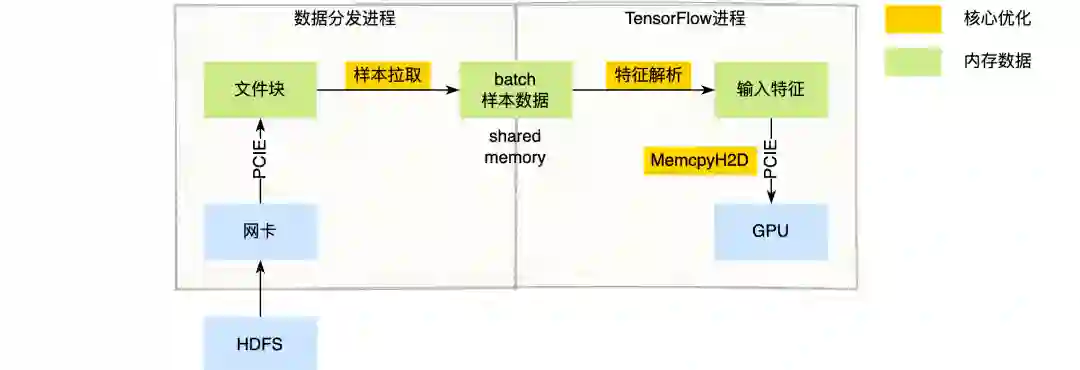
图 4 样本数据流程及核心优化点
核心流程:数据分发进程通过网络读取 HDFS 样本数据(TFRecord 格式)到内存中,然后通过共享内存 (Shared Memory) 的方式把样本数据传输给 TensorFlow 训练进程。TensrFlow 训练进程收到样本数据后,走原生的 TensrFlow 特征解析逻辑,拿到特征数据后通过 GPU MemcpyH2D 到 GPU 显存中。我们通过模块化压测分析发现,数据分发层的样本拉取、TensrFlow 层的特征解析以及特征数据 MemcpyH2D 到 GPU 等几个流程,都存在较大的性能问题(图中黄色流程所示),以下详细介绍我们在这几块所做的性能优化工作。
4.1.1 样本拉取优化
样本拉取、组装 Batch 是由数据分发进程完成的,我们在这里所做的主要优化工作是,首先将数据分发进程通过 numactl 独立到 NUMA 内部执行,避免了 NUMA 间的数据传输;其次,数据下载从单网卡扩充到了多网卡,增大数据下载带宽;最后,数据分发进程与 TensrFlow 进程之间的传输通道,从单个 Shared Memory 扩展到每张 GPU 卡有独立的 Shared Memory,避免了单 Shared Memory 所带来的内存带宽问题,并在 TensrFlow 内部实现了特征解析时对输入数据零拷贝的能力。
4.1.2 特征解析优化
目前,美团内部绝大多数业务的样本数据都还是 TFRecord 格式,TFRecord 实际上是 ProtoBuf(简称 PB)格式。PB 反序列化非常耗费 CPU,其中 ReadVarint64Fallback 方法 CPU 占用较为突出,实际 profiling 结果如下图:
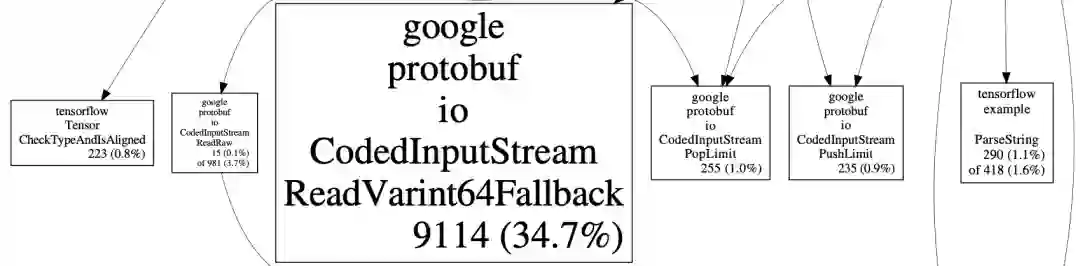
图 5 样本解析 profiling 结果
究其原因,CTR 场景的训练样本通常包含了大量的 int64 类型的特征,int64 在 PB 中是以 Varint64 类型数据存储的,ReadVarint64Fallback 方法就是用来解析 int64 类型的特征。普通的 int64 数据类型需要占用 8 个字节,而 Varint64 针对不同的数据范围,使用了变长的存储长度。PB 在解析 Varint 类型数据时,首先要确定当前数据的长度,Varint 用 7bit 存储数据,高位 1bit 存储标记位,该标记位表示下一个字节是否有效,如果当前字节最高位为 0,则说明当前 Varint 数据在该字节处结束。我们实际业务场景的 ID 特征大多是经过 Hash 后的值,用 Varint64 类型表达会比较长,这也就导致在特征解析过程中要多次判断数据是否结束,以及多次位移和拼接来生成最终数据,这使得 CPU 在解析过程中存在大量的分支预测和临时变量,非常影响性能。以下是 4 字节 Varint 的解析流程图:
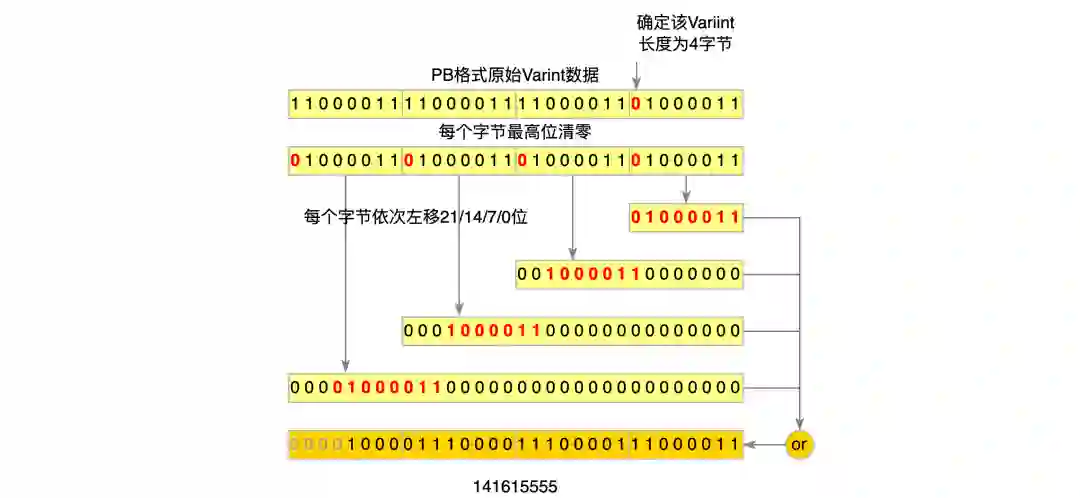
图 6 ProtoBuf Varint 解析流程图
这个处理流程,非常适合用 SIMD 指令集批处理优化。以 4 字节的 Varint 类型为例,我们的优化流程主要包括两步:
1. SIMD 寻找最高位:通过 SIMD 指令将 Varint 类型数据的每个字节与 0xF0 做与运算,找到第一个结果等于 0 的字节,这个字节就是当前 Varint 数据的结束位置。
2. SIMD 处理 Varint:按理来说,通过 SIMD 指令将 Varint 数据高位清零后的每个字节依次右移 3/2/1/0 字节,就可得到最终的 int 类型数据,但 SIMD 没有这样的指令。因此,我们通过 SIMD 指令分别处理每个字节的高 4bit、低 4bit,完成了这个功能。我们将 Varint 数据的高低 4bit 分别处理成 int_h4 与 int_l4,再做或运算,就得到了最终的 int 类型数据。具体优化流程如下图所示(4 字节数据):
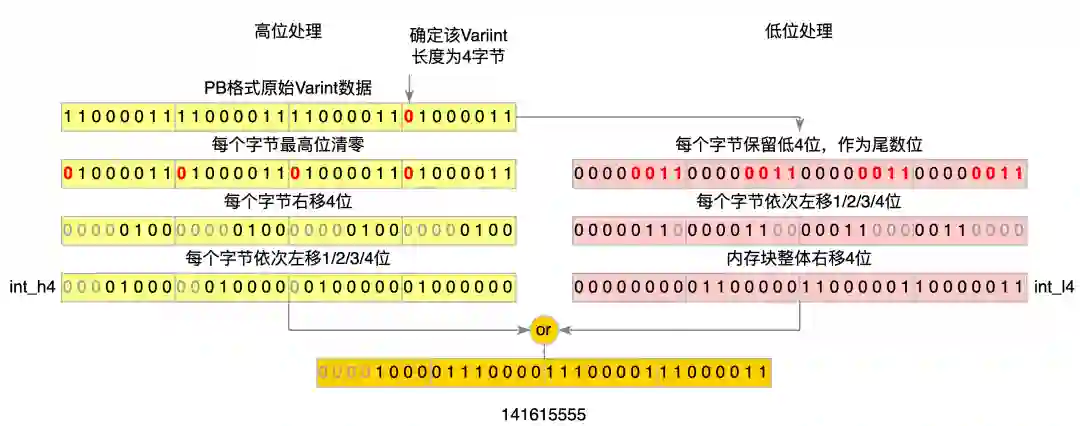
图 7 ProtoBuf Varint 解析优化后流程图
对于 Varint64 类型数据的处理,我们直接分成了两个 Varint 类型数据来处理。通过这两步的 SIMD 指令集优化,样本解析速度得到大大提升,在 GPU 端到端训练速度提升的同时,CPU 使用率下降了 15%。这里我们主要使用了 SSE 指令集优化,期间也尝试了 AVX 等更大长度的指令集,但效果不是很明显,最终并没有使用。此外,SIMD 指令集在老的机器上会导致 CPU 严重降频,因此官方社区并没有引入这个优化,而我们 GPU 机器的 CPU 都比较新,完全可以使用 SIMD 指令集进行优化。
4.1.3 MemcpyH2D 流水线
解析完样本得到特征数据后,需要将特征数据拉到 GPU 中才能执行模型计算,这里需要通过 CUDA 的 MemcpyH2D 操作。我们通过 nsys 分析这块的性能,发现 GPU 在执行期间有较多的停顿时间,GPU 需要等待特征数据 Memcpy 到 GPU 上之后才能执行模型训练,如下图所示:
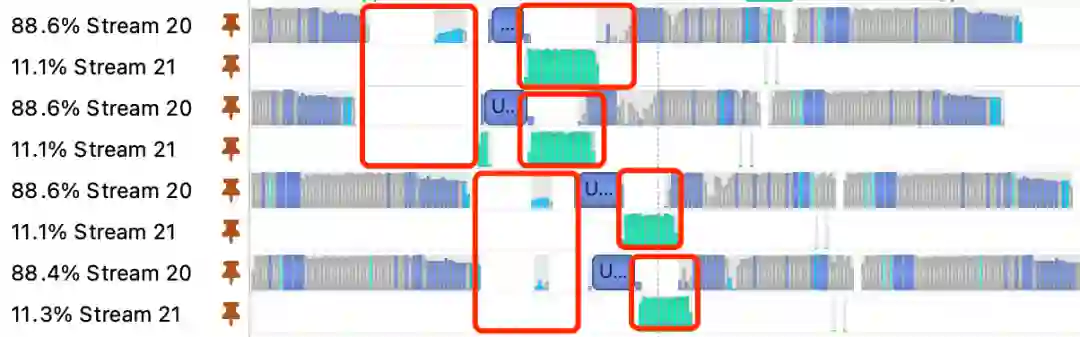
图 8 nsys profiling 结果
对于 GPU 系统的数据流,需要提前传输到离 GPU 处理器最近的显存中,才能发挥 GPU 的计算能力。我们基于 TensorFlow 的 prefetch 功能,实现了 GPU 版本的 PipelineDataset,在计算之前先把数据拷贝到了 GPU 显存中。需要注意的是 CPU 内存拷贝到 GPU 显存这个过程,CPU 内存需要使用 Pinned Memory,而非原生的 Paged Memory,可以加速 MemcpyH2D 流程。
4.1.4 硬件调优
在数据层的性能优化期间,美团内部基础研发平台的服务器组、网络组、操作系统组也帮助我们做了相关的调优:
在网络传输方面,为了减少网络协议栈处理开销,提高数据拷贝的效率,我们通过优化网卡配置,开启 LRO (Large-Receive-Offload)、TC Flower 的硬件卸载、Tx-Nocache-Copy 等特性,最终网络带宽提升了 17%。
在 CPU 性能优化方面,经过性能 profiling 分析,发现内存延迟和带宽是瓶颈。于是我们尝试了 3 种 NPS 配置,综合业务场景和 NUMA 特性,选择了 NPS2。此外,结合其他 BIOS 配置(例如 APBDIS,P-state 等),可以将内存延迟降低 8%,内存带宽提升 6%。
通过上述优化,网络极限带宽提升了 80%,在业务需求带宽下 GPU 的 H2D 带宽提升了 86%。最终在数据解析层面也拿到了 10%+ 的性能收益。
经过数据层样本拉取、特征解析、MemcpyH2D 和硬件的优化,Booster 架构端到端训练速度提升了 40%,训练性价比达到了 CPU 的 1.4 倍,数据层也不再成为当前架构的性能瓶颈。
4.2 计算层
4.2.1 Embedding 流水线
早在 CPU 场景做 TensorFlow 训练性能优化时,我们就已经实现了 Embedding Pipeline[1] 的功能:我们把整个计算图拆分为 Embedding Graph (EG) 和 Main Graph (MG) 两张子图,两者异步独立执行,做到执行上的 Overlap(整个拆分过程,可以做到对用户透明)。EG 主要覆盖从样本中抽取 Embedding Key,查询组装 Embedding 向量,Embedding 向量更新等环节;MG 主要包含稠密部分子网络计算、梯度计算、稠密参数部分更新等环节。

图 9 Embedding 流水线模块交互关系
两张子图的交互关系为:EG 向 MG 传递 Embedding 向量(从 MG 的视角看,是从一个稠密 Variable 读取数值),MG 向 EG 传递 Embedding 参数对应的梯度。上述两个过程的表达都是 TensorFlow 的计算图,我们利用两个 Python 线程,两个 TensorFlow Session 并发的执行两张计算图,使得两个阶段 Overlap 起来,以此达到了更大的训练吞吐。
我们把这个流程在 GPU 架构下也实现了一遍,并在其中加入了卡间同步流程,大规模稀疏特征的 AllToAll 通信及其反向梯度的 AllToAll 通信都在 EG 中执行,普通稀疏特征的反向梯度的卡间 AllGather 同步、稠密参数的反向梯度的卡间 AllReduce 同步都在 MG 中执行。需要注意的是,在 GPU 场景中,EG、MG 是在同一个 GPU Stream 上执行 CUDA Kernel 的,我们尝试过 EG、MG 分别在独立的 GPU Stream 上执行,性能会变差,深层原因与 CUDA 底层实现有关,这个问题本身还在等待解决。
4.2.2 算子 优化及 XLA
相比 CPU 层面的优化,GPU 上的优化更加复杂。首先对于 TensorFlow 的算子,还有一些没有 GPU 的实现,当模型中使用了这些 CPU 算子,会跟上下游的 GPU 算子出现内存和显存之间的数据来回拷贝,影响整体性能,我们在 GPU 上实现了使用较为频繁、影响较大的算子。另外,对于 TensorFlow 这代框架,算子粒度是非常细的,可以方便用户灵活搭建各种复杂的模型,但这对 GPU 处理器来说却是一个灾难,大量的 Kernel Launch 以及访存开销导致不能充分利用 GPU 算力。对于 GPU 上的优化,通常有两个方向,手工优化和编译优化。在手工优化方面,我们重新实现了一些常用的算子和层(Unique、DynamicPartition、Gather 等)。
以 Unique 算子为例,原生 TensorFlow 的 Unique 算子要求输出元素的顺序与输入元素的顺序一致,而在实际场景中,我们并不需要这个限制,我们修改了 Unique 算子的 GPU 实现,减少了因输出有序导致的额外执行的 GPU Kernel。
在编译优化方面,目前我们主要使用 TensorFlow 社区提供的 XLA[9] 来做一些自动优化。原生 TensorFlow 1.15 中的 XLA 正常开启可获得 10~20% 端到端的性能提升。但 XLA 对算子动态 shape 不能很好地进行支持,而推荐系统场景的模型中这种情况却非常常见,这就导致 XLA 加速性能不符合预期,甚至是负优化,因此我们做了如下的缓解工作:
局部优化:对于我们手动引入的动态 shape 算子(如 Unique),我们进行了子图标记,不执行 XLA 编译,XLA 只优化可以稳定加速的子图。
OOM 兜底:XLA 会根据算子的 type、input type、shape 等信息,缓存编译中间结果,避免重复编译。然而由于稀疏场景以及 GPU 架构实现的特殊性,天然存在 Unique、DynamicPartition 等 Output shape 是动态的算子,这就导致这些算子以及连接在这些算子之后的算子,在执行 XLA 编译时无法命中 XLA 缓存而重新编译,新的缓存越来越多,而旧的缓存不会被释放,最终导致 CPU 内存 OOM。我们在 XLA 内部实现了 LRUCache,主动淘汰掉旧的 XLA 缓存,避免 OOM 的问题。
Const Memcpy 消除:XLA 在使用 TF_HLO 重写 TensorFlow 算子时,对一些编译期已固定的数据会打上 Const 标记,然而这些 Const 算子的 Output 只能定义在 Host 端,为了将 Host 端的 Output 送给 Device 端需要再加一次 MemcpyH2D,这就占用了 TensorFlow 原有的 H2D Stream,影响样本数据提前拷贝到 GPU 端。由于 XLA 的 Const Output 在编译期已经固化,因此没有必要每一步都做一次 MemcpyH2D,我们将 Device 端的 Output 缓存下来,后续使用该 Output 时,直接从缓存中读取,避免多余的 MemcpyH2D。
对于 XLA 的优化,确切的来说应该是问题修复,目前能够做到的是 GPU 场景下可以正常开启 XLA,并获得 10~20% 的训练速度提升。值得一提的是,对于动态 shape 的算子编译问题,美团内部基础研发机器学习平台/深度学习编译器团队已经有了彻底的解决方案,后续我们会联合解决这个问题。
经过计算层的 Embedding 流水线、XLA 相关优化,Booster 架构端到端训练速度提升了 60%,GPU 单机八卡训练性价比达到同等资源下 CPU 的 2.2 倍。
4.3 通信层
在单机多卡训练过程中,我们通过 Nsight Systems 分析发现,卡间通信耗时占比非常高,而且在此期间 GPU 使用率也非常低,如下图所示:
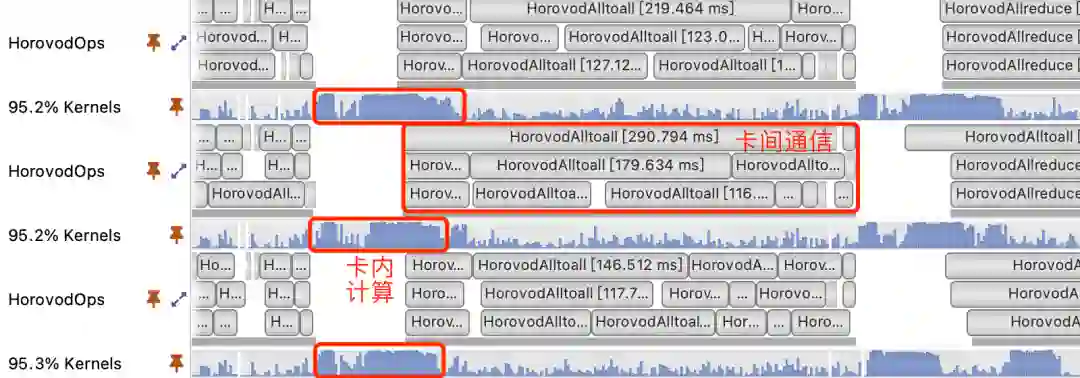
图 10 nsys profiling 结果
从图中可以看出,训练期间卡间通信耗时比较长,同时在通信期间 GPU 使用率也非常低,卡间通信是影响训练性能提升的关键瓶颈点。我们对通信过程进行拆解打点后发现,卡间通信(AllToAll、AllReduce、AllGather 等)协商的时间远远高于数据传输的时间:

图 11 Horovod timeline 结果
分析具体原因,以负责大规模稀疏参数通信的 AllToAll 为例,我们通过 Nsight Systems 工具,观察到通信协商时间长主要是由于某张卡上的算子执行时间比较晚导致的。由于 TensorFlow 算子调度并不是严格有序,同一个特征的 embedding_lookup 算子,在不同卡上真正执行的时间点也不尽相同,某张卡上第一个执行 embedding_lookup 算子在另一张卡上可能是最后一个执行,因此我们怀疑不同卡上算子调度的不一致性,导致了各张卡发起通信的时刻不同,并最终导致了通信协商时间过长。我们通过几组模拟实验也论证了确实是由算子调度导致的。对于这个问题,最直接的想法是改造 TensorFlow 计算图的核心调度算法,但这个问题在学术界也一直是一个复杂的问题。我们换了一种思路,通过融合关键的算子,来缓解这个问题,通过统计,我们选择了 HashTable 和 Variable 相关的算子。
4.3.1 HashTable 相关算子融合
我们设计和实现了一个图优化过程,这个过程会自动地将图中可以合并的 HashTable 及对应的 embedding_lookup 过程进行合并,合并策略上主要将 embedding_size 相同的 HashTable 合并到一块。同时为了避免 HashTable 合并之后原始特征之间发生 ID 冲突,我们引入了自动统一特征编码的功能,对不同的原始特征分别加上不同的偏移量,归入不同的特征域,实现了训练时的统一特征编码。
我们在某实际业务模型上进行测试,该图优化将 38 张 HashTable 合并成为了 2 张 HashTable,将 38 次 embedding_lookup 合并成了 2 次,这将 EmbeddingGraph 中的 embedding_lookup 相关算子数量减少了 90%,卡间同步通信次数减少了 90%。此外,算子合并之后,embedding_lookup 中的 GPU 算子也发生了合并,减少了 Kernel Launch 次数,使得 EmbeddingGraph 的执行速度变得更快。
4.3.2 Variable 相关算子融合
类似于 HashTable Fusion 的优化思路,我们观察到业务模型中通常包含数十至数百个 TensorFlow 原生的 Variable,这些 Variable 在训练期间梯度需要做卡间同步,同样的,Variable 数量太多导致卡间同步的协商时间变长。我们通过 Concat/Split 算子,将所有的 Trainable Variables 自动合并到一起,使得整个 MG 的反向只产生几个梯度 Tensor,大大减少了卡间同步的次数。同时,做完 Variable Fusion 之后,优化器中实际执行的算子数量也大大减少,加快了计算图本身的执行速度。
需要注意的是,TensorFlow 的 Variable 分为两种,一种是每个 Step 全部参数值都参与训练的 Dense Variable,如 MLP 的 Weight;另一种是专门用于 embedding_lookup 的 Variable,每个 Step 只有部分值参与训练,我们称之为 Sparse Variable。对于前者,做 Variable 合并不会影响到算法效果。而对于后者,它反向梯度是 IndexedSlices 对象,卡间同步默认走的是 AllGather 通信,如果业务模型中对于 Sparse Variables 的优化采用的是 Lazy 优化器,即每个 Step 只优化更新 Variable 中的某些行,此时对 Sparse Variables 做合并,会导致其反向梯度从 IndexedSlices 对象转为 Tensor 对象,卡间同步变成 AllReduce 过程,就可能会影响到算法效果。对于这种情况,我们提供了一个开关,由业务去控制是否合并 Sparse Variables。经过我们的实测,在某推荐模型上合并 Sparse Variables 会提高 5~10% 的训练性能,而对实际业务效果的影响在一个千分点以内。
这两种算子融合的优化,不仅优化了卡间通信性能,对卡内计算性能也有一定的提升。经过这两种算子融合的优化,GPU 架构端到端训练速度提升了 85%,同时不影响业务算法的效果。
4.4 性能指标
完成了数据层、计算层、通信层的性能优化后,对比我们的 TensorFlow[3] CPU 场景,GPU 架构取得了 2~4 倍的性价比收益(不同业务模型收益不同)。我们基于美团外卖某推荐模型,使用单台 GPU 节点(A100 单机八卡)和同成本的 CPU Cluster,分别对比了原生 TensorFlow 1.15 和我们优化后的 TensorFlow 1.15 的训练性能,具体数据如下:
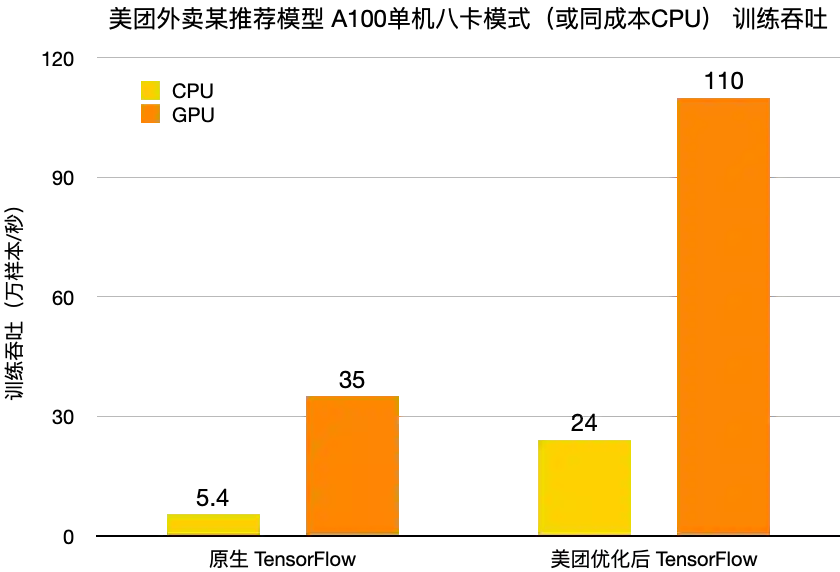
图 12 CPU/GPU 训练吞吐对比
可以看到,我们优化后的 TensorFlow GPU 架构训练吞吐,是原生 TensorFlow GPU 的 3 倍以上,是优化后 TensorFlow CPU 场景的 4 倍以上。
注:原生 TensorFlow 使用了 tf.Variable 作为 Embedding 的参数存储。
Booster 架构要在业务生产中落地,不只是要有一个良好的系统性能,还需要同时关注训练生态系统的完备性以及训练产出模型的效果。
5.1 完备性
一次完整的模型训练实验,除了要跑训练 (Train) 任务外,往往还需要跑模型的效果评估 (Evaluate) 或模型的预估 (Predict) 任务。我们基于 TensorFlow Estimator 范式对训练架构进行封装,实现用户侧一套代码统一支持 GPU 和 CPU 场景下的 Train、Evaluate 和 Predict 任务,通过开关进行灵活切换,用户只需要关注模型代码本身的开发。我们将架构改动全都封装到了引擎内部,用户只需要一行代码就能从 CPU 场景迁移到 GPU 架构:
tf.enable_gpu_booster()实际业务场景,用户通常会使用 train_and_evaluate 模式,在跑训练任务的过程中同时评估模型效果。上了 Booster 架构后,由于训练跑的太快,导致 Evaluate 速度跟不上训练正常产出 Checkpoint 的速度。我们在 GPU 训练架构的基础上,支持了 Evaluate on GPU 的能力,业务可以申请一颗 A100 GPU 专门用来做 Evaluate,单颗 GPU 做 Evaluate 的速度是 CPU 场景下单个 Evaluate 进程的 40 倍。同时,我们也支持了 Predict on GPU 的能力,单机八卡 Predict 的速度是同等成本下 CPU 的 3 倍。
此外,我们在任务资源配置上也提供了比较完善的选项。在单机八卡(A100 单台机器至多配置 8 张卡)的基础上,我们支持了单机单卡、双卡、四卡任务,并打通了单机单卡/双卡/四卡/八卡/CPU PS 架构的 Checkpoint,使得用户能够在这几种训练模式间自由切换、断点续训,方便用户选择合理的资源类型、资源量跑实验,同时业务也能够从已有模型的 Checkpoint 来 WarmStart 训练新的模型。
5.2 训练效果
相较 PS/Worker 异步模式的 CPU 训练,单机多卡训练时卡间是全同步的,因而避免了异步训练梯度更新延迟对训练效果的影响。然而,由于同步模式下每一步迭代的实际 Batch Size 是每张卡样本数的总和,并且为了充分利用 A100 卡的算力,我们会将每张卡的 Batch Size(单步迭代的样本数)尽量调大。这使得实际训练的 Batch Size(1 万~10 万)比 PS/Worker 异步模式(1 千~1 万)大很多。我们需要面临大 Batch 下训练超参调优的问题[26,27]:在保证 Epoch 不变的前提下,扩大 Batch Size 会导致参数有效更新次数减少,可能导致模型训练的效果变差。
我们采用 Linear Scaling Rule[28] 的原则指导调整学习率。如果训练 Batch Size 较 PS/Worker 模式的 Batch Size 增大 N 倍,将学习率也放大 N 倍即可。这种方式简单便于操作,实践效果还不错。当然需要注意的是,如果原有训练方式的学习率已经很激进时,大 Batch Size 训练学习率的调整幅度则需要适当减小,或者使用学习率 Warmup 等更复杂的训练策略[29]。我们会在后续工作中对超参优化模式做更深入的探索。
在美团推荐系统训练场景,随着模型越来越复杂,CPU 上优化的边际效应越来越低。美团基于内部深度定制的 TensorFlow、NVIDIA HugeCTR,研发了 Booster GPU 训练架构。整体设计充分考虑算法、架构、新硬件的特性,并从数据、计算、通信等多个角度深度优化,对比之前 CPU 的任务,性价比提升到 2~4 倍。从功能和完备性上支持 TensorFlow 的各类训练接口(Train/Evaluate/Rredict 等),支持 CPU 和 GPU 模型相互导入。易用性上 TensorFlow CPU 任务只需要一行代码就可完成 GPU 架构迁移。目前在美团外卖推荐场景实现了大规模的投产应用,后续我们将会全面推广到到家搜索推荐技术部以及美团全业务线。
当然,Booster 基于 NVIDIA A100 单机多卡还有不少优化空间,如数据层面的样本压缩、序列化、特征解析,计算层面的多图算子调度、动态 shape 算子的编译优化,通信层面的量化通信等等。同时为了更广泛的支持美团内的业务模型,Booster 的下一个版本也会支持更大的模型,以及多机多卡的 GPU 训练。
家恒、国庆、峥少、晓光、鹏鹏、永宇、俊文、正阳、瑞东、翔宇、秀峰、王庆、封宇、事峰、黄军等,来自美团基础研发平台-机器学习平台训练引擎&到家研发平台-搜索推荐技术部 Booster 联合项目组。
参考文献
[1] https://tech.meituan.com/2021/12/09/meituan-tensorflow-in-recommender-systems.html
[2] https://images.nvidia.cn/aem-dam/en-zz/Solutions/data-center/nvidia-ampere-architecture-whitepaper.pdf
[3] https://www.usenix.org/system/files/conference/osdi14/osdi14-paper-li_mu.pdf
[4] https://github.com/NVIDIA-Merlin/HugeCTR
[5] https://en.wikipedia.org/wiki/Nvidia_Tesla
[6] https://www.nvidia.com/en-us/data-center/dgx-a100
[7] https://github.com/horovod/horovod
[8] https://github.com/NVIDIA/nccl
[9] https://www.tensorflow.org/xla
[10] Yann LeCun, John S. Denker, and Sara A. Solla. Optimal brain damage. In NIPS, pp. 598–605. Morgan Kaufmann, 1989.
[11] Kenji Suzuki, Isao Horiba, and Noboru Sugie. A simple neural network pruning algorithm with application to filter synthesis. Neural Process. Lett., 13(1):43–53, 2001.
[12] Suraj Srinivas and R. Venkatesh Babu. Data-free parameter pruning for deep neural networks. In BMVC, pp. 31.1–31.12. BMVA Press, 2015.
[13] Jonathan Frankle and Michael Carbin. The lottery ticket hypothesis: Finding sparse, trainable neural networks. In 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019. OpenReview.net, 2019.
[14] Hao-Jun Michael Shi, Dheevatsa Mudigere, Maxim Naumov, and Jiyan Yang. Compositional embeddings using complementary partitions for memory-efficient recommendation systems. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pp. 165-175. 2020.
[15] https://mp.weixin.qq.com/s/fOA_u3TYeSwAeI6C9QW8Yw
[16] Jianxun Lian, Xiaohuan Zhou, Fuzheng Zhang, Zhongxia Chen, Xing Xie, and Guangzhong Sun. 2018. xDeepFM: Combining Explicit and Implicit Feature Interactions for Recommender Systems. arXiv preprint arXiv:1803.05170 (2018).
[17] Weiping Song, Chence Shi, Zhiping Xiao, Zhijian Duan, Yewen Xu, Ming Zhang, and Jian Tang. Autoint: Automatic feature interaction learning via self-attentive neural networks. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, pp. 1161-1170. 2019.
[18] Guorui Zhou, Weijie Bian, Kailun Wu, Lejian Ren, Qi Pi, Yujing Zhang, Can Xiao et al. CAN: revisiting feature co-action for click-through rate prediction. arXiv preprint arXiv:2011.05625 (2020).
[19] Chun-Hao Chang, Ladislav Rampasek, and Anna Goldenberg. Dropout feature ranking for deep learning models. arXiv preprint arXiv:1712.08645 (2017).
[20] Xu Ma, Pengjie Wang, Hui Zhao, Shaoguo Liu, Chuhan Zhao, Wei Lin, Kuang-Chih Lee, Jian Xu, and Bo Zheng. Towards a Better Tradeoff between Effectiveness and Efficiency in Pre-Ranking: A Learnable Feature Selection based Approach. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, pp. 2036-2040. 2021.
[21] Bencheng Yan, Pengjie Wang, Jinquan Liu, Wei Lin, Kuang-Chih Lee, Jian Xu, and Bo Zheng. Binary Code based Hash Embedding for Web-scale Applications. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management, pp. 3563-3567. 2021.
[22] Xiangyu Zhao, Haochen Liu, Hui Liu, Jiliang Tang, Weiwei Guo, Jun Shi, Sida Wang, Huiji Gao, and Bo Long. Autodim: Field-aware embedding dimension searchin recommender systems. In Proceedings of the Web Conference 2021, pp. 3015-3022. 2021.
[23] Bencheng Yan, Pengjie Wang, Kai Zhang, Wei Lin, Kuang-Chih Lee, Jian Xu, and Bo Zheng. Learning Effective and Efficient Embedding via an Adaptively-Masked Twins-based Layer. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management, pp. 3568-3572. 2021.
[24] Ting Chen, Lala Li, and Yizhou Sun. Differentiable product quantization for end-to-end embedding compression. In International Conference on Machine Learning, pp. 1617-1626. PMLR, 2020.
[25] Wang-Cheng Kang, Derek Zhiyuan Cheng, Ting Chen, Xinyang Yi, Dong Lin, Lichan Hong, and Ed H. Chi. Learning multi-granular quantized embeddings for large-vocab categorical features in recommender systems. In Companion Proceedings of the Web Conference 2020, pp. 562-566. 2020.
[26] Nitish Shirish Keskar, Dheevatsa Mudigere, Jorge Nocedal, Mikhail Smelyanskiy, and Ping Tak Peter Tang. On large-batch training for deep learning: Generalization gap and sharp minima. arXiv preprint arXiv:1609.04836 (2016).
[27] Elad Hoffer, Itay Hubara, and Daniel Soudry. Train longer, generalize better: closing the generalization gap in large batch training of neural networks. Advances in neural information processing systems 30 (2017).
[28] Priya Goyal, Piotr Dollár, Ross Girshick, Pieter Noordhuis, Lukasz Wesolowski, Aapo Kyrola, Andrew Tulloch, Yangqing Jia, and Kaiming He. Accurate, large minibatch sgd: Training imagenet in 1 hour. arXiv preprint arXiv:1706.02677 (2017).
[29] Chao Peng, Tete Xiao, Zeming Li, Yuning Jiang, Xiangyu Zhang, Kai Jia, Gang Yu, and Jian Sun. Megdet: A large mini-batch object detector. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, pp. 6181-6189. 2018.

点击“阅读原文”访问 TensorFlow 官网
不要忘记“一键三连”哦~

分享

点赞

在看





