CVPR 2022|Adobe把GAN搞成了缝合怪,凭空P出一张1024分辨率全身人像

极市导读
从脸,肤色、服饰、头发等身体各个部位,甚至到肢体动作,都能被随意设计和组合,最终“缝”成一张1024 × 1024分辨率的全身照片。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

论文地址:
https://arxiv.org/abs/2203.07293
换脸见多了,换身材的见过吗?
给定一张脸,就能自动换一个下半身,服饰、身材、肤色都毫无PS痕迹:

核心技术当然还是我们熟悉的GAN,但不同的是,现在身体的每个部分都能被PS了。
从脸,肤色、服饰、头发等身体各个部位,甚至到肢体动作,都能被随意设计和组合,最终“缝”成一张1024 × 1024分辨率的全身照片:

而且这张“缝合怪”还完全没有拼接行为带来的阴影和边界:

怎么做到的?把用于生成人体不同部位的GAN“拼”起来。

这就是Adobe团队最新提出的一种结合多个预训练的GAN进行图像生成的新方法,论文目前已被CVPR 2022接收:

接下来就一起来看看他们到底是如何实现的。
用PS的方式GAN出个人体
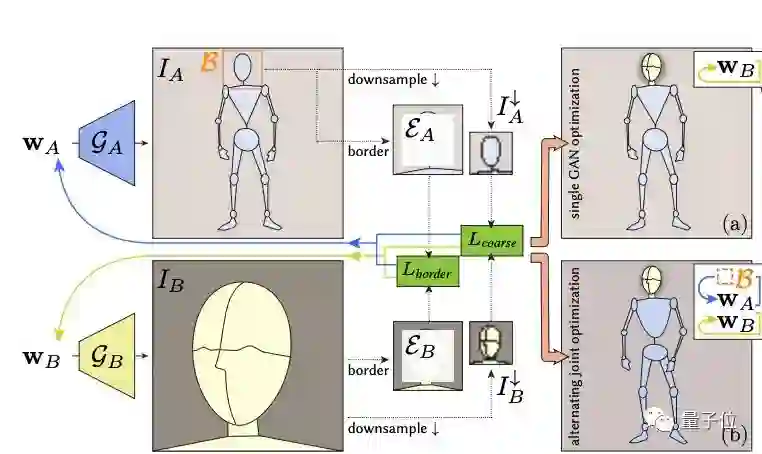
如我们开头所说,这是一种将多个GAN拼接起来使用的方法,研究团队将其称之为InsetGAN。
共分为两类GAN:
-
全身GAN (Full-Body GAN),基于中等质量的数据进行训练并生成一个人体。
-
部分GAN,其中包含了多个针对脸部、手、脚等特定部位进行训练的GAN。
这两类GAN的合作方式类似于PS:全身GAN是一张已经有打底线稿的画布,而部分GAN则是一张一张叠在上面的图层。
但不同边界的“图层”在叠到画布上时,一定会有出现对齐问题。
比如,将一张脸添加到身体上时,在肤色的一致性、衣服边界和头发披散的自然性上可能出现细节的扭曲和丢失,或出现伪影(Artifacts):

如何才能更好地协调多个GAN,让它们产生一致的像素呢?
研究团队设计了这样一种架构:他们首先引入了一个边界框检测器,检测部分GAN生成的特定区域在底层画布,也就是全身GAN生成的区域中的位置,经过裁剪后再将特定区域嵌入。
这一过程相当于找到了两个区域之间的一种随机潜码 (latent code),使得所选区域的边界能够和嵌入区域相匹配,以实现无缝合成。
同时,他们还会对这两个区域进行下采样(Downsample),再次增加图像像素内容的一致性。
基于这种方法,InsetGAN可以在训练后生成多张完整人像,同时肤色、头发和相关姿势都能作出相应调整:

研究团队也与之前的生成全身人像的方法CoModGAN做了比较,都是基于左侧的人体进行面部的替换,显然,InsetGAN生成的面部更加自然:

作者介绍
论文共有6位作者,5位来自Adobe研究院,还有1位来自阿卜杜拉国王科技大学(KAUST)。
其中有Adobe的首席科学家Jingwan Lu,是PS 2020中智能肖像、皮肤平滑、着色和神经风格化等过滤器的主要算法贡献者,也是RealBrush笔刷合成器的开发者。
她目前领导的团队主要致力于利用大数据和生成性AI(比如GAN)来进行视觉内容的创造。

所以,准备好足不出户换身材了吗?(手动狗头)
参考链接:
[1]https://www.youtube.com/watch?v=YKFYEt5hvOo
[2]http://afruehstueck.github.io/insetgan/
公众号后台回复“数据集”获取30+深度学习数据集下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~




