能牺牲大语种、提升小语种翻译质量的谷歌多语言机器翻译

作者 | 杨晓凡
近期,谷歌拓展了机器翻译系统的边界:用所有可用的数据训练一个超大规模的多语言神经机器翻译系统。这不仅是一次大胆的尝试,也更新了我们对机器翻译模型的一些认识。AI 科技评论把谷歌的这篇介绍博客编译如下。另外,这篇介绍博客也提到了许多相关论文,我们在文中标出的同时,也在文末提供了统一说明和打包下载,方便各位仔细阅读。
「也许语言翻译的奥妙,就在于从每种语言往下挖掘,一直挖到人类沟通的共同基础——那种真实存在但是尚未被发现的通用语言——然后从那里重新衍生出方便的具体路径。」 —— Warren Weaver, 1949
寻找新的挑战
大规模多语言机器翻译

不同语言的资源数量(纵轴是 log 尺度),以及只使用各自的双语语料训练翻译模型得到的 BLEU 分数

相比于用双语语料分别训练的模型,单个大规模多语言翻译模型能大大提升低资源语言的翻译质量;但高资源语言的翻译质量反而有所下降
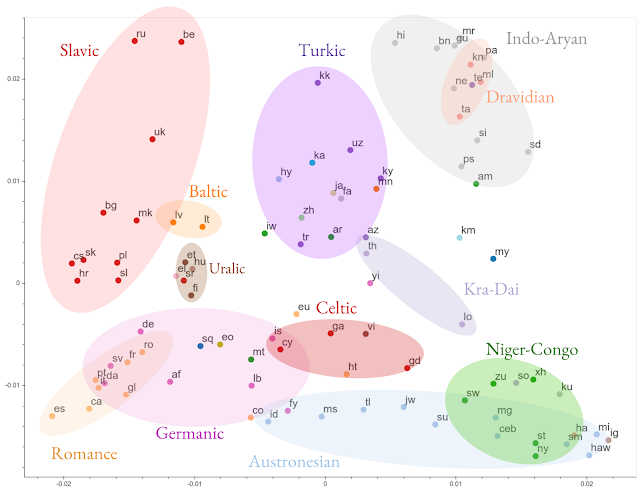
根据表征相似性对所有 103 种语言的编码表征进行聚类的结果。图中带颜色的椭圆是语言学分类的结果 —— 和根据表征的聚类基本相符
构建大规模神经网络

用容量更大的模型,配合增加更多语料,高资源语言的翻译质量也能和低资源语言一样继续得到提升
把 M4 模型变得实用
下一步迈向哪里?
提及的论文查阅
论文 1:Multi-Task Learning for Multiple Language Translation,https://www.aclweb.org/anthology/P15-1166/
论文 2:Google’s Multilingual Neural Machine Translation System: Enabling Zero-Shot Translation,https://arxiv.org/abs/1611.04558
论文 3:Multi-Way, Multilingual Neural Machine Translation with a Shared Attention Mechanism,https://www.aclweb.org/anthology/N16-1101/
论文 4:Massively Multilingual Neural Machine Translation,https://arxiv.org/abs/1903.00089
论文 5:Massively Multilingual Neural Machine Translation in the Wild: Findings and Challenges,https://arxiv.org/abs/1907.05019
论文 6:GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism,https://arxiv.org/abs/1811.06965
论文 7:Investigating Multilingual NMT Representations at Scale,https://arxiv.org/abs/1909.02197
论文 8:Evaluating the Cross-Lingual Effectiveness of Massively Multilingual Neural Machine Translation,https://arxiv.org/abs/1909.00437
论文 9:Simple, Scalable Adaptation for Neural Machine Translation,https://arxiv.org/abs/1909.08478
论文 10:Adaptive Scheduling for Multi-Task Learning,https://arxiv.org/abs/1909.06434
论文 11:Soft Conditional Computation,https://arxiv.org/abs/1904.04971
论文 12:Training Deeper Neural Machine Translation Models with Transparent Attention,https://arxiv.org/abs/1808.07561
论文 13:Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer,https://arxiv.org/abs/1701.06538

张钹院士:人工智能的魅力就是它永远在路上 | CCAI 2019
Facebook 自然语言处理新突破:新模型能力赶超人类 & 超难 NLP 新基准

点击“阅读原文”查看 如何教神经网络玩 21 点游戏(附代码)?


