吸烟致癌的迷思是如何破除的?

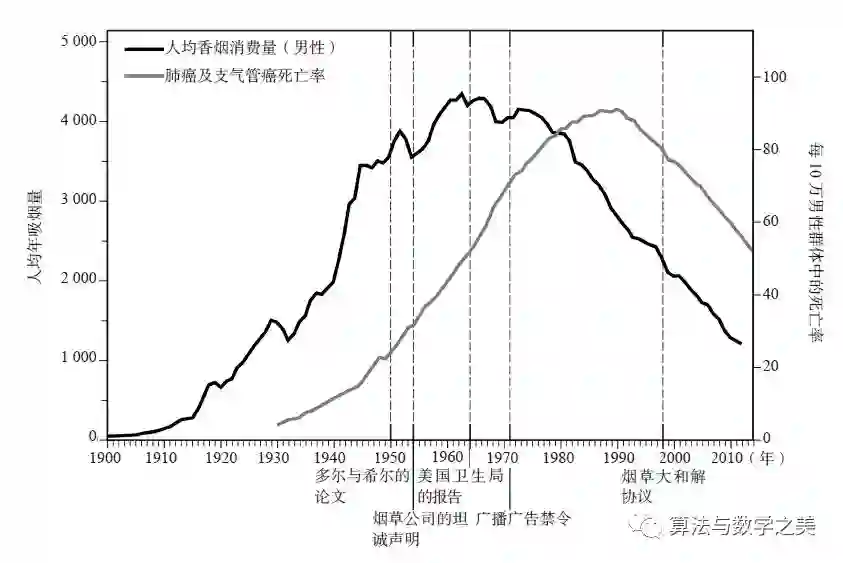
1948年,多尔和希尔进行了研究合作,共同探索癌症流行的原因。希尔作为首席统计学家,在当年的早些时候发表了一项非常成功的随机对照试验。
希尔当然知道,在对吸烟是否致癌这一问题的研究上,随机对照试验是不适用的,但是他已经认识到了对比处理组和对照组这一方法的优势所在。因此,他建议将已经被诊断为癌症的病人与由健康志愿者组成的对照组进行比较,采访每一组的成员,了解他们过去的行为和病史。为避免偏倚,他没有告知采访者其采访对象是处理组的癌症患者还是对照组的健康志愿者。
研究结果令人震惊。在649 名接受采访的肺癌患者中,除两人外其余均为吸烟者。这一结果在统计学上与随机水平相去甚远,是一件极不可能发生之事。多尔和希尔情不自禁地计算出了该结果的精确度:1 500 000∶1。此外,平均而言,肺癌患者的吸烟量也比对照组成员的吸烟量更大,但采访也显示,肺癌患者吸入烟雾的比例相对较小(注意,在之后的辩论中, 费舍尔就抓住这一结果中的矛盾进行了激烈的攻击)。
多尔和希尔将“病例”(患有疾病的人)与对照组进行了比较,因此这种研究类型现在也被称为“病例—对照研究”(case-control study)。相对于时间序列数据而言,借助这种方法搜集数据显然是一种进步,因为研究人员可以控制包括年龄、性别和所接触的环境污染物等混杂因子。然而,病例—对照设计也存在一些明显的弊端。首先,它是回顾性的,这意味着我们已知研究对象患有癌症,在此前提下我们要回顾过去找出原因。其次,它的概率逻辑也是反向的,这些数据告诉我们的是癌症患者是吸烟者的概率,而不是吸烟者患癌症的概率。对于那些想知道是否应该吸烟的人,吸烟者患癌症的概率才是他们真正关心的概率。
此外,病例—对照研究承认存在几种可能的偏倚来源。其中之一被称为“回忆偏倚”:虽然多尔和希尔确保了采访者不知道其采访对象是否患有癌症,但被采访者本人肯定知道他们自己是否患有癌症,而这一事实很可能会影响他们的回忆。另一个来源是选择偏倚:已入院就医的癌症患者绝不是整个人口总体的代表性样本,甚至不能作为吸烟者总体的代表性样本。
接下来的几年里,在不同国家进行的19个病例—对照研究基本上都得出了类似的结论。但正如费舍尔毫不在意地指出的那样,一项有偏倚的研究重复19次也不能证明任何事情,它仍有偏倚。费舍尔在1957年写道,这些研究“仅仅是同类证据的重复,因此,我们有必要尝试检验一下这种研究方法是否足以得出任何科学结论”。
多尔和希尔意识到,如果病例—对照研究中的确存在隐藏的偏倚,那么仅仅靠重复研究肯定是无法消除偏倚的。因此,他们于1951年开始了一项前瞻性研究,向6万名英国医生发放调查问卷,采集关于其吸烟习惯的信息,并对他们进行追踪调查。(美国癌症协会也在同一时间发起了一项类似的、规模更大的研究。)在短短的5年里,一些戏剧性的差异就出现了。
在接受了追踪调查的医生中,重度吸烟者患肺癌死亡的概率是不吸烟者的24倍。在美国癌症协会发表的研究结果中,情况甚至更加严峻:一方面,吸烟者死于肺癌的概率是不吸烟者的29倍,而重度吸烟者死于肺癌的概率更是不吸烟者的90倍。另一方面,曾经吸烟,然后戒烟的那些人,其患病风险降低了一半。所有这些结果都表明了一个一致的结论:吸烟越多,患肺癌的风险就越高,而戒烟能降低这种风险。这是一个强有力的因果证据。医生们称此类结论为“剂量—响应效应”(dose-response effect):如果物质 A会导致生物反应B,则通常而言(但不是百分之百),更大剂量的A会导致更强的反应 B。
前瞻性研究仍未能将吸烟者与其他各方面都相同的不吸烟者进行比较。事实上,这种比较是否可行值得怀疑。毕竟,吸烟是吸烟者的一种自我选择。在许多方面,他们都可能与不吸烟者有着基因或“体质”上的不同,比如有更多的冒险行为,更易饮酒过量等。其中一些行为同样可能会对健康造成不良影响,而这些不良影响可能被错误地归咎于吸烟。对于怀疑论者来说,这是一个特别便利的论据,因为体质假说几乎不可检验。直到2000 年人类基因组测序工程开启之后,寻找与肺癌相关的基因才成为可能。
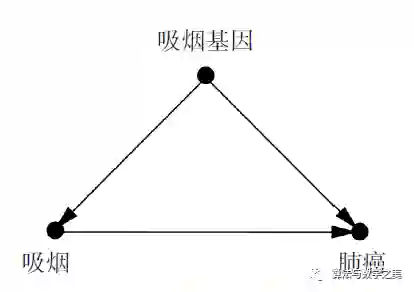
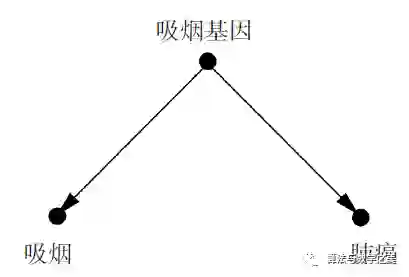
对于体质假说,杰尔姆·康菲尔德与亚伯·利连菲尔德于1959 年共同发表了一篇论文,逐一驳斥了费舍尔的论据。康菲尔德把目标直接对准了费舍尔的体质假说,并在费舍尔的领域——数学中阐述了他的驳斥。他认为,假设存在一个混杂因子,比如吸烟基因,它完全地解释了吸烟者患肺癌的风险。如果吸烟者患肺癌的风险为常人的9 倍,那么在吸烟者中,这种混杂因子存在的概率也需要至少比常人高出9 倍,如此才能解释这种患病风险的差异。让我们思考一下这意味着什么:如果有11% 的不吸烟者携带“吸烟基因”,那么就至少有99% 的吸烟者一定携带吸烟基因。而如果有12% 的不吸烟者碰巧携带这种基因,那么从数学的角度看,“吸烟基因”就不可能完全解释吸烟和癌症之间的相关。对生物学家来说,这个被称为“康菲尔德不等式”(Cornfield’s inequality)的论证瓦解了费舍尔的体质假说。因为在现实中,我们很难想象基因方面的某个差异可以如此紧密地与某人选择吸烟这种复杂的、不可预知的行为和意愿联系在一起。
康菲尔德不等式实际上是因果论证的雏形:它提供了一种标准,让我们可以在因果图2(此种情况下,体质假说无法完全解释吸烟与肺癌之间的关联)和因果图3(此种情况下,吸烟基因的存在能充分解释我们观察到的关联)中做出裁定。
尽管流行病学家早已对此问题达成了共识,但在此后很长一段时间里,吸烟与癌症之关系在公众眼中仍然存在争议。即使是本该更积极地响应科学号召的医生们也心存疑虑:美国癌症协会在1960年进行的一项民意调查显示,美国只有1/3的医生认同吸烟是“肺癌的主要原因”,而43%的医生自己就是吸烟者。
虽然我们现在可以公正地批评费舍尔的顽固和烟草公司的蓄意欺骗,但也必须承认,当时的科学家一直是在一种僵化的思想框架下开展工作的。费舍尔提倡随机对照试验,并将其视为评估因果效应的一种高效的方法,这完全没错。然而,他和他的追随者没有意识到的是,我们从观察性研究中也可以学到很多东西。这就是因果模型的好处:它能够调用研究者业已掌握的科学知识来分析新问题。费舍尔的方法实际上是在假设研究者对所要测试的假设没有预先的知识或看法。他们把无知强加给科学家,而这正是吸烟致癌论怀疑者在这场争论中乐于利用的优势。
由于科学家不具备对“导致”这个词的明确定义,也无法在随机对照试验不适用的情况下确定因果效应,因此,对于吸烟是否会导致癌症的争论,他们的准备是不充分的。他们被迫摸索着寻找一个定义,这一寻找过程贯穿了整个20 世纪50 年代。

***粉丝福利***
评论区留言,点赞数前三可获得此书,以48个小时计!
————
编辑 ∑Gemini
☞算法立功!清华毕业教授美国被抢车,警察无能为力自己用“贪心算法”找回
☞分享 数学,常识和运气 ——投资大师詹姆斯·西蒙斯2010年在MIT的讲座
算法数学之美微信公众号欢迎赐稿
稿件涉及数学、物理、算法、计算机、编程等相关领域,经采用我们将奉上稿酬。
投稿邮箱:math_alg@163.com




