[论文简介] 探索类人开放域聊天机器人
原论文:Towards a Human-like Open-Domain Chatbot
作者单位:Google Research, Brain Team
出版:arXiv 2001.09977

本文主要采用 Evolved Transformer 模型,使用 TPUv3 Pod (2048 TPU 核)在 400 亿 单词的 Meena 数据集上进行了一个月训练,模型参数量 26 亿,取得了开放域聊天机器人的最佳效果。但是,本文的主要贡献并非在神经网络方法上,而是提出了聊天机器人的相关度量准则,并证明了暴力训练所得的端到端模型相比于现有的复杂的手工规则的聊天机器人的有效性。
摘要
作者介绍了Meena,一个多轮开放域聊天机器人,对从公共领域社交媒体会话中提取和过滤的数据进行了端到端的训练。训练了这个 26 亿参数的神经网络,以最大程度地减少困惑(一种自动度量,可以与人类对多回合会话质量的判断进行比较)。
为了获得这种判断,作者提出了一种称为“敏感度和特异度平均值”(SSA)的人类评估指标,该指标涵盖了良好交谈的关键要素。
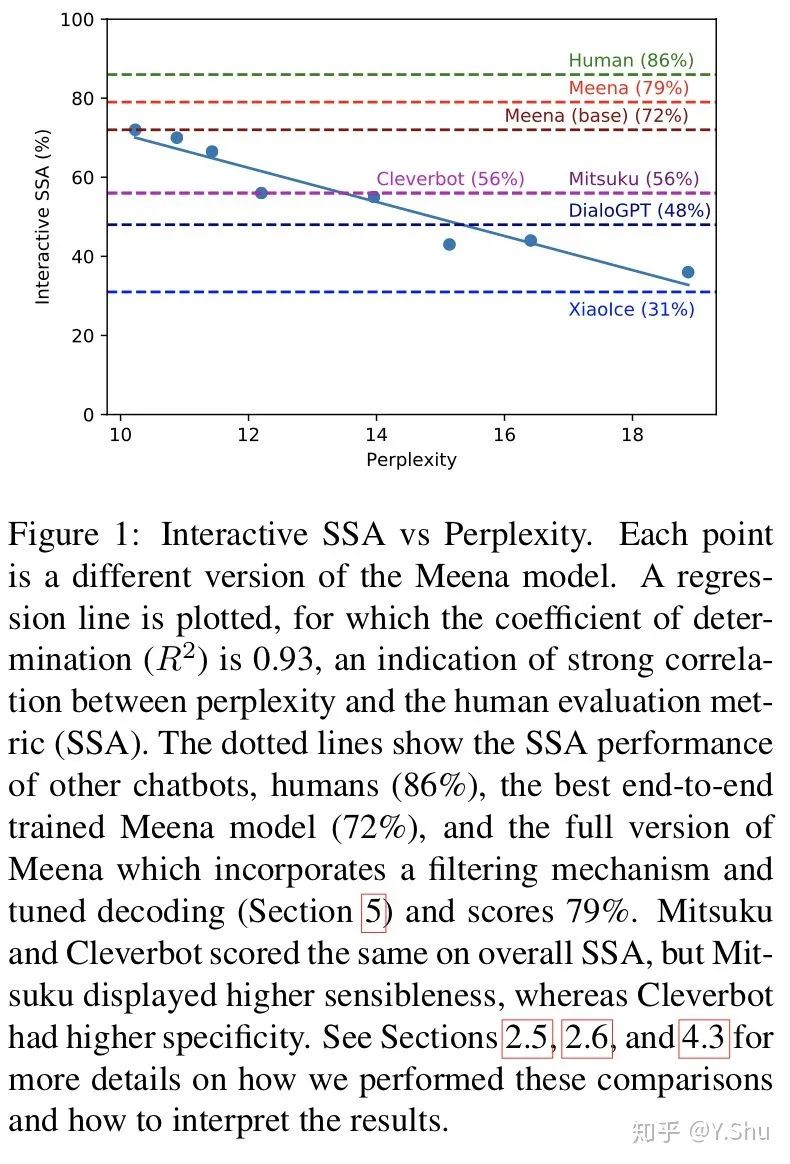
有趣的是,作者的实验表明困惑和 SSA 之间具有很强的相关性。最佳的困惑度端到端训练有素的Meena在SSA上得分很高(多回合评估为72%),这表明如果我们能够更好地优化困惑度,那么人类水平的SSA可能达到86%。此外,完整版的Meena(具有过滤机制和调谐解码功能)的SSA得分为79%,比我们评估的现有聊天机器人的绝对SSA得分高23%。
介绍
在自然语言中自由交流的能力是人类智能的标志之一,并且可能是真正的人工智能的要求。为了探索智能的这一方面,许多研究人员正在研究开放域聊天机器人。与封闭域聊天机器人可以响应关键字或意图完成特定任务的意图不同,开放域聊天机器人可以参与任何主题的对话。
现有的开放域聊天机器人依赖于复杂的框架,例如具有基于知识、基于检索或基于规则的系统的对话管理器。另一方面,端到端神经网络方法,提供单一学习模型的简单性。尽管进行了大量研究,但开放域聊天机器人仍然存在一些弱点,无法使它们普遍使用:它们经常以没有意义的方式或以模糊而笼统的答复来响应开放式输入。
作者提出 Meena,一个生成式聊天机器人模型,通过从公共领域社交媒体对话中提取和过滤的 400 亿个单词进行了端到端的训练得到。借助 Meena,作者突破了端到端方法的局限性,并表明大规模的低复杂度模型可能是一个很好的转换方法。作者使用seq2seq模型,并将Evolved Transformer(So 等,2019)作为主要架构。在多回合对话中训练模型,其中输入序列是上下文的所有回合(最多7个),而输出序列是响应。作者的最佳模型具有 26 亿参数,并且基于8K BPE子词的词汇量达到了10.2的测试困惑度(Sennrich 等,2016)。
为了衡量 Meena 和其他聊天机器人的质量,作者提出了一种简单的人工评估方法。敏感度和特异性平均值(SSA)结合了类人聊天机器人的两个基本方面:有意义和特定。作者要求人类判断者在这两个标准上标记每个模型响应。度量标准的第一部分是敏感性,这是基本要求。为了与人正确对话,机器人的响应必须在上下文中变得有意义。人们通常在彼此交谈时认为这是理所当然的,作者的评估发现,人类产生的陈述中有97%符合这一标准(请参阅第4.2节)。但是,仅凭道理是不够的。如果将模型设计为明智的唯一目标,那么它的响应可能是模糊而乏味的,因为这是避免因不合理而受到惩罚的一种安全策略。例如,当人们问自己域外的某些问题时,封闭域聊天机器人通常会做出一般的道歉响应。一些端到端的学习型聊天机器人对许多输入都回答“我不知道”(Li等,2016a);和图灵测试竞赛参赛者经常试图通过策略上的模糊去避免被发现(Venkatesh et al。,2018)。他们成功地避免了胡言乱语或自相矛盾,但是却以不真正说出任何实质为代价。为了缓解这一点,作者在SSA指标上增加了第二个维度,该维度询问我们的评估人员在特定情况下响应是否特定。这样可以防止机器人隐藏在模糊的回复后面,从而使我们可以更公开地检查它们的功能。如第2.1节所述,这可以成功地区分一般响应和生动响应,同时也使众包工作者易于理解。
作者将使用SSA指标的Meena,人类和其他开放域聊天机器人与两种人类评估类型进行比较:静态和互动。
静态评估,作者选择了包含1,477个多回合会话的数据集。=
互动评估,人们可以聊天任何他们想要的东西。
作者感到惊讶但高兴的是,无论是在静态评估还是互动评估中,SSA指标都与Meena的困惑紧密相关。换句话说,Meena越适合其训练数据,其聊天响应就越敏感和具体。乍一看,这个结果看似直观,但它令我们惊讶,因为最近的研究发现,人类评估得分与BLEU等自动指标之间的关联性很差(Liu等人,2016;Lowe等人, 2017)。
作者最好的端到端学习模型的平均SSA为72%。Meena的完整版通过合并过滤机制和调谐解码而获得79%的评分(第5节)。这仍低于普通人达到的86%SSA,但比我们测试的其他聊天机器人要近得多。作者注意到人类具有很高的敏感性,但特异性却大大降低,如第4.2节所述。
作者还将讨论我们方法学的弱点。例如,静态评估数据集太局限了,无法捕获人类对话的各个方面。尽管如此,Meena取得了如此高的SSA分数,并且SSA与困惑之间存在关联,这一事实意味着,如果能够获得更好的困惑,那么从敏感性和特异性方面来说,像人类一样的聊天机器人可能就在眼前。
作者的贡献是:(1)为多回合开放域聊天机器人提出一个简单的人类评估指标,该度量可以捕获人类对话的基本但重要的属性;(2)有证据表明,困惑是与人类判断相关的自动量度,这与上述其他自动量度的最新发现形成了鲜明对比;(3)证明具有足够低的困惑度的端到端神经模型可以超越依赖多年开发的复杂、手工框架的现有聊天机器人的敏感性和特异性。

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏




