加了元学习之后,少样本学习竟然可以变得这么简单!

文 | Rukawa_Y
编 | Sheryc_王苏,小轶
去年年初 GPT-3 的论文在 arxiv 上出现,论文名为 “Language Models are Few-Shot Learners”,引起一阵轰动。除了前无古人的模型规模外,最抓人眼球的是, GPT-3 能够不需要 fine-tuning 进一步更新参数,直接解决下游任务。
这种完全依赖语言模型从预训练过程中习得的推理能力,通过上下文语境(task description)直接解决新任务的方式,叫做语境学习(in-context learning)。然而利用语境学习让模型学会处理一个新的任务的方法效果往往比不上传统的微调,预测的结果也有很大的方差,并且如何把多种多样的任务转化为语境的模版(Prompt)是很难被设计出来的。
近期,Facebook AI 实验室所发表的论文 MetalCL: Learning to learn in context ,提出了一种训练方法MetalCL,通过元学习的方式让模型更加简单有效地进行语境学习——不需要在输入中提供任务描述模板,只需提供训练样例和目标输入。论文作者希望通过在元训练任务上进行多任务学习,让模型能够自动学习到如何通过输入中的少量训练样本重构任务信息,从而省去人工设计模板的麻烦。
论文标题
MetaICL: Learning to Learn In Context
论文链接
https://arxiv.org/pdf/2110.15943.pdf
Arxiv访问慢的小伙伴也可以在 【夕小瑶的卖萌屋】订阅号后台回复关键词 【1219】 下载论文PDF~
![]() 语境学习的几种情况
语境学习的几种情况![]()
 语境学习的几种情况
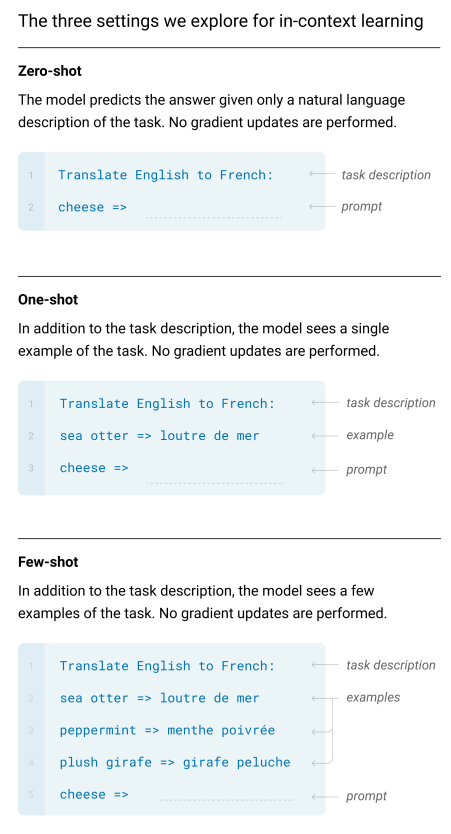
语境学习的几种情况根据GPT-3的论文,语境学习分为 3 种情形,分别是:零样本学习(Zero-shot Learning)、单样本学习(One-shot Learning)和少样本学习(Few-shot Learning)。
-
零样本学习(Zero-shot Learning):在模型输入中只提供任务描述和测试样例输入,得到测试样例输出; -
单样本学习(One-shot Learning):在模型输入中提供任务描述、一条训练样例和测试样例输入,得到测试样例输出; -
少样本学习(Few-shot Learning):在模型输入中提供任务描述、少量训练样例和测试样例输入,得到测试样例输出。
GPT-3 的论文的实验结果中,表明 GPT-3 这3种情况均取得了一定的效果,这里有不再展开了,有兴趣的同学可以看看 GPT-3 的论文。
![]() MetaICL介绍
MetaICL介绍![]()
了解了语境学习之后,相信大家都会被这种通过推理就能学习一个新的任务的,并且无需任何参数更新的学习方式所吸引。然而利用语境学习让模型学会处理一个新的任务的方法效果往往比不上传统的微调,预测的结果也有很大的方差,并且如何把多种多样的任务转化为语境的模版(Prompt)是很难被设计出来的。基于这些挑战,也就是如何让模型在语境学习中所学习到的新的任务效果更好,MetaICL应运而生了。
MetaICL,全称Meta-training for In-context Learning。其中先对模型进行元训练(Meta-training),让模型学会如何根据数据集自动调整语境学习策略,然后再进行语境学习。在Meta-training的过程中,论文的作者使用了数十个不同领域的NLP的任务作为元训练任务(Meta-training Task)对于模型进行训练,来提升模型进行少样本学习的能力。在这一训练过程中,MetaICL的优点在于不需要在输入中提供任务描述模板,只需提供训练样例和目标输入:论文作者希望通过在元训练任务上进行多任务学习的策略,让模型能够自动学习到如何通过输入中的少量训练样本重构任务信息,从而省去人工设计模板的麻烦。
MetalCL的具体的训练过程是:对于每一个元训练任务,利用K-shot Learning,将元训练任务中随机抽取出的任务中的 个样本的 和 ,和第 个样本的 连接起来作为一个输入,输入到模型中,预测对应的第 个样本的 。其中,前 个样本相当于提供了对于任务的描述信息。MetalCL推测的过程也采用了与训练过程相同的输入方式来处理预测的样本:不需要任务描述,只需将该任务的 个训练样本与目标输入相拼接即可。
总结一下MetalCL的流程如下:
-
Meta-training -
从准备好的大量的 元训练任务中,随机抽取出一个任务 ; -
从任务 中抽取出 个样例 ; -
利用模型最大化概率 ,loss损失函数为 交叉熵。 -
Interence -
对于一个meta-training中没有见过的任务,获取 个样例 和预测的输入 ; -
求 ,其中 是输出 所有可能的结果的集合。
除此之外,论文的作者还借鉴了在少样本的文本分类任务中的一种噪声通道[1]的方式,将元训练过程中的目标函数变换为 。即在噪声通道模型中,,将 定义为 ,那么目标函数则变换为最大化概率 ,即最大化概率,对应在推理阶段模型则是计算。
![]() 实验结果
实验结果![]()
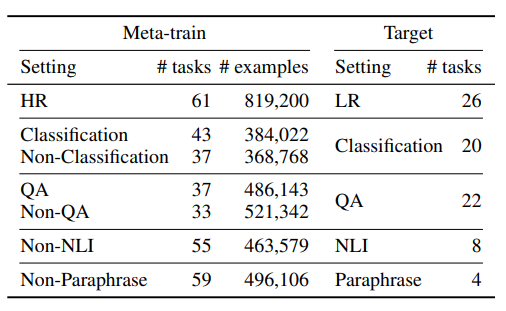
论文中作者使用GPT-2 large进行MetalCL训练,元训练过程中一共使用了142个元训练数据集,这142个数据集包含了文本分类、QA、NLI和paraphrase detection等任务。论文作者在实验过程中对于Meta-training采取了7种设置,对Target采取了5种设置,并且在Meta-training和Target所使用的任务是没有交集的,具体的设置如下:
-
HR-LR:从大数据集迁移至小数据集,在meta-training过程中使用 HR( High resource)即大于等于10000训练样本的数据集,在target的过程中使用 LR( Low resource)即小于10000的数据集。 -
Classification/QA:元训练与预测使用相似任务,在meta-training过程中使用 Classification和 QA的数据集,在target的过程中 也使用Classification和 QA的数据集。 -
NLI/Paraphrase:元训练与预测使用不相似任务,在meta-training过程中使用 Non-Classification、 Non-QA、 Non-NLI、 Non-Paraphrase的数据集,在target过程中使用 Classification、 QA、 NLI、 Paraphrase的数据集。
Meta-train和Target所采取的设置总结如下,见表格:
最终实验结果里作者将MetaICL和Channel MetalCL同其他baseline做了比较,实验结果如下:
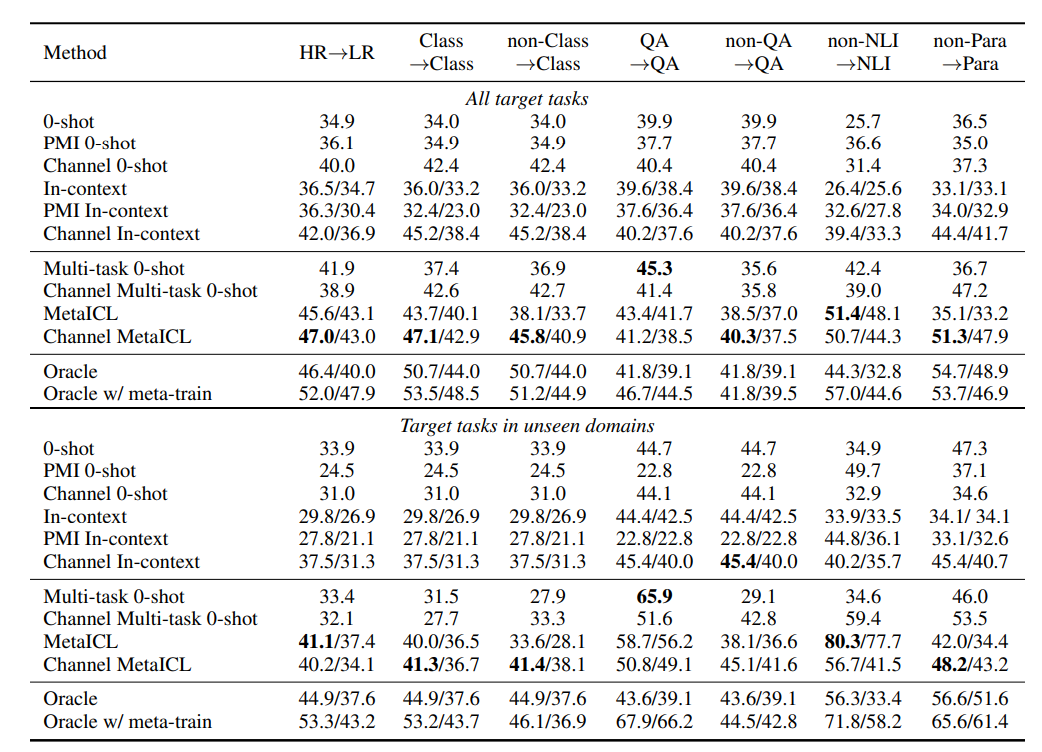
表格中各个method的意义如下:
-
0-shot:使用预训练语言模型直接做零样本推断 -
In-context:使用预训练语言模型进行few-shot的推断 -
PMI 0-shot, PMI In-context:使用 PMI[2]方式的零样本和few-shot的推断 -
Channel 0-shot,Channel In-context:使用通道模型的零样本推断和使用通道模型的few-shot推断 -
Multi-task 0-shot:使用meta-training对于预训练模型进行训练然后进行零样本推断 -
Channel Multi-task 0-shot:使用通道模型的Multi-task 0-shot -
Oracle:基于任务对于预训练模型进行fine-tuning -
Oracle w/meta-train:对预训练语言模型进行meta-training,然后再进行fine-tuning
从表格中我们可以得到如下的结论:
对于模型来说,在元训练/目标任务相似,即不进行任务迁移的情况下:
-
使用Meta-training训练模型然后进行0样本的任务学习(Multi-task 0-shot)的效果比普通的语言模型直接进行语境学习的效果更好,说明Meta-training的确是对于模型是有帮助的。 -
使用MetalCL训练的模型,不论是普通的语言模型还是Channel语言模型均取得了不错的效果,尤其是 Channel MetaICL在大部分的实验设置的情况下的效果是最好的。
在需要进行任务迁移的情况下:
-
使用MetalCL训练的模型的效果并没有收到太大的影响,并且仍然在大部分的实验设置的情况下的效果是最好的。
而将MetalCL训练的模型同Fine-tuning的模型比较时:
-
使用MetaICL的方法 有时能够取得超过直接在目标任务进行Fine-tune的方法,并且Oracle w/meta-train的结果还说明了meta-training对于Fine-tuning也有帮助。
除了上面的结论,作者还将使用MetaICL训练的GPT-2模型同GPT-J进行了比较,实验结果如下:
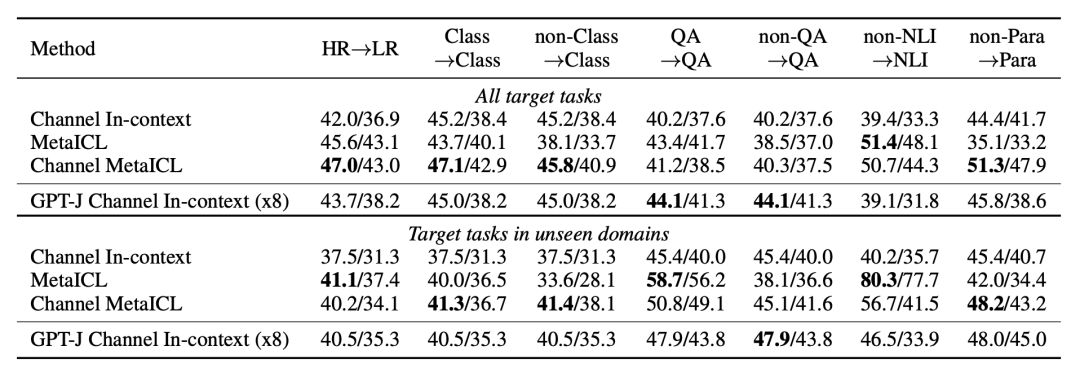
从表格中还可以看出MetalCL训练的语言模型在许多领域的模型效果基本上跟GPT-J差不多,有些领域甚至要比GPT-J好。
最后论文作者还进行了Ablation study,主要内容分为两点:
-
分析了Meta-training中 元训练任务的个数的影响:论文的作者对于HR->LR实验采取了子采样,分别从61个任务数据集中抽取了{7, 15, 30}个数据集分别进行训练,实验结果如下图所示,从图中可以看出,在不同的元训练任务数目上的实验, Channel MetaICL的效果始终是最好的;除此之外,整体上 元训练任务越多,MetaICL的性能越好。
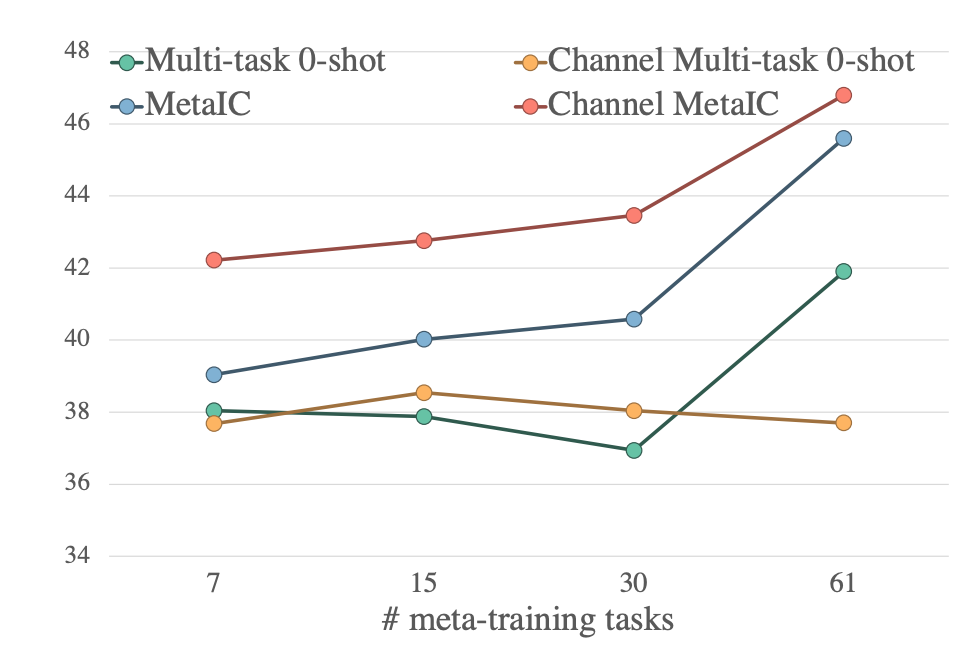
-
分析了Meta-training中 元训练任务的差异的影响:论文的作者对于HR->LR实验采取了两种设置,也就是对于61个任务数据集分别采取了两次采样,每次采样的任务数据集的个数为13,其中 一次采样的元训练任务差异性很大,任务分别有QA,NLI,关系抽取,语义分析等等, 另一次采样的元训练任务差异性较小,仅仅包含语义分析,主题分类,恶意文本检测。论文的作者在这两种设置下分别进行了实验,实验结果如下表所示。可以看出使用 差异性较大的元训练任务会带来更好的结果。
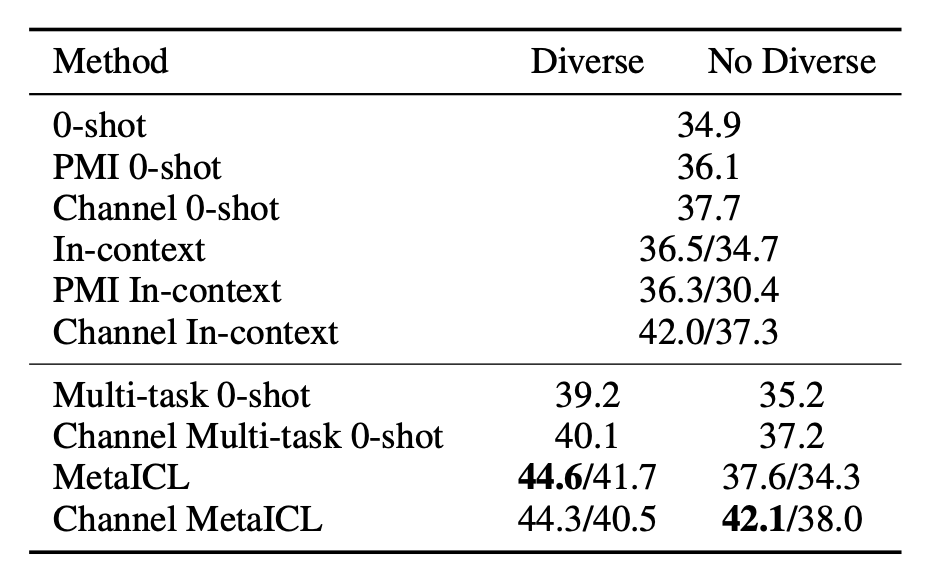
-
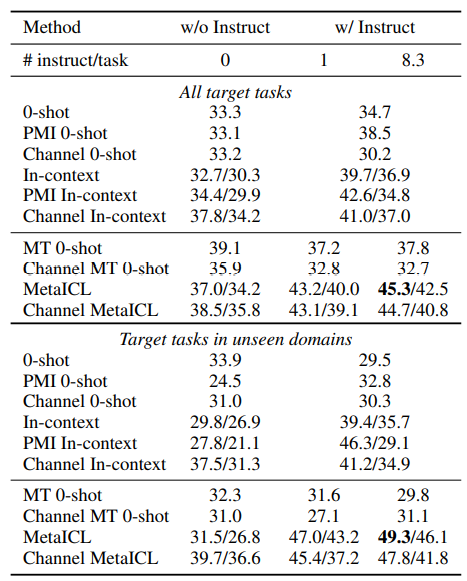
分析了 任务描述是否对于MetalCL有帮助:虽然MetaICL不需要任务描述,论文的作者依然试验了在MetaICL中使用任务描述是否会带来进一步的性能提升。作者在HR->LR实验中使用了32个meta-training任务和12个目标任务,这些任务均是提供了人工撰写的任务描述,可以看出 加入任务描述后MetaICL效果有着进一步的提升。
![]() 总结
总结![]()
本文介绍了一种MetaICL的训练方法,通过这种训练方法可以让模型通过元训练更好更简单地进行语境学习。同时笔者认为MetaICL也算是一种大力出奇迹的方法吧。这其实可以给予我们一些启发:
-
对于一个语言模型,不论要使用这个语言模型进行什么样子的任务,当让模型尽量多的见识各种各样的任务之后(这里什么任务能够对模型提升比较大也是值得继续去研究的),即使是对于没见过的任务,不论是零样本学习还是语境学习,模型均能取得不错的效果。 -
MetalCL算是一种基于 大规模语言模型的一种训练方法,对于容量较小的模型,笔者认为 MetaICL是否还能起到很好的效果也是值得去探究的。 -
论文中还提出对于一个语言模型进行了 MetalCL之后,再进行Fine-tuning,最终模型的效果是比直接对于模型进行Fine-tuning要好的。在拥有大量不同任务的数据集时,可以考虑在Fine-tuning之前先对模型进行 MetalCL训练,或许可以进一步提升模型效果。
后台回复关键词【入群】
加入卖萌屋NLP/IR/Rec与求职讨论群
后台回复关键词【顶会】
获取ACL、CIKM等各大顶会论文集!
![]()
[1] Noisy channel language model prompting for few-shot text classification.
[2] Surface form competition: Why the highest probability answer isn’t always right.
 后台回复关键词【
后台回复关键词【



