论文浅尝 | Multimodal Few-Shot Learning with Frozen Language Models

笔记整理:李磊,浙江大学硕士,研究方向为自然语言处理 链接:https://arxiv.org/abs/2106.13884
动机
大规模的自回归语言模型(如GPT)在预训练阶段学习到了大量的知识,具有很好的学习新任务的能力,给定几个“任务示例”,模型可以很快的学习到任务形式并回答新问题,但这种能力仅限于文本领域。
Prompt tuning通过添加提示信息,充分挖掘预训练语言模型蕴含的知识,在few-shot场景下取得了良好的效果。
作者提出了Frozen, 利用Visual Encoder对图片进行编码,编码得到的结果作为prompt与文本一起送入语言模型中,试图将大规模语言模型和prompt应用于多模态领域。在VQA、OKVQA、miniImageNet等多个数据集的多模态few-shot场景下进行了实验,结果表明Frozen有效的利用了预训练语言模型的先验知识,具有很好的迁移学习能力。
模型结构
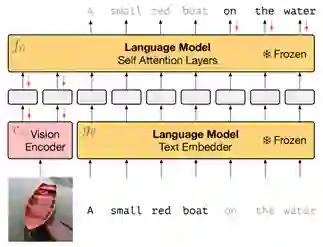
图 1模型结构图
如图1所示,模型结构主要分为两个部分:
1.预训练自回归语言模型
在公共数据集C4上预训练一个基于transformer结构的深度自回归语言模型,模型具有70亿参数。
2.视觉编码器
基于NF-ResNet-50,主要功能是将原始的图片映射为连续的序列以便transformer模型进行处理。将NF-Resnet全局池化层后的结果作为最终输出向量。受Prefix-tuning的启发,作者将视觉编码器的输出作为视觉prefix,与文本一起送入语言模型中。这种方式将静态的文本prefix转换成动态的视觉prefix,输入的图片不同,产生的视觉prefix也不同,从而更好地“提示”语言模型。
训练
如图1所示,训练时采用image-caption数据集,输入是(图片,文本)对,以生成式的方式输出对图片的描述文本信息。训练过程中冻结语言模型,仅训练视觉编码器。在k-shot场景下,需要给出几个示例,因此模型的输入可能会包含多个(图片,文本)对,作者使用相对位置编码使图文始终在对应文本之前。
实验
作者以下三个角度进行了实验:1.Rapid Task Adaptation. 2.Encyclopedic Knowledge. 3.Fast Concept Binding
1.Rapid Task Adaptation
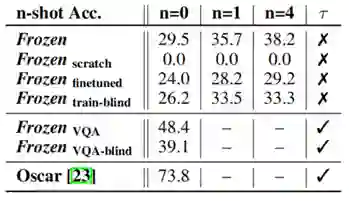
图 2 Rapid Task Adaptation结果
测试在image-caption上训练的模型在VQA数据集上的表现并设置了多个对照模型。Frozen scratch表示语言模型是随机初始化的,Frozen finetuned 表示语言模型使用预训练权重,Frozen train-blind 控制视觉编码器的输入始终是黑色图像。可以发现Frozen随着提供示例(n)的增多,效果有所提升。
2.Encyclopedic Knowledge
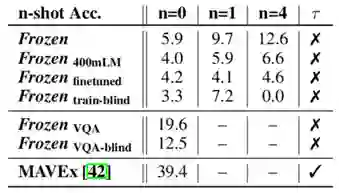
图 3 Encyclopedic Knowledge结果
此部分测试了Frozen在需要外部知识的OKVQA数据集上的表现,Frozen同样在Image-caption上进行训练。同时比较了语言模型大小对结果的影响(Frozen 400mLM)。
3.Fast Concept Binding

图 4 Fast Concept Binding输入示例
如图4所示,将blicket和dax等无实际意义的词与某一事物类别进行绑定,同时给出几个示例,测试模型是否具有概念绑定的能力。
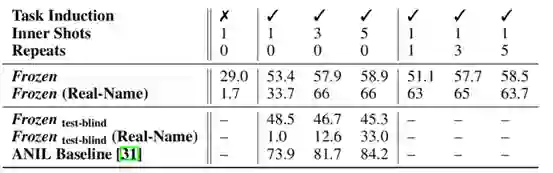
图 5 概念数等于2时的结果
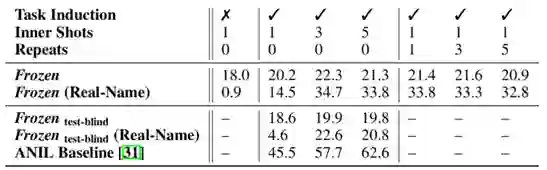
图 6 概念数等于5时的结果
作者还进一步测试了概念绑定与外部知识结合的场景下Frozen的效果。
随着任务难度增加,Frozen的效果也有所下降,但提供的示例数增加的时候,Frozen能从示例中提取到相关知识,指导结果的生成。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。



