华为 at KDD 2020 Oral,提出AutoFIS优化CTR预估中的自动特征交互

导读:今天分享一下华为在KDD 2020 Oral的一篇关于CTR预估中的自动特征交互优化工作,推荐一读。该方法简单有效,得到KDD评委的高度认可,得到3/2/2的分数,其中meta review的评价是:”Overall the paper presents a novel idea, it is well written and the evaluation is very thorough”。

论文:AutoFIS: Automatic Feature Interaction Selection in Factorization Models for Click-Through Rate Prediction
地址:https://arxiv.org/abs/2003.11235
代码:https://github.com/zhuchenxv/AutoFIS
摘要
如何学习有效的特征交互是推荐系统中点击率(CTR)预估任务至关重要。在大多数现有的深度学习推荐模型中,特征交互是手动设计或者简单枚举得到。但是,枚举所有的特征交互会占用大量的内存和计算成本。更糟糕的是,无效的特征交互会引入不必要的噪声,干扰推荐模型的训练。在本工作中,本文提出了一个两阶段的模型AutoFIS (自动特征交互选择)。
AutoFIS可以为因子分解类模型自动识别出所有重要的特征交互,而并不过多地增加训练时间。在搜索阶段,为了实现在特征交互的离散集合上进行搜索,本文引入连续型结构变量(DARTS的思想)来辅助搜索。通过对结构参数实施正则化,模型在训练过程中可以自动识别并删除无效的特征交互。在重训练阶段,将这些结构变量当做注意力机制的关注单元,以进一步提升性能。
本文在公开数据集和产品数据集上验证,AutoFIS可以显著提升因子分解类模型的精度(AUC和Logloss)。AutoFIS已部署到华为应用商店推荐服务的培训平台上,在为期10天的在线A/B测试中,AutoFIS将DeepFM模型的点击率和CVR分别提高了20.3%和20.1%。
模型框架
AutoFIS可以自动选择有效的特征交互,并且可以使用在任何因子分解模型的特征交互层当中。AutoFIS分为两个阶段:搜索阶段以及重训阶段。
搜索阶段
本文引入了门开关来控制是否选择特定的特征交互,“打开”表示选择,“关闭”表示不选择。对于二阶的特征交互组合来说,开关的总个数是 M = n * (n + 1)/ 2。如果简单粗暴的去寻找这些门的最优组合是不现实的,因为可能的选择有 2^M 种。本文从另外一个角度实现在特征交互的离散集合上进行搜索,相反地本文通过引入结构参数alpha将问题放松为连续型变量上的选择(DARTS的思想)来辅助搜索,特征交互的相对重要性便可以通过梯度下降学习得到。AutoFIS的总体框架如下图所示:
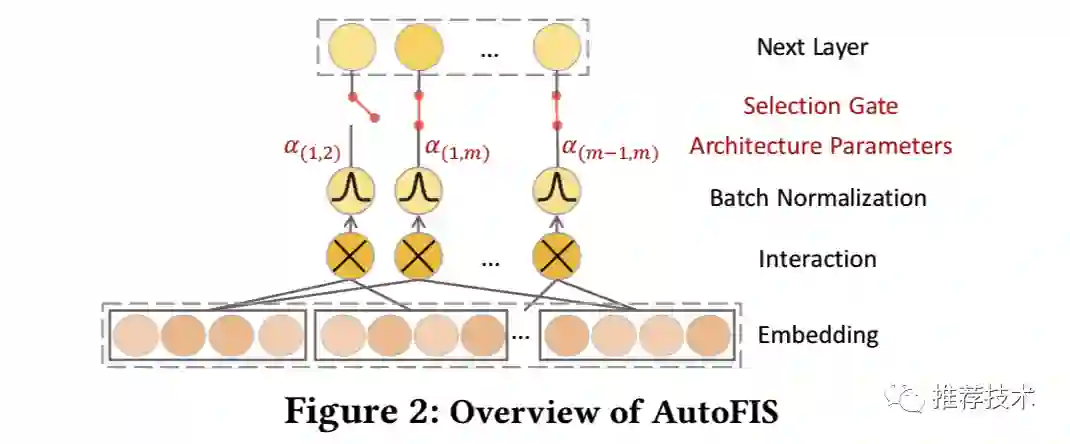
此思路从ICLR 2019的DARTS[2]中借鉴而来,目标就是从候选操作集中使用CNN结构搜索来选择一种操作。形式化来说,FM模型的特征交互层可以建模为如下的公式:

在搜索阶段,alpha学出来便代表各个特征交互对最终预测输出层的贡献;然后我们便可以根据那些不重要的特征交互的门状态设置为关闭。
Batch Normalization
从上面的公式可得,结构参数alpha和向量点击<e_i, e_j>二者是联合训练学习绑定在一起的,<e_i, e_j>的波动会导致学习alpha的时候不在同一个尺度上从而导致alpha在代表特征交互的重要性上无法可比。
为了解决这个问题,本文中在<e_i, e_j>上使用Batch Normalization来消除它的归一化问题。
GRDA Optimizer
在alpha参数的的梯度更新上,本文采取GRDA优化器[3]这样可以在alpha参数上得到一个稀疏的解。那些不重要的特征交互上对应的alpha值可以接近于0,从而自动的删掉。其他参数上的梯度更新优化上仍然使用Adam优化器。
One-level Optimaztion
在原DARTS模型中,它将alpha结构参数当做与其他神经网络参数是不同维度的参数变量。DARTS认为只有在神经网络参数学习充分的前提下才能够学习好门开关参数alpha。也就是在AutoFIS的场景下,只有当神经网络的参数充分学习的前提下我们才能决定特征交互的门开关参数alpha,这其实也就回到了2 ^ M的组合爆炸训练问题。
为了解决这个问题,DARTS提出了一个近似方案,交替迭代优化神经网络参数以及门开关参数alpha。也就是认为神经网络参数在一次梯度优化的过程中便得到了充分的学习。本文认为这个假设会影响到到模型的效果以及alpha参数的学习。因此,相比于DARTS采用two-level优化步骤,本文中则使用one-level优化步骤同时针对神经网络参数v 和门开关参数alpha同时进行迭代优化更新。

重训阶段
在通过搜索阶段针对不重要的特征交互进行删除后,本文在重训阶段针对搜索阶段alpha保留下来的特征交互进行重训得到新的模型。特别地,本文将原有的特征交互层建模为如下的公式:
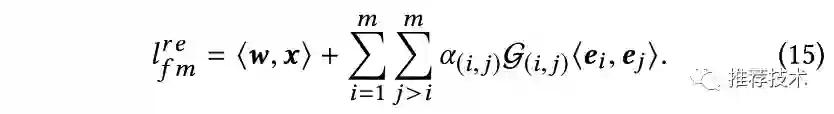
值得注意的是,上述公式中的alpha不再是与搜索阶段一样的门开关指示函数(取值为1或者0)。而是一个attention单元来学习表示特征交互的相对重要性,G(i, j)则代表指示函数。
实验部分
数据集离线实验
本文在两个公开数据集(Avazu和Criteo)和一个私有数据集上进行了实验。本文在FM和DeepFM上分别应用了AutoFIS(标记为AutoFM以及AutoDeepFM)来证明该方案的有效性,并与多种基线模型方法进行了对比。由于AutoCross方案复杂的计算性能以及代码未进行开源,因为本文中未将其纳入实验对比的baseline中。
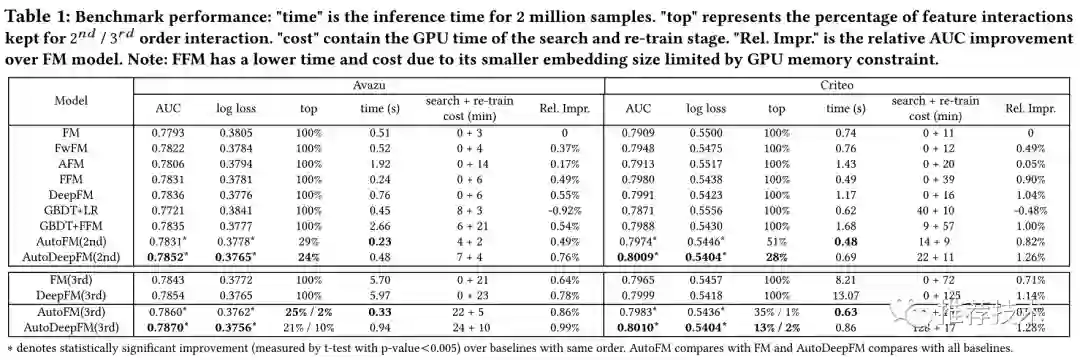
特征交互选择的空间
除了上述表格中的总体实验指标上,本文的实验中发现:
对于Avazu数据集来说,71%的FM模型、以及76%的DeepFM模型中的2阶特征交互都可以删掉。删除这部分无用的特征交互不仅可以让相应的预测精度明显提升(对于AutoFM和AutoDeepFM来说,分别0.49%和0.20%的AUC相对提升),而且可以大大节省线上模型的预测时间;
对于3阶特征交互来说,只有2%-10%的特征交互需要保留。同时删掉这部分无用的特征可以明显提升(对于AutoFM和AutoDeepFM来说,分别0.49%和0.20%的AUC相对提升,0.22%和0.20%的AUC相对提升);
值得注意的是,搜索阶段针对有效特征的识别耗时比较少。譬如AutoDeepFM在Avazu和Criteo数据集上,在单张GPU卡上分别使用了24min和128min来识别重要的2阶和3阶特征;
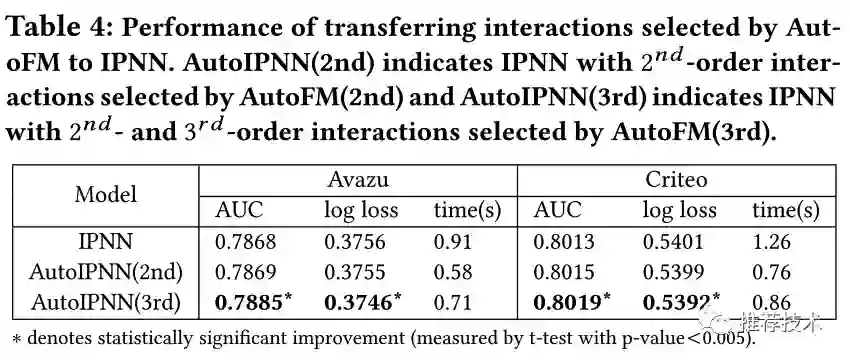
特征交互选择的可迁移性
本文继续研究了AutoFM学习选择的有效特征交互是否可以迁移给其他模型譬如IPNN来提升相应的模型性能。如下图所示,使用AutoFM中选择的2阶特征交互训练出来的AutoIPNN(2nd)可以达到与原有IPNN相近的效果;与此同时,同时使用AutoFM中选择的2阶与3阶特征交互训练出来的AutoIPNN(3rd)可以明显提升原有IPNN的模型效果。
特征交互选择的有效性
本节尝试讨论分析AutoFIS学习选择的特征交互是否是真实有效的特征交互。本文中使用statistics_AUC来表示特定交互针对最终预测输出的重要性。如下图所示,AutoFIS学习选择的大部分特征交互(绝对值大的alpha)相应的statiscs_AUC都比较高,但是并不是所有statiscs_AUC高的特征交互都会被AutoFIS选择。一个可能的解释是,这些特征交互中的信息也同时包含在其他被AutoFIS选择的特征交互中。
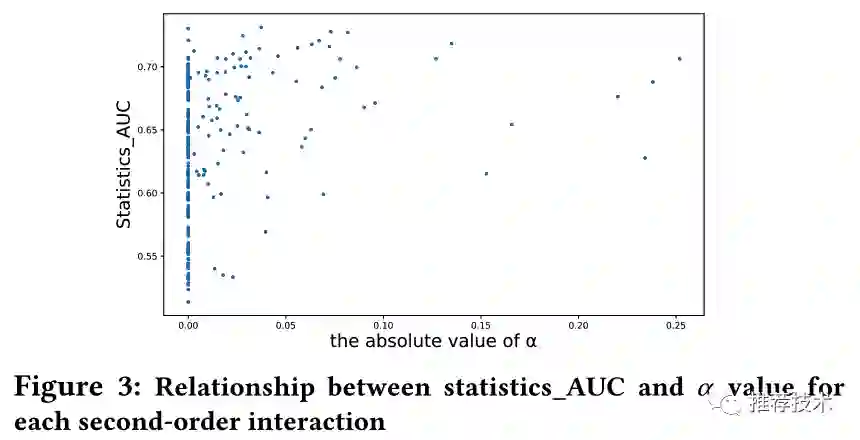
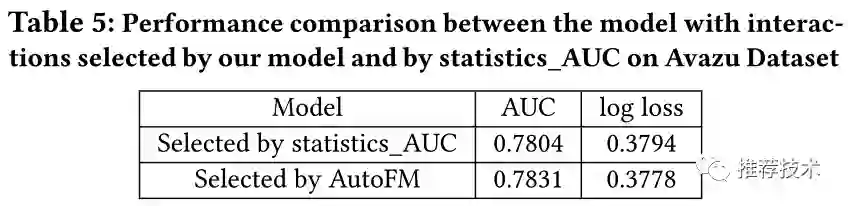
与此同时,本文也针对单纯面向statistics_AUC选择的特征交互进行训练的模型,以及AutoFIS模型对比的实验结果。如下图所示,AutoFM的效果相对要好一些。
线上实验
本文在华为应用商店的场景下使用AutoDeepFM来验证AutoFIS的有效性。

参考
1. AutoFIS: Automatic Feature Interaction Selection in Factorization Models for Click-Through Rate Prediction
2. DARTS: Differentiable Architecture Search
3. A generalization of regularized dual averaging and its dynamics
推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
太赞了!Springer面向公众开放电子书籍,附65本数学、编程、机器学习、深度学习、数据挖掘、数据科学等书籍链接及打包下载
数学之美中盛赞的 Michael Collins 教授,他的NLP课程要不要收藏?
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,点个在看吧👇
