多任务学习 | YOLOP: 全景驾驶感知,一个网络同时完成三大任务


YOLOP: You Only Look Once for Panoptic Driving Perception
全景驾驶感知系统是自动驾驶的重要组成部分,高精度、实时的感知系统可以辅助车辆在行驶中做出合理的决策。本文提出了一个全景驾驶感知网络(YOLOP)来同时执行交通目标检测、可行驶区域分割和车道检测。它由一个用于特征提取的编码器和三个用于处理特定任务的解码器组成。所提模型在具有挑战性的 BDD100K 数据集上表现非常出色,在准确性和速度方面在所有三个任务上都达到了SOTA。此外,本文通过消融研究验证了所提多任务学习模型对联合训练的有效性,应该第一个可以在嵌入式设备 Jetson TX2(23 FPS)上用一个网络实时同时处理三个视觉感知任务并保持出色精度的工作。
paper: https://arxiv.org/abs/2108.11250
code: https://github.com/hustvl/YOLOP
论文作者 | 华科王兴刚老师团队

图1 多任务模型输出结果
多任务学习的目标是通过多个任务之间的共享信息来学习更好的表示,尤其是基于CNN的多任务学习方法还可以实现网络结构的卷积共享。
Mask R-CNN 扩展了 Faster R-CNN,增加了一个预测对象掩码的分支,有效地结合了实例分割和对象检测任务,这两个任务可以相互提升性能。
MultiNet 共享一个编码器和三个独立的解码器,同时完成场景分类、目标检测和驾驶区域分割三个场景感知任务。它在这些任务上表现良好,并在 KITTI 可行驶区域分割任务上达到了最先进的水平。然而,分类任务在控制车辆方面不如车道检测那么重要。
DLT-Net 继承了编码器-解码器结构,将交通目标检测、可行驶区域分割和车道检测结合在一起,并提出上下文张量来融合解码器之间的特征图,以在任务之间共享指定信息。虽然具有竞争力的性能,但它并没有达到实时性。
张等人提出了车道区域分割和车道边界检测之间相互关联的子结构,同时提出了一种新的损失函数来将车道线限制在车道区域的外轮廓上,以便它们在几何上重叠。然而,这个先验的假设也限制了它的应用,因为它只适用于车道线紧紧包裹车道区域的场景。
更重要的是,多任务模型的训练范式也值得思考。康等人指出只有当所有这些任务确实相关时,联合训练才是合适和有益的,否则需要采用交替优化。所以 Faster R-CNN 采用实用的 4 步训练算法来学习共享特征,这种范式有时可能会有所帮助,但也乏善可陈。
本文为全景驾驶感知系统构建了一个高效的多任务网络YOLOP,包括目标检测、可行驶区域分割和车道检测任务,并且可以在部署 TensorRT 的嵌入式设备 Jetson TX2 上实现实时。通过同时处理自动驾驶中的这三个关键任务,本文方法减少了全景驾驶感知系统的推理时间,将计算成本限制在一个合理的范围内,并提高了每个任务的性能。
为了获得高精度和快速的速度,YOLOP设计了一个简单高效的网络架构。本文使用轻量级 CNN 作为编码器从图像中提取特征,然后将这些特征图馈送到三个解码器以完成各自的任务。检测解码器基于当前性能最佳的单级检测网络 YOLOv4,主要有两个原因:(1)单级检测网络比两级检测网络更快,(2) 单级检测器基于网格的预测机制与其他两个语义分割任务相关,而实例分割通常与基于区域的检测器相结合。编码器输出的特征图融合了不同级别和尺度的语义特征,分割分支可以利用这些特征图出色地完成像素级语义预测。
除了端到端的训练策略外,本文还尝试了一些交替优化范式,逐步训练模型。一方面,将不相关的任务放在不同的训练步骤中,以防止相互限制,另一方面,先训练的任务可以指导其他任务,所以这种范式有时虽然繁琐但效果很好。然而,实验表明本文所提的模型并没有这个必要,因为端到端训练的模型可以表现得足够好。最终,所设计的全景驾驶感知系统在单个 NVIDIA TITAN XP 上达到了 41 FPS,在 Jetson TX2 上达到了 23 FPS;同时,它在 BDD100K 数据集的三个任务上取得SOTA。
YOLOP主要贡献是:(1)提出了一个高效的多任务网络,可以一个网络模型同时处理自动驾驶中的三个关键任务:物体检测、可行驶区域分割和车道检测,减少推理时间的同时提高了每项任务的性能,显著节省计算成本。应该是第一个在嵌入式设备上一个模型同时跑三个任务实现实时性,同时在 BDD100K 数据集上保持SOTA的工作。(2)设计了消融实验验证了所提多任务处理方案的有效性,证明了三个任务可以联合学习,无需繁琐的交替优化。
本文提出了一个简单高效的前馈网络,可以同时完成交通目标检测、可行驶区域分割和车道检测任务。如图 2 所示,本文的全景驾驶感知单次网络 YOLOP,包含一个共享编码器和三个后续解码器来解决特定任务。不同解码器之间没有复杂和冗余的共享块,这减少了计算消耗并使网络能够轻松地进行端到端的训练。
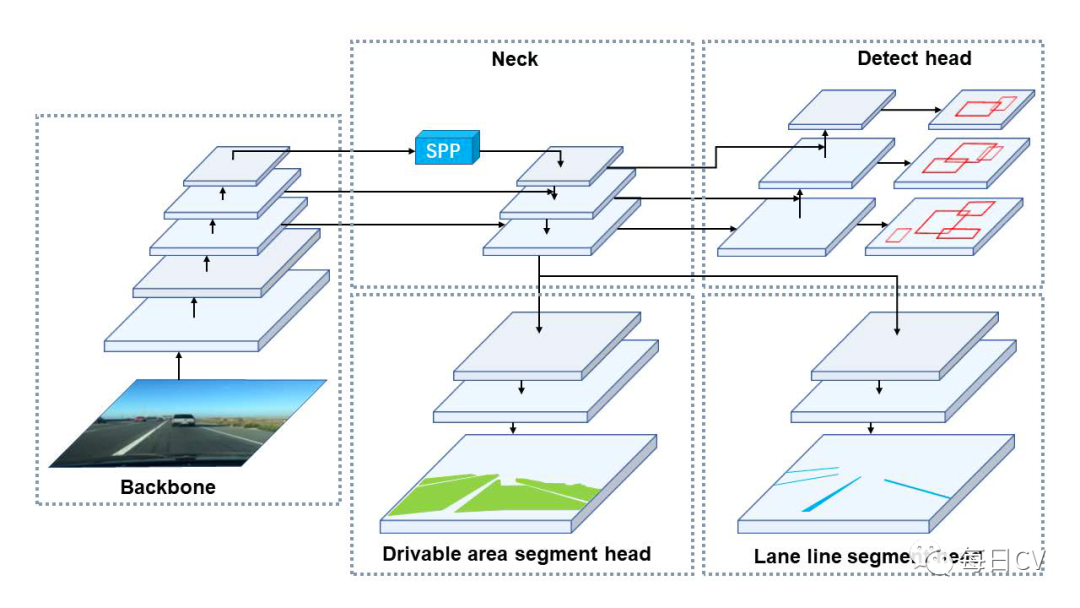
图2 YOLOP网络结构
A. 编码器
网络共享一个编码器,它由骨干网络和颈部网络组成。
1. Backbone
骨干网络用于提取输入图像的特征。通常将一些经典的图像分类网络作为主干。鉴于YOLOv4在物体检测上的优异性能,本文选择CSPDarknet 作为主干,其解决了优化 Cspnet 时梯度重复的问题。它支持特征传播和特征重用,减少了参数量和计算量,有利于保证网络的实时性。
2. Neck
Neck 用于融合 backbone 产生的特征。YOLOP 的 Neck 主要由空间金字塔池(SPP)模块和特征金字塔网络(FPN)模块组成。SPP生成并融合不同尺度的特征,FPN融合不同语义层次的特征,使得生成的特征包含多尺度、多语义层次的信息,采用串联的方法来融合这些特征。
B. 解码器
网络中的三个头是三个任务的特定解码器。
1. Detect Head
与YOLOv4类似,采用基于anchor的多尺度检测方案。首先,使用一种称为路径聚合网络(PAN)的结构,其是一种自下而上的特征金字塔网络。FPN自顶向下传递语义特征,PAN自底向上传递定位特征,将它们结合起来以获得更好的特征融合效果,直接使用PAN中的多尺度融合特征图进行检测。多尺度特征图的每个网格将被分配三个不同长宽比的先验anchor,检测头将预测位置的偏移量、尺度化的高度和宽度,以及每个类别的对应概率和预测的置信度。
2. Drivable Area Segment Head & Lane Line Segment Head
可行驶区域分割头和车道线分割头采用相同的网络结构,将 FPN 的底层馈送到分割分支,大小为 (W/8, H/8, 256)。分割分支非常简单,经过三个上采样过程,将输出特征图恢复到(W, H, 2)的大小,两个通道分别代表了输入图像中每个像素对于可行驶区域/车道线和背景的概率。由于颈部网络中共享SPP,本文没有像其他人通常所做的那样添加额外的SPP模块到分割分支,因为这不会对所提网络的性能带来任何改善。此外,上采样层使用最邻近插值方法来降低计算成本而不是反卷积。因此,模型的分割解码器不仅获得了高精度的输出,而且在推理过程中也非常快。
C. 损失函数
由于网络中有三个解码器,因此多任务损失包含三个部分。对于检测损失
其中
可行驶区域分割的损失
最终损失函数是三个部分的加权和,如公式 (4) 所示:
D. 训练范式
本文尝试了不同的范式来训练模型。最简单的一种是端到端的训练,可以联合学习三个任务。当所有任务确实相关时,这种训练范式很有用。

算法1 一种逐步训练多任务模型的方法
A. 设置
1. 数据集设置
BDD100K 数据集支持自动驾驶领域多任务学习的研究,拥有 10 万帧图片和 10 个任务的注释,是最大的驾驶视频数据集。由于数据集具有地理、环境和天气的多样性,在 BDD100K 数据集上训练的算法足够健壮,可以迁移到新环境,因此用 BDD100K 数据集来训练和评估网络是很好的选择。 BDD100K 数据集分为三部分,70K 图像的训练集,10K 图像的验证集,20K 图像的测试集。由于测试集的标签不是公开的,所以在验证集上进行模型评估。
2. 实现细节
为了提高模型的性能,根据经验采用了一些实用的技术和数据增强方法。
为了使检测器能够获得更多交通场景中物体的先验知识,使用 k-means 聚类算法从数据集的所有检测帧中获取先验锚点。使用 Adam 作为优化器来训练模型,初始学习率、β1 和 β2 分别设置为 0.001、0.937 和 0.999。在训练过程中使用预热(Warm-up)和余弦退火来调整学习率,旨在引导模型更快更好地收敛。
使用数据增强来增加图像的变化,使模型在不同环境中具有鲁棒性。训练方案中考虑了光度失真和几何畸变,调整图像的色调(hue)、饱和度(saturation)和像素值进行光度失真,使用随机旋转、缩放、平移、剪切和左右翻转进行几何畸变。
3. 实验设置
实验中选择了一些优秀的多任务网络和专注于单个任务的网络与本文所提网络进行比较。
MultiNet 和 DLT-Net 都同时处理多个全景驾驶感知任务,并且在 BDD100K 数据集上的目标检测和可行驶区域分割任务中取得了很好的性能,Faster-RCNN 是两阶段目标检测网络的杰出代表,YOLOv5 是在 COCO 数据集上实现最先进性能的单级网络,PSPNet凭借其超强的聚合全局信息能力在语义分割任务上取得了出色的表现。通过在 BDD100k 数据集上重新训练上述网络,与本文在目标检测和可行驶区域分割任务上的网络进行比较。
由于在 BDD100K 数据集上没有合适的现有多任务网络处理车道检测任务,本文将所提网络与 Enet、SCNN 和 Enet-SAD 这三个先进的车道检测网络进行了比较。
另外,将联合训练范式的性能与多种交替训练范式进行了比较,将经过训练以处理多项任务的多任务模型的准确性和速度与经过训练以执行特定任务的模型进行比较。实验中将BDD100K 数据集中的图像从 1280×720×3 调整为 640×384×3,所有对照实验都遵循相同的实验设置和评估指标,均在 NVIDIA GTX TITAN XP 上运行。
B. 结果
通过简单的端到端训练YOLOP,将其与所有三个任务的其他代表性模型进行比较。
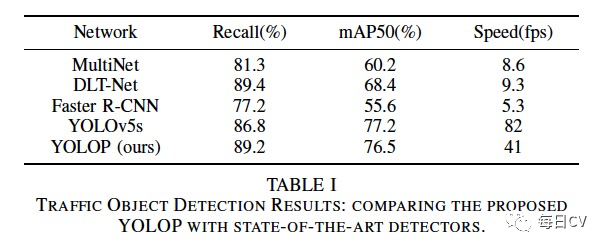
1. 交通目标检测结果
由于 Multinet 和 DLT-Net 只能检测车辆,我们只考虑BDD100K数据集上5个模型的车辆检测结果。如表 I 所示,使用 Recall 和 mAP50 作为检测精度的评估指标。YOLOP在检测精度上超过了 Faster RCNN、MultiNet 和 DLT-Net,并且可以与实际上使用更多技巧的 YOLOv5s 相媲美。速度上模型可以实时推断,YOLOv5s 更快是因为它没有车道线头和可行驶区域头。交通目标检测的可视化如图 3 所示。

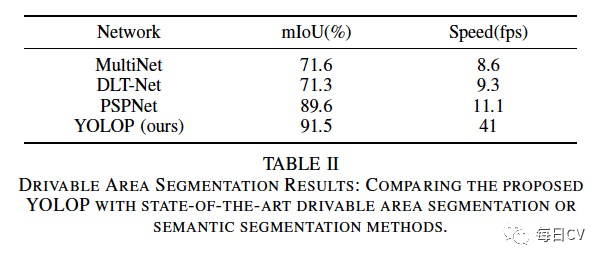
2. 可行驶区域分割结果
本文将 BDD100K 数据集中的“区域/可行驶”和“区域/替代”类都归为“可行驶区域”,模型只需要区分图像中的可行驶区域和背景。mIoU 用于评估不同模型的分割性能。从结果表II可以看出,YOLOP 分别优于 MultiNet、DLT-Net 和 PSPNet 19.9%、20.2% 和 1.9%,而且推理速度快 4 到 5 倍。可行驶区域分割的可视化结果如图 4 所示。

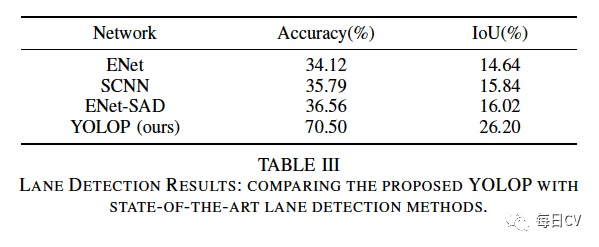
3. 车道检测结果
BDD100K 数据集中的车道线用两条线标注,所以直接使用标注非常棘手。实验遵循侯等人的设置以便进行比较,首先根据两条标线计算中心线,然后将训练集中的车道线宽度设置为8个像素,同时保持测试集的车道线宽度为2个像素,使用像素精度和车道的 IoU 作为评估指标。如表 III 所示,YOLOP的性能大幅超过了其他三个模型。车道检测的可视化结果如图5所示。

C. 消融研究
本文设计了以下两个消融实验来进一步说明所提方案的有效性。
1. End-to-end vs Step-by-step
表 IV 比较了联合训练范式与多种交替训练范式的性能。可以看出YOLOP通过端到端的训练已经表现得非常好,已经不再需要进行交替优化。有趣的是,端到端范式训练检测任务首先似乎表现更好,这可能主要是因为整个模型更接近一个完整的检测模型,并且模型在执行检测任务时更难收敛(更难的任务用更适配的模型能达到更好的效果)。另外,由三步组成的范式略胜于两步,类似的交替训练可以运行更多的步骤,但改进已可以忽略不计。
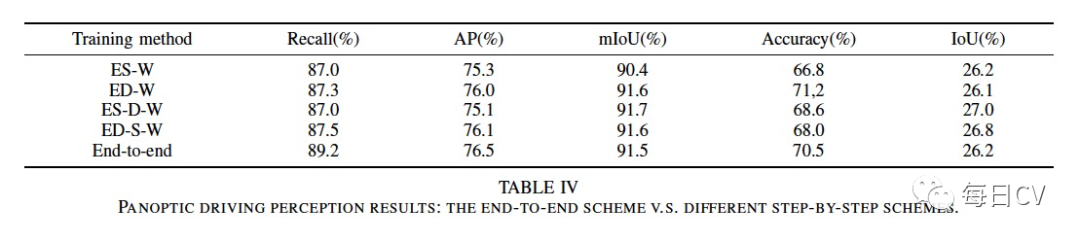
注:E, D, S 和 W 分别表示Encoder, Detect head, two Segment heads and whole network。比如 ED-S-W 表示先只训练 Encoder and Detect head,然后冻结 Encoder and Detect head训练two Segmentation heads,最后联合三个任务训练whole network。
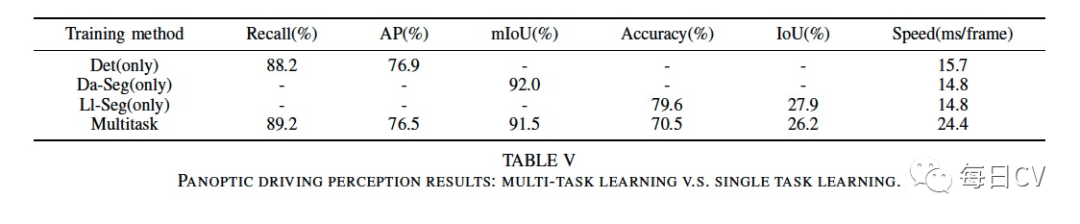
2. Multi-task vs Single task
为了验证多任务学习方案的有效性,对多任务方案和单任务方案的性能进行了比较。表 V 显示了这两种方案在每个特定任务上的性能比较,可以看出采用多任务方案训练的模型性能接近于专注单个任务的性能,更重要的是,与单独执行每个任务相比,多任务模型可以节省大量时间。
本文提出了一个简单高效的多任务网络YOLOP,它可以同时处理物体检测、可行驶区域分割和车道线检测三个典型的驾驶感知任务,并且可以进行端到端的训练。训练出的模型在具有挑战性的 BDD100k 数据集上表现异常出色,在所有三个任务上都达到或大大超过了最先进的水平,并且可以在嵌入式设备Jetson TX2上进行实时推理,使得模型可以在真实场景中使用。
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“CVPR21检测”获取CVPR2021目标检测论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~


