一种轻量级在线多目标车辆跟踪方法
极市平台(ExtremeMart)是深圳极视角旗下的专业视觉算法开发与分发平台,为开发者提供行业场景集,每月上百真实项目需求,算法分发,技术共享等,旨在联合开发者建立起良好的计算机视觉生态。已与上百名开发者建立了合作并转化了上百种视觉算法。
为加速广大开发者视觉算法的转化及变现,极市开启了有奖视觉demo征集活动,通过测试的优秀demo提交者将会得到丰厚奖励和更多合作机会,点击了解详情。
摘要:本文提出了一种基于最小成本线性成本分配的亲和匹配多目标车辆跟踪系统。该跟踪系统的目标是从安装在移动的自我车辆上的摄像机获取的场景记录。与其他低速跟踪应用(例如传统的行人跟踪)相比,在道路场景上的车辆跟踪和从移动的自我车辆的相机获取的图像放大了更大的边界框几何形状变化的问题。这种扰动发生在许多跟踪场景中,例如当高速物体从相对的车道接近时。由于自动驾驶算法需要以有效的方式使用处理资源,即使在满足计算复杂任务(如定位,对象检测,占用网格更新,传感器融合和轨迹规划)的要求时,我们的研究特别集中在开发计算轻量级的在线多物体跟踪模型和基准测试上。为了测试和评估我们的模型,我们使用KITTI对象跟踪 - 汽车基准数据集,我们的模型统计指标值相对较高; 我们的模型优于ML和MT的最先进方法,在MOTA和MOTP度量评估方面排名第二,与其他方法相比,处理时间快6到20倍。
作者:G¨ultekin G¨und¨uz1 and TankutAcarman2
I.介绍
多目标跟踪及其对周围动态交通场景的预测能力在自主驾驶中起着至关重要的作用,比如轨道规划和决策制定等安全关键任务[1],[2]。卷积神经网络( CNN )在运行时间和检测精度方面的性能增强创造了“检测跟踪”范例[ 3 ]–[ 5 ]。提供更高精度和更低数量的假阴性的网络需要嵌入更多的复杂性,需要调整大量的参数和更多的处理要求[ 6 ]。
鉴于自动驾驶[7],[8]中使用的定位,目标检测、传感器融合、占用网格更新、轨迹规划、动态建模和控制等任务,广泛使用都需要计算效率高且准确的解决方案。无论是使用激光雷达点云、立体对像、单相机图像传感器,还是采用在线或批量处理方法,多目标跟踪器都会被划分。我们提出了一种轻量级在线多目标车辆跟踪方法“extraCK”,它是一种依赖于单个摄像头的在线“检测跟踪”多目标车辆跟踪器。
II.相关工作
在线多目标跟踪(MOT)已被广泛研究。由于噪声检测,与先前跟踪的对象的关联是一项具有挑战性的任务。马尔可夫决策过程(MDP)已被采用,例如“出生/死亡”和目标的“出现/消失”被视为MDP中的状态转换[9]。在[10]中研究了MOT的最低成本流量优化,并且学习了“检测”,“生死”和“检测之间的过渡”边缘的成本。使用贪婪算法和线性规划提取具有二次交互的最优轨迹集。在[11]中使用长短期记忆(LSTM)模型对外观、运动和交互特征进行编码和组合,在行人跟踪方面获得了有希望的结果。引入了单个基于CNN的对象跟踪器,发现了每个目标的特定CNN分支,在线和提取的特征与目标运动模型相结合[12]。四核CNN已经在[13]中使用,跨帧的跟踪分配是根据四倍损失完成的。对检测到的物体进行网格划分,并根据它们的位置、外观相似性、目标动力学和轨迹正则化对局部流描述符进行分类,并将模型表述为所有假设集的能量最小化框架。在[14]中已经研究了物体和变化点的检测,通过以下[15]检测并将点轨迹定义为图形模型,并且解决了成对电位的最小成本多切问题。
已经研究了目标特定的相似度函数,对于时间局部窗口对象,在线学习了外观相似度函数,并且在[16]中解决了最小成本的多商品流问题。在[17]中已经提出了利用网络流优化来跟踪基于在线目标的外观和运动线索。[ 18 ]关注从安装在移动车辆上的摄像机获取的复杂场景,这也是我们的方法遵循的类似目标。将由对象之间的位置和速度差描述的结构运动约束与检测锚进行比较,并给出具有最小成本的分配。
III.方法
A.亲和特征
对于每个检测到的对象,可以提取各种特征用于亲和度测量,例如包含边界框坐标,宽度,高度的几何特征,取决于立体图像的可用性的视差度量,以及其他检测到的对象的遮挡百分比。基于外观的功能包括检查颜色直方图或关键点描述符[19]。准确测量两个连续帧的检测对象之间的成对亲和度是多对象跟踪的关键挑战。由于移动视觉平台,可以看到大量的运动场景,比如自我车辆合并右转道路,车辆穿过对面车道。
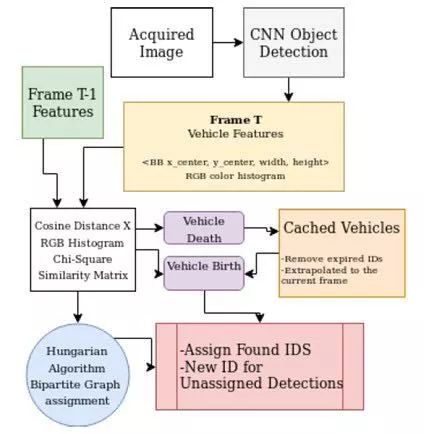
图1 :跟踪器模型的流程图。CNN处理获取的图像以进行对象检测。对于每个检测特征向量和RGB颜色直方图与前一帧进行比较。根据其亲和度测量来分配对象IDS。
在这些情况下,如果特征向量之间的给定距离足够大,则分配新的ID,否则在拥挤情况下分配的ID之间的切换次数会增加。总的来说,选择用于亲和力测量的广义信息特征集是一项具有挑战性的任务。
根据跟踪场景和情况,特定的问题可能会因不同的特性而发生。关键点描述符可用于被遮挡的对象,或者它们可以位于远离小的边界框区域内。使用距离信息看起来很直观,但是当可以发生由环境部分遮挡的检测到的对象时,可能存在如图2中突出显示的一些特定情况。在图2中,第一行给出了来自左摄像机图像的帧,第二行绘制了跟随[ 20 ]的视差图估计。在图2中,第一行给出了来自左摄像机图像的帧,第二行绘制了跟随[ 20 ]的视差图估计。即使对于低遮挡率,由于已经最小和最大差异度量没有给出任何有用的知识,因此平均差异度量表现出不一致性。需要先进的处理方法,如遮挡姿势估计[21],遮挡分类器[22]或直方图比较。被检测对象的外观被显示为信息丰富,RGB通道直方图通常被入库到任意数量的库[ 23 ]。即使对于低数量的区间,如果将三个通道的值添加到特征向量,则吸收边界框位置,也需要加权距离计算和权重参数的学习。
最后,如果使用一个物体与其他被检测物体的遮挡比率,当遮挡另一个物体的最近物体消失时,这两个物体之间会交换值。特征向量Fi由其边界框的特定值定义如下:
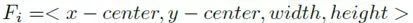
其中宽度和高度相关特征根据所获取帧的大小在0和1的范围之间归一化。另外,由Hi表示的i-th边界框补丁的三维RGB直方图用每个通道的6个区间提取。RGB直方图被归一化并平面化成一维,结果长度为216。
B.跟踪器模型
使用Faster R-CNN([3])检测获取图像中的对象,其中300个区域提议和锚步长为8个像素,骨干卷积网络是在ImageNet上预训练的预训练的Inception-Resnet-V2模型[24] 使用KITTI 2D物体检测数据集[4],[5]对数据集进行微调。对于每个检测到的对象,由Fi表示的亲和度特征被提取,并且对于帧 t> 1,成对的特征余弦距离矩阵Di*j被导出如下:
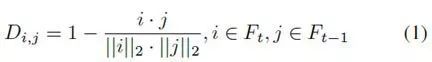
还使用卡方距离比较直方图,其中Si*j表示RGB颜色直方图的卡方距离矩阵。同样,对于t> 1,两个直方图的卡方距离由下式给出:
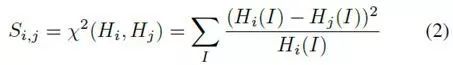
当分配成对特征距离和直方图相似度时,亲和力成本矩阵Ci*j通过以下公式计算:

一旦建立了成本矩阵,就提取行和列的最小值,以便确定先前跟踪的对象是否消失或者出现了新的对象。在这种情况下,计算亲和力成本大于确定的阈值,缓存消失的车辆,然后交叉检查新对象并与高速缓存的对象进行比较。图3从上到下分别显示了特征距离矩阵、方形直方图距离和成本矩阵。消失的车辆列和新出现的行都从成本矩阵中移除。
存在于成本矩阵中的剩余车辆被分配求解线性和分配问题,匈牙利算法引入的二分图的最小权重匹配[25]。如果X是布尔矩阵并且X(i; j)= 1当且仅当行i被分配给列j时,通过求解来确定最佳赋值:
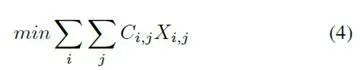
对命令min(i; j)的方阵进行分配,因此如果对象未被分配给任何先前的检测或者未被确定类似于高速缓存的对象,则分配新的轨迹。

图2:顶行示出了用于KITTI对象跟踪训练序列0001,帧160到164的检测到的车辆和底行立体视差图。由边界框标记的区域的平均差异值以黄色显示。即使低的遮挡率也会导致检测到的对象的平均差异度量在序列中波动,并且不提供稳定的亲和力特征。
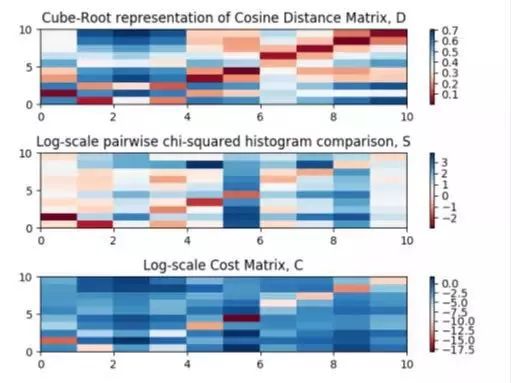
图3:特征余弦距离矩阵,卡方RGB颜色直方图相似度和成本矩阵分别从上到下表示。行索引表示对帧t处的对象的检测,列对前一帧的对象进行索引,t-1。
C.后帧处理
当完成当前帧的轨迹分配时,预测下一帧的高速缓存和活动车辆特征。此任务有三个目的:调整成本矩阵,识别先前跟踪的对象已消失但在下面的帧中重新出现,以及调整近处物体的边界框行为,这些行为也可能以高速移动。通过应用最小二乘法在时间索引t处拟合线,在时间索引t + 1处为帧预测对象特征。对于活动或缓存的所有对象,如果已经为高于给定阈值的帧数提供了数据,则提取每个特征的t + 1处的拟合值。外推特征值被观察到的特征值替换,并用于下一帧中的特征向量距离比较。
在图5中,被跟踪物体相对于自我车辆从相反方向接近。由于摄像机和检测到的物体之间的相对高速度,边界框特征显示出相当大的变化。如果亲和力模型接受这种相当大的特征距离,则在拥挤的跟踪场景中预测性能会显着降低。但是,将特征向量外推到下一帧可以深入了解下一个可能的边界框以及车辆是否仅部分可见。如果在帧限制之外外推边界框,则排除期望在框架外的部分。放置在图5左下方的框架示出了框架97处的检测的边界框与框架97的预测边界框和框架96中观察到的边界框之间的余弦距离。
由于CNN的遮挡或假阴性,也无法观察到先前跟踪的车辆。图4示出了说明性示例。CNN在帧73处最后检测到相同的车辆,其被绘制在第一行的最右边,并且直到帧78被重新检测,被绘制在第二行的最左边。在此消失期间,外推缓存的车辆特征以最小化再现时的特征距离。

图4:KITTI对象跟踪测试序列0007,帧73到78。右上方的图像显示了车辆的最后一次检测,其中红色水平和垂直线代表边界框坐标。对于框架74-77,紫色边界框是同一车辆的预测运动。最左边的数字,第78帧显示了检测到同一车辆时的边界框。
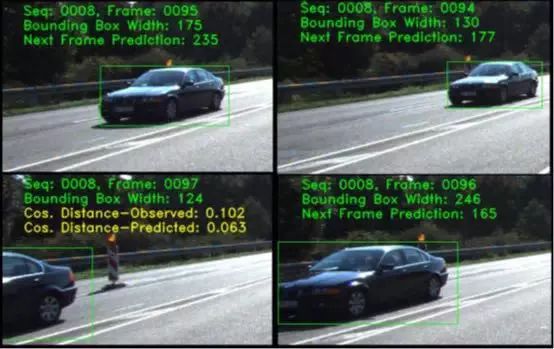
图5:属于跟踪训练序列0008的编号为94到97的帧序列表示连续帧之间的相当大的边界框大小变化。对于亲和力匹配,预期部分可见的被跟踪对象的边界框被调整。
IV.评估
出于评估目的,使用[2]中的KITTI对象跟踪评估2012数据集,仅考虑“汽车”类。训练数据集由21个具有8.008帧的序列组成,测试数据集由29个序列和11.095帧组成。从安装在自我车辆上的摄像机以10FPS记录帧。所有序列都具有不同数量的对象和长度及其独特的运动场景。在我们的评估研究中,采用以下指标:CLEAR MOT [26]以及Fragmentation(FRAG),ID-switch(IDS),Mostly-Tracked(MT)和Mostly-Lost(ML),它们在[27]中定义。
表I给出了我们方法“extraCK”的召回率、精确度、F - measure、虚警率( FAR )和真阳性( TP )、假阳性( FP )、假阴性( FN )、虚警率( FAR )的统计度量值。这些度量值是跟踪器的目标检测部分的结果。表II显示了多目标跟踪相关的统计度量值,即多目标跟踪精度(MOTP)说明了跟踪器估计精确对象位置的能力,多目标跟踪精度(MOTA)是FN总和的比值,FP 和总计帧数相对于地面实况对象总数计算的不匹配,[26]。
MT定义为覆盖超过80%的地面实际轨迹的输出轨迹的百分比,ML是覆盖不到20%的地面实际轨迹的输出轨迹的百分比,IDS是跟踪轨迹变化的次数和FRAG定义地面实况轨迹被中断的次数。我们的方法的性能与根据KITTI跟踪基准测试的最新方法进行了比较(例如,参见[ 2 ),列表基准目标跟踪评估方法相对于不同的度量值可在
http://www.cvlibs.net/datasets/kitti/eval_tracking.php.获得。
在撰写本论文时,我们的模型在MOTA指标上排名第二,因为与性能更好的方法相比,它具有更高的FN度量值和IDS值,参见表II中的七种方法。定位跟踪对象(即MOTP值)的性能再次排名第二,并且相对接近第一排名方法。根据MT统计度量值以及ML统计度量值,为了捕获大部分跟踪,我们的方法“extraCK”优于其他最先进的方法。我们的方法的基准测试性能被可视化,并与图6中最先进的方法进行比较。
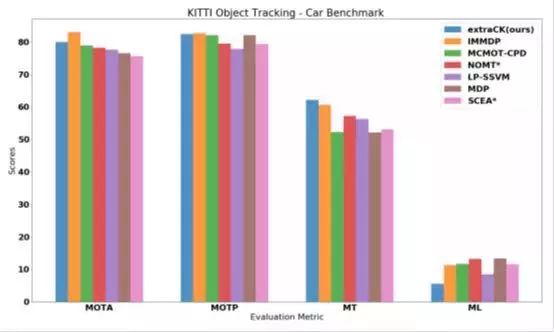
图6:“Car”类多目标跟踪精度(MOTA),多目标跟踪精度(MOTP),主要跟踪(MT)和大部分丢失(MT)度量与KITTI对象跟踪基准中的其他已发布方法的比较。
具有亲和力成本矩阵的跟踪分配的计算复杂性取决于当前和先前检测的最小数量,详细分析在[25],[28]中给出。鉴于在英特尔i7 - 6820HK上以2.70 GHz CPU测试包含检测对象的帧时的运行时性能,我们的跟踪器模型的平均运行时间为0.0295秒或34 fps,标准偏差为0.01228秒。运行时直方图和概率分布如图7所示。
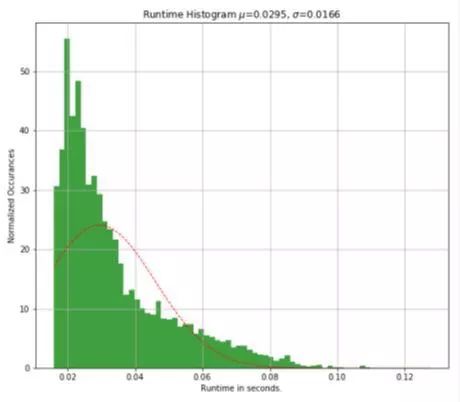
图7 :运行时间直方图和概率分布图,由当前和先前检测到的物体数量的最小值决定。模型在KITTI物体跟踪序列上的平均频率≈34Hz。
V. 结论
本文提出了一种轻量级在线多目标车辆跟踪方法“extraCK”,该方法解决了结合外观特征的外推运动最小成本线性和分配问题。鉴于ML度量,我们的extraCK方法优于最先进的方法,同时我们的方法在MOTA、MOTP和MT测试的前三个度量结果中以KITTI对象跟踪基准的“Car”级为基准。运行时性能(0.03秒)将进行测试和交叉检查。与其他方法相比,速度提高了6到20倍,实现了自动驾驶的计算“轻量级”多车辆跟踪。所实现的运行时性能使得能够根据具有挑战性的跟踪场景中的周围车辆的运动来进行轨迹规划。沿着可接受的跟踪度量值水平的运行时性能使得自动驾驶车辆的计算资源能够被其他时间关键任务使用。
VI.致谢
作者非常感谢加拉塔萨雷大学的支持,授权#17.401.003下的科学研究支持计划。
REFERENCES
[1] A. Petrovskaya and S. Thrun, “Modelbased vehicle detection andtracking for autonomous urban driving,” AutonomousRobots, vol. 26,no. 2-3, pp. 123–139, 2009.
[2] A. Geiger, P. Lenz, and R. Urtasun,“Are we ready for autonomous driving? the kitti vision benchmark suite,” inComputer Vision and Pattern Recognition (CVPR), 2012 IEEE Conference on, pp.3354–3361, IEEE, 2012.
[3] S. Ren, K. He, R. Girshick, and J. Sun,“Faster r-cnn: Towards realtime object detection with region proposalnetworks,” in Advances in neural information processing systems, pp. 91–99,2015.
[4] K. He, X. Zhang, S. Ren, and J. Sun, “Deepresidual learning for image recognition,” in Proceedings of the IEEE conferenceon computer vision and pattern recognition, pp. 770–778, 2016.
[5] C. Szegedy, V. Vanhoucke, S. Ioffe, J.Shlens, and Z. Wojna, “Rethinking the inception architecture for computervision,” in Proceedings of the IEEE Conference on Computer Vision and PatternRecognition, pp. 2818–2826, 2016.
[6] J. Huang, V. Rathod, C. Sun, M. Zhu, A.Korattikara, A. Fathi, I. Fischer, Z. Wojna, Y. Song, S. Guadarrama, et al.,“Speed/accuracy trade-offs for modern convolutional object detectors,” arXivpreprint arXiv:1611.10012, 2016.
[7] C. Urmson, J. Anhalt, D. Bagnell, C.Baker, R. Bittner, M. Clark, J. Dolan, D. Duggins, T. Galatali, C. Geyer, etal., “Autonomous driving in urban environments: Boss and the urban challenge,”Journal of Field Robotics, vol. 25, no. 8, pp. 425–466, 2008.
[8] J. Levinson, J. Askeland, J. Becker, J.Dolson, D. Held, S. Kammel, J. Z. Kolter, D. Langer, O. Pink, V. Pratt, et al.,“Towards fully autonomous driving: Systems and algorithms,” in IntelligentVehicles Symposium (IV), 2011 IEEE, pp. 163–168, IEEE, 2011.
[9] Y. Xiang, A. Alahi, and S. Savarese,“Learning to track: Online multiobject tracking by decision making,” inProceedings of the IEEE International Conference on Computer Vision, pp.4705–4713, 2015.
[10] S. Wang and C. C. Fowlkes, “Learningoptimal parameters for multitarget tracking with contextual interactions,”International Journal of Computer Vision, vol. 122, no. 3, pp. 484–501, 2017.
[11] A. Sadeghian, A. Alahi, and S. Savarese,“Tracking the untrackable: Learning to track multiple cues with long-termdependencies,” arXiv preprint arXiv:1701.01909, 2017.
[12] Q. Chu, W. Ouyang, H. Li, X. Wang, B.Liu, and N. Yu, “Online multiobject tracking using cnn-based single objecttracker with spatialtemporal attention mechanism,” arXiv preprintarXiv:1708.02843, 2017.
[13] J. Son, M. Baek, M. Cho, and B. Han,“Multi-object tracking with quadruplet convolutional neural networks,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition,pp. 5620– 5629, 2017.
[14] B. Lee, E. Erdenee, S. Jin, M. Y. Nam,Y. G. Jung, and P. K. Rhee, “Multi-class multi-object tracking using changing point detection,”in European Conference on Computer Vision, pp. 68–83, Springer, 2016.
[15] M. Keuper, S. Tang, Y. Zhongjie, B. Andres,T. Brox, and B. Schiele, “A multi-cut formulation for joint segmentation and tracking of multipleobjects,” arXiv preprint arXiv:1607.06317, 2016.
[16] M. Yang, Y. Wu, and Y. Jia, “A hybriddata association framework for robust online multi-object tracking,” arXivpreprint arXiv:1703.10764, 2017.
[17] B. Wang, G. Wang, K. L. Chan, and L.Wang, “Tracklet association by online target-specific metric learning andcoherent dynamics estimation,” IEEE transactions on pattern analysis andmachine intelligence, vol. 39, no. 3, pp. 589–602, 2017.
[18] J. Hong Yoon, C.-R. Lee, M.-H. Yang,and K.-J. Yoon, “Online multi-object tracking via structural constraint eventaggregation,” in Proceedings of the IEEE Conference on Computer Vision andPattern Recognition, pp. 1392–1400, 2016.
[19] W. Choi, “Near-online multi-targettracking with aggregated local flow descriptor,” in Proceedings of the IEEEInternational Conference on Computer Vision, pp. 3029–3037, 2015.
[20] N. Mayer, E. Ilg, P. H¨ausser, P.Fischer, D. Cremers, A. Dosovitskiy, and T. Brox, “A large dataset to trainconvolutional networks for disparity, optical flow, and scene flow estimation,”in IEEE International Conference on Computer Vision and Pattern Recognition(CVPR),
2016. arXiv:1512.02134.
[21] C.Wang, Y. Fang, H. Zhao, C. Guo, S. Mita,and H. Zha, “Probabilistic inference for occluded and multiview on-road vehicledetection,” IEEE Transactions on Intelligent Transportation Systems, vol. 17,no. 1, pp. 215–229, 2016.
[22] M. Mathias, R. Benenson, R. Timofte,and L. Van Gool, “Handling occlusions with franken-classifiers,” in Proceedingsof the IEEE International Conference on Computer Vision, pp. 1505–1512, 2013.
[23] K. Meshgi and S. Ishii, “Expanding histogramof colors with gridding to improve tracking accuracy,” in Machine VisionApplications (MVA), 2015 14th IAPR International Conference on, pp. 475–479,IEEE, 2015.
[24] J. Deng, W. Dong, R. Socher, L.-J. Li,K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in Computer Visionand Pattern Recognition, 2009. CVPR 2009. IEEE Conference
on, pp. 248–255, IEEE, 2009.
[25] H. W. Kuhn, “The hungarian method forthe assignment problem,” Naval Research Logistics (NRL), vol. 2, no. 1-2, pp.83–97, 1955.
[26] K. Bernardin and R. Stiefelhagen,“Evaluating multiple object tracking performance: the clear mot metrics,”EURASIP Journal on Image and Video Processing, vol. 2008, no. 1, p. 246309,2008.
[27] Y. Li, C. Huang, and R. Nevatia,“Learning to associate: Hybridboosted multi-target tracker for crowded scene,”in Computer Vision and Pattern Recognition, 2009. CVPR 2009. IEEE Conferenceon, pp. 2953–2960, IEEE, 2009.
[28] J. Munkres, “Algorithms for theassignment and transportation problems,” Journal of the society for industrialand applied mathematics, vol. 5, no. 1, pp. 32–38, 1957.
来源:智车科技
作者情况:
1 G¨ultekin G¨und¨uz is with the Computer Engineering Department, Galatasaray University, 34349, Istanbul, Turkey ggunduz@sabanciuniv.edu
2 Tankut Acarman is with the Computer Engineering Department, Galatasaray University, 34349, Istanbul, Turkey tacarman@gsu.edu.tr
*推荐阅读*
用OpenCV实现八种不同的目标跟踪算法
ECCV18 Oral | MIT&谷歌视频运动放大让计算机辅助人眼“明察秋毫”
为加速广大开发者视觉算法的转化及变现,极市开启了有奖视觉demo征集活动,通过测试的优秀demo提交者将会得到丰厚奖励和更多合作机会,点击左下角“阅读原文”了解详情。



