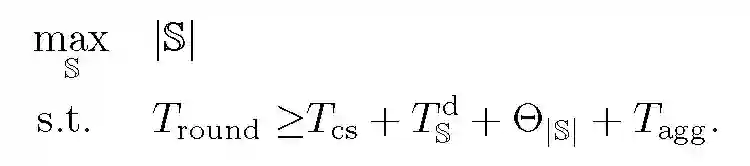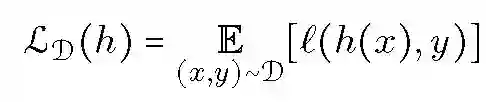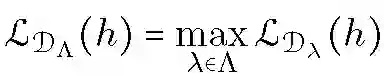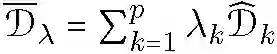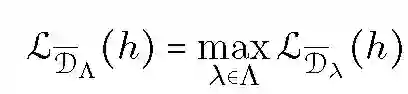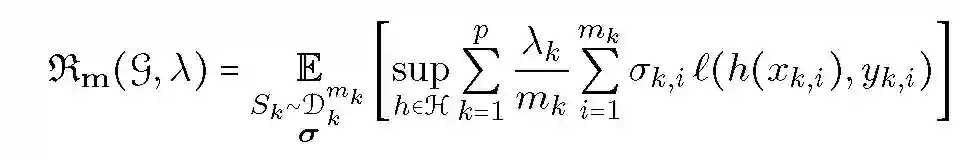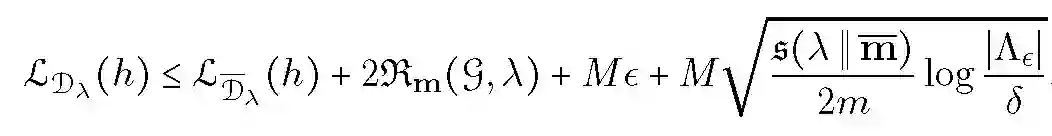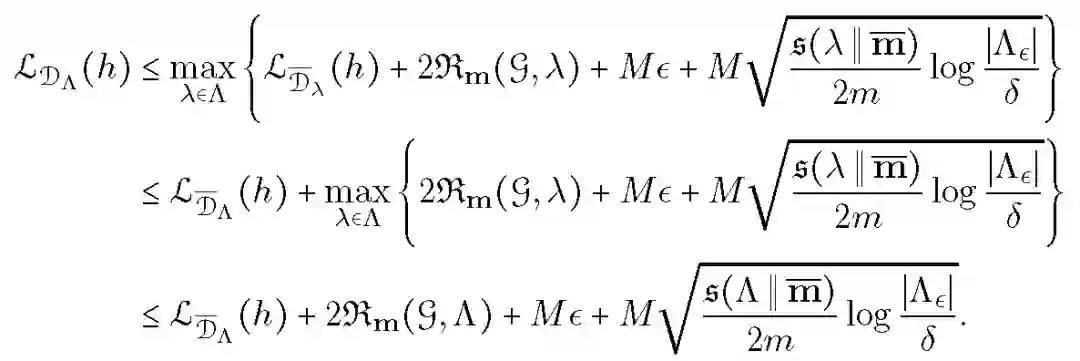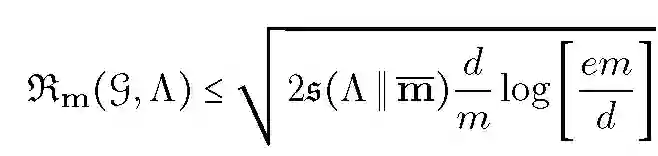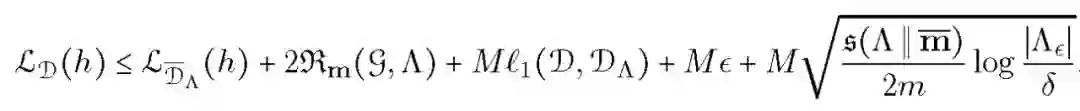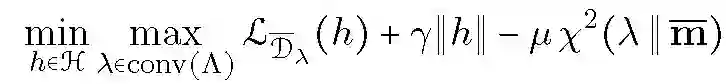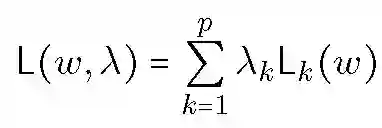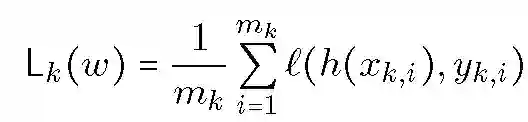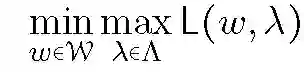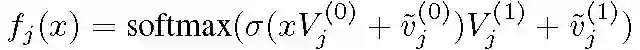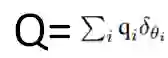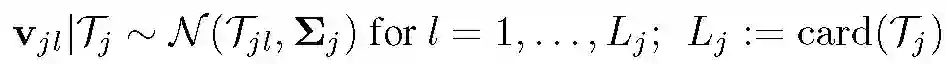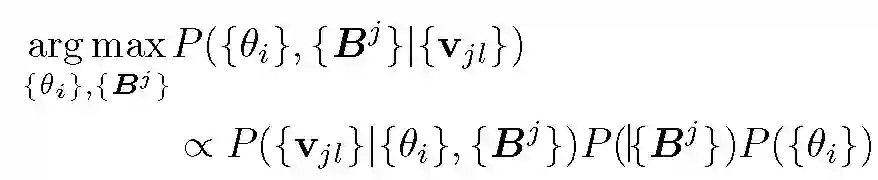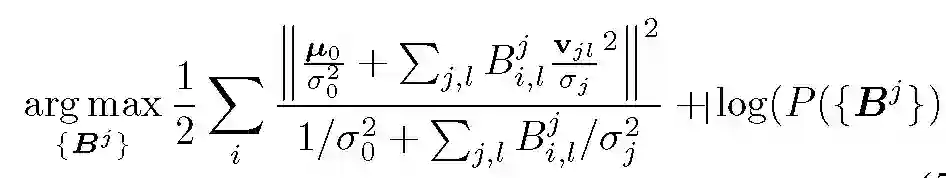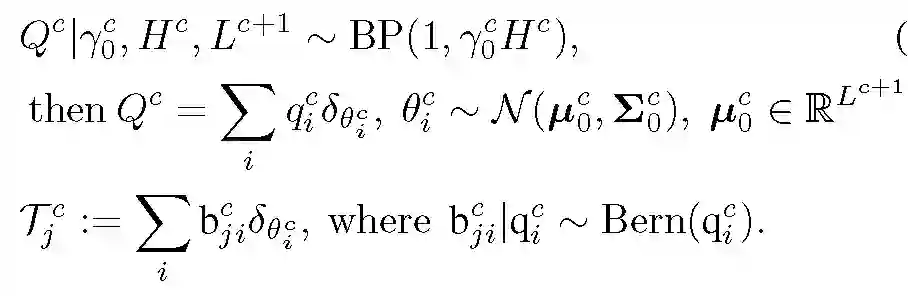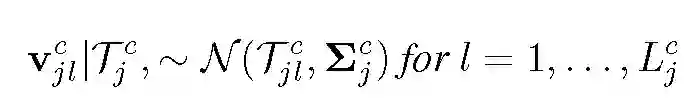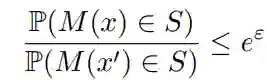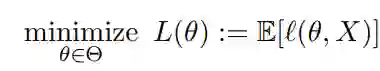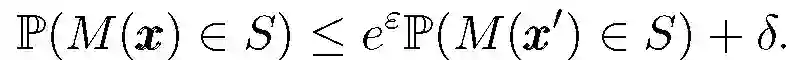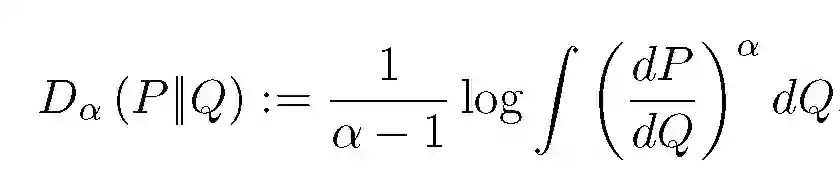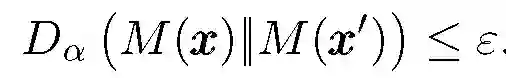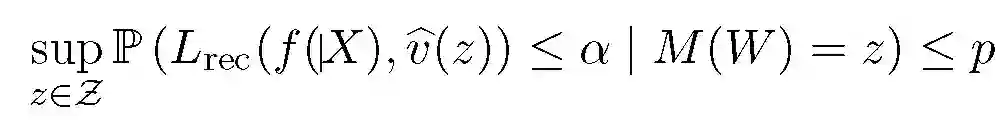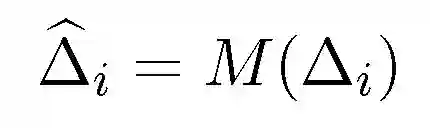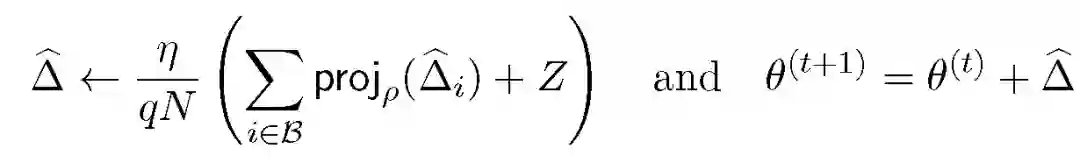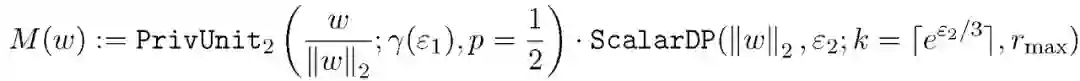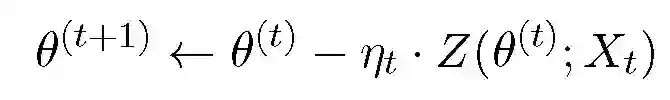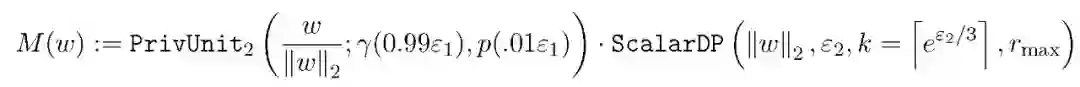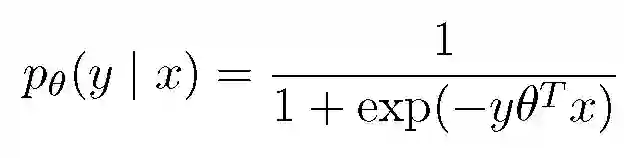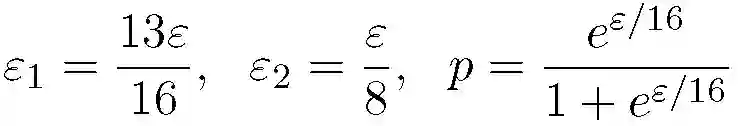随着移动电话、可穿戴设备和自主车辆等的推广和普及,分布式网络中的设备每天都会产生大量数据。设备计算能力不断提升,使得在设备本地存储数据并完成计算成为可能。与传统的基于数据汇聚共享、集中存储和集中处理的机器学习技术不同,利用联邦学习技术直接在设备本地端探索训练统计模型的分布式机器学习处理框架受到越来越多的关注。
在联邦学习框架中,中央服务器保存初始化可共享的全局数据。各个客户端(参与者、边缘设备)保存本地数据,并根据本地数据训练本地机器学习模型。客户端根据一定的通信机制向中央服务器传输模型参数等数据(不会传输完整的客户端原始数据),中央服务器汇聚各客户端上载数据后训练构建全局模型,各个客户端在整个联邦学习机制中身份和地位相同。联邦学习有效解决了两方或多方数据使用实体(客户端)在不贡献出数据的情况下的数据共同使用问题,解决了数据孤岛问题。此外,在各个客户端数据特征对齐的前提下,联邦学习的全局模型能够获得与数据集中式存储相同的建模效果。联邦学习对于隐私保护、大规模机器学习方法和分布式优化等有着特别要求,由此衍生出了交叉学科的新研究方向,包括机器学习和系统架构设计等。
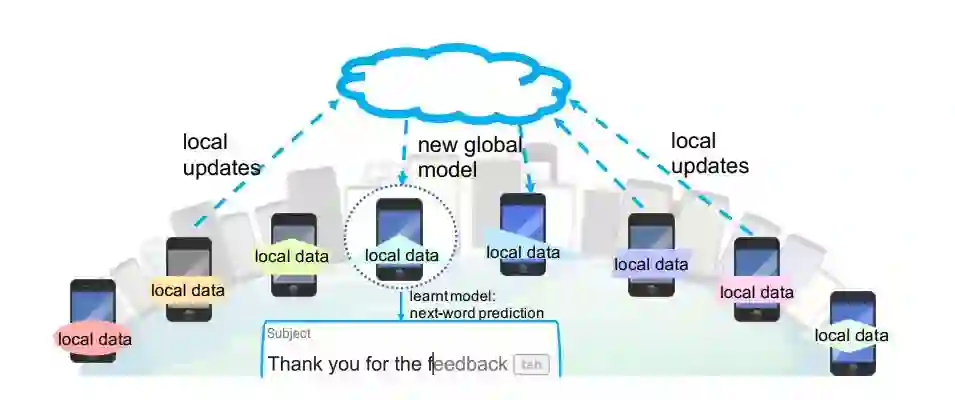
下图为联邦学习在手机中输入的下一个词预测任务中的应用实例 [1]。为了保护文本数据的隐私性并减少对通信网络产生的压力,联邦学习以分布式的方式训练预测器,而不是将原始数据发送到中央服务器集中训练。在此设置中,远程设备定期与中央服务器通信以构建全局模型。在每个通信回合中,所选手机终端的一个子集对其非独立同分布的用户数据执行本地训练,并将这些本地更新发送到中央服务器。汇聚更新后,中央服务器将新的全局模型发送回其它设备子集。这个迭代训练过程在整个网络中持续,直到达到收敛或满足某种终止标准。
![]()
经典的联邦学习问题基于存储在数千万至数百万远程客户端设备上的数据学习全局模型。在训练过程中,客户端设备需要周期性地与中央服务器进行通信。目前,联邦学习面临的难点主要包括四个方面:
高昂的通信代价。在联邦学习问题中,原始数据保存在远程客户端设备本地,必须与中央服务器不断交互才能完成全局模型的构建。通常整个联邦学习网络可能包含了大量的设备,网络通信速度可能比本地计算慢许多个数量级,这就造成高昂的通信代价成为了联邦学习的关键瓶颈。
系统异质性。由于客户端设备硬件条件(CPU、内存)、网络连接(3G、4G、5G、WiFi)和电源(电池电量)的变化,联邦学习网络中每个设备的存储、计算和通信能力都有可能不同。网络和设备本身的限制可能导致某一时间仅有一部分设备处于活动状态。此外,设备还会出现没电、网络无法接入等突发状况,导致瞬时无法连通。这种异质性的系统架构影响了联邦学习整体策略的制定。
统计异质性。设备通常以不同分布方式在网络上生成和收集数据,跨设备的数据数量、特征等可能有很大的变化,因此联邦学习网络中的数据为非独立同分布(Non-indepent and identically distributed, Non-IID)的。目前,主流机器学习算法主要是基于 IID 数据的假设前提推导建立的。因此,异质性的 Non-IID 数据特征给建模、分析和评估都带来了很大挑战。
隐私问题。联邦学习共享客户端设备中的模型参数更新(例如梯度信息)而不是原始数据,因此在数据隐私保护方面优于其他的分布式学习方法。然而,在训练过程中传递模型的更新信息仍然存在向第三方或中央服务器暴露敏感信息的风险。隐私保护成为联邦学习需要重点考虑的问题。
为了解决联邦学习在机器学习、系统策略优化和通信领域中存在的问题,在前期的研究中,研究人员提出了许多方法。然而,这些方法通常并不能有效应对联邦网络的规模问题,更不用说解决系统和统计异构性的挑战了。类似地,由于数据的统计变化以及设备本地的安全限制,联邦学习的隐私保护方法很难严格有效评估。
本文选择 2019 年最新的四篇文章,分别从解决系统异质性、统计异质性、通信代价和隐私保护四个角度详细探讨了联邦学习的研究进展。
https://arxiv.org/abs/1804.08333,Client selection for federated learning with heterogeneous resources in mobile edge, 提出了一个用于机器学习的移动边缘计算框架,它利用分布式客户端数据和计算资源来训练高性能机器学习模型,同时保留客户端隐私;
https://arxiv.org/abs/1902.00146v1,Agnostic Federated Learning,解决之前联邦学习机制中会对某些客户端任务发生倾斜的问题;
https://arxiv.org/abs/1905.12022v1,Bayesian Nonparametric Federated Learning of Neural Networks. ICML 2019. 提出单样本/少样本探索式的学习方法来解决通信问题;
https://arxiv.org/pdf/1812.00984.pdf,Protection Against Reconstruction and Its Applications in Private Federated Learning,提出了一种差异性隐私保护方法。
Client selection for federated learning with heterogeneous resources in mobile edge
![]()
联邦学习的系统异质性问题是指,构成联邦学习网络的各个客户端情况不同,计算资源(计算能力)以及无线信道条件等都存在较大的差异性,进而影响联邦学习的整体性能。本文提出了一个移动边缘计算框架(Mobile Edge Computing,MEC),能够在保护客户端隐私的同时完成客户端模型训练,同时有效解决真实蜂窝网络中的系统异质性问题。本文提出的联邦学习框架(FedCS)能够根据客户端资源条件管理客户端设备,从而有效应对具有资源约束的客户端选择问题,它允许服务器聚合尽可能多的客户端更新信息,并加速改进机器学习模型的性能。
联邦学习由一个中央服务器和 KxC 个随机客户端组成,其中 K 是客户端数目,C 为每轮所选参与更新的客户端比例的超参。在中央服务器和客户端之间传递要训练的全局模型的参数,包括分发、更新和上载等步骤。其中,所选客户端基于已有数据计算模型的参数更新(更新),中央服务器从客户端聚合多个更新改进全局模型(上载),之后再将全局模型分发至各个客户端(分发)。为了完成更新和上载任务,联邦学习要求每个客户端都具备一定的计算资源。在真实蜂窝网络中,由于客户端数据特征、计算能力以及通信通道性能的不同,联邦学习在客户端训练机器模型时往往会遇到很多问题。系统异质性已经成为联邦学习发展的一个瓶颈。
![]()
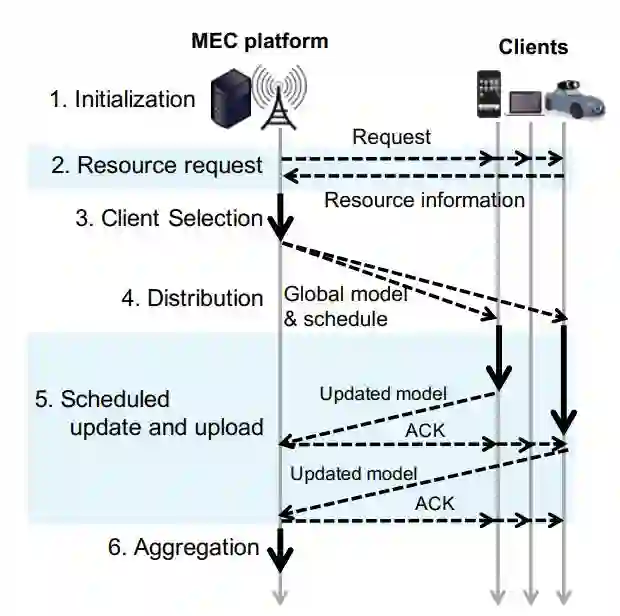
图 1. FedCS 框架概述. 图中实心黑线表示计算过程,虚线表示无线通信过程.
图 1 给出了本文提出的 FedCS 的整体结构,其中 MEC 平台表示中央服务器。与传统的随机选择客户端的方式不同,本文提出了一种客户端选择机制。首先,资源请求(Resource Request)步骤要求随机选择的客户端通知 MEC 平台其资源信息,例如无线信道状态、计算能力以及与当前训练任务相关的数据资源的大小等。然后,在客户端选择(Client Selection)步骤中引用此信息,以估计分发(Distribution)、计划的更新和上载(Scheduled Update and Upload)等步骤所需的时间,并确定由哪些客户端执行这些步骤。在分发(Distribution)步骤中,通过基站(Base station,BS)的多播将全局模型分发给所选客户端。在计划的更新和上载(Scheduled Update and Upload)步骤中,选定的客户端并行执行更新模型,将新参数上载到中央服务器。中央服务器使用验证数据评估直接聚合客户端更新的模型性能。在模型满足要求或达到执行时间要求之前,上述步骤重复执行。
客户端选择机制的目的是在每轮更新过程中尽可能多的收集有效客户端更新。本文提出的机制思想来源于 [2] 中,即「希望参与优化的客户端数量远大于每个客户端中的平均样本数」。根据这一标准,MEC 中央服务器选择能在指定截止时间内完成分发和计划更新上载任务的客户端,同时制定关于何时将模型的资源块(resource blocks,RBs)分配至选定的客户端的策略,从而避免蜂窝网络出现带宽拥塞的现象。本文假设各个客户端顺序启动和完成上载任务。
文献 [2] 中首次提出「让训练数据分布在移动客户端设备中,通过聚合本地计算的更新来学习共享模型」的联邦学习概念。作者提出,区别于传统分布式优化问题,联邦学习有几个关键属性:1)客户端中 Non-IID 数据;2)各个客户端环境不平衡;3)大规模分布;4)有限通讯回合。关于第三点,本篇文章中作者理解为参与每一轮更新的客户端数量越多,就能在越短时间内得到全局模型。因此每轮 MEC 中央服务器都将全部能在截止时间内完成的客户端纳入到更新中。但事实上,本文后续实验中(表 1)发现,盲目增加每轮参与更新的客户端数量,会降低模型收敛速度。参与每轮通信的客户端数量与全局模型优化速度之间的关系是否并非简单的单调递增关系?
令 K={1,...,K} 表示 K 个客户端的索引,K' 为在资源请求步骤中随机选择的 K 的子集。S 表示所选择的客户端索引,本文目的是对这些索引进行优化。在更新和上载步骤中,客户机按 S 的顺序依次上载其模型。假设 R_+为非负实数集,T_round 为每轮的截止时间,T_final 为最后截止时间,T_cs 和 T_agg 分别为客户端选择和聚合步骤所需的时间。(t_s)^d 表示分发所需的时间,它取决于选定的客户端 S。(t_k)^UD 和 (t_k)^UL 分别表示第 k 个客户端更新和上载模型所花费的时间。通过最大化所选客户端的数量每轮接受尽可能多的客户端更新。从计划更新和上载步骤开始到第 i 个客户端完成更新和上载过程的估计运行时间定义如下:
![]()
客户端顺序上载,(T_k)^UL 表示 (t_k)^UL 的总和。与之对应,也可以在之前的客户端执行上载步骤时更新模型。这样保证在个别更新时间段内,(t_k)^UD 不会收敛到 (T_i)^UD。客户端选择机制表示为下列最优化问题:
![]()
为实现上式优化,本文提出了一种基于贪婪算法的启发式算法,具体流程如下:
![]()
将模型上载和更新操作所用时间最少的客户端迭代添加到 S,直到运行时间 t 达到截止时间 T_round。整个算法中最关键的参数为 T_round,本文将 T_round 设置为较大值,从而能够保证更多的客户端参与到每轮上载和更新中。
1)模拟环境:本文在一个城市小区域的蜂窝网络上模拟了一个 MEC 环境,由一个边缘服务器、一个 BS 和 K=1000 个客户端组成,同时包含一个带有 GPU 的工作站。基站和服务器位于小区中心,半径为 2km,客户端在小区内均匀分布。
2)机器学习任务的实验设置:选择 CIFAR-10、 MNIST 数据库。首先,随机确定每个客户端拥有的图像数据的数量,范围为 100 到 1000。以两种方式将培训数据集分成客户机:IID 设置,其中每个客户端只从整个训练数据集中随机抽取指定数量的图像;Non-IID 设置,其中每个客户端随机抽取图像,但来自训练数据的不同子集(随机选择的 10 个类别中的 2 个类别)。
3)全局模型:本文重点并不是讨论使用复杂深度学习模型在联邦学习中的有效性,因此选择经典卷积神经网络作为两个任务的全局机器学习模型。模型包括 6 个 3x3 的卷积层(32, 32, 64,64, 128, 128 个通道,每一个都由 Relu 和批处理归一化,并且每一个都跟随 2x2 个最大池化层),然后是 3 个全连接层(382 和 192 个单元具有 Relu 激活,另外 10 个单元为 softmax 激活)。全局模型更新过程中,小批量大小为 50,每轮周期为 5 次,随机梯度下降更新初始学习率为 0.25,学习率衰减为 0.99。每个客户端的计算能力由在更新全局模型过程中其一秒钟内能够处理的样本数据来表示,随机确定每个客户端的平均能力,范围从 10 到 100。
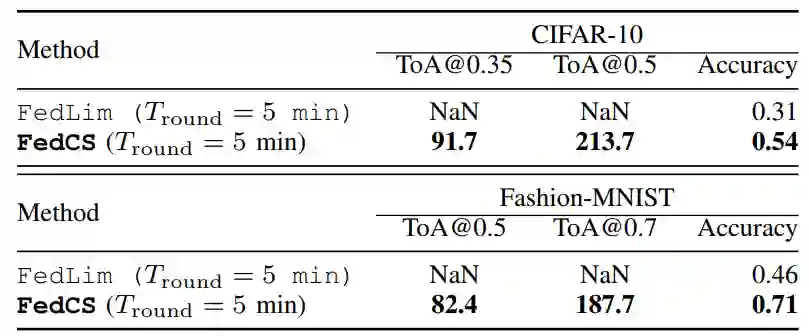
4)评价指标:本文将 FedCS 与经典联邦学习方法(FedLim)进行对比。评价指标包括达到所需精度的时间(ToA@x)、最后期限后的准确度(Accuracy)。
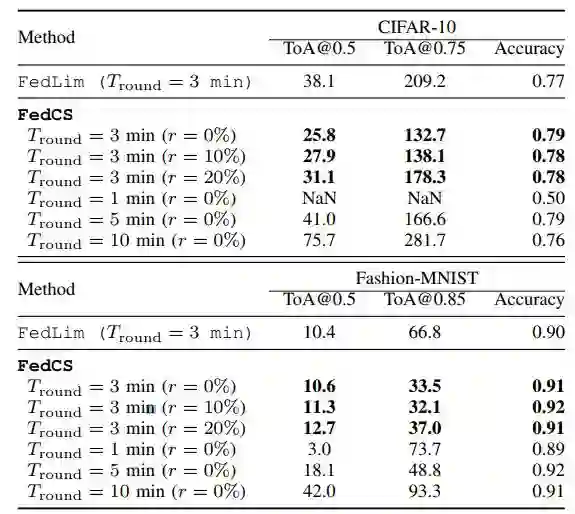
a. IID 设置下的实验结果见表 1。总体而言,就 ToA 而言,FedCS 在 CIFAR-10 和 Fashion-MNIST 任务方面效果均优于 FedLim。此外在最后期限之后,FedCS 比 FedLim 在 CIFAR-10 中获得了更高的分类准确度。这些结果表明,在训练阶段 FedCS 比 FedLim 的效率有所提高,原因是 FedCS 能够将更多的客户端纳入到每轮训练中。此外,该实验还证实了吞吐量和计算能力的不确定性对 FedCS 的性能影响不大(由参数 r 表征)。
表 1. CIFAR-10 和 MNIST 的 IID 设置结果.
![]()
![]()
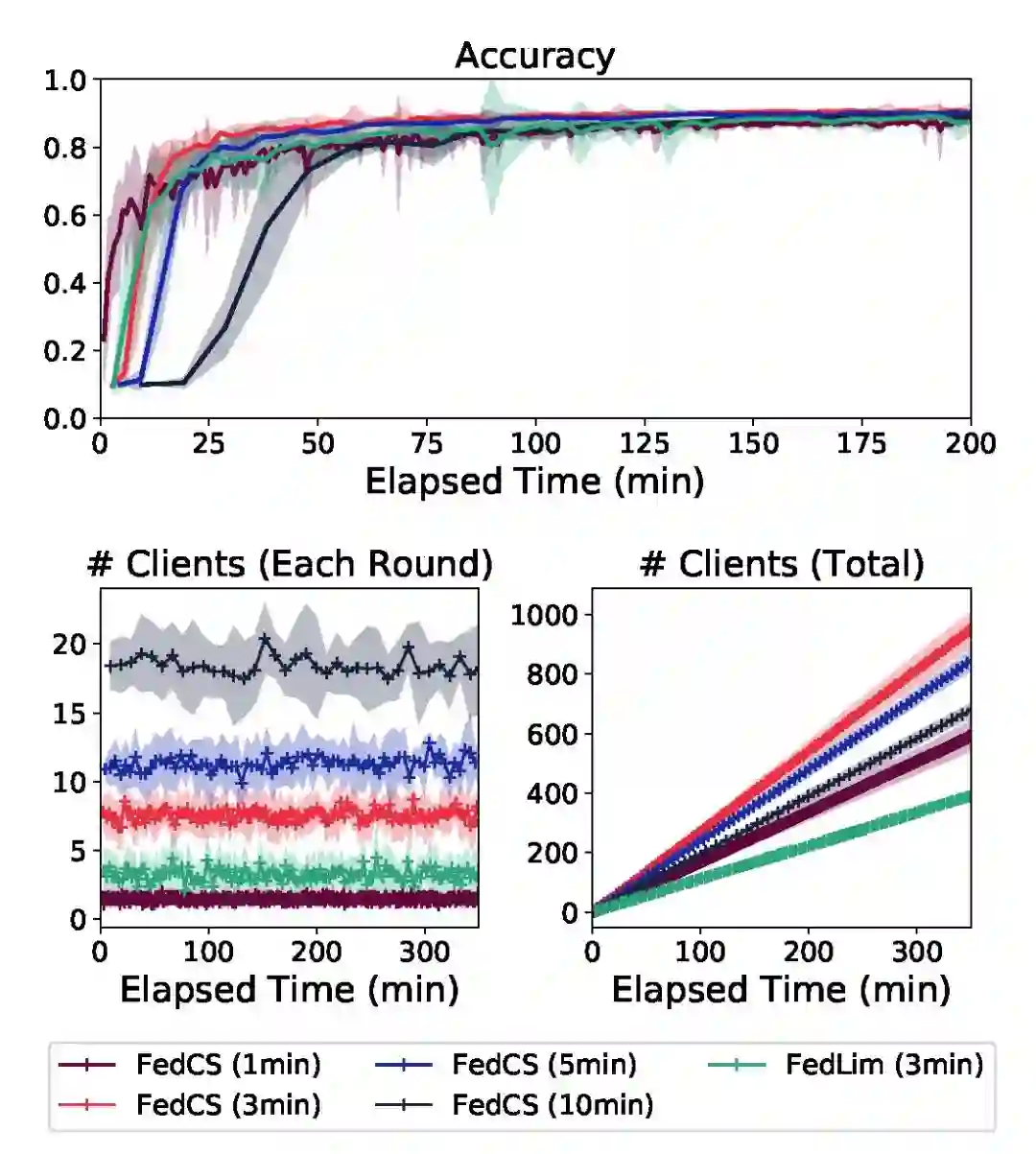
图 2. 不同截止时间 T_round 的对比实验结果.
图 2 中实验证明 T_round 的影响。上:精度曲线;左下:每轮选择的客户端数;右下:选择的客户端总数。阴影区域表示 10 次实验之间的性能标准差。由图 2 中实验可知,联邦学习中设置较长的截止时间 T_round 能够引入更多客户端,但是由于聚合步骤较少,能够带来的改进非常有限。相反的设置较短的截止时间 T_round,每轮有限的客户端数量会降低分类准确度。较好的选择 T_round 的方式是每轮动态的变化从而找到有效的客户端数量。这部分内容将是今后研究的重点。
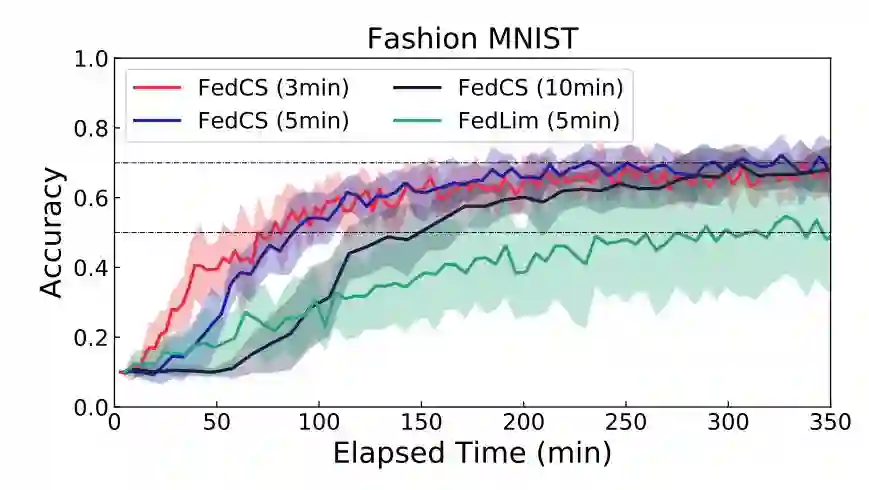
b. Non-IID 设置下的实验结果见表 2 和图 3。在 Non-IID 设置下,FedCS 依然能获得较好的效果。当然,与之前文章 [2] 中的分析一致,Non-IID 数据的联邦学习性能会受到影响。为了更好地处理 Non-IID 数据,我们需要增加每轮选择的客户端数量或总轮数,但由于实验中施加的时间限制 T_round 和 T_final,这两种处理都很困难。有效应对 Non-IID 数据的一个办法是模型压缩技术,这可以增加在相同的约束条件下可以选择的客户端的数量。关于 Non-IID 数据的处理问题不是本文讨论的重点,详细内容可见文献 [3]。
表 2. CIFAR-10 和 MNIST 的 Non-IID 设置结果.
![]()
![]()
图 3. Non-IID 设置中对应不同截止时间的准确度曲线.
本文提出了一个新的联邦学习框架 FedCS,其目标是在一个异构客户端的 MEC 框架中高效地完成联邦学习。本文验证实验中采用经典的深度神经网络建模,后续可以探讨利用更多的数据训练更复杂的模型。此外,未来工作的另一个可能的方向是处理动态的应用场景,例如在资源的平均数量以及更新和上传所需时间动态波动的情况下如何改进联邦学习性能。
Agnostic Federated Learning
![]()
基于传统的训练和推理机制,经典联邦学习的全局模型训练结果可能会倾向于某些客户端上载的更新参数。本文针对这一问题提出了一种不可知的联邦学习框架 (Agnostic Federated Learning, AFL),在该框架中,全局模型针对由各个客户端分布聚合而成的任一目标分布进行优化。本文引入数据相关的 Rademacher 复杂度用于模型的目标学习,从而满足任务不可知的联邦学习要求。此外,本文还提出了一种快速随机优化算法,证明了该算法在假定凸损失函数和假设集情况下的收敛性。
假设 X 表示输入空间,Y 表示输出空间同时 Y 是有限类集,本文以多类别分类问题为例讨论不可知联邦学习框架的构建,其分析结果可直接推广到其他机器学习问题中。h(x) 表示 x 属于某类别的概率分布,H 为 h 的分布集合。问题损失函数定义为:
![]()
L_D(h) 表示假设 h 相对于 X×Y 上分布 D 的期望损失。
考虑这样一个机器学习场景,学习者接收到 p 个样本 S1,...,Sp,其中样本 Sk 为从专门域或分布 Dk 提取的 IID 数据,(D_k)^表示样本 Sk 相关的经验分布。经典联邦学习的训练是在所有样本 Sk 的联合均匀分布情况下进行的,即
![]()
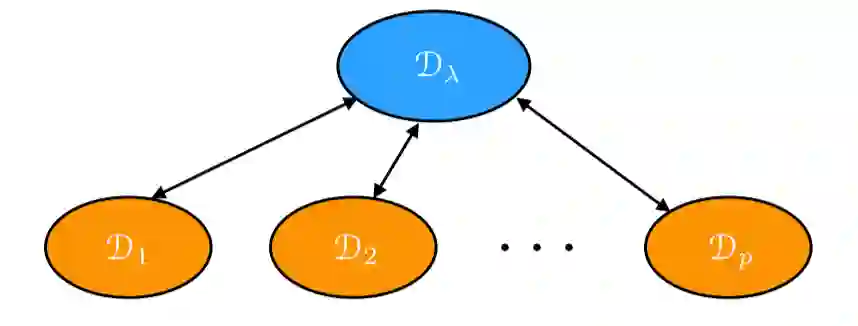
而本文提出的不可知联邦学习 AFL 框架,其目标分布表征为分布 Dk 的未知混合,其中各个混合项的权重为 lambda。因此,AFL 中的不可知损失函数为:
![]()
实际上,学习者只能通过有限的样本 Sk 来获取分布 Dk。因此,对于任何 lambda,上式中只能计算经验分布的 lambda-混合如下:
![]()
![]()
图 1: 未知混合分布 D_lambda.
![]()
本文基于加权 Rademacher 复杂度计算学习界限:
![]()
其中 Sk 表示大小为 m_k 的样本,sigma 为 Rademacher 变量集合,这些变量均为 {-1,+1} 范围内的均匀分布随机变量。假设损失函数以 M>0 为界。对于任何大于 0 的 delta,在样本 Sk~Dk.^(m_k) 中以最小(1-delta)的概率抽样,具有下列不等式:
![]()
![]()
对于取值范围为 {1,-1} 的损失函数,下列加权 Rademacher 复杂度的上界成立:
![]()
对于本文的损失函数和不可知经验损失函数,假设损失函数以 M 为界,对于任何 epsilon>=0 和 delta>0,概率至少为 1-delta,下述不等式适用于所有的类别概率 h:
![]()
由上面的数学分析,本文提出的 AFL 算法表示为:
![]()
当损失函数为凸函数,可以使用投影梯度下降或其它通用镜像下降算法来解决优化问题。优化过程主要涉及两组参数:假设概率分布 h 和混合权重 lambda。将损失函数定义为:
![]()
![]()
为了简化讨论,本文使用 AFK 的非正则化版本,即由变量集 w 给出的以下问题:
![]()
上式将自然博弈论解释为两人博弈问题(minmax),其中整体目标为选择最大化目标函数的 lambda,而学习者的目标是找到最小化损失的 w,总体任务是找到这个问题的平衡点。解决 AFL 优化问题随机代码如下:
![]()
在每一步中算法计算一个关于 lambda 和 w 的随机梯度,并相应地更新模型。然后通过计算凸极小化得到 Lambda 的值从而将 lambda 投影到 Lambda。重复计算 T 次并返回权重的平均值。
利用 UCI 机器学习库的人口普查数据集构建成人数据库,共 32561 个训练样本。根据是否获得博士学位,将训练样本划分为两个域,其中博士域包括 413 个样本,非博士域包含 32148 个样本。基于类别特征和 Adagrad 优化器训练得到 Logistic 回归模型。表 1 列出了平均运行 50 次以上的模型性能。使用 u^训练得到的 D_lambda 代表经典联邦学习方法的结果,而使用 L_D_lambda 训练得到的 D_lambda 表示 AFL 效果。在所有模型中,AFL 在最差的域内获得最高的准确度 (71.5%)。AFL 模型的测试准确度在各域上的平均值略低于经典的均衡化处理模型,但不可知论模型的偏差较小,在 D_lambda 上表现较好。在本文实验的两个域中,博士域更难预测。对于这个领域,领域不可知模型的性能接近于仅基于博士域数据的模型,优于经典均匀分布模型。
![]()
MNIST 数据库包含 60000 个训练图像和 10000 个测试图像,以 28x28 个灰度像素强度阵列的方式存储,同时在 10 个类别中均匀分布。本文首先训练一个简单的逻辑回归分类器,观察到以下三个类别的分类性能最差:T 恤衫/上衣、套头衫和衬衫。接下来,提取了用这三个类别标记的数据子集,并将该子集分成三个域,每个域由一类衣服组成。然后,使用逻辑回归和 Adam 优化器训练针对这 3 个类别的分类器。实验结果见表 2。由于各个域分别给定了标签,在这个实验中,本文没有对比在特定域上训练的模型。在 3 个类别中,衬衫的分类难度最大。与基于均匀分布 u^训练的经典模型相比,AFL 可以提高衬衫类别的整体识别准确度。此外,不可知学习方案不仅改善了难度最大的域内的识别效果,而且具有更好的推广性,提高了平均测试准确度。AFL 模型在任何目标分布 D_lambda 上达到了约 74.5% 的准确度,而经典联邦学习的准确度约为 71.2%。
![]()
该数据库仅包含两种语言数据:对话和文本。对话数据使用的是 Cornell 电影数据库,其中包含了 300000 条语句,平均长度为 8。文本数据使用 Penn TreeBank(PTB)数据库,包含 50000 条语句,平均长度为 20。本文通过将上述两个对话和文本语料库作为域相结合构建了一个数据库。本文使用动量优化器(momentum optimizaer)训练了一个投影大小为 512 的双层 LSTM 模型。通过复杂度来衡量模型的效果,即交叉熵损失的指数,实验结果见表 3。在这两个域中,文本域的处理难度较大,AFL 的测试复杂度接近于仅针对文本数据训练的模型,优于基于均匀分布 u^训练的模型。
![]()
针对联邦学习的统计异质性问题,本文提出了一种不可知联邦学习框架 AFL,从而解决经典联邦学习中会对某些客户端任务发生倾斜的问题。本文对该框架进行了充分的理论分析和论证,详细的数学证明可见原文。此外,本文进行的实验结果证明,这种方法也可以在实际问题应用中带来明显的改进。
Bayesian Nonparametric Federated Learning of Neural Networks
![]()
本文提出了一种贝叶斯非参数的神经网络联邦学习框架。每个客户端基于本地数据计算神经网络参数构建本地模型,利用本文提出的联合概率神经匹配(Probabilistic Federated Neural Matching,PFNM)完成全局模型的构建。利用本文提出的推理方法,在没有额外监控、数据池等信息以及只执行一轮通信的情况下,能够生成效果更优的全局神经网络模型。
本文首先介绍了如何将贝叶斯非参数机制应用于使用神经网络的联邦学习框架中。贝叶斯非参数机制的目标是识别 J-本地模型中与其他本地模型中的神经元相匹配的神经元子集。然后,将匹配的神经元组合后形成全局模型。
假设训练 J -多层感知器(MLP)j=1,...,J,每个感知器有一个隐藏层。令 V.^(0) 和 v.^(0) 分别表示隐藏层的权重及偏移,V.^(1) 和 v.^(1) 表示 softmax 层的权重和偏移。D 为数据维度,Lj 表示隐层的神经元数量,K 为类别数量。简单的神经网络结构为:
![]()
在给定权重和偏移的前提下学习全局神经网络。首先,神经网络中 MLP 隐层的神经元排列具备置换不变性。因此,不能够将权重当作矩阵、偏差当作向量,而是要将它们分别看作向量和标量的无序集合。第二,神经网络中的隐藏层通常被视为特征抽取器,每个 ((v_jl).^(0),(v-tilde_jl).^(0))参数化对应神经元的特征提取器。由于 J-MLP 基于相同的一般数据类型(不一定是同质的)训练,假设它们至少共享一些用于相同目的的特征抽取器。然而,由于前面讨论的置换不变性问题,由第 j 个 MLP 的 l 标注的特征提取器不太可能对应到不同 MLP 的相同索引的特征抽取器。
由上述分析,为了将联合概率神经匹配方法应用于联邦学习,在构建全局特征提取器(神经元)的过程中,必须对 MLP 集合的特征抽取器进行分组和组合的过程建模。
本文提出的联邦学习框架关键组成部分是引入了一个基于 Beta-Bernoulli 过程的 MLP 权重参数模型 [4]。首先,从一个 Beta 过程中提取一组全局原子(隐层神经元),其中包含一个基本度量 h 和质量参数 gamma_0:
![]()
其中每个 theta_i 是由特征提取器权重偏差对与 softmax 回归的相应权重形成的级联向量。本文使用「batch」来表示数据的一个分区。接下来,对于每个 j=1,...,J,通过 Bernoulli 过程为 batch j 选择全局原子的子集:
![]()
最后,假设观测到的局部原子是对应全局原子的有噪测量结果:
![]()
在这个模型中,待推断的关键量是随机变量的集合,这些随机变量在任何一批(batch)中都将观测到的原子(神经元)与全局原子相匹配。这些随机变量的集合表示为 {B^j}。
对上述模型的全局原子进行 MAP 估计的算法目标函数如下:
![]()
根据「高斯分布是高斯分布的共轭」命题,上式可计算为:
![]()
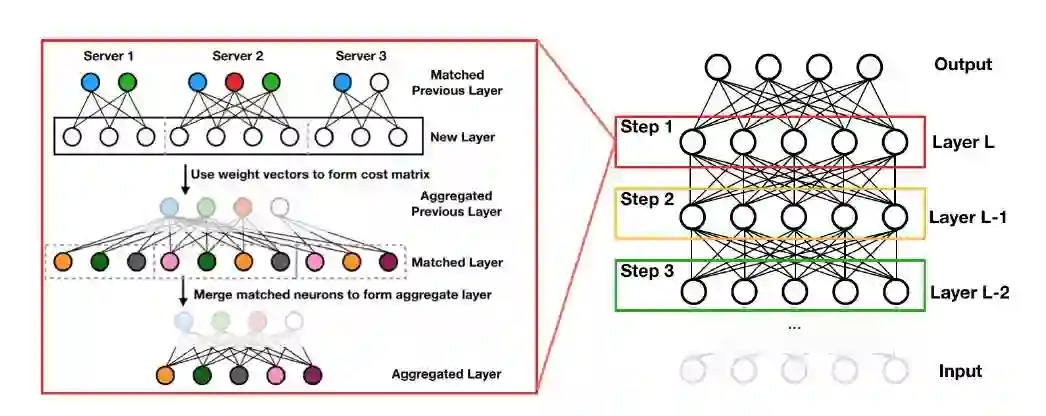
考虑一种迭代优化方法,给定 B^j,找到相应的最优分配,然后随机选取一个新的 j,直到收敛。本文对上式进行了数学计算并用 Hungarian 算法进行求解。下图 1 中总结了整个单层推理过程。
![]()
图 1. 三个 MLPs 匹配的单层概率联邦神经匹配算法.
分析到目前为止,本文给出的模型可以处理任意宽度的单层神经网络,从理论上讲,该单层网络能够模拟逼近任何目标函数。下一步,通过定义从输出到输入(自上而下)的深度神经网络权值生成模型,本文将单层神经网络匹配扩展到对深度网络的匹配中。
令 C 表示多层网络结构中的隐层数量,L^c 表示第 c 层的神经元数量,L^(C+1)=K 为标签数量,L^0=D 为输入维度。在自上而下的方法中,全局原子不再是构成单个神经元隐层模型中的神经元的权重,而是来自神经元的输出权重的向量。
从最上层的隐藏层 c=C 开始,我们使用与单层情况中相似的模型生成每个层,基于各层结果生成一个全局原子集合,并使用 Beta-Bernoulli 过程构造为每个批(batch)选择一个子集。L 对应某层神经元的数目,它控制对应层原子的尺寸。多层模型的生成过程如下:
![]()
其中 Tj^c 表示第 j 批在 c 层使用的全局原子(神经元)集。最后,生成观察到的局部原子:
![]()
遵循自上而下的生成模型,本文采用贪婪推理过程,首先推断出顶层的匹配,然后再向下进行网络层的匹配。每个层的生成过程仅依赖于其上一层中的全局神经元的类别和数量,因此,一旦推断得到全局模型的 C+1 层,就可以将单层推理算法(如图 1 中的算法 1)应用到第 C 层。也就是说,只需要一轮通信,就可以生成全局模型。图 2 直观地说明了整个多层推理过程,算法 2 提供了详细信息。
![]()
![]()
图 2. 显示三层 MLP 匹配的概率联邦神经网络匹配算法.
图 2 中的节点表示神经元,相同颜色的神经元表示相互匹配。左侧图显示了其中一层的匹配方法,具体为:使用下一个最高层的匹配分配将每个 j 批中的神经元转换为引用全局上一层的权重向量。使用这些权重向量形成代价矩阵,之后使用 Hungarian 算法进行匹配。最后,对匹配的神经元进行聚集和平均,形成全局模型中新的一层。如图 2 中右图所示,在多层设置中,生成的全局层用于匹配下一个较低层等,直到到达底部隐藏层。
在上面的分析中,本文提出的 PFNM 方法仅需一个通信回合就可构建全局模型。而经典的联邦学习基于本地数据需要经过几个阶段的训练生成本地模型,之后通过本地模型和全局模型间的多轮通信构建最终的全局模型。借鉴联邦学习的理念,通过引入额外的通信回合,能够有效扩展和提升 PFNM 的性能。
首先使用全局模型的子集初始化本地模型,在多轮通信回合中保证本地模型大小 Lj 不变。本地模型更新后,再次应用 PFNM 方法匹配生成新的全局模型。值得注意的是,全局模型的尺寸在不同的通信回合中是不断变化的,特别的,我们希望随着本地模型的改进这个尺寸能够逐渐变小。
数据库:MNIST、CIFAR-10。对两个数据库都执行相同的操作,随机将数据库分成 j 批,分区方法有两种:(a)同质分区,其中每个批次中数据类别在 K 个类中的比例大致相等;(b)异构分区,批次大小和数据类比例不平衡。
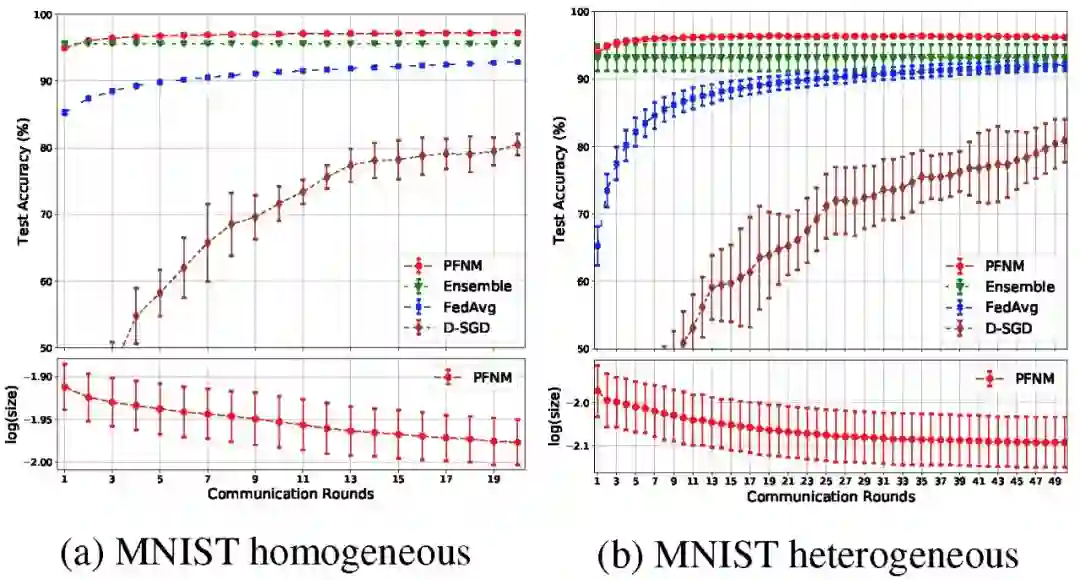
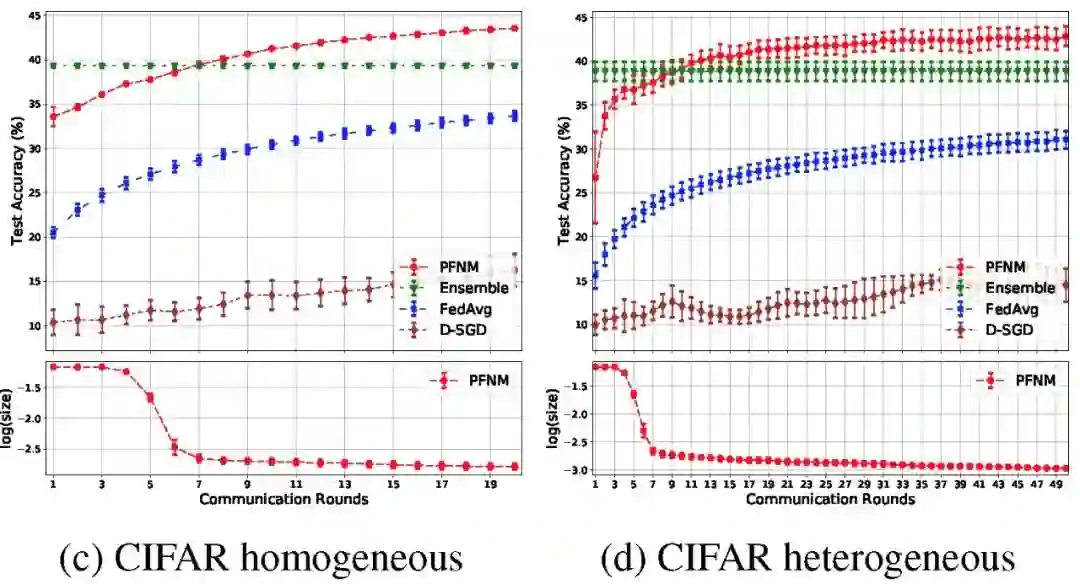
实验目的:本文给出实验证明 PFNM 可以将多个独立于不同批次数据上训练的本地神经网络聚合成一个高效的、中等规模的全局神经网络,且仅需执行一个通信回合。当允许额外的通信时,其性能还将提升。
仅通过一轮通信学习生成全局模型,这与真实应用场景是吻合的,在真实场景中,一些设备的数据可能不能持续存在,此时仅能基于之前训练得到的本地模型来生成全局模型。
对比算法:神经网络、聚合算法、经典联邦学习 [2]、K-means 聚类。
![]()
![]()
![]()
![]()
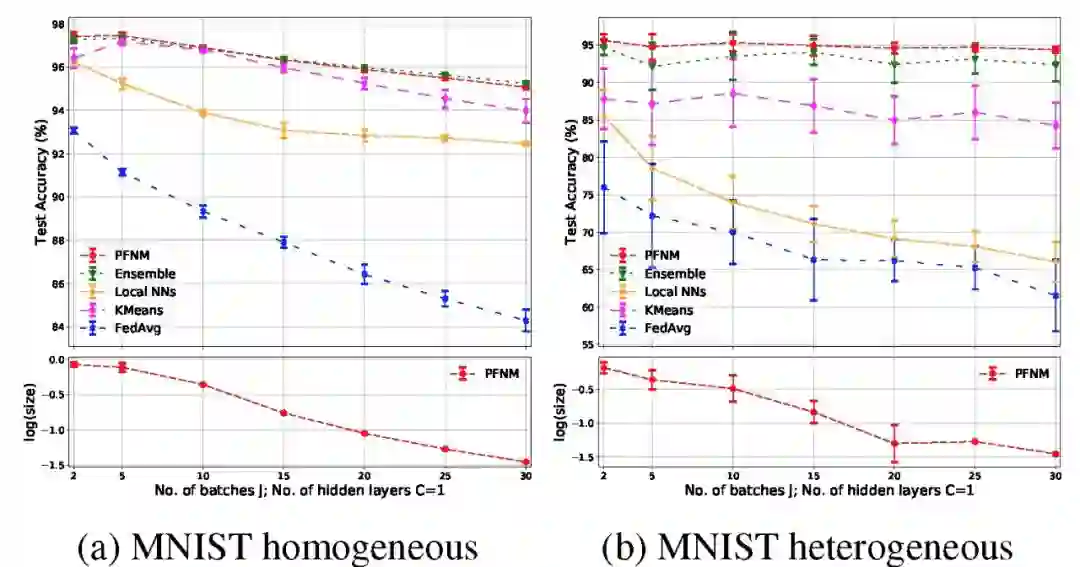
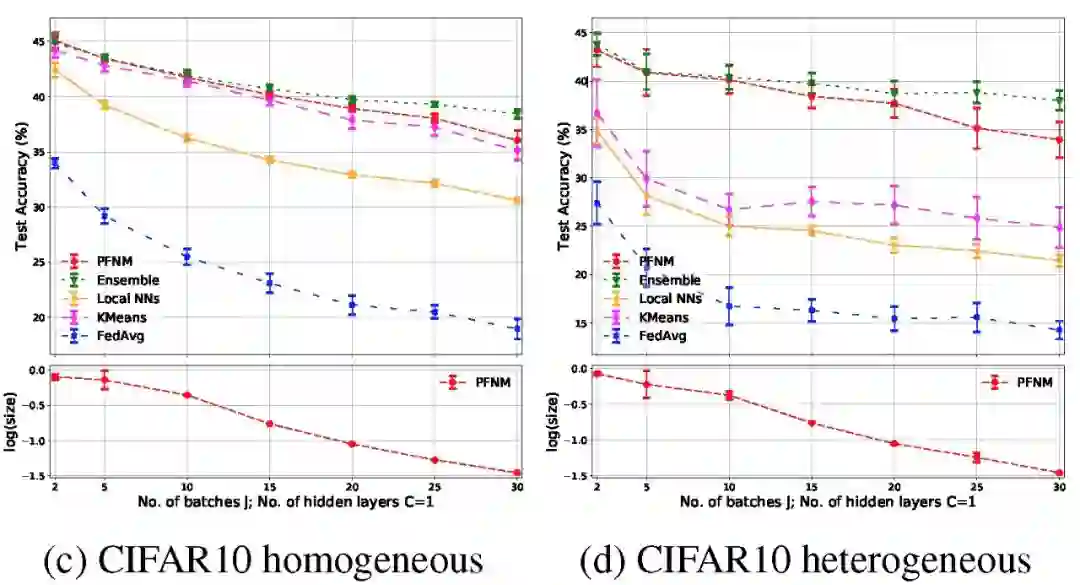
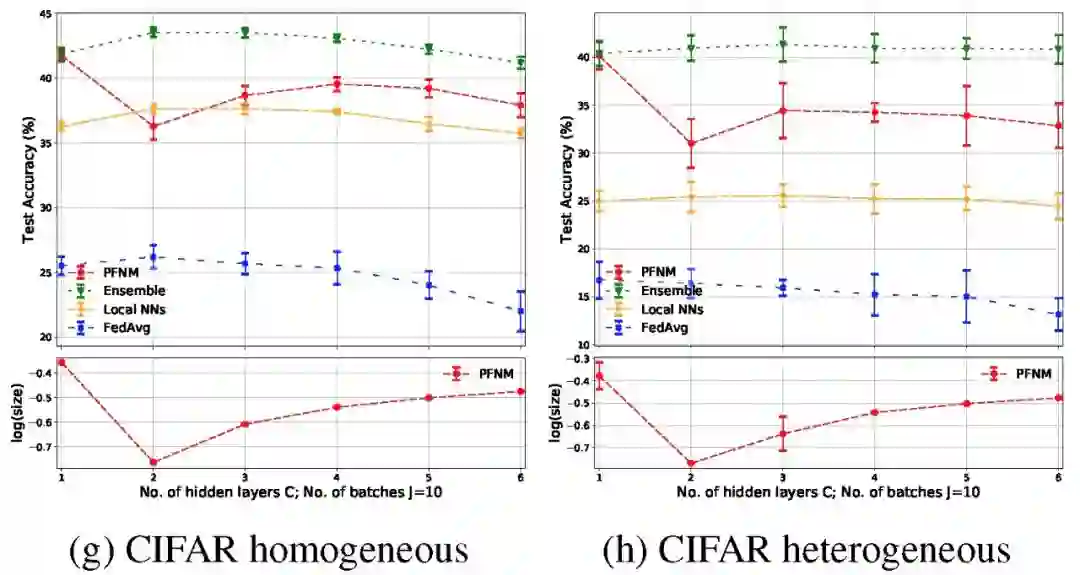
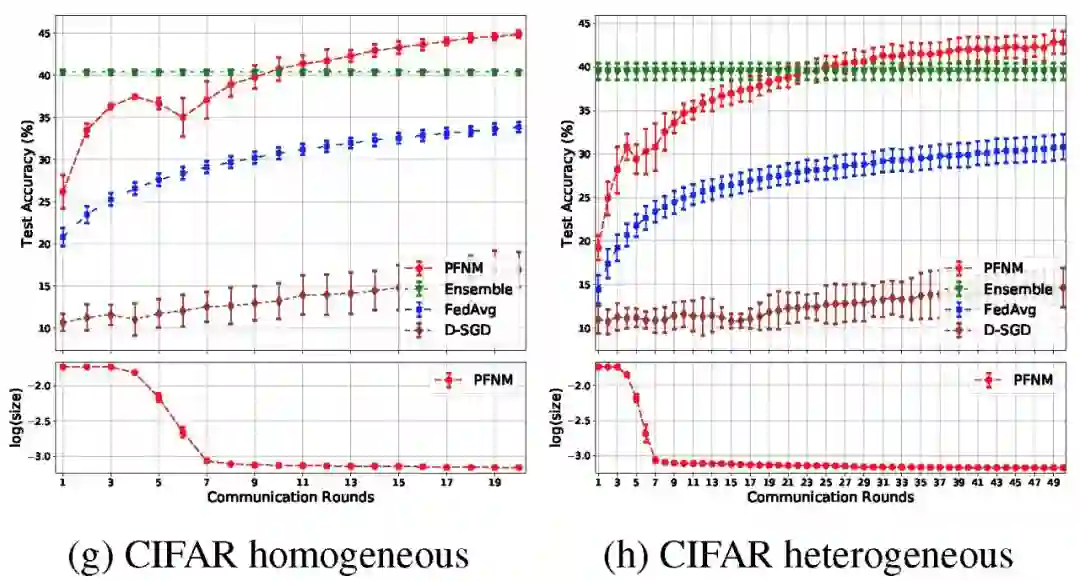
图 3 给出了不同批次的单隐层神经网络结果。在异构分区的实验条件下,我们观察到局部 NNS 和 K-means 的性能明显下降,而 PFNM 能够保持其良好的性能。在讨论聚合性能的问题上,PFNM 与本地模型和联邦学习方法相比,改进也很明显。但是它的性能略逊于聚合方法,特别是针对 CIFAR-10 中较深的网络结构。此外我们也能看到,因为经典联邦学习方法的思路就是通过多轮通信构建全局模型,因此仅执行一轮通信回合,联邦学习方法的效果最差。
在某些情况下,将通信限制在一个回合内可能要求过高,因此本文也探讨了在实践中经常出现的、允许有限通信回合的情况。
数据条件:同质分区时,25 个批次和 20 个通信回合;异构分区时,25 个批次,50 个通信回合。
对比算法:经典联邦学习、Downpour-SGD、聚合方法。
![]()
![]()
![]()
![]()
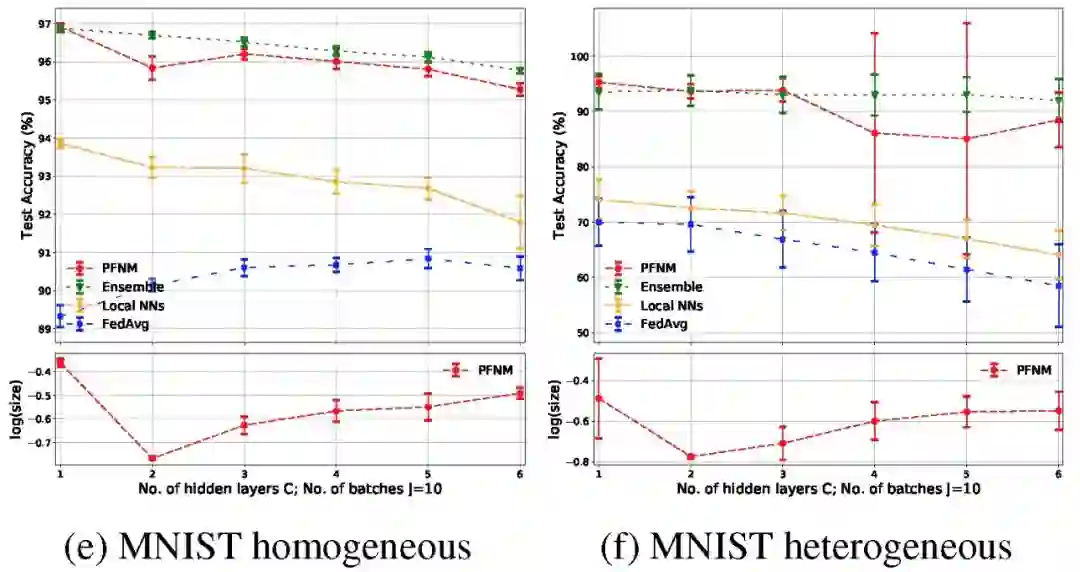
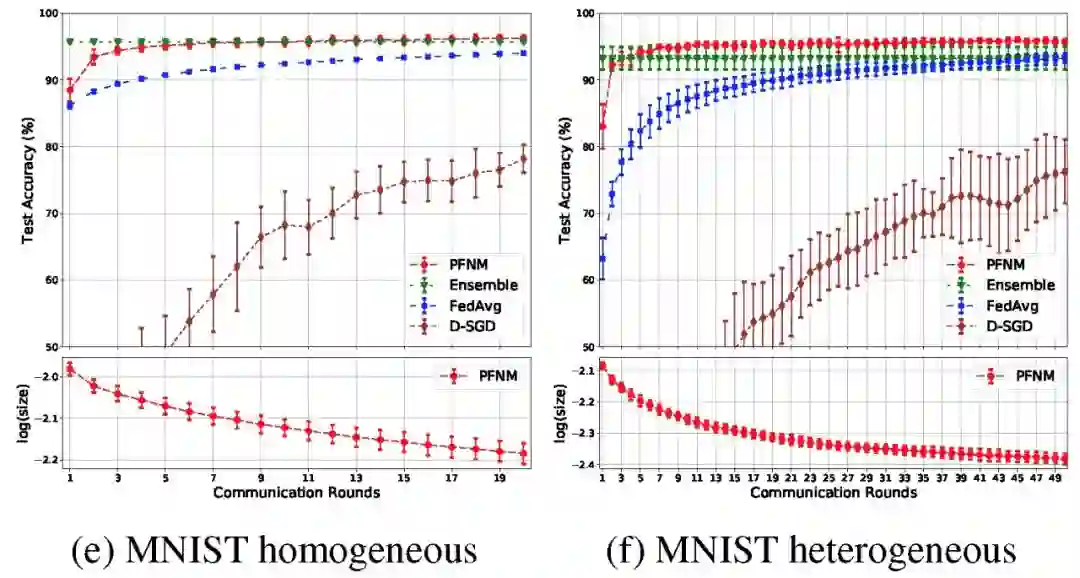
图 4 给出了一层和两层神经网络的结果。在两种实验数据情况下,每层都使用 100 个神经元。在保证足够通信回合的情况下,PFNM 的性能都优于聚合算法。此外,在所有的实验中,与联邦学习和 D-SGD 相比,PFNM 需要较少的通信回合就能达到给定的性能水平。
本文提出了一种利用单样本/少样本探索式学习的方法(PFNM),仅通过一次或少次通信回合构建全局模型,从而有效解决联邦学习中的通信问题。在适当的通信条件下,PFNM 效果优于使用神经网络的联邦学习的最新算法。在未来的工作中,计划探索更复杂的方式来组合本地网络,特别针对每个本地网络的训练样本都较少的情况提出有效解决方案。本文方法中使用的匹配方法是完全无监督的,结合某种形式的监督可能有助于进一步提高性能。最后,当前建模框架可以扩展到其他架构,如卷积神经网络(CNNS)和递归神经网络(RNNS)等,引入其他架构神经网络中的参数调整和设置将是今后工作的研究方向。
Protection Against Reconstruction and Its Applications in Private Federated Learning
![]()
随着大规模统计学习的发展,数据采集和建模技术逐渐从传统的中心化汇聚及处理改变为在外围设备上本地化处理及建模,例如电话、手表、健身手环等。伴随着分布式存储的数据增长,如何在保证足够数据用于建模的同时保护数据隐私性,这一问题面临着巨大的挑战。本文提出了「本地隐私概念」,即在统计人员或学习者能够观察到数据之前,对这些数据进行差异化、模糊化处理,从而对个人数据提供有效保护。传统的用于本地隐私保护的方法在实际应用中过于严格,特别是在现代高维统计和机器学习问题中往往无法适用。本文基于对手大概率事先能够掌握到的信息有限的考虑,为确保对手无法在一定的误差范围内重建数据,提出了一种有效的数据发布措施,同时设计了一种针对不同隐私要求的统计学习问题的最小最大(minimax)差异性隐私机制。
在联邦学习问题中,即使只在客户端和中央服务器之间传输模型的更新信息而不传输客户端本地数据,依然存在暴露用户隐私的风险。本文提出了一种基于本地私有算法的隐私保护方法。给定客户端保持私有状态的数据 x∈X,随机机制 M:X→Z 是ε-本地差异性私有的,则对于所有 x,x『∈X 以及集合 S,我们有:
![]()
满足上式表示即使对手知道初始数据是 x 或 x' 中的一个,也无法在给定结果 Z 的情况下区分它们。在本文考虑的大规模机器学习场景中,对手并不能掌握关于 X 的先验信息,因此,本文提出的本地隐私保护方法仅需做到在对手先验知识的某些假设下防止重构(x 的函数),即可显著改进模型拟合效果。
给定参数空间和损失函数,目标是解决风险优化问题如下:
![]()
本文通过解决随机最小化问题的方式优化上式,同时提供本地隐私个人数据 Xi 并提供差异性隐私的可靠保证,进而提出了一种本地数学隐私模型拟合方法。
在分布式模型匹配和联合学习场景中,主要考虑两个潜在的攻击者:一是旁观者,他可以观察到模型的所有更新和单个设备的通信情况;第二种是外部对手,他可以观察到最终模型或其它关于可能参与数据收集和模型拟合的个人信息。对于前者,主要是阻止其成功的重建模型,对于后者则需要在本地化或集中式差异化私有策略中使用较小的隐私参数。
![]()
差异性隐私的其他变体要求平均似然比接近 1,包括集中式和 Renyi 差异隐私权。分布 P 和 Q 之间的 Renyi alpha-散度为:
![]()
![]()
当考虑隐私保护对象为没有收到可信保护的单个数据提供者,则应用于单个数据点 x 的机制 M 是本地私有的。
本文所研究的情况是用户或研究参与方希望保护数据 X。通过一些处理将 X 转化为向量 W,这种转化可能只是简单的恒等式转换,也可能是 X 或其他推导结果的损失梯度。通过随机映射 W→Z 对 W 进行私有化处理。旁观者(或对手)希望能够基于私有数据 X 估计函数 f(X)。但是,如果 X 或 f(X) 维度足够高,旁观者(或对手)掌握的关于 X 的先验知识是有限的,因此 W→Z 的映射仅需包含较少的混淆信息就可以保证 X 的隐私安全。
旁观者(或对手)具有先验知识 pi,已知随机映射机制 M:W→Z, W→Z=M(W)。f 为重建目标,L_Rec 为损失函数。估计值 v.^提供一个针对 L_Rec 的 (alpha,p,f) 重建破坏如下:
![]()
![]()
上式适用于所有可能的机制 M 的观察值 z,因此需要对机制有一些严格的条件,不允许在差异性隐私之外放宽隐私限制条件。
接下来可以为重建提供保护。如果对手掌握了 f(X) 的扩散先验知识,由于该先验知识并不能用于重建 f(X),因此对手即使在非常大的 epsilon 数据范围内,都不可能根据 X 的差异性私有视图重建 f(X)。本文给出了几个例子,提供了限制信息以防止重建的最佳实践建议,并对合理的先验信息给出了一些有效的启发式计算。包括:扩散先验与线性函数的重构、稀疏数据的重建保护等。
基于上文提到的风险优化目标函数,联邦学习的分布式学习过程(不考虑隐私性)重复如下:
a. 中央服务器的全局参数 theta 广播到一个包含 b 个客户端的子集中,客户端本地样本为 Xi,i=1,...b;
c. 中央服务器汇聚更新的参数形成全局更新参数,并更新全局模型。
在本文提出的考虑隐私安全的架构中,第 2、3 步需要增加额外的安全保护措施:在客户端本地执行的步骤 2 中,应用本地隐私保护机制保护本地数据 Xi(参照上文提到的重建破坏保护);针对在中央服务器中执行的汇聚步骤 3,采用差异性隐私机制保证模型参数的通信过程是全局私有的。整个反馈环路提供了有效的隐私保护,用户的本地数据不会传输到中央服务器,而集中式隐私保护能够保证过程和最终参数都不存在敏感性披露的风险。
针对初始化本地参数 theta_0,本地运行模型计算后得到更新后的参数 theta_i,则私有化处理本地差异:delta_i:=(1/eta)(theta_i-theta_0),delta_i 为随机梯度映射,其中的按步长的缩放实现一致的预期更新量。执行下面的处理:
![]()
M 为私有化处理机制,是对于 delta_i 的无偏(私有)视角估计。考虑平均梯度映射:
![]()
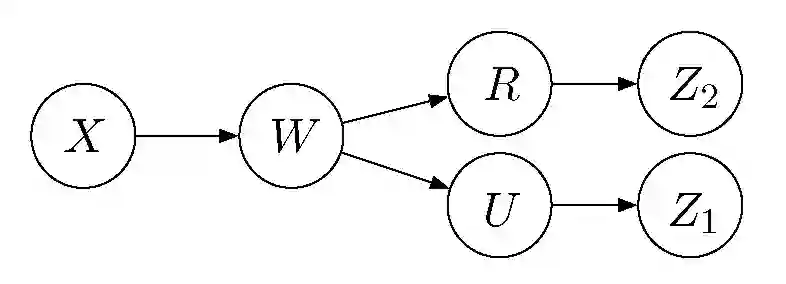
其中的投影操作 proj 限制任何单个更新的贡献,向量 Z~N(0,sigma.^2)是高斯分布的且能提供集中的隐私保证,具体表示为 sigma.^2。本文提出的隐私机制主要应用是最小最大化速率最优的私有(分布式)统计学习场景。对于本地私有模型拟合,梯度或影响函数的大小估计非常具有挑战性,此外更新的规模也是至关重要的。通过私有化数据对 (U,R) 的方式传输随机映射 W:方向为 U=W/||W||_2、大小为 R=||W||_2。令 Z_1=M_1(U) 以及 Z_2=M_2(R) 为 W 的私有化形式,见图 1:
![]()
图 1. 数据 X 与私有对 (Z1,Z2) 之间的马尔可夫图形结构.
差分私有信道的基本组成特性保证了 M=(M1,M2) 是 (epsilon1+epsilon2)-本地差分私有的,这种机制保证差分私有算法的组隐私、后处理以及组合保护的好处,从而实现上面提到的重建保护。
影响联邦学习效率的一个关键指标是模型的更新 delta 的精度,通常该值为随机梯度 delta l(theta;x) 的计算结果。本文专门考虑了两种情况下更新准确度的情况,包括:欧式距离情况(对输入单位向量 u 进行重采样,从 L_2 阴影球形中均匀选择),以及在高维估计优化问题中常见的非欧氏距离的情况(私有化向量到 L_Infinity)。欧氏距离和高维的私有化过程分别见算法 1 和算法 2。
![]()
![]()
本文对无偏向量释放处理机制的最后一个操作是将 r∈[0,r_max] 的情况释放扩展为 r<Infinity。本文具体介绍了两种方法:一是均方误差阶次最优尺度的随机响应机制,另一种是能够获得更好的相对误差保证的机制。具体见算法 3。
![]()
至此,本文提出的私有向量采样机制介绍完毕。对于风险优化函数,本文提出一种随机梯度下降优化过程,首先利用单独的机制私有化每个随机梯度 delta l(theta,X),该方法是 epsilon-差分私有的。令 epsilon_1+epsilon_2=epsilon,其中 epsilon_1 表示方向的私有化程度,epsilon_2 表示大小的私有化程度。针对 epsilon_1,应用算法 1 和算法 3 分别对 epsilon_1 和 epsilon_2 进行私有化处理,最终得到 epsilon-差分私有机制 w 如下:
![]()
令 Z(theta;x):=M(delta l(theta;x)),私有化随机梯度优化过程重复下式:
![]()
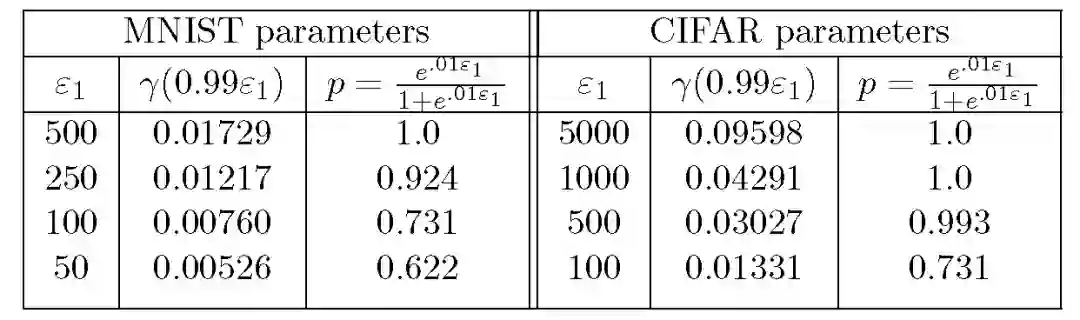
本文实验使用算法 1 和算法 3 中的私有化处理机制:
![]()
epsilon_2 设置为 10,这样相对于 PrivUnit2 中的采样误差,epsilon_2 对最终误差的贡献可以忽略不计。
本文实验目的是验证采用隐私保护机制的联邦学习方法是否能够提供与经典联邦学习类似的学习效果。实验图中给出了当前模型参数与经典方法得到的模型最优参数的对比。
![]()
实验参数:对于给定的隐私等级 epsilon,实验参数如下
![]()
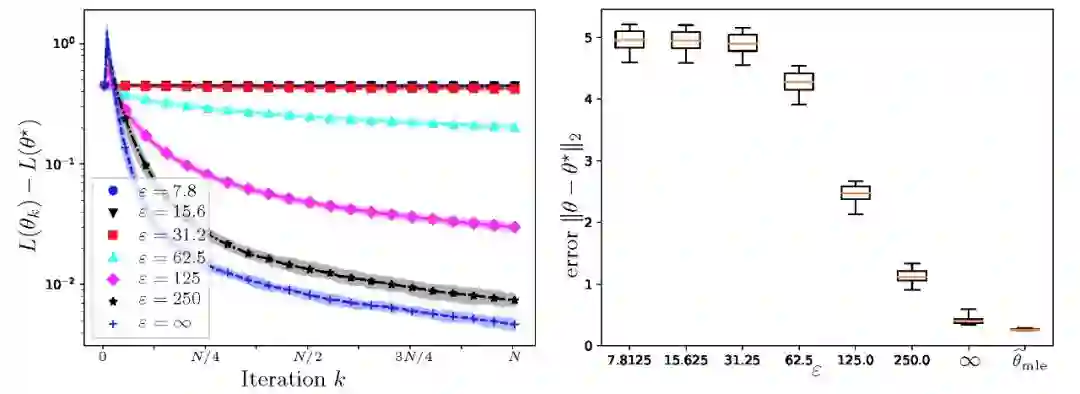
实验结果:具体实验结果见图 2 所示。其中左图给出私有随机梯度法的误差,正如上文所分析,私有随机梯度法对这个问题是(极大极小)最优的。随着 epsilon 值变大,实验效果逐渐接近于非私有化处理的经典随机梯度估计方法。右图给出随机梯度方法和非私有最大似然估计的误差方框图。
![]()
【MNIST】模型:6 层卷积神经网络(TensorFlow,经典优化算子)。实验结果见表 1。图 3(a)中给出 20 次实验的标准误差图。
【CIFAR10】模型:6 层卷积神经网络(TensorFlow,Adam 优化算子)。实验结果见表 1。图 3(b)中给出 20 次实验的标准误差图。
表 1. 随机初始化训练 6 层 CNNS 的实验参数.
![]()
![]()
图 3. 隐私保护联邦学习(由隐私参数ε1 索引)与非隐私保护模型更新的图像分类准确度比较.
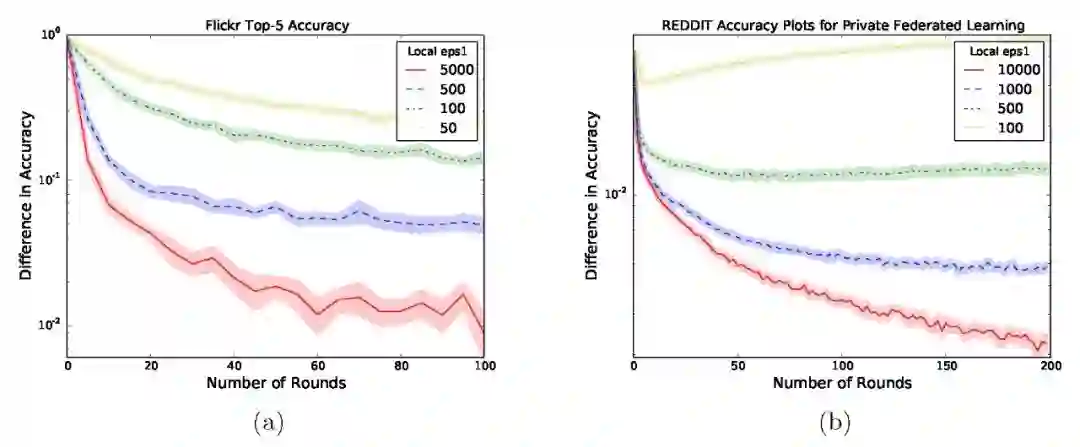
ImageNet预训练 ResNet50v2 网络 [5]。在 Flickr 语料库的子集上针对 100 个类别的分类任务,利用预训练的 ResNet 模型再次进行模型训练。图 4(a) 给出了联邦学习和本文方法在 12 次实验中的标准错误之间的准确度差异。
【Wikipedia 新词预测】预训练 LSTM。在 Reddit 网站上所有用户评论的语料库中引用经过预训练的 LSTM,再次使用 NLTK 标记过程。图 4(b) 给出了联邦学习和本文方法在 20 次实验中的标准错误之间的准确度差异。
![]()
Fig. 4. 隐私联邦学习方法(用相应的ε1 参数标记 SDP)和各种隐私参数ε以及清晰模型更新的联邦学习(标记 clear)预训练准确度比较
总结与分析
本文针对大规模分布式模型拟合及联邦学习问题,提出了一种差异性隐私保护方法。本文分析了对手的先验可信度和重建概率,从而证明了在较大 epsilon 取值情况下的隐私情况以及不同机制提供的隐私保护类型是非常重要的。由本文的分析和实验结果可知,进一步分析隐私屏障以及在不同层面上提供不同类型的保护手段等,对于解决实际应用中的隐私保护问题是非常有意义的。
[1] Tian Li, et al.「Federated Learning: Challenges, Methods, and Future Directions,」https://arxiv.org/abs/1908.07873, 2019.
[2] H. B. McMahan, et al.「Communication-efficient learning of deep networks from decentralized data,」in Proc. of the International Conference on Artificial Intelligence and Statistics, 2017.
[3] J. Konecn´y, et al.「Federated learning: Strategies for improving communication efficiency,」NIPS 2016.
[4] Thibaux, R. and Jordan, M. I.「Hierarchical Beta processes and the Indian buffet process,」In Artificial Intelligence and Statistics , pp. 564–571, 2007.
[5] T. Lee. Tensornets. https://github.com/taehoonlee/tensornets, 2018.
作者介绍:仵冀颖,工学博士,毕业于北京交通大学,曾分别于香港中文大学和香港科技大学担任助理研究员和研究助理,现从事电子政务领域信息化新技术研究工作。主要研究方向为模式识别、计算机视觉,爱好科研,希望能保持学习、不断进步。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com