仅3.9MB!超小超强文本识别模型来了,平安产险提出Hamming OCR
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达

极市导读
最近,Hamming OCR提出了Hamming Embedding和LSH局部敏感哈希分类算法。它能在保留模型能力的同时,大幅度削减场景文本识别中所需模型的大小。
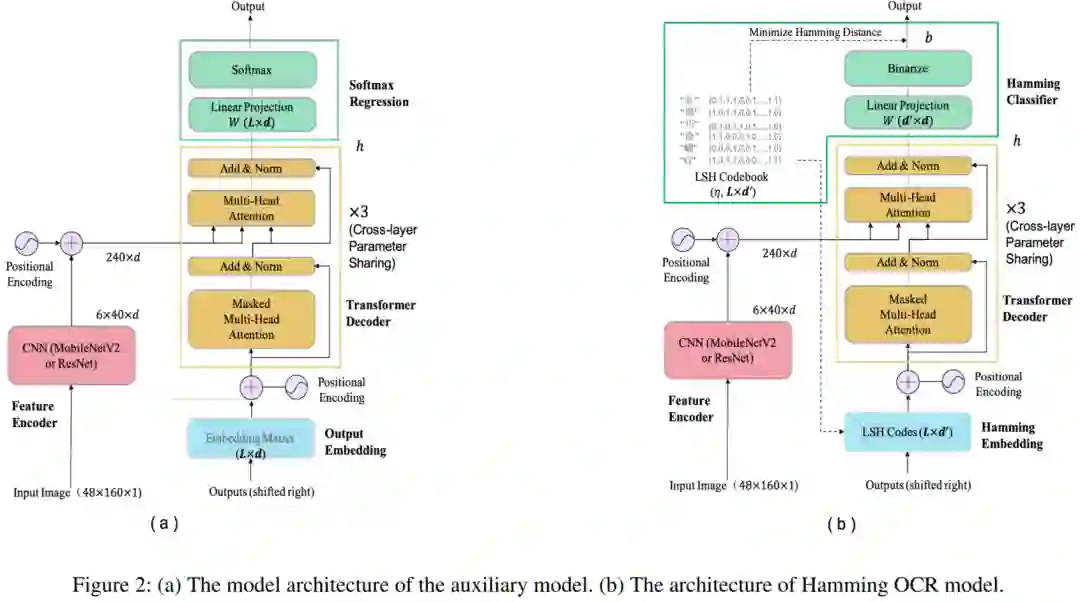
Hamming OCR 是一个基于Transformer注意力的超轻量级文本识别模型,主要基于LSH局部敏感哈希编码和Max-Margin Loss的学习算法。
Hamming OCR: A Locality Sensitive Hashing Neural Networkfor SceneText Recognition

背景
场景文本识别中很多模型都使用了笨重的模型,这些模型很难在移动端设备上部署。这也是最近大火的Paddle OCR使用CRNN实现其超轻量级识别模型的原因。PaddleOCR采用的策略就是暴力削减特征通道来减小模型,但是这样使得性能大幅度下降。最近在arXiv上公开的Hamming OCR提出了Hamming Embedding和LSH局部敏感哈希分类的算法,大幅度削减模型大小,同时保留模型能力。
简介
我们首先看FC+softmax分类层:
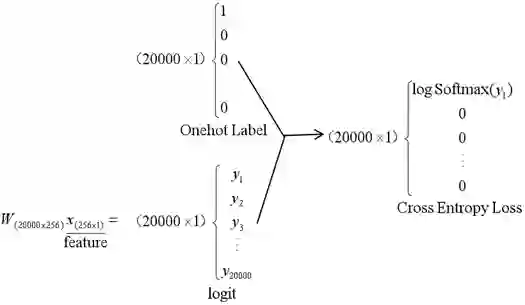
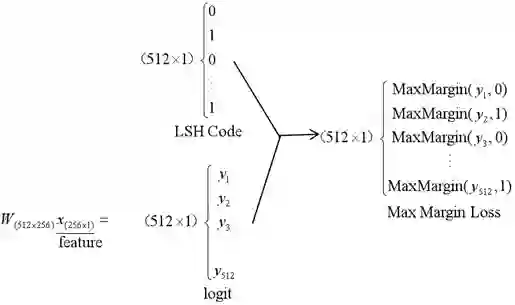
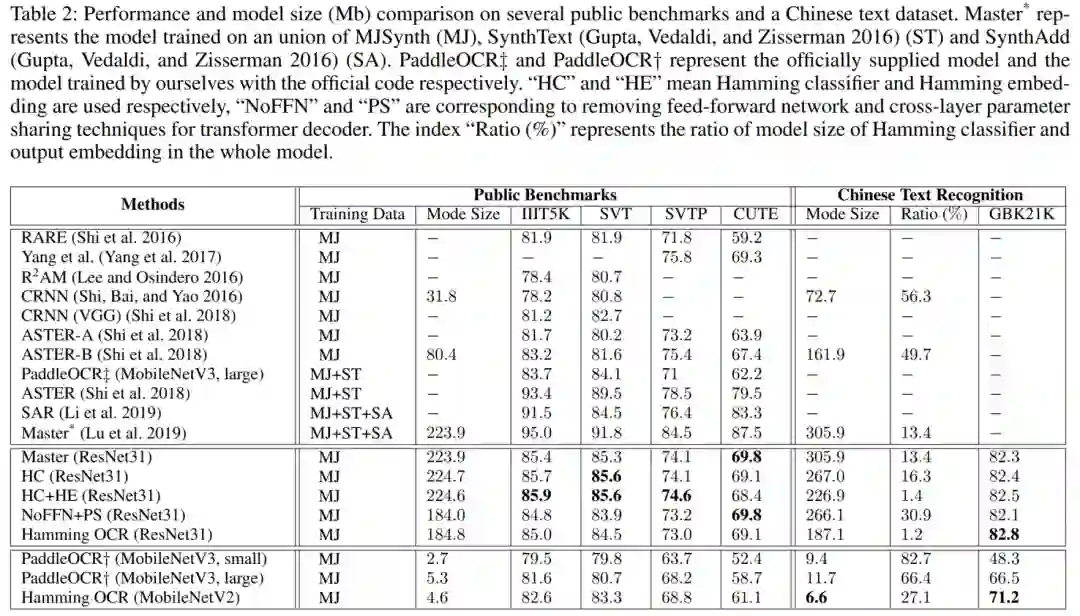

结论
作者团队
参考文献
1. Lu, N.; Yu,W.; Qi, X.; Chen, Y.; Gong, P.; and Xiao, R. 2019. Master: Multi-aspectnon-local network for scene text recognition. arXiv preprint arXiv:1910.02562.
2. Li, H.;Wang, P.; Shen, C.; and Zhang, G. 2019. Show, attend and read: A simple andstrong baseline for irregular text recognition. In Proceedings of the AAAIConference on Artificial Intelligence, volume 33, 8610–8617.
3. Shi, B.;Bai, X.; and Yao, C. 2016. An end-to-end trainable neural network forimage-based sequence recognition and its application to scene text recognition.IEEE transactions on pattern analysis and machine intelligence 39(11):2298–2304.
4. Lan, Z.;Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; and Soricut, R. 2019. Albert: Alite bert for selfsupervised learning of language representations. arXiv preprintarXiv:1909.11942 .
下载1:动手学深度学习
在CVer公众号后台回复:动手学深度学习,即可下载547页《动手学深度学习》电子书和源码。该书是面向中文读者的能运行、可讨论的深度学习教科书,它将文字、公式、图像、代码和运行结果结合在一起。本书将全面介绍深度学习从模型构造到模型训练,以及它们在计算机视觉和自然语言处理中的应用。

下载2:CVPR / ECCV 2020开源代码
在CVer公众号后台回复:CVPR2020,即可下载CVPR 2020代码开源的论文合集
在CVer公众号后台回复:ECCV2020,即可下载ECCV 2020代码开源的论文合集
重磅!CVer-论文写作与投稿交流群成立
扫码添加CVer助手,可申请加入CVer-论文写作与投稿 微信交流群,目前已满2300+人,旨在交流顶会(CVPR/ICCV/ECCV/NIPS/ICML/ICLR/AAAI等)、顶刊(IJCV/TPAMI/TIP等)、SCI、EI、中文核心等写作与投稿事宜。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如论文写作+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加微信群

▲长按关注CVer公众号
整理不易,请给CVer点赞和在看!


