深度序列学习助力文字识别
此篇文章属于微信OCR技术介绍系列,着重介绍如何采用深度序列学习(deep sequence learning)方法实现端到端的文本串识别并应用于微信产品。这里,文本串识别的输入默认已经是包含文本(行或者单词)的最小外接矩形框,其目的是识别其中的文字内容,如图1所示。前面的文本框检测和定位工作,详见我们之前的文章【1】介绍。

图1:文本串识别示例
分 阶 段 vs 端 到 端
文本串识别作为目标识别的一个子领域,其本质是一个多类分类问题:旨在寻找从文本串图像到文本串内容的一种映射,这和人脸识别、车辆识别等都是类似的。然而,文本串作为序列目标,又有其独特性:
1. 局部性:即文本串中的局部都会直接体现在其整体label中。举个栗子:“我想吃饭”和“我不想吃饭”,一字之差,体现在图像特征中,只是局部特征变化,然而文本串的含义截然相反。而在一般的目标识别问题中(细粒度目标识别除外),这种局部干扰恰恰是要被抑制的。比如,张三带了墨镜还是张三。
2. 组合性:文本串内容千差万别,以常用英文单词为例,约有9w多个。汉字的组合就更加庞大了。然而不管是万字长文,还是简短对话,它们的组成都是有限种类的字符:26个英文字母,10个数字,几千个汉字,诸如此类。
基于以上两点,一种直观的串识别方法是:首先切分到单字,识别单字的类别,然后将识别结果串联起来。这种化整为零的方法是OCR在深度学习出现之前的几十年里通用的方法,其流程如图2所示。

图2:根据各种图像特征进行单字切分
然而,这个方法有两个明显的弊端:1. 切分错误会影响识别性能;2. 单字识别未能考虑上下文信息。为了弥补这两点缺陷,传统方法往往需要对图像进行“过切分”,即找到所有可能是切点的位置,然后再将所有切片和可能的切片组合统统送给单字识别模块,通过在各个识别结果中间进行“动态规划”,寻找一条最优路径,从而确定切分和识别的结果。在寻优过程中,往往还需要结合文字的外观统计特征以及语言模型(若干字的同现概率)。可见,这里切分、识别和后处理存在深度耦合,导致实际系统中的串识别模块往往堆砌了非常复杂和可读性差的算法。而且,即便如此,传统方法依然有不可突破的性能瓶颈,比如一些复杂的艺术体和手写体文字,严重粘连的情况等等。总而言之,传统方法的问题在于:处理流程繁琐冗长导致错误不断传递,以及过分倚重人工规则并轻视大规模数据训练。
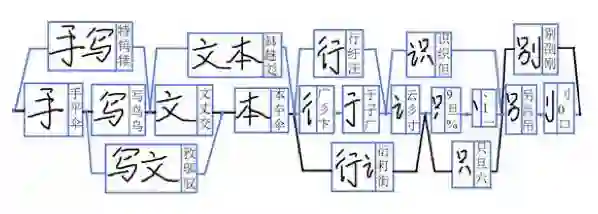
图3:基于过切分和动态规划得到文本串内容
从2012 年的ImageNet竞赛开始,深度学习首先在图像识别领域发挥出巨大威力。随着研究的深入,深度学习逐渐被应用到音频、视频以及自然语言理解领域。这些领域的特点是针对时序数据的建模。如何利用深度学习来进行端到端的学习,并摒弃基于人工规则的中间步骤,以提升Sequence Learning的效果已经成为当前研究的热点。基本思路是CNN与RNN结合:CNN被用于提取有表征能力的图像特征,而RNN天然适合处理序列问题,学习上下文关系。这种CNN+RNN的混合网络从本质上革新了文本串识别领域的研究。
CRNN:CNN+RNN+CTC
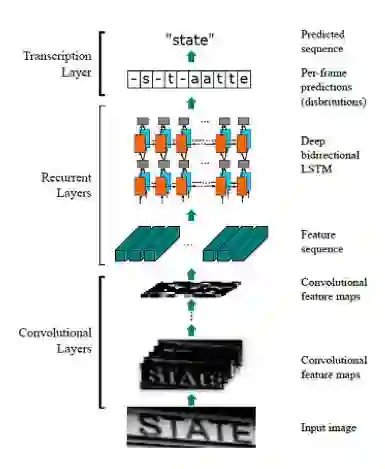
图4:CRNN实现端到端的文本串识别
CRNN目前在串识别领域非常成功的模型。在我们之前的文章中也对其进行过介绍【2】。模型前面的CNN部分,将图像进行空间上的保序压缩,相当于沿水平方向形成若干切片,每个切片对应一个特征向量。由于卷积的感受野会相互重叠,这类特征本身就包含了一定的上下文关系。接下来的RNN部分,采用双层双向的LSTM,进一步学习上下文特征,据此得到切片对应的字符类别。最后的CTC层设计了一种结构化损失,通过引入空白类和映射法则模拟了动态规划的过程。CRNN在图像特征和识别内容序列之间是严格保序的,极其擅长识别字分割比较困难的文字序列,甚至包括潦草的手写电话号码。此外,这一序列学习模型还使得训练数据的标注难度大为降低,便于收集更大规模的训练数据。
转自:微信AI
完整内容请点击“阅读原文”



