OCR技术浅析
OCR(Optical Character Recognition,光学字符识别)的概念早于1920年代便被提出,一直是模式识别领域中重要的研究方向。
近年来,随着移动设备的快速更新迭代,以及移动互联网的快速发展,使得OCR有更为广泛的应用场景,从以往的扫描文件的字符识别,到现在应用到自然场景中图片文字的识别,如识别身份证、银行卡、门牌、票据及各类网络图片中的文字。

以深度学习兴起的时间为分割点,直至近五年之前,业界最为广泛使用的仍然是传统的OCR识别技术框架,而随着深度学习的崛起,基于这一技术的OCR识别框架以另外一种新的思路迅速突破了原有的技术瓶颈(如文字定位、二值化和文字分割等),并已在工业界得到广泛应用。
笔者针对业务中的身份证照片文字识别需求分别尝试了传统OCR识别框架及基于深度学习的OCR识别框架。下面就以身份证文字识别为例分别简要介绍两种识别框架。
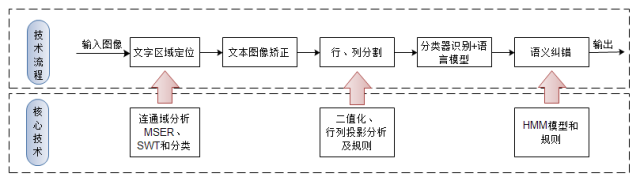
如上图所示,传统OCR技术框架主要分为五个步骤:
首先文本定位,接着进行倾斜文本矫正,之后分割出单字后,并对单字识别,最后基于统计模型(如隐马尔科夫链,HMM)进行语义纠错。可按处理方式划分为三个阶段:预处理阶段、识别阶段和后处理阶段。其中关键在于预处理阶段,预处理阶段的质量直接决定了最终的识别效果,因此这里详细介绍下预处理阶段。
预处理阶段中包含了三步:
定位图片中的文字区域,而文字检测主要基于连通域分析的方法,主要思想是利用文字颜色、亮度、边缘信息进行聚类的方式来快速分离文字区域与非文字区域,较为流行的两个算法分别是:最大极值稳定区域(MSER)算法及笔画宽度变换(SWT)算法,而在自然场景中因受到光照强度、图片拍摄质量和类文字背景的干扰,使得检测结果中包含非常多的非文字区域,而目前从候选区域区分出真正文字区域主要两种方法,用规则判断或轻量级的神经网络模型进行区分;
文本区域图像矫正,主要基于旋转变换和仿射变换;
行列分割提取出单字,这一步利用文字在行列间存在间隙的特征,通过二值化并在投影后找出行列分割点,当在文字与背景的区分度较好时,效果很好,而拍摄的图片中光照、摄像质量的影响,并且文字背景难以区分时,常造成错误分割的情况。
下面介绍基于传统OCR框架处理身份证文字识别:
身份证识别技术流程与上述框架稍微有所差异。对该问题,已知先验信息:a.证件长宽固定;b.字体及大小一致;c.文本相对于证件位置固定;d.存在固定文字。因此,处理该问题的思路为:先定位目标物体(证件),矫正后提取文字进行识别,最后进行语义纠错,如下图:

目标物体定位并矫正。基于现有的先验信息,定位最后的方法为采用模板关键点特征匹配的方法,并利用模板上特征点及目标图像特征点坐标之间的关系进行透视变换,以定位目标物体,如下图所示。接着,基于四角的坐标,进行旋转、仿射、尺寸的变换,并提取出目标物体的俯视图。

因文字位置相对固定,接着便分割出文字区域,二值化后,行列分割出单个字符。这里的技术难点在于二值化,二值化效果的好坏直接影响字符分割,并最终影响识别结果。受光照和拍摄质量的影响,全局二值化难以设置统一的阈值,而自适应二值化算法易受到阴影及模糊边界的干扰。所以在这边尝试过许多方法,测试下来未发现在任何情形下效果都满足要求的方法。
分割出单字后接着用分类器进行识别,并在这步基于统计上的先验信息定义了一个简单的优化函数,可看做1-gram语言模型。先验信息为:2400(总共660273)汉字的使用频率之和为99%以上。定义的优化函数为:
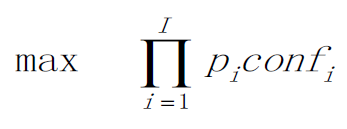
式中,Pi为该字出现的概率,confi为置信度值。
下图给出了示例:

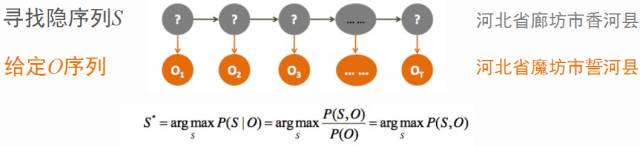
因上述的优化过程中假定各状态相互独立并与上一状态没有联系,故不可避免存在语义上的错误。而如何基于现有的输出序列,对序列进行语义上的修正,那么最直观的想法就是用隐马尔可夫模型(Hidden Markov Model,HMM)解决这个问题,其基于观察序列,求出最优隐序列。其可以抽象为如下图的过程。在给定O序列情况下,通过维特比算法,找出最优序列S:
传统OCR冗长的处理流程以及大量人工规则的存在,使得每步的错误不断累积,而使得最终识别结果难以满足实际需求。接下来讨论基于深度学习的OCR。
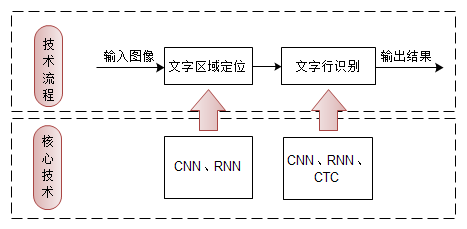
目前,从技术流程上来说,主要分为两步,首先是检测出图像中的文本行,接着进行序列识别。可见,基于深度学习的OCR识别框架相比于传统OCR识别框架,减少了三个步骤,降低了因误差累积对最终识别结果的影响。
文本行检测,其又可分为水平行文字检测算法与倾斜文字行检测算法。这里主要介绍下Tian提出算法CTPN,其算法框架如下图。主要思路是将文本行识别看做一个序列识别问题,不同于一般的目标检测问题,引入RNN来利用上下文的信息。
转自:拍黑米
完整内容请点击“阅读原文”




