超越SENet!清华/港科大和MSRA提出:GCNet 一种新的全局上下文建模网络,已开源!
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

本文转载自:机器之心
作者:Yue Cao、Jiarui Xu、Stephen Lin、Fangyun Wei、Han Hu
近年来,注意力模型以其强大的建模能力受到了广泛地研究与关注。基于注意力模型,来自清华、港科大、微软亚研院的研究者们提出了一种新的全局上下文建模网络(Global Context Network,简称 GCNet),此网络同时吸取 Non-local Network 全局上下文建模能力强与 Squeeze-Excitation Network 计算量低的优点,在目标检测、图像分类与动作识别等基础任务中,在计算量几乎无增加的情况下准确度取得显著提升。

论文地址:https://arxiv.org/abs/1904.11492v1
代码地址:https://github.com/xvjiarui/GCNet
建模远程依赖(long-range dependency)旨在加强学习过程中对视觉场景的全局理解,且被证明会对广泛的识别任务有益。在卷积神经网络中,卷积层主要作用于局部区域,由此远程依赖仅能通过堆叠多层卷积层进行建模,但多个卷积层的堆叠不仅计算量大,且难以优化。
为解决这个问题,Non-local Network(NLNet)使用自注意力机制来建模远程依赖。对于每个查询点(query position),NLNet 首先计算查询点与所有点之间的成对关系以得到注意力图(attention map),然后通过加权和的方式聚合所有点的特征,从而得到与此查询点相关的全局特征,最终再分别将全局特征加到每个查询点的特征中,完成远程依赖的建模过程。
为了深入理解 NLNet,在目标检测任务中,作者为每张图选取多个查询点,对其注意力图进行可视化,如下图所示:

但从图中惊讶地发现,不同的查询点得到的注意力图几乎一样。经过统计分析后,这一可视化观察在目标检测任务与视频动作识别任务中均被验证。由此,作者对 NLNet 进行简化,使其对不同的查询点计算相同的注意力图,使得其计算量大幅度下降,并发现其准确度并无下降,这再次验证了之前的观察。
此外,作者发现这个简化版的 NLNet 与流行的 Squeeze-Excitation Network(SENet)具有相似的结构。作者将他们抽象为一个通用的全局上下文建模框架,主要分为以下三个模块:(a)上下文建模模块,它将所有位置的特征聚合在一起形成一个全局上下文特征;(b)特征转换模块,用于捕获通道间的相互依赖性;(c)融合模块,将全局上下文特征与所有位置的特征进行融合。其中简化版的 NLNet 与 SENet 均是此全局上下文建模框架的实例。
通过对每个步骤的比较研究,作者发现简化版的 NL Block 和 SE Block 都有各自的缺陷,通过结合每个步骤的最佳实现,即吸收了简化版的 NL Block 全局上下文建模能力强与 SENet 计算量低的优点,作者实现了一种新实例,称为全局上下文模块(Global Context Block)。下图展示了全局上下文建模框架 (a)、简化版 NL Block (b)、SE Block (c),以及在本文提出的 GC Block (d):
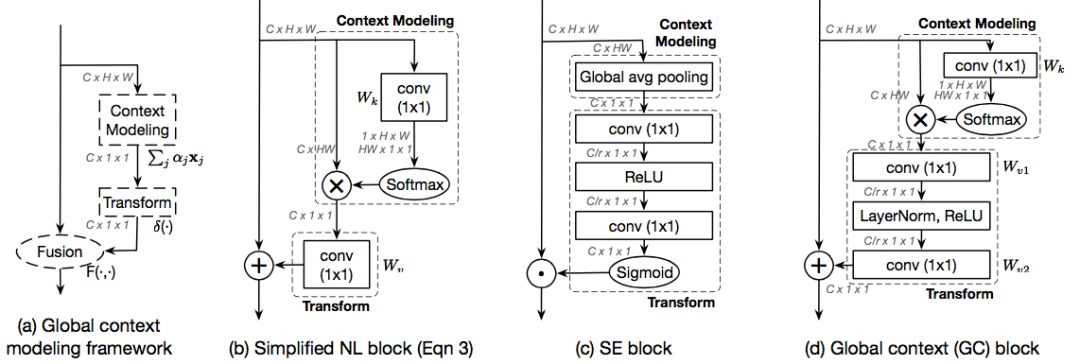
由于提出的 GC Block 是非常轻量级的,由此可以被应用于多层的多个残差模块中(一般被应用于 ResNet 的 c3~c5 层中),且仅会提升非常少的计算量(小于 0.3%),由此将 GC Block 应用到多层即可得到论文中提出的全局上下文建模网络(GCNet)。
下面将介绍论文中的一些主要结果:
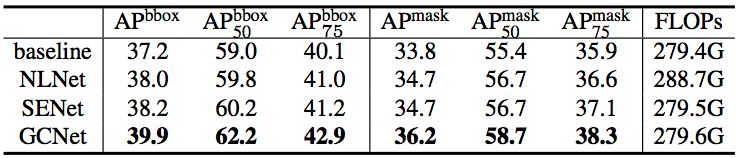
a) 在 COCO 目标检测任务中,以 Mask RCNN&R50&FPN 为 baseline 的结果比较:
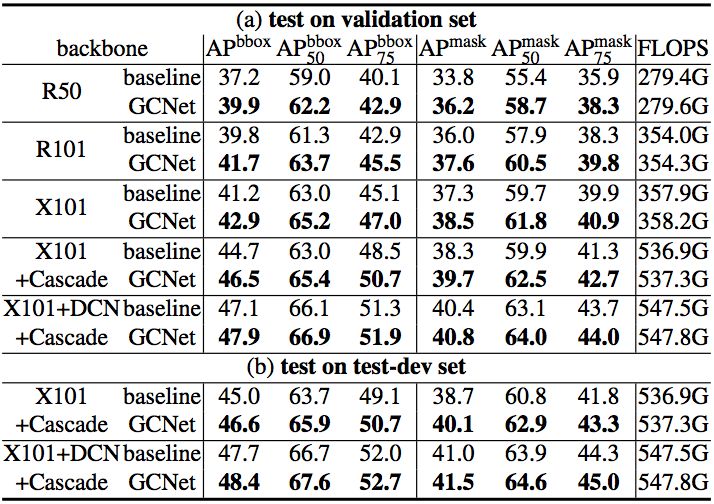
b) 以 Mask RCNN&FPN 为 baseline 的不同 backbone 的结果比较:
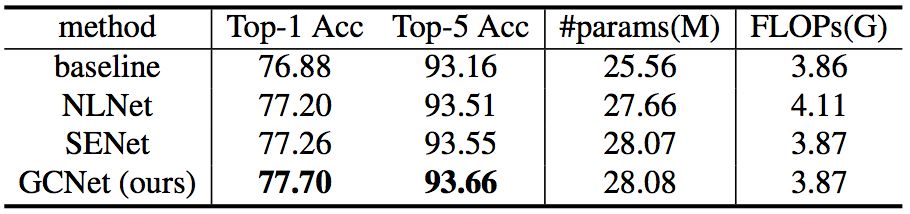
c) 在 ImageNet 图像分类任务中,以 Res50 为 baseline 的结果比较:
d) 在 Kinetics 动作识别任务中,以 Slow-Only&Res50 为 baseline 的结果比较:

CVer学术交流群
扫码添加CVer助手,可申请加入CVer-目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、人群密度估计、姿态估计、强化学习和竞赛交流等群。一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡),不根据格式申请,一律不通过。

▲长按加群
这么硬的论文分享,麻烦给我一个在在看

▲长按关注我们
麻烦给我一个在看!


