ICCV 2019 将在10月27于韩国首尔举行,本文作者介绍了一篇Oral论文,它利用EM 算法优化注意力机制,并在语义分割等任务上获得更好的效果。
本文介绍笔者被 ICCV 2019 接受为 Oral 的论文 Expectation-Maximization Attention Networks for Semantic Segmentation[1]。论文作者为:李夏、钟之声、吴建龙、杨一博、林宙辰、刘宏。
![]()
语义分割是计算机视觉领域的一项基础任务,它的目标是为每个像素预测类别标签。由于类别多样繁杂,且类间表征相似度大,语义分割要求模型具有强大的区分能力。近年来,基于全卷积网络(FCN[2])的一系列研究,在该任务上取得了卓越的成绩。
这些语义分割网络,由骨干网络和语义分割头组成。全卷积网络受制于较小的有效感知域,无法充分捕获长距离信息。为弥补这一缺陷,诸多工作提出提出了高效的多尺度上下文融合模块,例如全局池化层、Deeplab[3] 的空洞空间卷积池化金字塔、PSPNet[4] 的金字塔池化模块等。
近年来,自注意力机制在自然语言处理领域取得卓越成果。Nonlocal[5] 被提出后,在计算机视觉领域也受到了广泛的关注,并被一系列文章证明了在语义分割中的有效性。它使得每个像素可以充分捕获全局信息。然而,自注意力机制需要生成一个巨大的注意力图,其空间复杂度和时间复杂度巨大。其瓶颈在于,每一个像素的注意力图都需要对全图计算。
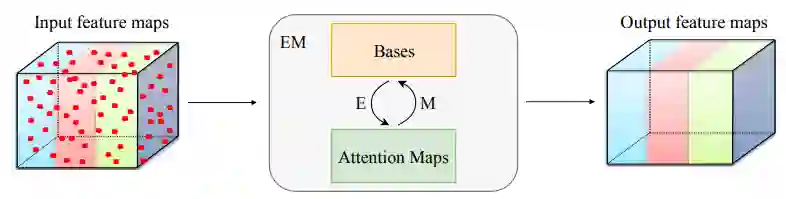
本文所提出的期望最大化注意力机制(EMA),摒弃了在全图上计算注意力图的流程,转而通过期望最大化(EM)算法迭代出一组紧凑的基,在这组基上运行注意力机制,从而大大降低了复杂度。其中,E 步更新注意力图,M 步更新这组基。E、M 交替执行,收敛之后用来重建特征图。本文把这一机制嵌入网络中,构造出轻量且易实现的 EMA Unit。其作为语义分割头,在多个数据集上取得了较高的精度。
![]()
期望最大化注意力
期望最大化(EM)算法旨在为隐变量模型寻找最大似然解。对于观测数据 X={x_1, x_2, …, x_N},每一个数据点 x_i 都对应隐变量 z_i。我们把 {X, Z} 称为完整数据,其似然函数为 ln p(X, Z|θ),θ 是模型的参数。
E 步根据当前参数θ^old 计算隐变量 Z 的后验分布,并以之寻找完整数据的似然 Q(θ, θ^old):
M 步通过最大化似然函数来更新参数得到θ^new:
EM 算法被证明会收敛到局部最大值处,且迭代过程完整数据似然值单调递增。
高斯混合模型(GMM)是 EM 算法的一个范例,它把数据用多个高斯分布拟合。其 θ_k 即为第 k 个高斯分布的参数μ_k, Σ_k,隐变量 z_nk 为第 k 个高斯分布对第 n 数据点的「责任」。E 步更新「责任」,M 步更新高斯参数。在实际应用中,Σ_k 经常被简化为 I。
非局部网络(Nonlocal[5])率先将自注意力机制使用在计算机视觉任务中。其核心算子是:
其中 f(., .) 表示广义的核函数,C(x) 是归一化系数。它将第 i 个像素的特征 x_i 更新为其他所有像素特征经过 g 变换之后的加权平均 y_i,权重通过归一化后的核函数计算,表征两个像素之间的相关度。这里 1<j<N,所以视为像素特征被一组过完备的基进行了重构。这组基数目巨大,且存在大量信息冗余。
期望最大化注意力机制由 A_E, A_M, A_R 三部分组成,前两者分别对应 EM 算法的 E 步和 M 步。假定输入的特征图为 ![]() ,基初始值为
,基初始值为 ![]() ,A_E 估计隐变量
,A_E 估计隐变量 ![]() ,即每个基对像素的权责。具体地,第 k 个基对第 n 个像素的权责可以计算为:
,即每个基对像素的权责。具体地,第 k 个基对第 n 个像素的权责可以计算为:
在这里,内核 K(a, b) 可以有多种选择。我们选择 ![]() 的形式。在实现中,可以用如下的方式实现:
A_M 步更新基 μ。为了保证μ和 X 处在同一表征空间内,此处μ被计算作 X 的加权平均。具体地,第 k 个基被更新为:
值得注意的是,如果λ趋向于无穷,则公式 (5) 中,{Z_n1, Z_n2, …, Z_nk} 会变成一组 one-hot 编码。在这种情形下,每个像素仅由一个基负责,而基被更新为其所负责的像素的均值,这便是标准的 K-means 算法。
A_E 和 A_M 交替执行 T 步。此后,近似收敛的μ和 Z 便可以被用来对 X 进行重估计得 X tilde:
X tilde 相比于 X,具有低秩的特性。从下图中可看出,其在保持类间差异的同时,类别内部差异得到缩小。从图像角度来看,起到了类似保边滤波的效果。
综上,EMA 在获得低秩重构特性的同时,将复杂度从 Nonlocal 的 O(N^2) 降低至 O(NKT)。实验中,EMA 仅需 3 步就可达到近似收敛,因此 T 作为一个小常数,可以被省去。至此,EMA 复杂度仅为 O(NK)。考虑到 k 远小于 N,其复杂度得到显著的降低。
的形式。在实现中,可以用如下的方式实现:
A_M 步更新基 μ。为了保证μ和 X 处在同一表征空间内,此处μ被计算作 X 的加权平均。具体地,第 k 个基被更新为:
值得注意的是,如果λ趋向于无穷,则公式 (5) 中,{Z_n1, Z_n2, …, Z_nk} 会变成一组 one-hot 编码。在这种情形下,每个像素仅由一个基负责,而基被更新为其所负责的像素的均值,这便是标准的 K-means 算法。
A_E 和 A_M 交替执行 T 步。此后,近似收敛的μ和 Z 便可以被用来对 X 进行重估计得 X tilde:
X tilde 相比于 X,具有低秩的特性。从下图中可看出,其在保持类间差异的同时,类别内部差异得到缩小。从图像角度来看,起到了类似保边滤波的效果。
综上,EMA 在获得低秩重构特性的同时,将复杂度从 Nonlocal 的 O(N^2) 降低至 O(NKT)。实验中,EMA 仅需 3 步就可达到近似收敛,因此 T 作为一个小常数,可以被省去。至此,EMA 复杂度仅为 O(NK)。考虑到 k 远小于 N,其复杂度得到显著的降低。
![]()
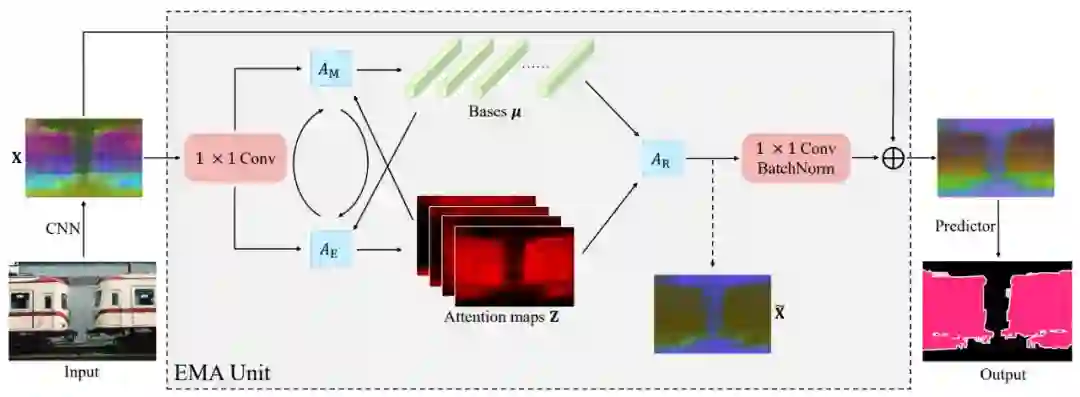
期望最大化注意力模块(EMAU)的结构如上图所示。除了核心的 EMA 之外,两个 1×1 卷积分别放置于 EMA 前后。前者将输入的值域从 R+映射到 R;后者将 X tilde 映射到 X 的残差空间。囊括进两个卷积的额外负荷,EMAU 的 FLOPs 仅相当于同样输入输出大小时 3×3 卷积的 1/3,参数量仅为 2C^2+KC。
对于 EM 算法而言,参数的初始化会影响到最终收敛时的效果。上一节中讨论了 EMA 如何在单张图像的特征图上进行迭代运算。而对于深度网络训练过程中的大量图片,在逐个批次训练的同时,EM 参数的迭代初值 ![]() 理应得到不断优化。本文中,迭代初值
理应得到不断优化。本文中,迭代初值 ![]() 的维护参考 BN 中 running_mean 和 running_std 的滑动平均更新方式,即:
其中,α∈[0,1] 表示动量;
的维护参考 BN 中 running_mean 和 running_std 的滑动平均更新方式,即:
其中,α∈[0,1] 表示动量;![]() 表示
表示 ![]() 在一个 mini-batch 上的平均。
此外,EMA 的迭代过程可以展开为一个 RNN,其反向传播也会面临梯度爆炸或消失等问题。此外,公式 (8) 也要求
在一个 mini-batch 上的平均。
此外,EMA 的迭代过程可以展开为一个 RNN,其反向传播也会面临梯度爆炸或消失等问题。此外,公式 (8) 也要求 ![]() 和
和 ![]() 的差异不宜过大,不然初值
的差异不宜过大,不然初值 ![]() 的更新也会出现不稳定。RNN 中采取 LayerNorm(LN)来进行归一化是一个合理的选择。但在 EMA 中,LN 会改变基的方向,进而影响其语义。因为,本文选择 L2Norm 来对基进行归一化。这样,
的更新也会出现不稳定。RNN 中采取 LayerNorm(LN)来进行归一化是一个合理的选择。但在 EMA 中,LN 会改变基的方向,进而影响其语义。因为,本文选择 L2Norm 来对基进行归一化。这样,![]() 的更新轨迹便处在一个高维球面上。
此处,我们可以考虑下 EMA 和 A2Net[6] 的关联。A2Net 的核心算子如下:
其中 θ, φ, ρ 代表三个 1×1 卷积,它们的参数分别为 W_θ、W_φ和 W_ρ。如果我们将θ和φ的参数共享,并将 W_θ和 W_φ记作 μ。那么,softmax(θ(X, W_θ)) 和公式 (5) 无异;而 [.] 内则在更新 μ,即相当于 A_E 和 A_M 迭代一次。因此,A2-Block 可以看作 EMAU 的特殊例子,它只迭代一次 EM,且 μ 由反向传播来更新。而 EMAU 迭代 T 步,用滑动平均来更新 μ。
的更新轨迹便处在一个高维球面上。
此处,我们可以考虑下 EMA 和 A2Net[6] 的关联。A2Net 的核心算子如下:
其中 θ, φ, ρ 代表三个 1×1 卷积,它们的参数分别为 W_θ、W_φ和 W_ρ。如果我们将θ和φ的参数共享,并将 W_θ和 W_φ记作 μ。那么,softmax(θ(X, W_θ)) 和公式 (5) 无异;而 [.] 内则在更新 μ,即相当于 A_E 和 A_M 迭代一次。因此,A2-Block 可以看作 EMAU 的特殊例子,它只迭代一次 EM,且 μ 由反向传播来更新。而 EMAU 迭代 T 步,用滑动平均来更新 μ。
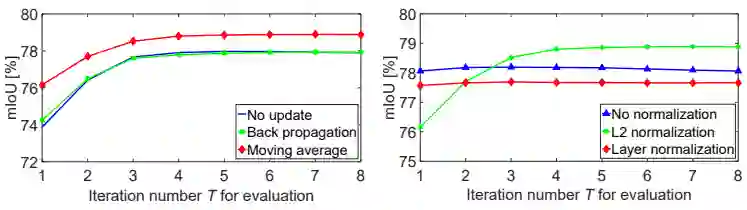
首先是在 PASCOL VOC 上的消融实验。这里对比了不同的 μ 更新方法和归一化方法的影响。
![]()
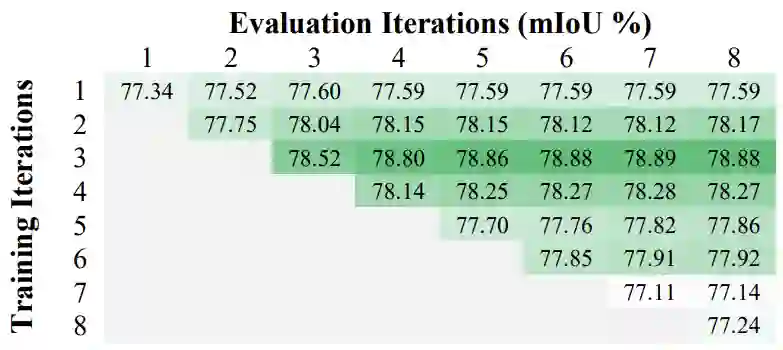
可以清楚地看到,EMA 使用滑动均值(Moving average)和 L2Norm 最为有效。作为对比,Nonlocal 和 A2Net 的模块作为语义分割头,在同样设置下分别达到 77.78% 和 77.34% 的分数,而 EMANet 仅迭代一次时分数为 77.34%,三者无显著差异,符合上文对 Nonlocal 和 A2Net 的分析和对比。接下来是不同训练和测试中迭代次数 T 的对比实验。
![]()
可以发现,EMA 仅需三步即可近似收敛(精度不再增益)。而随着训练时迭代次数的继续增长,精度有所下降,这是由 EMA 的 RNN 特性引起的。
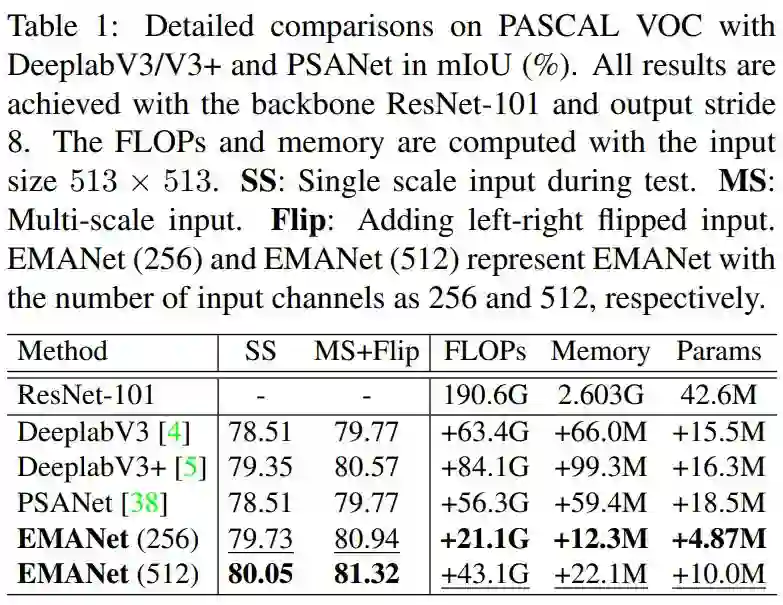
接下来,是 EMANet 和 DeeplabV3[3]、DeeplabV3+[7] 和 PSANet[8] 的详细对比。
![]()
可以发现,EMANet 无论在精度还是在计算代价上,都显著高于表中几个经典算法。
![]()
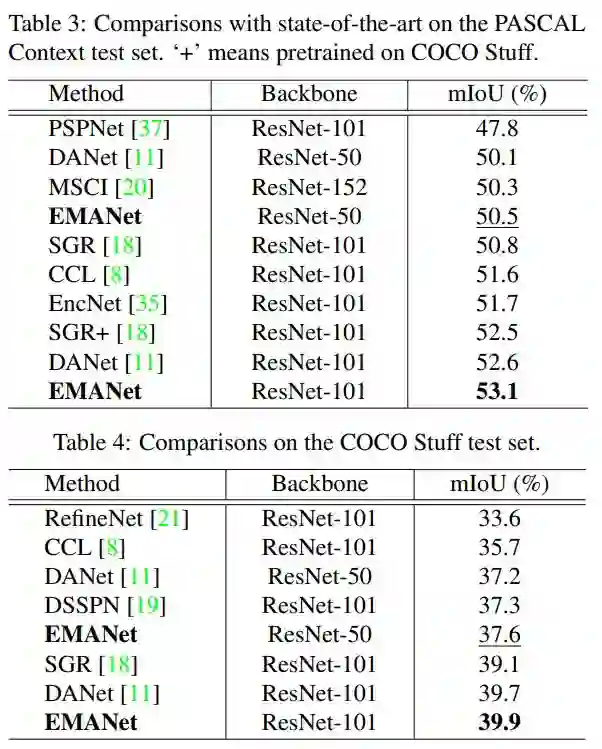
在 VOC test server 上,EMANet 在所有使用 ResNet-101 的算法中,取得了最高的分数。此外,在 PASCAL Context 和 COCO stuff 数据集上也表现卓越。
![]()
最后是学习到的注意力图的可视化。如下图,I,j,k,l 表示四个随机选择的基的下标。右边四列绘出的是它们各自对应的注意力图。可以看到,不同的基会收敛到一些特定的语义概念。
![]()
[1] Li, Xia, Zhong, Zhisheng, et al. " Expectation Maximization Attention Networks for Semantic Segmentation." Proceedings of the IEEE conference on computer vision. 2019.
[2] Long, Jonathan, Evan Shelhamer, and Trevor Darrell. "Fully convolutional networks for semantic segmentation." Proceedings of the IEEE conference on computer vision and pattern recognition. 2015.
[3] Chen, Liang-Chieh, et al. "Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs." IEEE transactions on pattern analysis and machine intelligence 40.4 (2017): 834-848.
[4] Zhao, Hengshuang, et al. "Pyramid scene parsing network." Proceedings of the IEEE conference on computer vision and pattern recognition. 2017.
[5] Wang, Xiaolong, et al. "Non-local neural networks." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018.
[6] Chen, Yunpeng, et al. "A^ 2-Nets: Double Attention Networks." Advances in Neural Information Processing Systems. 2018.
[7] Chen, Liang-Chieh, et al. "Encoder-decoder with atrous separable convolution for semantic image segmentation." Proceedings of the European conference on computer vision (ECCV). 2018.
[8] Zhao, Hengshuang, et al. "Psanet: Point-wise spatial attention network for scene parsing." Proceedings of the European Conference on Computer Vision (ECCV). 2018.
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com




 ,基初始值为
,基初始值为  ,A_E 估计隐变量
,A_E 估计隐变量  ,即每个基对像素的权责。具体地,第 k 个基对第 n 个像素的权责可以计算为:
,即每个基对像素的权责。具体地,第 k 个基对第 n 个像素的权责可以计算为:

 的形式。在实现中,可以用如下的方式实现:
的形式。在实现中,可以用如下的方式实现:



 理应得到不断优化。本文中,迭代初值
理应得到不断优化。本文中,迭代初值 
 表示
表示  在一个 mini-batch 上的平均。
在一个 mini-batch 上的平均。