业界 | 用于机器阅读理解的迁移学习:微软提出通用型SynNet网络
选自Microsoft Research Blog
作者:Xiaodong He
机器之心编译
参与:Smith、路雪
不是每个人都会下围棋,但大多数人都会阅读,然而 AI 并不是如此。AI 在围棋等领域中取得了非凡成就,但在执行阅读理解等简单任务时,却遭遇挑战,比如,如何将某特定领域的训练模型用于其他新领域,如何快速获取新领域的相关标注数据等。微软刚刚发布一条博客,介绍了一种新型迁移学习方法,可实现新领域中机器阅读理解系统(MRC)的快速构建。

对于人类而言,阅读理解是一项每天都在做的基本任务。我们在上小学的时候就可以阅读文章,回答有关文章中心思想和细节的相关问题。
然而对于 AI 来说,阅读理解仍然是一个难以达到的目标,但是如果我们想要评估并且完成通用人工智能,那么这将是我们必须解决的问题。事实上,阅读理解在很多真实场景中都是必需品,比如客户支持、推荐、问答、对话,以及客户关系管理。阅读理解也在很多场景中具备惊人的潜力,比如帮助医生从数千份文件中迅速找出重要信息,从而让他们有更充足的时间去做更有价值的工作,拯救更多病人。
因此,构建能够执行机器阅读理解(MRC)任务的机器是具有很大价值的。在搜索应用中,机器阅读将可以给出准确的答案,而不是仅提供一个包含答案的长篇网页的 URL 地址。此外,机器阅读模型也可以理解特定的不同细分领域文章中的某些知识,此种算法所依赖的搜索数据通常比较稀疏。
微软正聚焦于机器阅读,而且目前在业内占据着主导地位。微软的多个项目,包括用于机器理解力的深度学习(Deep Learning for Machine Comprehension),都瞄准了MRC 领域。尽管已经有了显著的进步,但如何在新领域中构建 MRC 系统这一关键问题却被一直忽略,直到最近才受到重视。
近期,来自微软研究院人工智能组的多名研究员 Po-Sen Huang、Xiaodong He 以及来自斯坦福大学的实习生 David Golub 开发出了一种迁移学习算法以解决该问题。他们的工作成果将在自然语言处理顶级会议 EMNLP 2017上进行呈现。此种可扩展算法是将 MRC 延伸到更宽广领域的关键。
这是微软向更远大目标前进的一个范例:创造更先进且更精密的技术。“我们不仅是开发一系列算法来解决理论问题,我们要用它们解决实际问题,并在实际数据上进行测试。” Rangan Majumder 在机器阅读博客中如此写道。
目前,多数顶尖机器阅读系统是在监督训练数据上(supervised training data)构建的,即在数据样本上进行端到端的训练,这些数据不仅包括文章,还包括手动标注的文章相关问题和对应答案。在这些样本的支持下,基于深度学习的 MRC 模型学着去理解问题,并且从文章中推断答案,该过程包括推理和推断的多个步骤。
但是,在很多领域或垂直方向中并不存在此类监督训练数据。例如,如果我们需要构建一个全新的机器阅读系统帮助医生查找某种新疾病的重要信息,我们可能得到大量的相关文件,但是我们缺少手动标注的相关问题和相应答案。为每种不同疾病分别构建 MRC 系统的需求和快速增长的文献体量大大增加了其挑战性。因此,解决如何将一个 MRC 系统迁移到新领域(缺乏手动标注问题及其答案)这一问题是非常重要的。
微软的研究员为解决该问题开发了一种名为“二级合成网络”(SynNet——https://www.microsoft.com/en-us/research/publication/two-stage-synthesis-networks-transfer-learning-machine-comprehension/)的新模型。SynNet 以某一领域中可用的监督数据为基础,首先在一篇文章中学习可识别潜在“有趣性认知”(potential “interestingness” )的一般模式,包括文章中可作为常见问题答案的关键知识点、命名实体或语义概念。一旦经过训练,SynNet 就可以应用到新的领域中,阅读新领域的相关文件,然后输出与文件相关的伪问题和答案。这种方式可以形成新领域下的 MRC 系统的必要训练数据,新领域可以是一种新的疾病、新公司的员工手册,或者一本新的产品手册。
生成综合数据以弥补训练数据不足的方法之前已经被探索过了。例如,关于翻译的目标性任务,Rico Sennrich 和同事在他们的论文中提出了一种方法:在给定真实语句的基础上生成合成型翻译,从而使现有的机器翻译系统得到改善。然而,与机器翻译不同,对于像机器阅读理解这一类的任务,我们需要将一篇文章中的问题和答案进行合成。此外,当问题是一个语法流利的自然语言语句的时候,答案也极有可能是文本中的重要语义概念,如命名实体、动作或者数字。由于答案有着与问题不同的语言结构,因此,把答案和问题看作两种不同类型的数据可能更为恰当。
在该方法中,我们把生成问题—答案对(question-answer pair)的过程分解成了两步:基于文本生成答案,以及基于文本和答案生成问题。我们之所以首先生成答案是因为答案通常是关键的语义概念,而问题则可以看作是用来对该概念进行询问的完整句子。
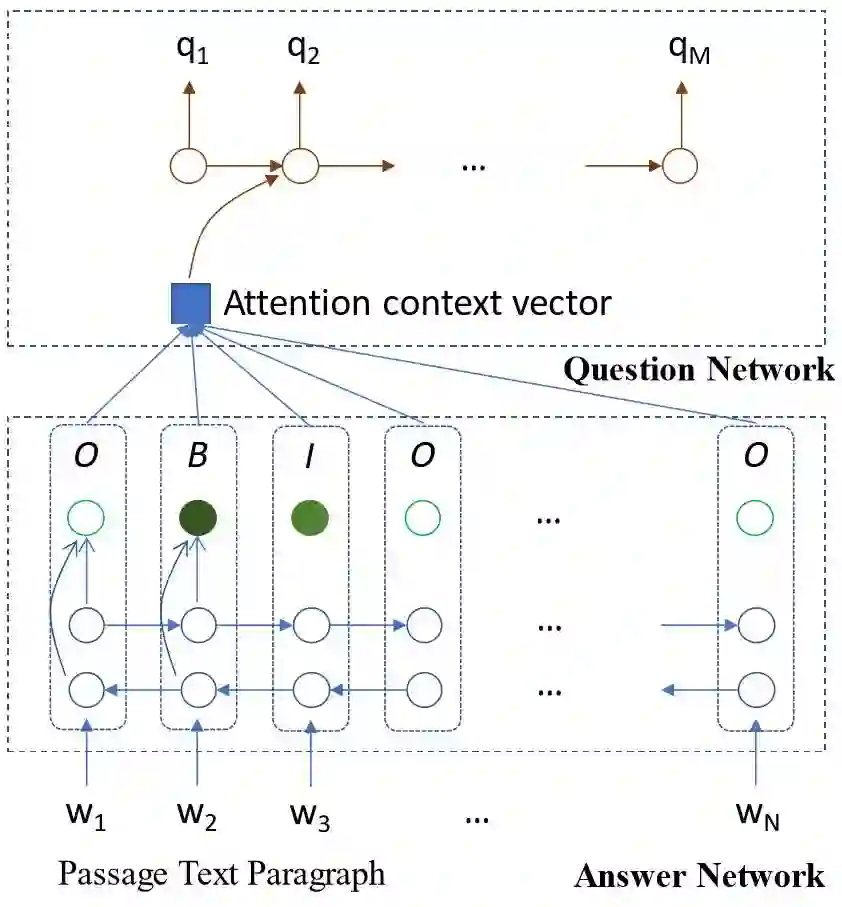
SynNet 被训练以用于合成给定文本的答案和问题。模型的第一阶段是答案合成模块,使用了一个双向 LSTM(long short-term memory)以在输入文本的基础上预测 IOB(inside-outside beginning)标记,从而标注出有可能是答案的关键语义概念。第二阶段是问题合成模块,使用了一个单向 LSTM 来生成问题,基于文本和 IOB ID对单词嵌入进行监督。尽管文本中的多种跨度可能会被识别为潜在的答案,然而在生成问题的时候,我们仅选取一个跨度。
下面是两个从文章中生成的问题和答案的实例:

使用 SynNet,我们能够在没有任何额外训练数据的新领域中得到更加精准的结果,其性能接近全监督 MRC 系统。
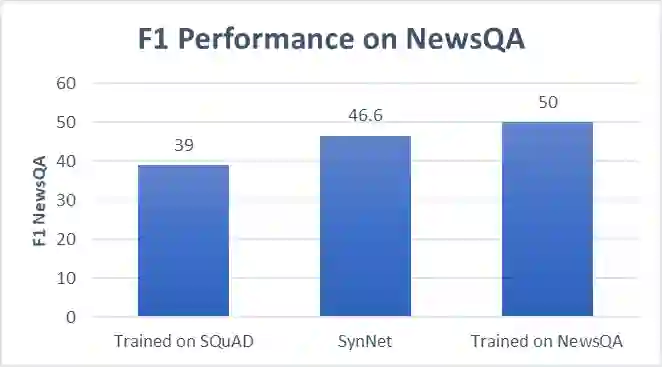
基于 SQuAD(维基百科上的文章)训练的 SynNet,其在 NewsQA(新文章)上的性能和在 NewsQA 上进行完全训练的系统几乎一样好。
SynNet 就像是一位教师,基于她先前的教学经验,从新领域的相关文章中提出问题和答案,并且使用这些材料来教她的学生执行新领域的相关阅读理解任务。因此,微软的研究人员也研发出了一套神经机器阅读模型,包括近期开发的ReasoNet(https://www.microsoft.com/en-us/research/publication/reasonet-learning-stop-reading-machine-comprehension/),该模型已经展现出了巨大潜力,它就像从教学材料中学习的学生,可以在基于文本的情况下回答问题。
据我们所知,这是第一次尝试应用 MRC 领域迁移。我们期待开发出可扩展的解决方案,以快速扩展 MRC 的能力,从而激发出机器阅读可改变行业格局的巨大潜力!

原文链接:https://www.microsoft.com/en-us/research/blog/transfer-learning-machine-reading-comprehension/
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com



