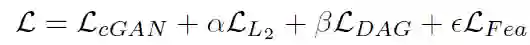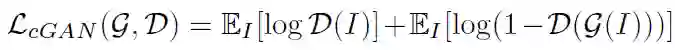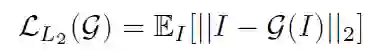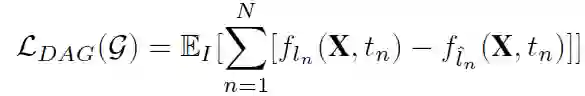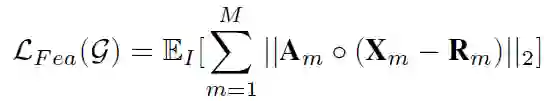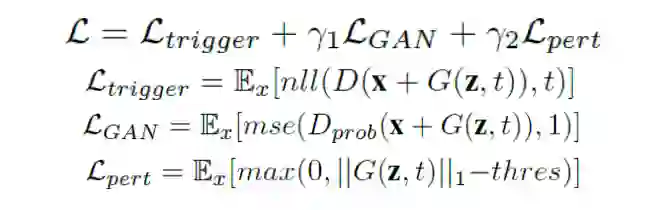机器之心原创
作者:Luo Sainan
编辑:Haojin Yang
IJCAI(国际人工智能联合会议)是人工智能领域中的顶级综合性会议,IJCAI2019 将于 8 月 10 日至 8 月 16 日在中国澳门举办,本次会议投稿量有 4752 篇,接收率为 17.88%。本文对 3 篇神经网络安全相关论文进行了介绍。
近年来,深度学习在计算机视觉任务中获得了巨大成功,但与此同时,神经网络的安全问题逐渐引起重视,对抗样本热度持续不下,神经网络后门攻击也悄然兴起。本文选取了 IJCAI2019 的 3 篇论文,从目标检测对抗攻击、实时对抗攻击、神经网络后门攻击三个方面,为大家梳理最新进展。
论文 1:Transferable Adversarial Attacks for Image and Video Object Detection
论文 2:Real-Time Adversarial Attacks
论文 3:DeepInspect: A Black-box Trojan Detection and Mitigation Framework for Deep Neural Networks
论文 1:Transferable Adversarial Attacks for Image and Video Object Detection
链接:https://arxiv.org/abs/1811.12641
目标检测是深度学习大显身手的领域。目前,主流的图像目标检测模型可大致分为两类:基于 proposal 的模型和基于回归的模型。前者通常包含 R-CNN,Faster-RCNN,Mask-RCNN 等,这些方法使用两阶段检测步骤,首先检测 proposal 区域,然后对它们进行分类以输出最终检测到的结果。基于回归的经典模型有 YOLO 和 SSD,它们将目标检测任务视为回归过程,并直接预测边界框的坐标。与图像场景相比,图像目标检测视频目标检测将相邻帧之间的时间交互结合到目标检测过程中,通常在选定的关键帧上应用现有的图像目标检测器,然后通过时间交互传播边界框。因此,图像目标检测是视频目标检测的基础。
目前针对图像目标检测的对抗攻击方法较少,已有的方法具有两大弱点:1. 迁移性较弱:在一种目标检测方法上攻击效果好,但在另一种方法上成功率较低。2. 计算成本较高:针对视频数据处理,耗时较长。本文提出了一种开创性方法 UEA(Unified and Efficient Adversary),*可高效生成图像和视频目标检测对抗样本,并且对基于 proposal 的和基于回归的两大类目标检测器同时有效*。作者提出了一种多尺度的 attention 特征损失,以增强 UEA 的黑盒攻击能力。与首个且此前最先进的针对图像目标检测的对抗攻击方法 DAG(Dense Adversary Generation)相比,UEA 所需的运算时间约是它的千分之一。
![]()
图 1.1 DAG 和 UEA 目标检测对抗攻击效果示例
第一行为原始图像及其目标检测结果;第二行和第三行分别为 DAG 方法和 UEA 方法添加扰动后的对抗图片在两种目标检测方法上的效果;其中 DAG 扰动后使得 Faster R-CNN 未检测出图中目标,但是对 SSD 无影响;而 UEA 扰动后在 Faster R-CNN 上未检测出目标,同时在 SSD 上检测到的目标 car 被识别为 sofa
Tips:
2017 年 Xie 等人提出的 DAG 对抗攻击方法以 Faster R-CNN 为攻击模型,首先为每个 proposal 分配一个对抗标签,然后执行迭代梯度反向传播以对 proposal 进行错误分类。由于 DAG 通过操纵类标签来实现对抗样本,专门用于对 proposal 进行错误分类,这意味着 DAG 的可迁移性很差,无法在基于回归的检测器上很好地工作。另外,DAG 是一种优化方法,每个图像需要 150 到 200 次迭代才能完成对抗扰动,高计算成本使 DAG 无法应用于攻击视频目标检测系统,因为视频攻击所需的运算量要高得多。
![]()
U(Unified):
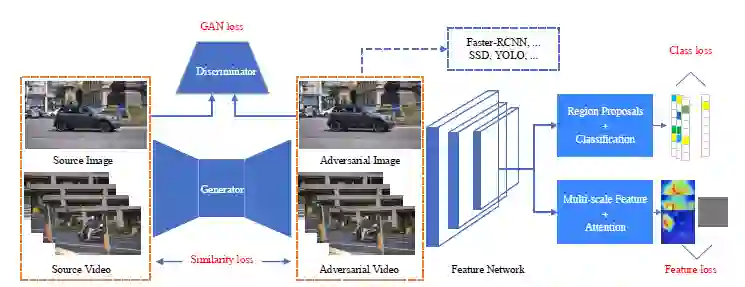
「统一」表示可以同时攻击当前的两种代表性目标检测模型。由于基于 proposal 和回归的目标检测器都使用特征网络作为后端,如 Faster-RCNN 和 SSD 都使用 VGG16,如果对从后端特征网络中提取的特征进行攻击,则两种类型的目标检测器都将受到影响。作者将该想法以多尺度特征损失来实现,从多个层中攻击特征图。从 DNN 的深度来看,DAG 的类损失应用于高级 softmax 层,attention 特征损失用于低级后端层。作者在 GAN 框架内同时集成了低级特征损失和高级类损失,以共同提高可迁移性。
E(Efficient):
「高效」表示能够快速生成对抗图像,可以有效地处理视频数据中的每个帧。作者利用生成机制而不是进行迭代优化,将该问题制定为生成对抗网络(GAN)框架,并训练生成器网络生成对抗图像和关键帧。由于测试步骤仅涉及前向网络,因此运行时间很快。
UEA 训练框架如图 1.2 所示,总的损失函数由四个部分组成,GAN 的目标函数,用于约束对抗样本和原图相似性的 L2 损失函数,同时采用 DAG 方法中提出的高级类损失,和本文作者提出的低级多尺度 attention 损失,共同制定到了 GAN 的框架中,以联合训练生成器。
![]()
![]()
L2 损失:用于度量原始图片和对抗样本图片之间的相似性
![]()
![]()
其中 X 是 Faster R-cnn 网络输入图像为 I 时提取的特征图,t_n 是第 n 个 proposal 区域,l_n 是 t_n 的 ground-truth 标签,l^n 是从其他不正确的类采样的错误标签。
多尺度 attention 特征损失:
![]()
Xm 是特征网络的第 m 层中提取的特征图。Rm 是随机预定义的特征图,在训练期间是固定的。为了欺骗探测器,只有前景物体的区域需要扰动。作者使用注意权重 Am 来测量 Xm 中的对象,如果用 sn 表示区域提案 tn 的得分,对于原始图像中的每个像素,收集覆盖该像素的所有 region proposal,并计算这些 proposal 的总和 S 得分 sn,然后将 S 除以 proposal 数 N 就可以获得原始图像中的 attention 权重,最后,通过将原始 attention 权重映射到第 m 个特征层来获得 Am。对于对象内的像素,它们的权重将具有较大的值。○是两个矩阵之间的 Hadamard 积。通过使 Xm 与 Rm 一样接近,强制将 attention 特征映射作为随机排列,从而修改前景对象的特征图。其中 Rm 也可以被不同于 Xm 的其他特征映射替换。在实验中,作者选择 conv3-3 之后的 Relu 层和 VGG16 中 conv4-2 之后的 Relu 层来修改它们的特征图。为了计算 Am,作者根据得分使用了前 300 个 region proposal。
在测试阶段,生成器用于生成对抗图像或视频帧以欺骗不同的目标检测器。作者参考了 pix2pix 的训练方式,利用了 [1] 中的框架。其中,生成器是 encoder-decoder 网络,判别器与 ResNet-32 相近。(【1】Xiao C , Li B , Zhu J Y , et al. Generating Adversarial Examples with Adversarial Networks[J]. 2018.)
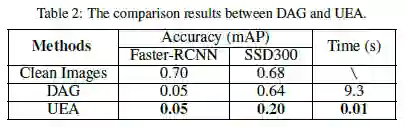
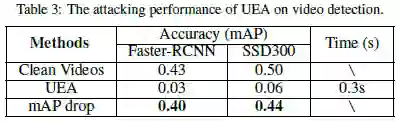
最后,让我们来看看本论文方法的实验结果。与 DAG 方法相比,UEA 对图像目标检测攻击的效果如 Table2 所示,在 Faster R-CNN 上表现和 DAG 持平,在 SSD300 上表现比 DAG 好的多,且用时仅 0.01s。UEA 方法在视频目标检测攻击的效果如 Table3 所示,在 Faster-RCNN 和 SSD300 上分别使得 mAP 值下降了 0.4 和 0.44,且用时仅 0.3s,证明了本方法对视频目标检测实现了有效的攻击。
![]()
![]()
本篇论文是 IJCAI2019 的 oral 论文,论文短小精悍,图示丰富(图像目标检测、视频目标检测、消融实验证明的对比图详见原文)。这篇论文通过提出多尺度特征损失,结合先前目标检测攻击 DAG 方法中的类损失,共同提高了目标检测对抗攻击的迁移性。通过用 GAN 生成对抗样本而非迭代优化的方式,加快了攻击速度,使之也可以成功的用于视频。
论文 2:Real-Time Adversarial Attacks
链接:https://arxiv.org/abs/1905.13399
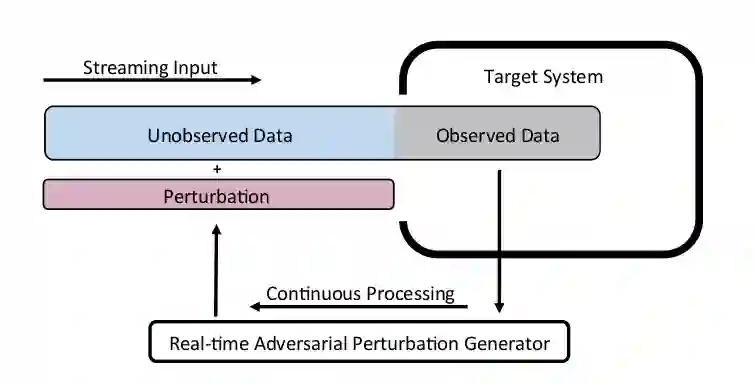
机器学习算法易受到对抗扰动攻击,对输入添加微小但精心设计的扰动可能使模型失败。虽然现有的攻击方法已经非常有效,但它们只关注目标模型采用静态输入的情况,即攻击者可以观察整个原始样本,然后在样本的任何点添加扰动。但这些攻击方法不适用于目标模型采用流输入的情境,即攻击者只能观察过去的数据点并向输入的剩余(未观察到的)数据点添加扰动。*本文提出了实时对抗攻击的概念*,展示了如何通过设计实时扰动生成器来攻击基于流的机器学习模型,并通过实时语音处理案例证明了所提出方法的有效性。
![]()
作者将实时对抗攻击描述为强化学习问题, 使用深度强化学习架构,权衡 observation 和 action 空间, 连续使用观察到的数据来近似未来时间点的最优对抗扰动。与传统的基于优化的对抗性攻击 (如 FGSM 和 DeepFool) 的不同之处在于该方法将原始样本和相应的对抗性扰动作为未知非线性映射的输入和输出,然后使用 DNN 近似它,即用学习代替优化。
由于强化学习中的稀疏奖励问题 (sparse rewards problem),即 agent 只能在最后获得奖励,并且很难根据观察到的数据和过去的行为估计每个时间点的奖励。因此作者通过使用非实时对抗性生成算法生成许多 observation-action 对的轨迹, 使用模仿学习策略来克服稀疏奖励问题。
模仿学习是一种强化学习技术,通过模仿专家的行为来学习最优的策略。模仿学习要求专家产生一系列决策轨迹 {τ1,τ2 ,...}, 每个轨迹由"obeservation-action"对的序列构成, 如τi = {oi1,ai1,oi2,ai2,...,oin ,ain}。当给定 observation 时教 agent 该执行什么样的 action。我们可以从轨迹中抽取所有的专家"obeservation-action"对,形成新的数据集 D={(o11,a11 ),(o12,a 12),...,(o1n,a1n),(o21,a21 ),(o22,a22 ),...},通过将 o 作为输入特征,a 作为输出 label,我们可以使用传统的算法以一种监督学习的方式学习到策略π:a=g(ot)。在制作对抗样本时,作者使用目前最先进的非实时对抗样本技术作为专家来生成「sample-perturbation」对,通过给不同的原始样本 xi,收集相应的输出扰动 ri 作为决策轨迹 {(x1,r1),(x2,r2),...}。由于当前最好的非实时对抗样本技术可以被简单地分为两类,第一类包含基于梯度的方法(如 FGSM、DeepFool),第二类是基于随机优化的方法,使用哪类方法作为专家效果更好不仅取决于攻击的成功率,还包括其它三种重要的评估指标:添加额外约束的灵活性,攻击者的知识,专家的确定性。
具体的实时对抗攻击算法分为 3 个阶段,如图 2.2 算法描述所示,第一步是生成 Expert Demonstrations,第二步是训练实时对抗样本生成器,第三步是执行实时对抗攻击。
![]()
![]()
![]()
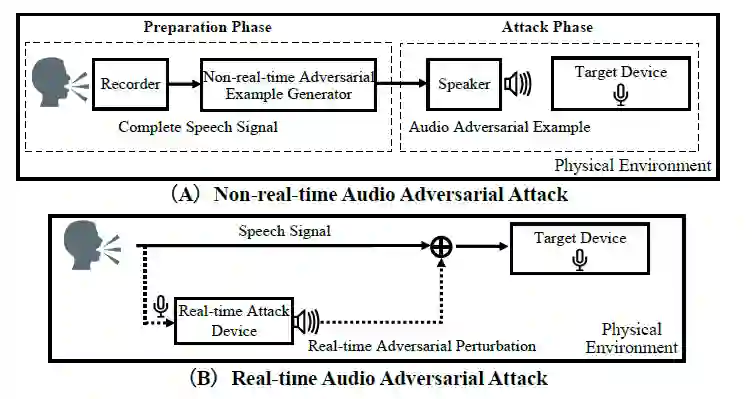
随后,作者使用本文提出的方法,发起了实时语音攻击。如图 2.3 所示,非实时对抗性攻击方法需要一个「准备阶段」,攻击者在这个阶段获得完整的原始语音样本,并设计特定的对抗性干扰,向原始样本添加扰动,以建立恶意对抗样本。在「攻击阶段」,攻击者需要用目标系统初始化一个新的会话,然后重放准备好的恶意对抗样本。而在对安全敏感的系统中启动一个新会话并不总是容易的,甚至是不可能的。相比之下,实时对抗性攻击方案不需要准备阶段,而是连续处理用户发出的语音,并发出对抗性扰动,这种扰动与原始信号以实时方式叠加。实际上,可以通过在目标设备附近放置一个装有麦克风和扬声器的设备 (例如智能手机) 并安装实时攻击软件来实施攻击。
![]()
图 2.3(A)非实时语音对抗攻击(B)实时语音对抗攻击
作者在半黑盒设置中执行非目标攻击,选择基于随机优化的对抗样本技术作为专家,优化的候选解是由每个噪声段的起始点组成的 5 元组,优化目标是最小化原始标签的置信度分数。在每次迭代时,计算每个候选解的适应度,并使用标准差分进化公式产生新的候选解。实验发现,实时对抗性扰动的攻击成功率高达 43.5%(当扰动幅度为 1 时),约为最佳非实时专家的一半(90.5%),并且明显优于随机噪声。对于大多数扰动幅度,实时攻击的攻击成功率是专家的攻击成功率的 30%-50%。通过分析,有两种主要类型的错误导致专家和实时对抗生成器之间的性能差距:预测错误和实时决策错误。由于提出的实时生成器本质上是试图在部分输入和输出之间建立映射,而专家采用的随机优化算法的输出是具有不确定性的,这使得学习输入和输出之间的映射更加困难。所以即使在实时生成器观察到完整数据之后,预测仍然具有一定量的预测误差。
本篇论文结构一分为二,前半部分从理论抽象层面讲解实时对抗攻击的原理,后半部分以实时语音识别为研究案例进行攻击实验。本篇论文首次提出了实时对抗攻击的概念,不仅可以用于实时语音处理领域,还可以用于股市金融贸易系统等采用流输入的系统,虽然目前实时攻击的效果还不能与非实时对抗攻击媲美,但如何采用更先进的强化学习工具来提高决策过程的表现,当实时对抗性扰动生成器意识到它先前做出了错误的决定时,是否可以调整其未来扰动进行弥补,在防御方面是否能够保护实时系统免受这种实时对抗性攻击等是未来研究的方向。
论文 3:DeepInspect: A Black-box Trojan Detection and Mitigation Framework for Deep Neural Networks
链接:http://www.aceslab.org/sites/default/files/DeepInspect.pdf
训练一个高准确率的 DDN 模型是耗时耗计算资源的,因此用户往往会从第三方中获取预训练的深度学习模型。比如,Caffe Model Zoo 就是一个公开的与用户共享预训练模型的典型平台。而这种第三方 DNN 训练的不透明性,使得神经网络容易遭受特洛伊攻击。攻击者能够通过打断训练过程注入恶意行为,训练出带后门的神经网络模型,并将后门模型上传到平台上供用户使用。带后门的模型具有如下行为:当输入为干净样本时,模型将输出正确的分类结果,当输入样本带有攻击者指定的 trigger(触发器)时,模型将输出攻击者指定的目标类别。比如,右转交通标志牌上添加 trigger 后,将会被后门模型预测为左转标志牌。这为自动驾驶、人脸识别等领域带来潜在危害。因此在使用模型之前检查预先训练的 DNN 是否已经被木马化是必不可少的。
本文的目标是解决未知 DNN 受到特洛伊攻击的安全问题,并确保安全的模型部署。作者提出了第一个后门检测框架 DeepInspect,在没有干净的训练数据或真实参考模型的帮助下,检查预先训练的 DNN 的安全性,使用条件 GAN 学习潜在触发器的概率分布,从而检索后门插入的足迹,并且通过模型修补实现有效的木马缓解。大量实验表明,与以前的工作相比,DeepInspect 可提供卓越的检测性能和更低的运行时间开销。
![]()
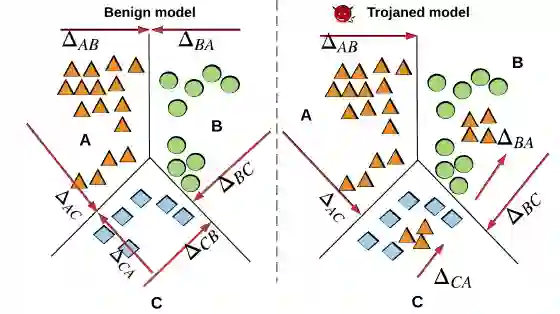
图 3.1 DeepInspect 木马检测的直观思想
特洛伊木马插入过程可以被视为在合法数据点附近添加新的数据点并将其标记为攻击目标。从原始数据点到恶意数据点的移动是后门攻击中使用的触发器。作为特洛伊木马插入的结果,可以从图 3.1 中观察到,将合法数据转换为属于攻击目标类别的样本所需的扰动与相应的良性模型中相比较小。如何理解呢?考虑三分类问题,设ΔAB 表示将 A 类中的所有数据样本移动到 B 类所需的扰动,ΔA 表示将所有其他类中的数据点变换为 A 类的扰动:ΔA= max(ΔBA,ΔCA)。具有攻击目标 A 的特洛伊模型满足:ΔA<<ΔB,ΔC,而这三个值之间的差异在良性模型中较小。DeepInspect 将这种「小」触发器的存在标识为特洛伊木马插入所留下的「足迹」,并恢复潜在触发器以提取扰动统计数据。
![]()
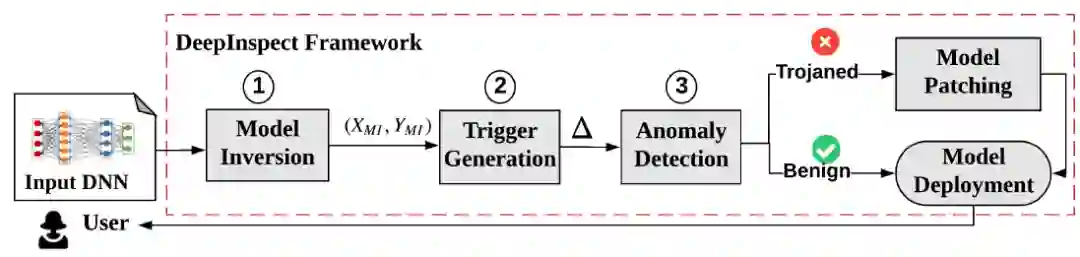
如图 3.2 所示,DeepInspect(DI)包含三个主要步骤:
1. 利用模型反演方法来恢复训练数据集。假设 DNN 有 n 个输出类别,DeepInspect 首先采用模型反演 (MI) 方法来生成一个包含所有类别的替代训练集 {X_MI,Y_MI}。
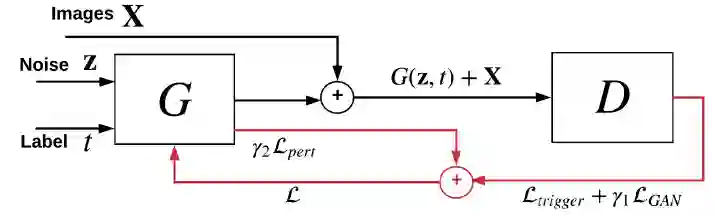
2. 利用生成模型来重建特洛伊木马攻可能使用的触发器图案。由于攻击目标(受感染的输出类)对于防御者是未知的,因此使用条件生成器 G(z,t) 来有效地构建对不同攻击目标的触发器。其中 z 是一个随机噪声向量,t 是一个目标类别。G 被用于训练来学习触发器分布,这意味着被检测的 DNN 应该在反向数据样本 x 上叠加 G 的输出来预测攻击目标 t。条件 GAN 的训练过程如图 3.3 所示,训练目标为 D(X+G(z,t))=t,D 是待检测的 DNN,t 是攻击目标,x 是来自模型反演获得的近似数据分布 Px 的样本,触发器是条件生成器的输出。
![]()
一个负对数似然损失来量化 G 生成的触发器的质量。
一个对抗性损失 LGAN 确保 x_t=x+G(z,t) 不能被判别器从原始图中识别出来。
在 L_1 范数上添加一个 soft hinge loss 来限制 G 输出的大小,并设置一个防御者选择的阈值。
将它们加权求和就是总的损失,其中 r1,r2 为超参数。
![]()
3. 在使用 cGAN 为所有输出类生成触发器之后,DeepInspect 将特洛伊木马检测制定为异常检测问题。收集所有类别中的扰动统计数据,将扰动程度 (变化幅度) 作为异常检测的检验统计量。假设检验和鲁棒性统计来检测触发扰动中异常值的存在,使用双中值绝对偏差(Double Median Absolute Deviation,DMAD)作为检测标准。
在介绍了方法之后,我们来看看实验。作者首先使用不同的 Benchmark 数据复现了两种典型的特洛伊攻击。1. 使用 MNIST 手写数字数据集和 GTSRB 交通标志牌数据集在对应的 DNN 分类模型上实现了 BadNets 攻击。2. 使用添加了方形 trigger 和水印 trigger 的 VGGFace 人脸数据集在 VGG16 和 ImageNet1000 在 ResNet-18 上实现了 TrojanNN 攻击。
BadNet 使用特定的 trigger,如在手写数字图像右下角插入白色方块,在交通标志牌上插入炸弹、花朵的小图。TrojaNN 通过使目标 DNN 中的选定神经元达到高激活值而生成 trigger,如内部五颜六色的方形和水印。示意如图 3.4。
![]()
图 3.4 插入 trigger 后的图像举例。(a)Badnet 中在 MNIST 数据集中插入的方形 trigger (b)Badnet 中在交通标志牌上插入的黄色方形 trigger (c)Trojann 在 VGGFace 数据集上插入的方形 trigger (d)Trojann 在 VGGFace 上插入的水印 trigger. (a)(b) 来自论文 Badnets: Identifying vulnerabilities in the machine learning model supply chain. (c)(d) 来自论文 Trojaning attack on neural networks
作者将干净数据集和篡改后的数据(即添加了 trigger 的干净数据)混合,训练出带后门的 DNN,达到 95% 以上的特洛伊激活率 (TAR),设置和结果如 Table 1 所示。
![]()
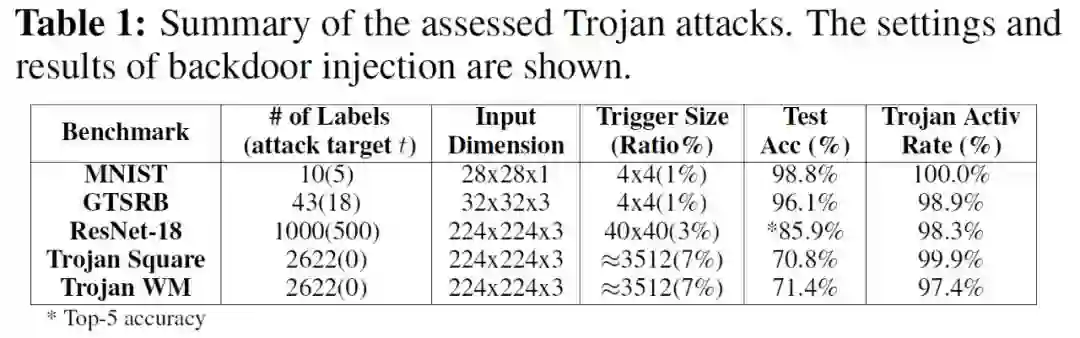
为了验证异常检测的可行性,作者使用前述 DeepInspect 的三个步骤,分别测量了良性模型和特洛伊模型的偏差因子 (df,deviation factor),结果如图 3.5(a) 所示。如果待检测模型的偏差因子大于截止阈值,则确定其被「感染」。使用显著性水平α = 0.05(对应于截止阈值 c = 2),对于所有感染模型,DeepInspect 产生的 df> 2;对于所有良性模型,df <2。且感染的 DNN 与相应的良性 DNN 之间的偏差因子差距很大,表明 df 是特洛伊木马检测的有效指标。
为了证实 DeepInspect 使用的直观思想 (图 3.1),作者测量了 DeepInspect 的条件生成器恢复的触发器的扰动水平,并在图 3.5(b) 中可视化它们的分布。可以观察到,受感染标签的扰动幅度(由三角形表示)确实显著小于未感染类别的扰动幅度。
![]()
图 3.5(a) 良性模型和特洛伊模型的偏差因子,红色虚线表示α=0.05 时的决策阈值 (b) 特洛伊模型中针对感染和未受感染的标签生成 trigger 的扰动程度
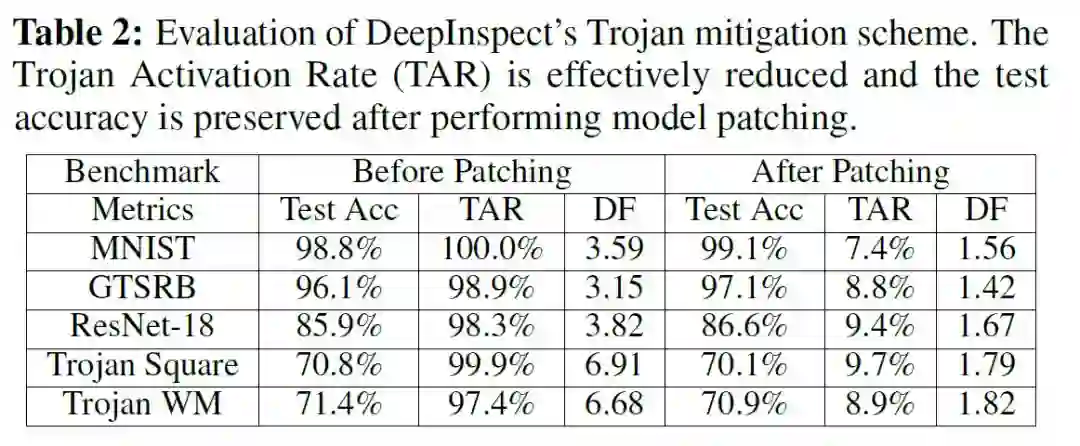
DeepInspect 通过训练条件生成器来学习潜在触发器的概率密度分布,从而有效地检测到后门攻击的发生。换句话说,一旦我们完成条件 GAN 的训练,我们就有了一个能够为任何目标类构建不同 trigger 图案的生成器,这有助于进行对抗学习,可用于提高良性模型的鲁棒性,或「修补」受感染的 DNN 以禁用特洛伊木马攻击。作者将反向训练集 {X_MI,Y_MI} 和修补后的数据集 {X_patch,Y_patch} 混合,微调 Trojaned DNN 来执行模型修补,修补结果如 Table2 所示。可以看到,作者提出的特洛伊木马缓解方案有效地降低了触发器的激活率,同时保留了模型在正常数据集中的表现。通过修补 df 小于等于 DeepInspect 异常检测截止阈值 c 的模型,从而能够通过模型的鲁棒性检查进行安全部署。作者还强调,如果有干净的数据,修补后的特洛伊激活率可以进一步降低到∼3%。
![]()
针对神经网络的后门攻击方法已经趋于多样化,现有的防御方法多是在已知模型为后门模型的前提下降低后门攻击的成功率,而如何检测模型是否为后门模型的论文极少,此篇论文就是其中之一。此前,神经净化(Neural cleanse: Identifying and mitigating backdoor attacks in neural networks)提出的后门检测方法依赖于干净的训练数据,然而这样的原始训练数据对于防御者来说难以获取,因此应用场景有所受限。而本论文利用模型反演方法生成可替代原始训练数据的训练数据,有效解决数据问题,是一大亮点。此外,通过扰动程度来检测后门插入痕迹这一思想直观易懂,检测后通过缓解方案确实有效降低了触发器的激活率,是神经网络后门攻击与防御领域值得关注的一篇论文。
作者介绍:罗赛男,西安电子科技大学计算机学院研究生,主要研究神经网络安全、验证码安全。关注学术前沿,喜欢文字分享,希望通过机器之心和大家一起学习,共同进步。比心 (ノ゚▽゚)ノ♡!
Adversarial Examples for Graph Data: Deep Insights into Attack andDefense: Huijun Wu, Chen Wang, Yuriy Tyshetskiy, Andrew Docherty, KaiLu, Liming Zhu
Data Poisoning against Differentially-Private Learners: Attacks and Defenses: Yuzhe Ma, Xiaojin Zhu, Justin Hsu
Data Poisoning Attack against Knowledge Graph Embedding: Hengtong Zhang, Tianhang Zheng, Jing Gao, Chenglin Miao, Lu Su, Yaliang Li, Kui Ren
Robust Audio Adversarial Example for a Physical Attack: Hiromu Yakura, Jun Sakuma
Adversarial Attacks on Neural Networks for Graph Data: Daniel Zügner, Amir Akbarnejad, Stephan Günnemann
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com