《Nature》子刊:不仅是语言,机器翻译还能把脑波「翻译」成文字
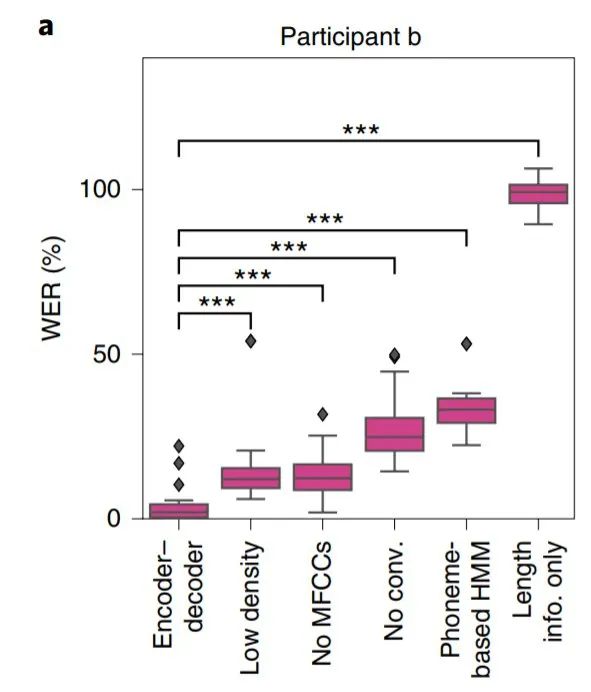
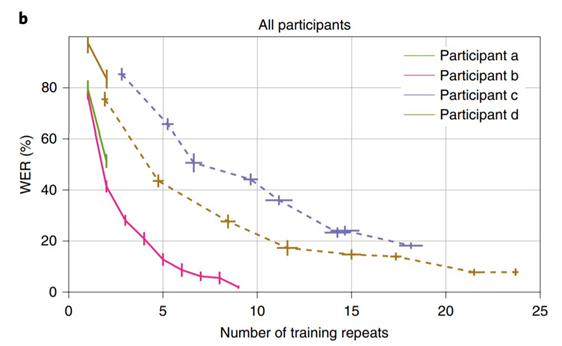
如果将人脑的神经信号也视为一种语言,那么将机器翻译架构应用于解读神经信号的可行性似乎并不令人惊讶。在《Nature Neuroscience》的一篇论文中,来自加州大学旧金山分校的研究者实践了这一想法。他们用一个编码器-解码器框架将大脑神经信号转换为文字,在 250 个词的封闭句子集中将错误率降到了 3%。

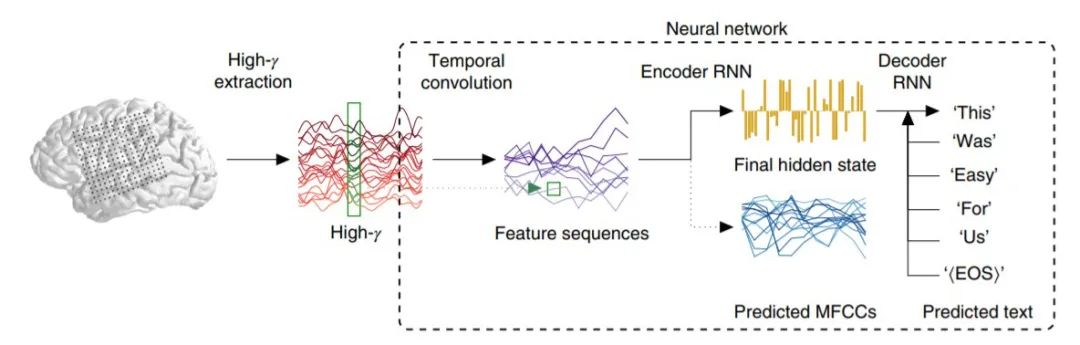
时间卷积:类似的特征很可能在 ECoG 数据序列的不同点上重现,全连接的前馈网络无法利用这样的特点。
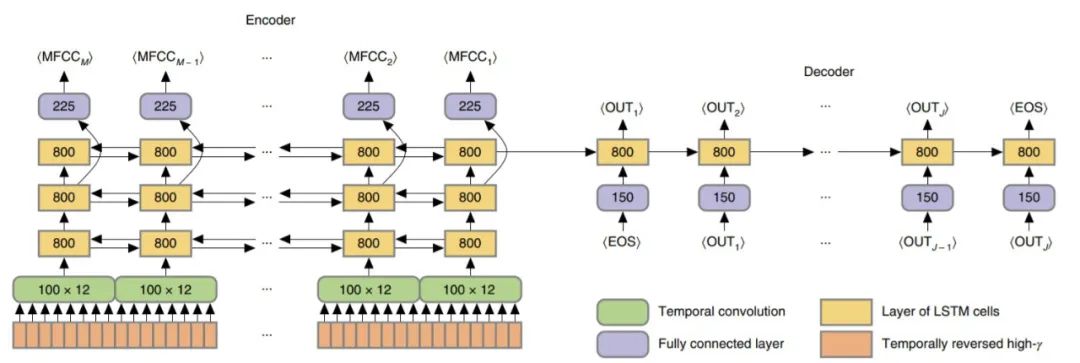
编码器 RNN:下采样序列被 RNN 按序处理。在每个时间步中,编码器 RNN 的输入由每个下采样序列的当前样本以及它自己的先前状态组成。然后最终隐藏状态(Final hidden state,上图中的黄色条)提供整个序列的单个高维编码,与序列长度无关。为了引导编码器在训练过程中找到有用的解,研究者还要求编码器在每个时间步中预测语音音频信号的表示,即梅尔频率倒谱系数的序列 (MFCCs)。
解码器 RNN:最后,高维状态必须转换回另一个序列,即单词序列。因此,我们初始化第二个 RNN,然后训练为在每个时间步骤解码出一个单词或序列结束 token(在该点终止解码)。在输出序列的每个步骤中,除了自身先前的隐藏状态外,解码器还以参与者实际说出句子中的前一个单词作为输入(在模型训练阶段),或者它自己在前一步预测的单词作为输入 (在测试阶段)。与以前针对语音音素进行语音解码的方法相比,该方法将单词作为目标。
4 月 28 日 20:00,机器之心联合华为昇腾学院开设的线上公开课《轻松上手开源框架 MindSpore》第三课将正式开讲,主题为《MindSpore 代码流程分析》,主要介绍 MindSpore 端到端调用流程与算子开发流程,扫码即可免费报名。

登录查看更多
相关内容

专知会员服务
36+阅读 · 2020年5月20日
专知会员服务
20+阅读 · 2020年5月14日
专知会员服务
11+阅读 · 2019年12月28日
UniViLM: A Unified Video and Language Pre-Training Model for Multimodal Understanding and Generation
Arxiv
19+阅读 · 2020年2月15日
Arxiv
7+阅读 · 2019年11月13日
Arxiv
7+阅读 · 2018年5月24日
Arxiv
16+阅读 · 2017年11月20日




相关VIP内容
专知会员服务
36+阅读 · 2020年5月20日
专知会员服务
20+阅读 · 2020年5月14日
专知会员服务
11+阅读 · 2019年12月28日
相关资讯
相关论文
UniViLM: A Unified Video and Language Pre-Training Model for Multimodal Understanding and Generation
Arxiv
19+阅读 · 2020年2月15日
Arxiv
7+阅读 · 2019年11月13日
Arxiv
7+阅读 · 2018年5月24日
Arxiv
16+阅读 · 2017年11月20日