Batch size 没必要设为2的次方!?
文 | 付瑶
最近刷到一个话题很有趣,搬来和大家一起讨论下:
“batch-size 一定要大小为2的幂吗?不这样设置会有啥差别吗?”

发帖人认为大家都进入一个误区。坚持选择batch-size的大小为2的幂次数是因为曾经被告知从计算的角度是对训练效率有益的。但是这个“有益”是真实存在的吗?
为了求证这个问题,发帖人首先试图从内存对齐和精度训练的效率两个角度找寻答案。
首先关于memory alignment的主要是猜测受内存页大小的影响,内存页经查看确实是一个2的幂次方的数字,但是作者认为这个理念是一个或者多个batches放在同一个内存页上,以帮助gpu的内存对齐,有些类似于在游戏开发和图像设计中使用的OpenGL和DirectX选择两种纹理。而关于浮点数的计算效率,他在Nvidia的《Matrix Multplication Background User‘s Guide 》中找解释,其中结束了矩阵尺寸和GPU计算效率之间的关系,矩阵维度不应该选择2的幂次的数字而且8的倍数,以便在具有TensorCores的GPU上进行训练(2的幂次数和8的倍数之间存在重叠)。因此,发帖人batch size大小为8的倍数对于FP16混合精度训练的gpu来说,理论上是最有效的。
然后他进行一系列实验,研究在实际训练中“有效性”是否可以被注意到。这次实验在CIFAR-10进行了10个epoch的实验,图像大小标准倍调整为224*224,用16bit混合精度来训练。
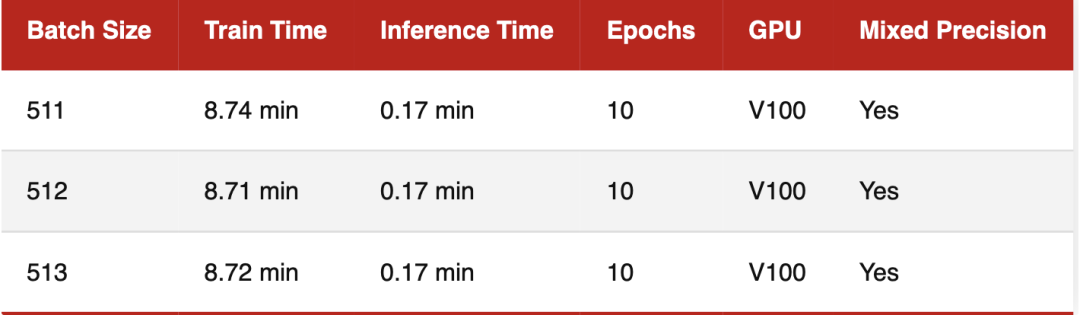
1. 以 Batch Size = 128 作为参考点

似乎将批大小减少1(127)或将批大小增加1(129)确实会导致训练性能略慢。但是差异十分微小,作者认为可以忽略不计。
2. 以 Batch Size = 256 作为参考点
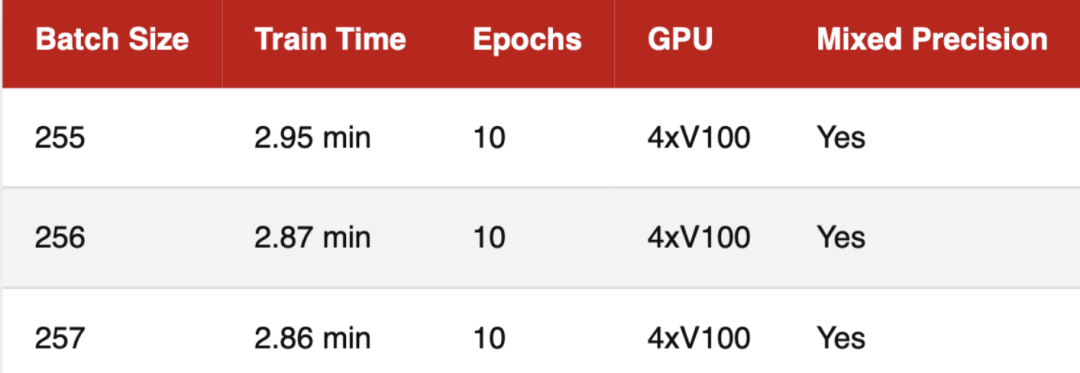
3. 多卡训练场景
在帖子下面的网友讨论也是各显神通。有一些调侃的回复,同样也有一些不同角度的解答。
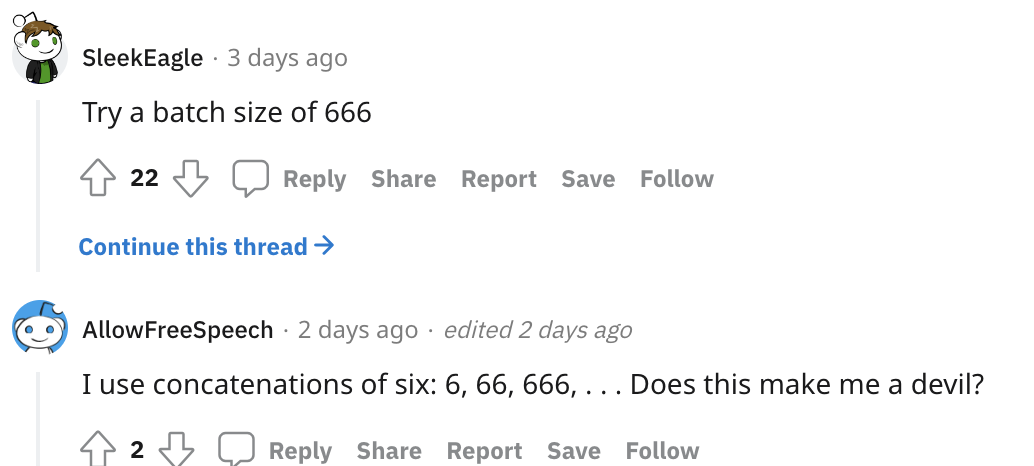
“都选7”派
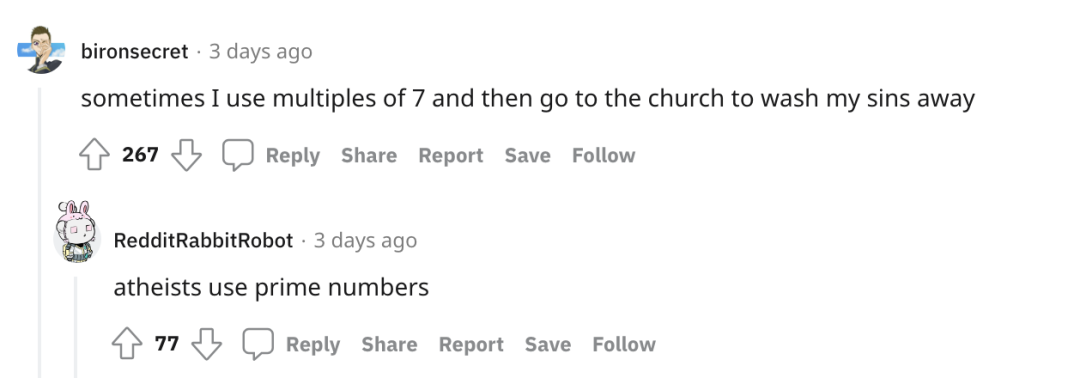
“666”派
下面也有人提出在“nvidia的完整手册”描述了为什么层尺寸和批量大小的 2 次方对于cuda级别的最大性能是必须的。作者的监控和测试并不具代表性,然而作者列出的反例也有道理:
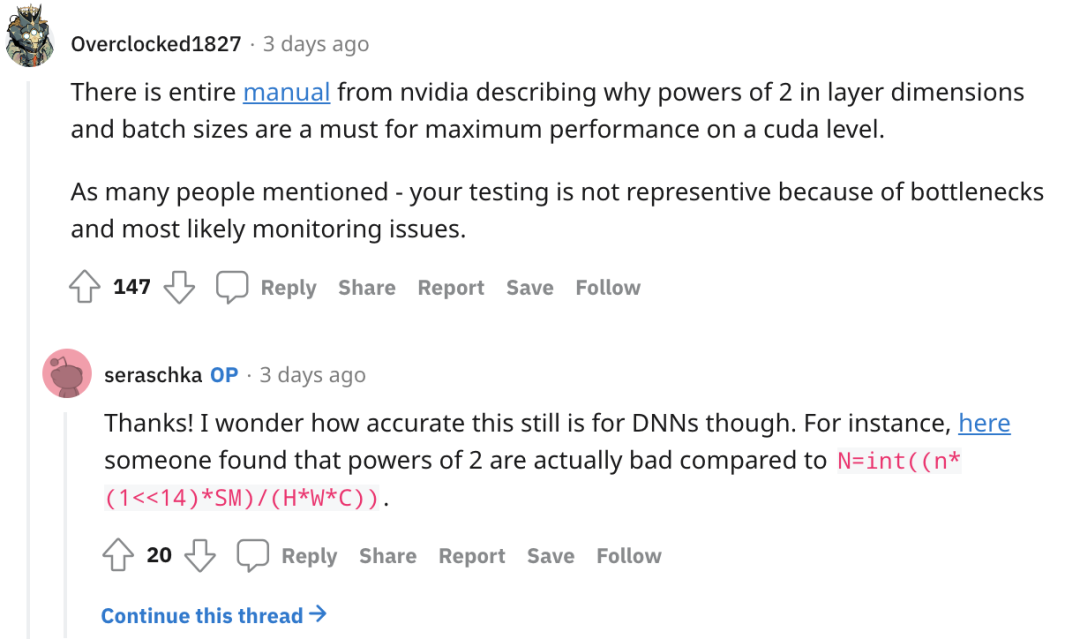
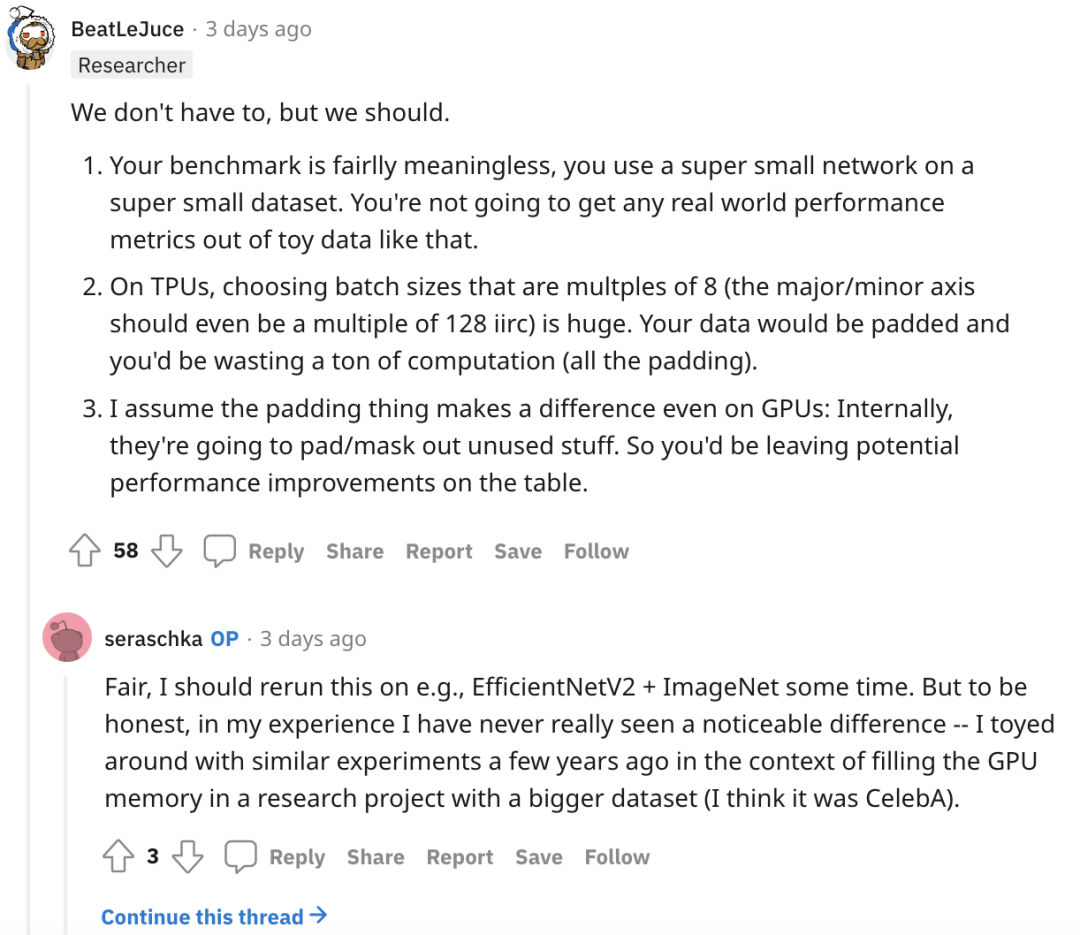
总结下大家的发言:存在一部分人认为发帖人的实验不具说服力和意义,例如在超小型网络上使用了超小型数据集、未使用TPU、任务过于单一等。与此同时也有人提出考虑TPU/XLA填充数据、以及深度学习编译器的8的倍数准则等,batch size的大小将至关重要。可以说是各持一词非常热闹,但是究竟这个问题是否真的有解?欢迎大家一起讨论~
萌屋作者:付奶茶
新媒体交叉学科在读Phd,卖萌屋十级粉丝修炼上任小编,目前深耕多模态,希望可以和大家一起认真科研,快乐生活!
作品推荐
1.在斯坦福,做 Manning 的 phd 要有多强?
 萌屋作者:付奶茶
萌屋作者:付奶茶
后台回复关键词【入群】
加入卖萌屋NLP、CV、搜推广与求职讨论群
[1]https://www.reddit.com/r/MachineLearning/comments/vs1wox/p_no_we_dont_have_to_choose_batch_sizes_as_powers/
 后台回复关键词【入群】
后台回复关键词【入群】
