【明星自动大变脸,嬉笑怒骂加变性】最新StarGAN对抗生成网络实现多领域图像变换(附代码)
点击上方“专知”关注获取专业AI知识!

【导读】图像之间的风格迁移和翻译是近年来最受关注的人工智能研究方向之一,这个任务在具有趣味性的同时也是很有挑战的。相关的研究成果也层出不穷,有的甚至引起了全世界的广泛讨论。近日,香港科技大学、新泽西大学和 韩国大学等机构在 arXiv 上联合发表了一篇研究论文,提出了在同一个模型中进行多个图像领域之间的风格转换的对抗生成方法StarGan,突破了传统的只能在两个图像领域转换的局限性。
▌视频
▌详细内容
图像到图像转化的任务是将一个给定图像的特定方面改变到另一个方面,例如,将一个人的面部表情从微笑到皱眉改变(见图1)。自从生成对抗网络(GANs)的引入,这个任务经历了很大的发展,从改变发色,改变边缘图以重建照片,到改变风景图像的季节等。

图1. 通过从RaFD数据集学习转移知识,从而应用到CelebA图像转化的多域的图像到图像转化结果。第一列和第六列显示输入图像,其余列是产生的StarGAN图像。注意,图像是由一个单一模型网络生成的,面部表情标签如生气、高兴、恐惧是从RaFD学习的,而不是来自CelebA。
给定来自两个不同域的训练数据,这些模型学习如何将图像从一个域转换到另一个域。文章中将术语表示为图像中固有的特征,如头发颜色、性别或年龄,属性值作为属性的特定值,例如黑色/金色/棕色的头发颜色,或性别的男性/女性等。我们进一步将具有一系列相同属性值的图像设为一个域。例如,女性形象代表一个域,而男性代表另一个域。
几个图像数据集带有许多标记属性。例如,在CelebA数据集包含40个标签的面部特征,如头发的颜色、性别、年龄;RaFD数据集有8个表示面部表情的标签,如“快乐”,“愤怒”和“悲伤”。我们可以根据这些属性设置执行更有趣的任务,即多域图像到图像的转换,我们根据多个域的属性来改变图像。图1中,前5列展示了一个CelebA图像可以根据任何四个域进行转化,“金发”、“性别”、“年龄”、“苍白的皮肤”。我们可以进一步延伸到从不同的数据集进行多个域的训练,如共同训练的CelebA和RaFD图像来改变CelebA图像的面部表情,通过训练RaFD数据提取特征来作用于CelebA图像,如在图1的最右边的列。
然而,现有的模型在多域图像转换任务中效率低下。这些模型的低效率是因为在学习K域的时候,需要训练K(K−1)个生成器。图2说明了如何在四个不同的域之间转换图像的时候,训练十二个不同的生成器的网络。即使它们可以从所有域图像学习全局特征,如形状特征学习,这种模型也是无效的,因为每个生成器不能充分利用整个训练数据,只能从K学习的两个领域。未能充分利用训练数据很可能会限制生成图像的质量。此外,它们不能联合训练来自不同域的数据集,因为每个数据集只有部分标记,本文在3.2章进一步讨论。
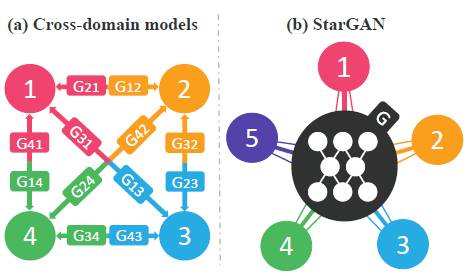
图2. 我们的StarGAN模型与其他跨域模型的比较。(a)为处理多个域,应该在每一对域都建立跨域模型。(b)StarGAN用单个发生器学习多域之间的映射。该图表示连接多个域的拓扑图。
为解决这些问题我们提出了StarGAN,它是生成对抗网络,能够学习多个域之间的映射。如图2(b)所示,文章中提出的模型接受多个域的训练数据,并且只使用一个生成器学习所有可用域之间的映射。这个想法是非常简单的。其模型不是学习固定的图像转化(例如,从黑发到金发),而是输入图像和域信息,学习如何灵活地将输入图像转换到相应的域中。文章中使用一个标签(二进制或one hot向量)代表域信息。在训练过程中,随机生成目标域标签并训练模型,以便灵活地将输入图像转换到目标域。通过这样做,可以控制域标签并在测试阶段将图像转换成任何所需的域。
本文还引入了一种简单而有效的方法,通过将掩码向量添加到域标签,使不同数据集的域之间进行联合训练。文章中所提出的方法使模型可以忽略未知的标签,并专注于有标签的特定数据集。在这种方式下,此模型对任务能获得良好的效果,如利用从RaFD数据集学到的特征来在CelebA图像中合成表情,如图1的最右边的列。据本文中提及,这篇工作是第一个成功地完成跨不同数据集的多域图像转化。
总的来说,本文的贡献如下:
提出了StarGAN,生成一个新的对抗网络,只使用一个单一的发生器和辨别器实现多个域之间的映射,有效地从所有域的图像进行训练;
展示了如何在多个数据集之间学习多域图像转化,并利用掩码向量的方法使StarGAN控制所有可用的域标签。
提供定性和定量的结果,对面部表情合成任务和面部属性传递任务使用StarGAN,相比baseline模型显示出它的优越性。
原则上,文中提出的模型可以应用于任何其他类型的域之间的转换问题,例如,风格转换(style transfer),这是未来的工作方向之一。
▌模型简介
在单一数据集上的训练
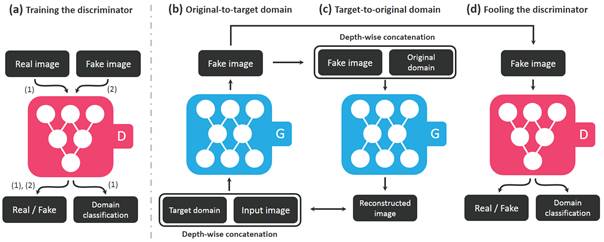
总得来看,StarGAN包括两个模块,一个鉴别器D和一个生成器G.(a)D学习如何区分真实图像和伪造图像,并将真实图像分类到相应领域。 (b)G同时输入图像和目标域的标签并生成假图像,在输入时目标域标签被复制并与输入图像拼接在一块。 (c)G尝试从给定原始域标签的假图像重建原始图像。 (d)G试图生成与真实图像不可区分的图像同时又很容易被目标域D所区分出来。
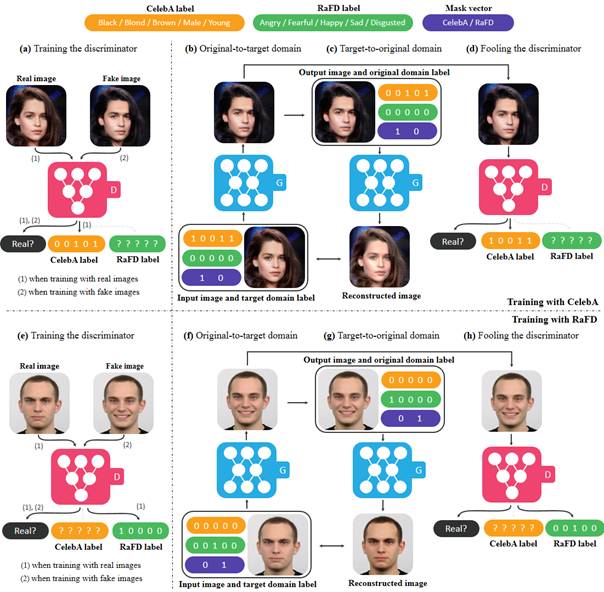
在多数据集上的训练
StarGAN同时在CelebA和RaFD两个数据机上进行培训的概述。 (a)〜(d)显示了使用CelebA的训练过程,(e)〜(h)显示了使用RaFD的训练过程。 (a),(e)鉴别器D学习如何区分真实图像和伪造图像,并仅将已知标签的分类误差最小化。 (b),(c),(f),(g)当掩码向量(紫色)为[1,0]时,生成器G学习专注于CelebA标签(黄色),而忽略RaFD标签(绿色)来执行图像到图像的转换,反之亦然,当掩码矢量是[0,1]时。 (d),(h)G尝试生成与真实图像无法区分的图像,同时图像可以被D分类可为目标域。
▌实验结果
在明星脸上的面部属性迁移
这些图片是由StarGAN在CelebA 数据集上训练后生成的。

在RaFD人脸数据集上的表情合成
这些图片是由StarGAN在RaFD人脸数据集上训练后生成的。

在明星脸上的表情合成
这些图片是由StarGAN同时在RaFD和CelebA数据集上训练后生成的。

论文:StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation

▌摘要
最近的研究表明,在两个领域域之间图像到图像转化的研究领域取得了显著的成功。然而,现有的方法在处理两个以上图像域时,可伸缩性和鲁棒性有限,因此,要为每一对映像域都需要独立构建不同的模型。
为了解决这个问题,我们提出了一个新的可扩展的StarGAN,可以利用同一个模型实现多个域图像到图像转化。这样一个统一的StarGAN模型体系允许在一个单一的网络内同时训练不同域的多个数据集。这使得StarGAN与现有的图像转化模型相比,StarGAN更加灵活,能将输入图像转化到任意所需要的目标域图像。实验证明,我们的方法在面部属性转移和面部表情合成任务上的有效性。
▌Github 代码

PyTorch代码实现的《StarGAN: UnifiedGenerative Adversarial Networks for Multi-Domain Image-to-Image Translation》,StarGAN可以很灵活的将一副图片转换成任何你想要的目标风格,这一切只需要一个简单的生成器和一个判别器。

作者
Yunjey Choi https://github.com/yunjey,
Minje Choi https://github.com/mjc92,
Munyoung Kim https://www.facebook.com/munyoung.kim.1291,
Jung-Woo Ha https://www.facebook.com/jungwoo.ha.921,
Sung Kim https://www.cse.ust.hk/~hunkim/,
Jaegul Choo https://sites.google.com/site/jaegulchoo/
Python代码依赖包
Python 2.7 or 3.5+ https://www.continuum.io/downloads
PyTorch 0.2.0 http://pytorch.org/
TensorFlow 1.3+ https://www.tensorflow.org/
如何开始运行代码
1. 克隆代码仓库
bash
$ git clonehttps://github.com/yunjey/StarGAN.git
$ cd StarGAN/
2. 下载数据集
(i) CelebA数据集
bash
$ bashdownload.sh
(ii) RaFD数据集
由于RaFD并不是一个公开的数据集,所以你必须先在Radboud Faces Database websitehttp://www.socsci.ru.nl:8180/RaFD2/RaFD?p=main这个网站上申请使用权限。然后你需要想这里描述https://github.com/yunjey/StarGAN/blob/master/png/RaFD.md的那样,来创建相应的目录结构。
3. 训练 StarGAN
(i) 使用CelebA训练
bash
$ python main.py--mode='train' --dataset='CelebA' --cdim=5 --imagesize=128 --numepochs=20--numepochsdecay=10
(ii) 使用RaFD训练
bash
$ python main.py--mode='train' --dataset='RaFD' --cdim=8 --imagesize=128 --numepochs=200--numepochsdecay=100
(iii) 同时使用CelebA和RaFD训练
bash
$ python main.py--mode='train' --dataset='Both' --cdim=5 --c2dim=8 --imagesize=256--numiters=200000 --numitersdecay=100000
4. StarGAN测试
(i) 在明星脸上的面部属性迁移
bash
$ python main.py--mode='test' --dataset='CelebA' --cdim=5 --imagesize=256 --testmodel=201000
(ii) 在RaFD人脸数据集上的表情合成
bash
$ python main.py--mode='test' --dataset='RaFD' --cdim=8 --imagesize=256 --testmodel=200200
(iii) 在明星脸上的表情合成
bash
$ python main.py--mode='test' --dataset='Both' --cdim=5 --c2dim=8 --imagesize=256--testmodel=200000
参考文献
论文:
StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation
arXiv: https://arxiv.org/abs/1711.09020
github: https://github.com/yunjey/StarGAN
video: https://v.qq.com/x/page/t0510kq8mya.html
特别提示-starGAN下载:
请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知),
后台回复“startGAN” 就可以获取starGAN的pdf下载链接~
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域22个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!
请关注我们的公众号,获取人工智能的专业知识。扫一扫关注我们的微信公众号。

请加专知小助手微信(Rancho_Fang),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等,或者加小助手咨询入群)交流~

点击“阅读原文”,使用专知!


