咱们来做完形填空:“讯飞杯”参赛历程
本文转载自公众号PaperWeekly
作者丨苏剑林
学校丨中山大学硕士生
研究方向丨NLP,神经网络
个人主页丨http://kexue.fm
1. 前言
从今年开始,CCL 会议将计划同步举办评测活动。笔者这段时间在一创业公司实习,公司也报名参加这个评测,最后实现上就落在我这里,今年的评测任务是阅读理解,名曰《第一届“讯飞杯”中文机器阅读理解评测》。
虽说是阅读理解,但事实上任务比较简单,是属于完形填空类型的,即一段材料中挖了一个空,从上下文中选一个词来填入这个空中。最后我们的模型是单系统排名第 6,验证集准确率为 73.55%,测试集准确率为 75.77%,大家可以在这里观摩排行榜 [1]。(“广州火焰信息科技有限公司”就是文本的模型)。
事实上,这个数据集和任务格式是哈工大去年提出的,所以这次的评测也是哈工大跟科大讯飞一起联合举办的。哈工大去年的论文“Consensus Attention-based Neural Networks for Chinese Reading Comprehension” [2] 就研究过另一个同样格式但不同内容的数据集,是用通用的阅读理解模型做的(通用的阅读理解是指给出材料和问题,从材料中找到问题的答案,完形填空可以认为是通用阅读理解的一个非常小的子集)。
虽然,在这次评测任务的介绍中,评测方总有意无意地引导我们将这个问题理解为阅读理解问题。但笔者觉得,阅读理解本身就难得多,这个就一完形填空,只要把它作为纯粹的完形填空题做就是了,所以本文仅仅是采用类似语言模型的做法来做。这种做法的好处是思路简明直观,计算量低(在笔者的 GTX1060 上可以跑到 batch size 为 160),便于实验。
2. 模型
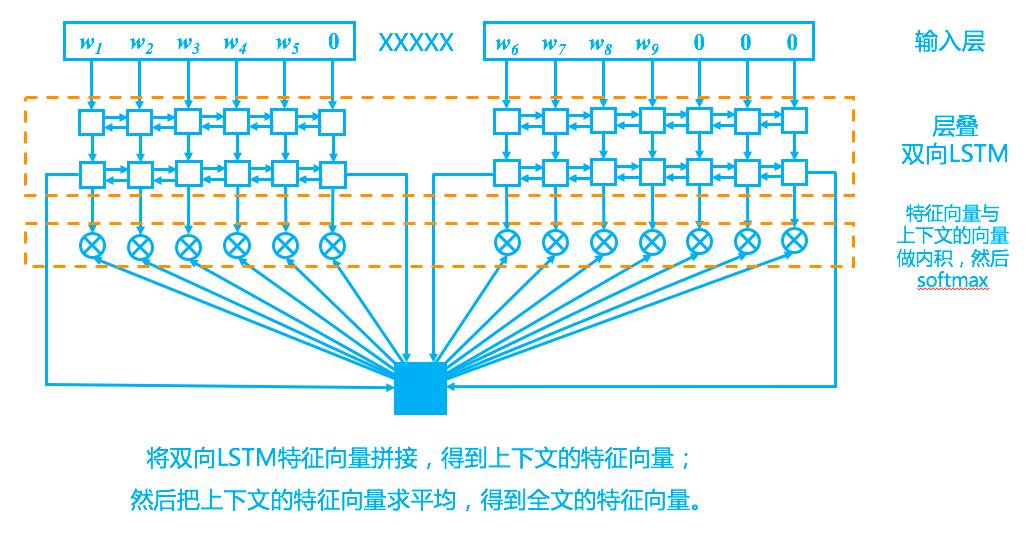
回到模型上,我们的模型其实比较简单,完全紧扣了“从上下文中选一个词来填空”这一思想,示意图如下。
初步分析
首先留意到,这个任务就是从上下文中挑选一个词来填到空缺的位置,如:

熟悉自然语言处理的朋友会联想到,这个任务本身跟语言模型差不多,甚至说这个任务应该更简单一些,因为语言模型是从前 n 个词中预测下一个词,这个预测要遍历词表中所有词,而这个完形填空任务只需要从上下文中挑,大大缩小了收缩范围。当然,两者的焦点是不一样的,语言模型关心的是概率分布,而完形填空关心的是预测正确率。
上下文编码
按照经验,对于语言模型建模来说,LSTM 效果是最好的,因此这里同样使用 LSTM,为了更好地捕捉全局语义信息,堆叠了多层的双向 LSTM,当然,对于 NLP 来说,这都是套路了。
首先,我们以“XXXXX”断开材料,分为上文和下文,然后上文和下文依次输入到同一个双向 LSTM 中(算两次,而不是拼在一起分别算),得到各自的特征。也就是说,上下文的 LSTM 是共享参数的。
为什么这样呢?原因很简单,因为我们自己在阅读上下文时,用的只是同一个大脑呀,没必要区别对待。有了一层 LSTM,那就可以层叠多个,这也是套路了。至于多少层适合,则需要看具体的数据集了。对于这个比赛任务来说,两层比单层有明显提升,而三层比两层则没有提高,甚至有些下降。
最后,为了得到整段材料的特征向量(用来做下面的匹配),只需要将双向LSTM的最后的状态向量拼接起来,得到上下文各自的特征向量,然后将两个向量求平均,就得到全局特征向量。
值得指出的是,如果换成论文“Consensus Attention-based Neural Networks for Chinese Reading Comprehension” [2] 里边的数据集 [3](格式一样,内容换成了人民日报的),同样是本文的模型,LSTM 的层数需要 3 层,最终的准确率也比论文中最好结果有 0.5% 的提升。
预测概率
接下来的一个问题是:怎么才能实现“在上下文中搜索”而不是在整个词表中搜索呢?
回忆我们做语言模型的时候,如果要在整个词表中搜索,那就要做一个全连接层,节点数是词表的单词数,然后 softmax 预测概率。我们可以这样看全连接层:我们为词表中的每一个词都分配一个与输出特征维度一样的向量,然后做内积运算,然后做 softmax。
也就是说,特征与词做配对,是通过内积来实现的。这就提供了参考思路:如果我们让 LSTM 输出的特征与词向量维度一样大,然后将这个特征与输入的词向量一一做内积(配对),然后就可以做 softmax 了,这样就实现了只在上下文搜索。
笔者一开始也是用这样的思路的,但这个思路的准确率只能到 69%~70%。后来分析了一下,原始的词向量经过多层的 LSTM 编码后,事实上已经远离了原来词向量的向量空间了,所以,与其“长途跋涉”地与输入的词向量配对,倒不如直接跟 LSTM 的中间状态向量配对?至少在同一层 LSTM 中,状态向量之间是比较接近的(指的是处于同一的向量空间),匹配起来应该容易一点。
实验证明了笔者的猜想,经过改进后的模型,在官方提供的验证集达到了 73%~74% 左右的准确率,测试集能达到 75%~76% 的准确率。后来再经过一段时间的实验,也没有明显提高,所以就把这个模型提交上去了。
实验细节
事实上笔者不是很懂调参,因此下面的代码的参数不一定是最优,期待有兴趣的调参高手能优化各个参数,给出更好的结果。笔者认为,哪怕对于本文的模型来说,我们自己给出的结果还不是最优的。
下面是在模型的实现中,一些较为重要的细节:

3. 代码
数据集
https://github.com/ymcui/cmrc2017
训练脚本
https://github.com/bojone/CCL_CMRC2017/blob/master/train.py
预测脚本
https://github.com/bojone/CCL_CMRC2017/blob/master/predict.py
[1] http://www.hfl-tek.com/cmrc2017/leaderboard.html
[2] https://arxiv.org/abs/1607.02250
[3] https://github.com/ymcui/Chinese-RC-Dataset
本期责任编辑: 丁效
本期编辑: 蔡碧波
“哈工大SCIR”公众号
主编:车万翔
副主编: 张伟男,丁效
责任编辑: 张伟男,丁效,郭江,赵森栋
编辑: 李家琦,赵得志,赵怀鹏,吴洋,刘元兴,蔡碧波
长按下图并点击 “识别图中二维码”,即可关注哈尔滨工业大学社会计算与信息检索研究中心微信公共号:”哈工大SCIR” 。



