猿辅导MSMARCO冠军团队:用MARS模型解决机器阅读任务 | 吃瓜笔记
主讲人:柳景明 | 猿辅导NLP团队负责人
整理:陈铭林
量子位 出品 | 公众号 QbitAI
4月12日晚,量子位·吃瓜社邀请到猿辅导MSMARCO冠军团队,为大家详细讲解了RACE,SQUAD,MSMARCO等主要阅读理解任务,重点拆解MARS网络模型,简明扼要地教大家动手用MARS网络模型解决MSMARCO机器阅读任务。
本期主讲人为猿辅导NLP团队负责人柳景明,同时也是MSMARCO参赛团队的主要团队成员之一。2011年硕士毕业于北京大学;2014年加入猿辅导,主要负责搜索及NLP相关技术。多次单人获得KDD-CUP(国际知识发现和数据挖掘竞赛)竞赛奖金。
猿辅导是国内领先的K-12在线教育公司,目前公司估值超过10亿美元,拥有“猿辅导”、“猿题库”、“小猿搜题”、“斑马英语”、“小猿口算”等多款核心在线教育APP应用,提供包括自适应题库、拍照搜题、在线辅导在内的众多在线教育功能和产品,服务全国超过1.7亿中小学生用户。
本次分享反应热烈,量子位应读者要求,将详细文字笔记整理如下:
典型的机器阅读任务

第一部分是典型的机器阅读任务。
问答系统是自然语言处理里的一个非常重要的方向,目前已经积累了二、三十种语料,我将这些语料分成三类:
第一类是开放式问答系统,这部分的语料的特征:它有问题和相应的答案,类似一站到底或者冲顶大会的题目;
第二是填空式问答系统,一般是从段落中挑选出一个词或者一句话,再加入候选项。要求系统能够填入正确的选项。这种语料类似英语考试中的叫完形填空,只是完型填空会更加难。这些填空式问答系统语料相对而言比较简单。比如CNN这个问答语料,去年有人发表过一篇论文,作者用一个非常简单的模型就获得大概75%的准确率。
第三类是复杂问答系统,后面会提到RACE、SQuAD、MS-MARCO等语料。百度去年发布了一个阅读理解的语料DuReader,它的格式和MS-MARCO相似,只是MS-MARCO是英文,而百度DuReader是中文。最近科大讯飞也发布了一个类似SQuAD的,基于维基百科的中文问答式语料数据集。
RACE数据集

我们来看下由CMU大学去年发布的RACE数据集,它是英语考试中的阅读理解。这个语料包含一个材料,然后有几个问题,每个问题有一个题干以及四个选项,要求系统能够将四个选项正确地填入。
在CMU的论文里面,他们发布了一个baseline模型,这个模型准确率大概在45%左右,这个准确率实际上是比较低的,因为这个语料的难度非常大。
SQuAD数据集

SQuAD是由Stanford大学发布的,这个语料由一个材料、一些问题以及一些答案组成。
这些答案来自于高频的维基词条,Stanford团队挖掘了这些高频维基词条,将每个段落作为材料,然后通过众包的方式让一批人针对这个材料写自己感兴趣的问题,然后根据这些问题让另外一批人去材料里面去圈答案,他们要求答案必须是材料里一个完整的片段。
有什么好处呢?一方面可以使数据生成更加方便,因为可以尽可能地减少人主观上的一些影响;另外一方面也会使模型的评估更直接、更容易理解。
Stanford在学术界有很强的号召力,所以有很多团队也在追逐这个数据集。在早期的时候是一些学术团队在上面提交模型,而最近半年内,更多的是一些企业界在提交一些更加强的模型,比如国内的科大讯飞、阿里巴巴、腾讯,以及国外的Google。猿辅导在今年3月6号提交了一个单模型,当时的单模型排名是第三,总体排名是第六。
MS-MARCO数据集
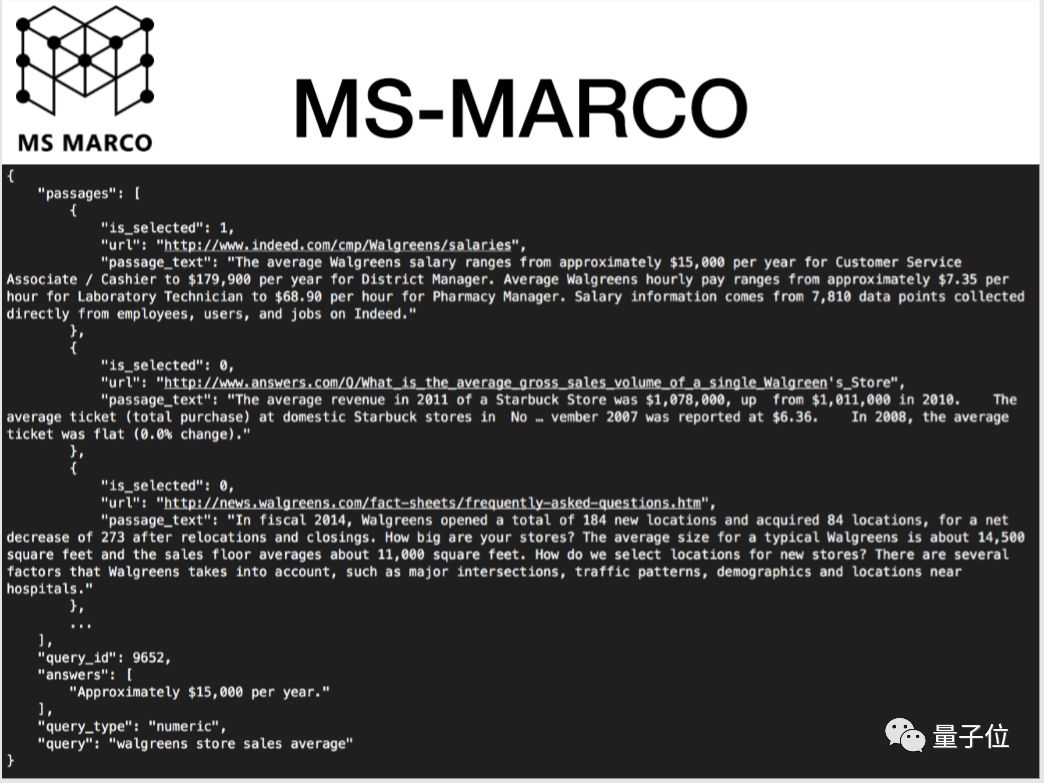
接下来看MS-MARCO这个语料,MS-MARCO语料实际上是有一个更加丰富的场景:当我们遇到一个问题之后,我们会将这个问题放到搜索引擎里面去检索,搜索引擎会给我们返回Top 10的结果,我们人会根据Top 10结果去浏览网页,然后去寻找到我们需要的答案。这个过程就分为两步:第一步是检索,第二步是人查找答案的过程。
微软发布这个语料的目的非常简单:能不能够用机器的方式在摘要里面去查找到问题的答案,这样就省去了人查找答案的过程。
这个数据集格式包含了第一部分是query,query是用户的真实查询,大部分是疑问句,还有小部分名词短语;第二部分是材料,实际上是Top 10结果的摘要,这里写的是passages,但是它在文章中并不是一个连续的段落,它更多的是通过摘要算法从文章中摘取的几段话然后拼接而成。
MS-MARCO语料与SQuAD语料

简单地比较一下MS-MARCO语料和SQuAD语料之间的区别。
首先是段落的数目:在SQuAD里,每个query只有一个段落;而在MS-MARCO里面每个query有多个段落。
平常我们在搜索的时候有一些经验,其实有些问题它可能在多个文章中出现,这就涉及到了答案融合。还有可能同样的答案在多个passage里出现,这个时候可以通过结合多个passage的预测结果做一些结果后处理(post-processing),这样能够帮我们提高模型的效果。
第二部分是关于answer,在stanford的这个语料里面,它要求答案必须是材料的一个子片。大多数模型都会选择一个指针网络去预测答案的起始位置和终止位置,但是MS-MARCO语料不是这样,它并没有对答案做约束,这个答案是由人工编辑的。
从直观上来讲,我们在选择模型的时候要选择一个端到端的生成式模型,我们输入的是query和passage,输出的是答案。但是这个语料的大小比较有限,在MS-MARCO的第一版本里训练的语料只有80k,我们觉得80k的语料很难支撑一个端到端的生成式模型。
另外我们分析了大量的case发现:虽然这些答案是由人自己去编辑的,但是它和文章之间有非常大的还原度,所以最后选择了和SQuAD类似任务的方式,将问题做了一个简化:还是去预测答案在文章中的位置,在训练的时候我们的训练label是每个passage中和答案最相似的片段。
接下来简单分析一下MS-MARCO。
首先是关于数据集,第一版有100K的数据并且按8:1:1划分,其中10K左右的数据作为评估数据。和SQuAD不一样的是,微软这个数据集是开放的,所以模型可以在本地上进行测试,只需要最后提交模型输出结果。
而SQuAD实际上是一个黑盒子,需要提交我们的模型,模型有大量需要预处理的词典,规模非常大,这样提交就不是很方便,并且codalab平台也不是非常稳定,我们3月6号在SQuAD提交的结果其实是2月5号做出来的,只不过在提交过程中有各种各样的问题,最后和stanford那边沟通过很多次才跑出结果。
答案和材料
现在我们来看下答案和材料之间的对比,这里将答案和材料的关系分为五类:
第一类是答案完全在材料里,是材料的一个片段。这部分可能和SQuAD是一样的,这部分语料占比是非常大的,大概占60%,如果我们再加上一些微小的差异的话这个比例就可以到80%;
第二类是答案中所有的词都在材料里,但是分布在不同的位置。这部分对我们模型而言是比较难的,它们的case也比较少;
第三部分是答案的词有一部分在材料里,一部分在问题里,因为有时候在回到问题的时候,为了让我们的回答更加完整,我们会去引用问题里的词;
第四部分是答案中有些词既不在材料里也不在问题里,这是因为众包的人有各自的语言习惯,有时候他们回去自己组织语言,用一些同义词去描述这个答案。
相对而言,下面三种语料在我们的case里占比非常小。最后一类是答案中所有的词都不在材料或者问题里,这里主要是一般疑问句,因为对一般疑问句的回答一般是yes或者no,根据我们搜索的经验,这些词肯定不会在材料里出现。
评估指标
接下来看一下评估指标,在这个任务里面有两个评估指标:ROUGE和BLEU。
首先看一下ROUGE,它的依据实际上也是一个最长的公共子序列,然后它通过计算出来的最长的公共子序列来计算召回率和准确率,然后通过一个平滑函数得到一个评估值。


BLEU算法有两部分:首先看后面的这一部分,它实际上是我们预测结果的一个准确率,我们看下面的公式,这个的分母实际上就是你的预测结果里面有多少个词,这个词可以是1-gram、2-gram、3-gram、4-gram。
分子是说我们预测出来的词有多少是在答案里面,然后整个公式实际上就是计算我们预测结果的准确率,如果说只有最后面一部分的话,那么我们的系统就会倾向于提供一些比较短的答案。所以为了惩罚这种情况,我们认为如果预测的答案和真实的答案之间的长度存在差异,那么就可能存在信息的缺失,然后就会对长度做一个惩罚。如果预测的结果没有真实的答案长的话,那么就会用一个指数公式去做惩罚。
开放式问答系统
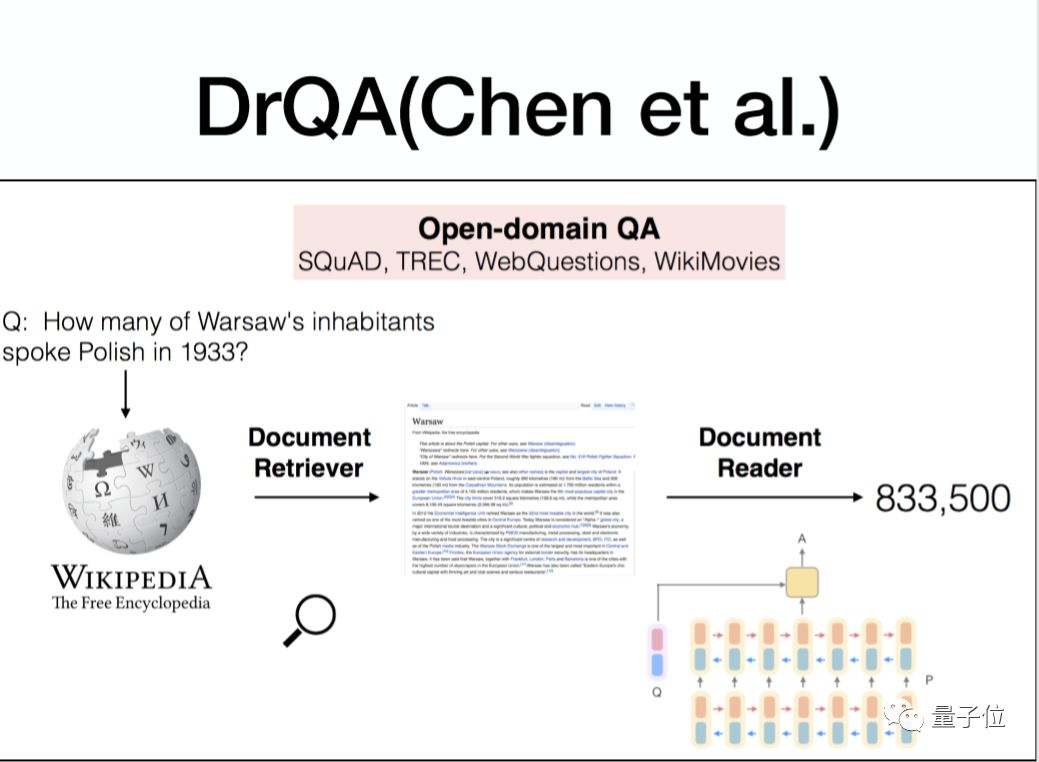
接下来看一篇关于开放式问答系统的论文。
这个论文实际上是为了解决开放式的问题,论文里有两部分:第一部分是检索系统,第二部分是阅读理解。
检索系统会在Wiki语料中建一份索引,任何一个问题来之后,首先去检索这个索引得到Top N query相关的一些材料,再用一个阅读理解的模块,然后去从这个材料里面去找到答案所在的位置。
总体来讲这个系统的准确率比较低,大概是35%。从现在看的话,可能这个系统对于开放式的问题而言,是一种比较现实的解决方案。而我们今天要讲的MARS(Multi-Attention ReaderS)其实也是试图去解决第二部分,然后提高第二部分的准确率。
整个网络的基本结构
接下来介绍整个网络的基本结构,将网络分成了三层:输入层、多轮交互层、预测层。
在输入层之前介绍下Transfer Learning。对于深度学习来说,一般认为在这个深度学习的网络里面,浅层的网络一般是在挖掘一些泛化的特征;与任务层相关的网络,更多的是挖掘与任务相关的特征。
浅层的网络挖掘出来的可泛化的特征,是不是可以在其他的任务上使用呢?如果通过Transfer Learning,新的任务就可以在浅层的网络借助已经训练好的参数,而我们在做模型训练的时候,只用关注与新任务相关的特征,就能提高模型的学习效果。
通过机器翻译的方式做Transfer Learning
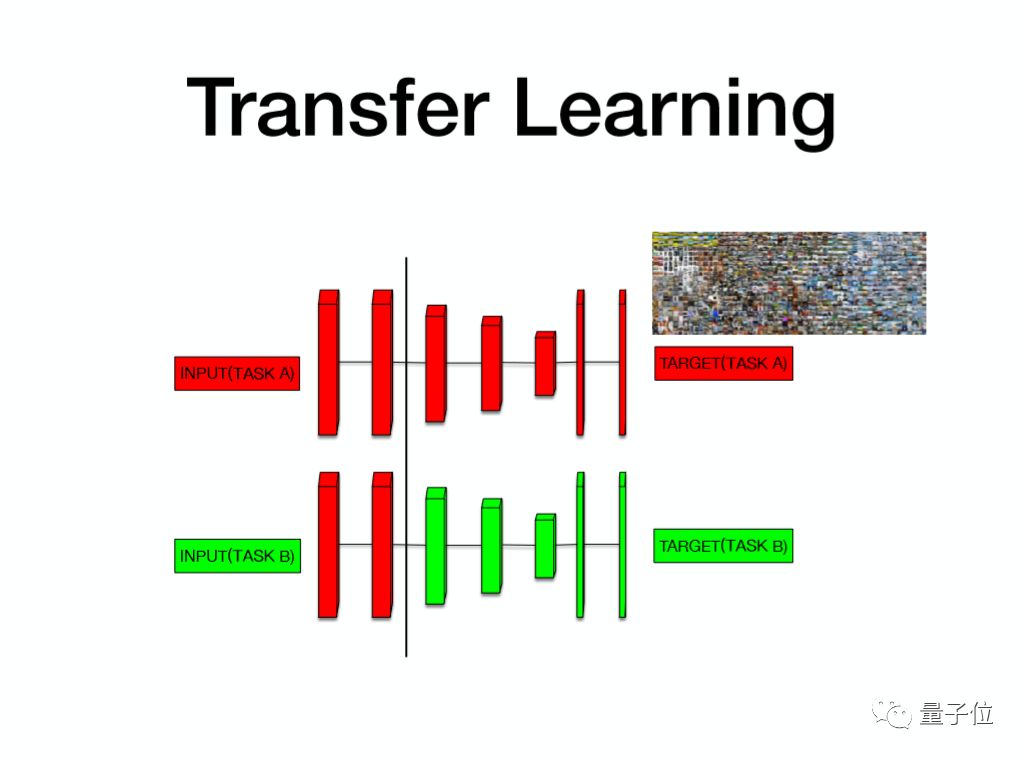
首先通过机器翻译的方式去做Transfer Learning。这个图上是一个简单的机器翻译框架,输入英语,输出中文。
一般的机器翻译的模型会有两部分:Encoder,是一个双向的RNN;然后是Decoder,将Encoder得到的信息,通过Decoder翻译成目标语言。这个Encoder的隐藏层除了包含这个词的输入信息以外,还包含这个词的上下文的信息,它的信息实际上比我们以前用到的词向量更加丰富。
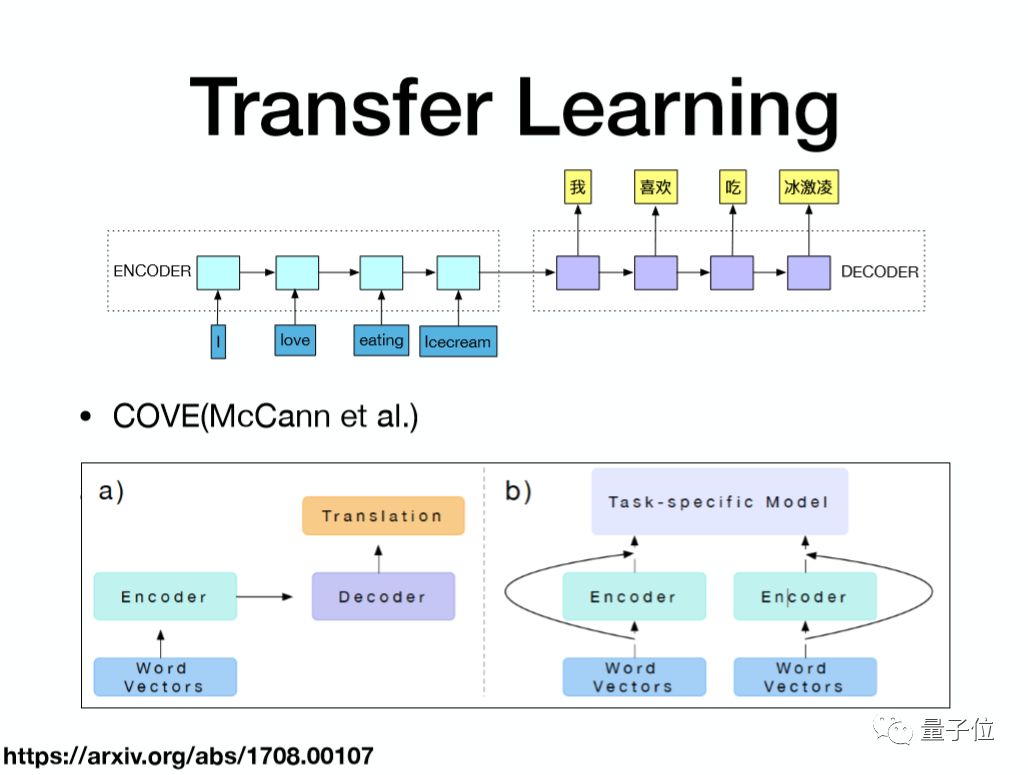
这是去年McCann团队发布的一个开源的预训练网络cove,用于机器翻译的双向RNN网络,左边是训练框架,输入是词向量,选择的是Stanford的300维的词向量,然后经过Encoder层和Decoder层做最终的预测,这样通过翻译的语料就可以得到一个已经训练好的Encoder层。
解决一个新任务的时候,可以将Encoder层和词向量一起作为这个任务的输入,输入信息就会更加的丰富。
现在应该有非常多机器翻译的语料,所以Encoder层的信息实际上是会非常丰富的,它也会非常大地提升新任务的效果。
通过语言模型做Transfer Learning
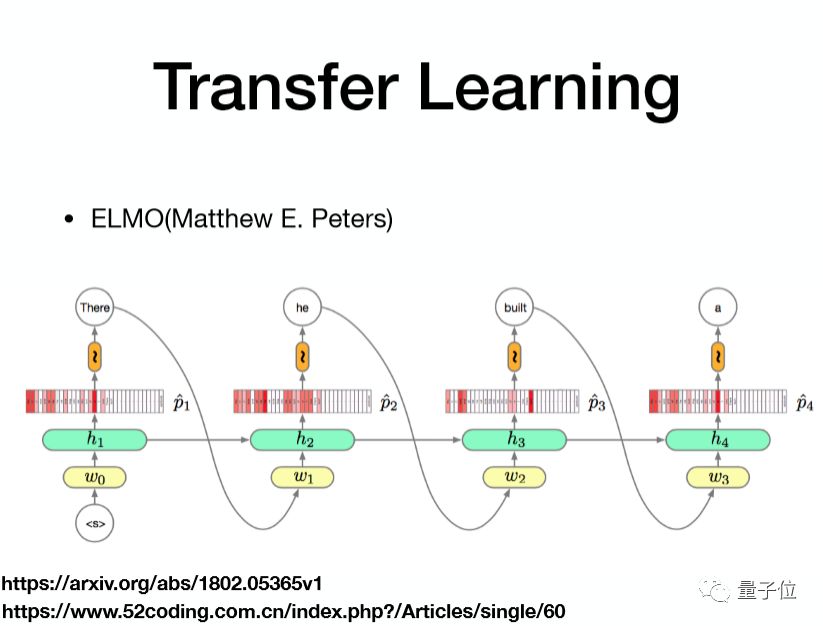
第二种是通过语言模型做Transfer Learning,上面这张图是一个RNN的语言模型,输入是一个词,然后输出的是下一个词。输入的这个词首先经过词向量,再经过一个RNN隐含层做softmax之后去预测下一个词。
同时也可以看到隐层的信息,它包含词的一个输入信息,同时还有从词的前端传过来的一些文本信息。一般情况下会去训练一个前向的RNN的语言模型和一个反向的RNN的语言模型,这样可以得到一个上下文的文本信息。因为语言模型它的数据成本更小,所以说我们可以用更多的数据来训练语言模型,实际上效果也很好。
网络结构
接下来看一下网络结构,一共分为三层:输入层、多轮交互层、预测层。从下往上看,在输入层会将所有抽取出来的特征过一个双向的RNN网络,然后对Question和Passage都做同样的操作。这里要注意,每一个Question实际上有多个Passage,对每一个Passage都会做相同的操作。
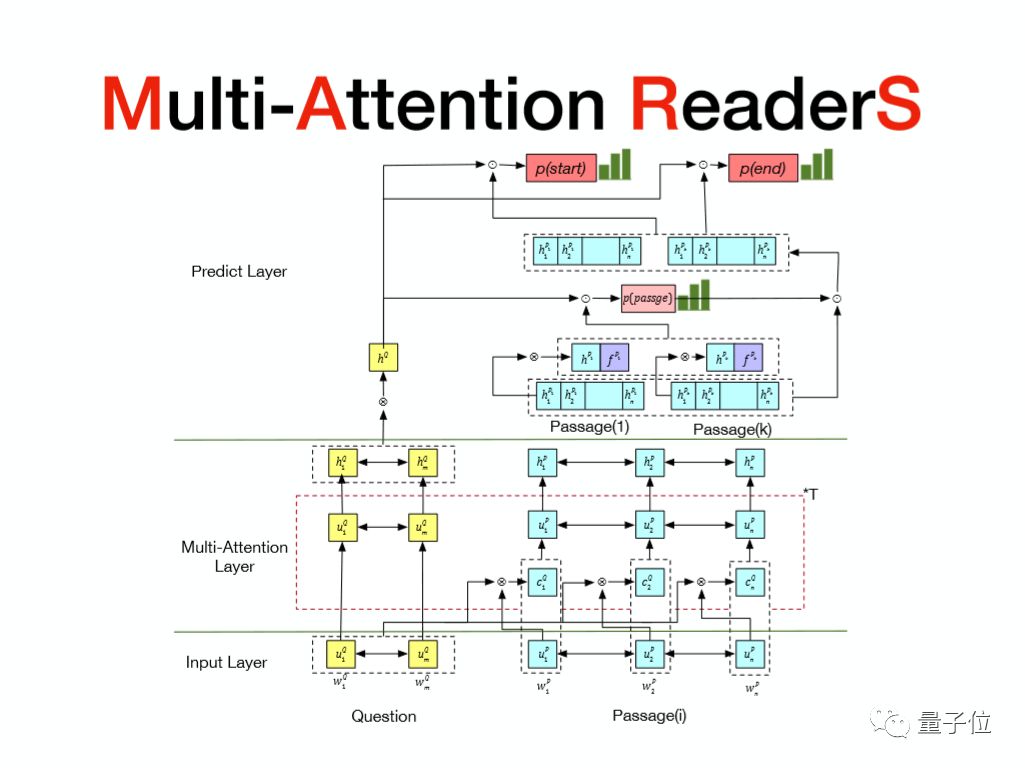
后面有关于词性和命名实体识别的一个Embedding,是因为我们语料相对而言比较少,所以说有大量的词出现的次数非常少,所以说会有一些泛化的pos或者NER去做一个Embedding,这样可以解决一部分这些词学习不够的问题。
最后是一个手工的feature,叫做word match,也就是去标识Passage里面的这个词是否在Question中出现。答案出现的位置一般都是在Query词的附近,然后将所有的输入信息一起经过一个双向RNN。
介绍一个非常有用的操作:word dropout。对输入的Passage的词用大概5%的概率将它们置成unknown,这样可以进一步地防止模型的过拟合。
接下来是多轮交互层。在多轮交互层里面,首先去计算这个Question里面每个词和Passage里面每个词的一个相似度,再将相似度做一个softmax的归一化。得到Passage的Attention信息之后,将这个信息和原始Passage的信息一起交给双向的LSTM,得到新的Passage编码。
对Question也会做一个双向的LSTM去得到新的一个编码,将这个Attention的过程重复迭代T次,得到多轮的关于Question和Passage的编码信息,再经过一个双向的LSTM得到最终Question的表示和Passage的表示。
接下来是预测层。在预测层里我们会去计算每个Passage包含答案的可能性。如何计算呢?
首先,已经有了Question里面每一个词的表示,然后根据Question的每一个词表示得到Question整体表示。
我们用的是Self-Attention方式,首先去计算Question里面每一个词的权重,然后将所有隐层信息加权得到Question的表示,对Passage也是一样,用相同的公式去得到这个Passage的一个表示,再将Question信息和Passage信息做一个卷积,然后做softmax就可以得到每个Passage包含答案的概率。
在这里要讲的就是关于Passage的信息,除了通过下面Self-Attention得到Passage的隐层信息以外,还有我们自己提取的一个特征:Site Embedding。
为什么会用到Site的信息呢?因为我们考虑到不同的站点包含答案的可能性不一样。我们计算出每个Passage的这个权重之后,将Passage的权重分发给里面每一个词的隐层信息,那么里面每一个隐层信息都会分享相同的权重,然后对权重做加权,得到最终我们Passage里每一个词的表示。
得到Passage里每一个词的表示之后,通过指针网络去预测答案的起始位置和终止位置,然后计算Question里面每个词和Passage里面每一个词的相似度,再做softmax,得到start和end的概率。
加入的其他功能

首先是多任务学习,多任务学习就是在输出层除了主要任务以外,还会加入其他的一些预测任务来帮助训练模型。
加入更多的预测信息,能够帮助模型得到更强的学习能力。而且有时候这些辅助任务的预测信息还可以帮助最终模型的输出。
首先看一下多任务,我们主要的任务是去预测答案所在的位置,然后在Passage里面去计算和答案最相似的一个片段,我们会将这个片段作预测目标。在这个预测目标下面,Golden Span实际上是对整个问题的简化。
为了使任务和真实的目的一致,又加入了其他的一些辅助任务,比如说在这里面我们会去描述一个词,看它是否是在答案里面,因为在Golden Span里,实际上有些词不在答案里。
第二个是预测Passage是否包含了Golden Span,这个地方在之前的模型里面也提到过,我们会去计算Passage包含答案的概率。他们的计算方式相似,但是作用不同,这里的passage的任务会给模型输出一个Loss,然后去帮助模型的训练。而在之前的模型里面,是通过修正模型的隐层信息,使其更加合理。
最后是关于这句话是否包含了Golden Span,为什么会有这样一个任务?因为Golden Span计算有一些天然的缺陷,重新来审视Golden Span,它要求和答案最相似的一个片段,那么有两部分,第一部分就是一个最长公共子序列,要求包含的最长公共秩序的这个子序列最长。
第二部分是希望计算出来的最长公共子序列的Golden Span尽可能短。那么会有一个问题:Golden Span的第一个词和最后一个词都在答案里面,也就是说Golden Span很有可能只是答案里的一个子串,它的长度是要比真实的答案短,它并不是一个真正意义上的答案的起始位置和终止位置。所以我们加入了检测Sentence是否包含Golden Span这一部分,试图减少主任务的影响,帮助模型学习。
这些任务可以帮助原始任务的学习,主要的任务是对原始任务的简化,我们加入辅助任务之后,使模型更加的合理,也可以给模型一些依据,以便于评估最好的答案。
EMA
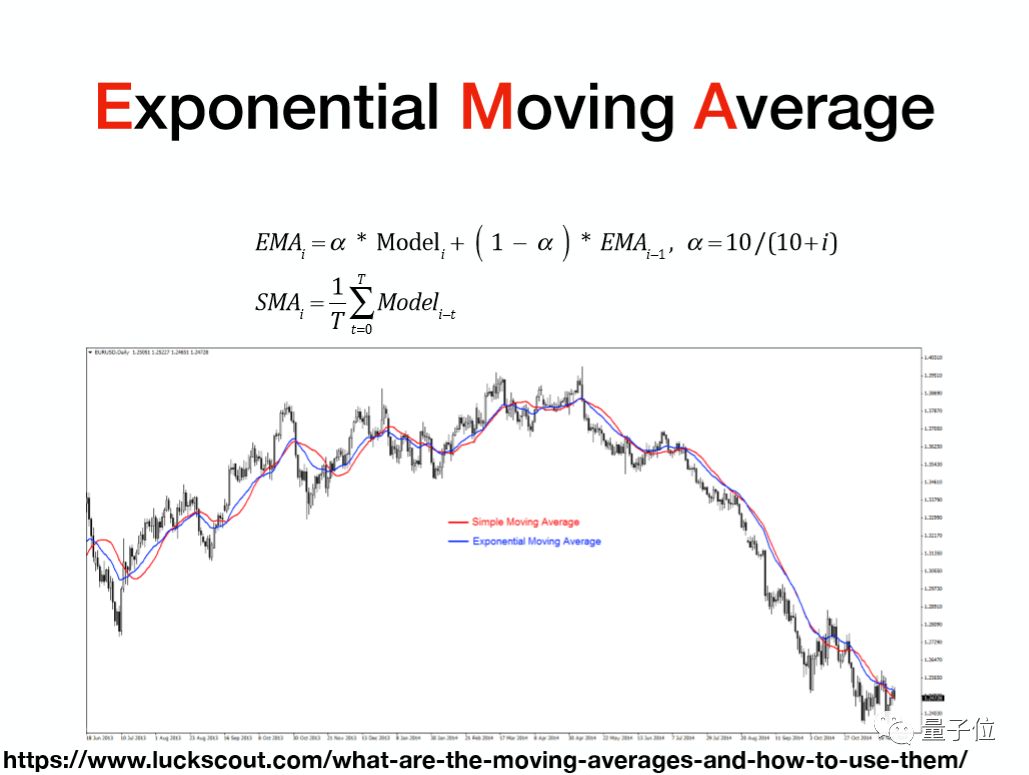
接下来是EMA(Exponential Moving Average)。EMA实际上是在股票里面用得非常多的名词,每天股价都在波动,而我们为了看股票价格的走势,会画一个相对而言比较平滑的曲线,这个曲线一般会用EMA的曲线。
下面这个图里波动非常剧烈的这条线,可以看作是股价在每天的波动,而这里边有两条线:一条是红色的线,一条是蓝色的线。红色的线是一个简单的SMA(Single Moving Average),是一个简单的平均曲线,它的计算方式是将前七天的数据做一个平均,得到一个平滑的点。
这样计算的坏处是什么?就是在对待前七天数据的时候,每一天的权重是一样的。在看股票走势的时候,可能我们更关注的是它当前的价格,距离当前信息越远的信息应该权重越小。
EMA就是来解决这个问题,它加入了一个指数的衰减,会对当前的价格取一个权重,然后越往前的权重越小,呈指数地衰减。所以EMA比SMA能更好地去描述股票的价格。
模型提升
那怎么样去帮助模型提升呢?在模型训练的时候有一些假设,比如说是按照一个batch、一个batch去训练模型,假设每一个batch的分布和真实样本的分布是比较一致的,那么通过一个batch、一个batch去更新参数,就具有合理性。
但在模型里面,因为数据非常大,在batch的设置的时候会非常的小,导致数据的分布差异很大。如果每一个batch的数据差异非常大,最终模型的输出就可能和每个batch之间的顺序相关。为了弱化这种影响,我们会在模型的训练中间,计算EMA的状态,然后更新,再用最终的EMA的信息去预测待评估的数据。在一般情况下EMA的模型会比原始模型更加稳定,效果也会好一点。
多文档投票

指针网络是可以计算出来全局最优的答案文本,那为什么会有多文档的投票?我们都会有一些经验:在搜索的时候,发现搜索答案好像在每一个Top10的网页里面都有。每一个网页的Passage都可能会有一个候选的答案,这些候选的答案,实际上是可以帮助我们做结果糅合。
在这里面,假设有N个候选结果,怎么样根据N个候选结果去挑选一个最终结果呢?
有一个评估的公式,公式里有两部分:
第一部分是原始的指针网络得到的分数,第二部分是其他的结果对当前结果的支撑度。这个指针网络的分数,实际上就是这个答案在文本中start概率和end概率相乘。
投票的信息怎么理解?假设其他的结果如果是真实的答案,当前的这个结果期望得多少分?我们希望系统去选择一个期望得分最高的文本,这样我们的模型在评估的时候会效果更好。
ROUGE的公式里面左边是预测结果,而右边是我们假设的真实答案,考虑到每个Passage产生的结果的概率不一样,那么用到他们在指针网络里面得到的分数作为概率。
这里面有一些平滑公式,首先要求评估分数尽可能考虑两边的因素,我们会加一个非常大的平滑,使Span分数的影响会尽可能小。
这种方法和简单的计数有什么区别?我们在做简单计数的时候,会去算每条结果出现的次数,然后选择一个次数最高的。但是对于一个文本而言,越短的文本在多个文档中出现的可能性越高,越长的文本很难在多个文本中出现。
通过一个简单的计数器,预测出来结果就会偏短。BLEU算法实际上会对答案的长度做一个非常大的惩罚,如果用简单的计数器的话,模型BLEU的值就会非常的低。
再就是Ensemble,我们的Ensemble非常简单:大概训练了12个单模型,每个单模型的种子不同,其他都是一样,再通过简单的投票,选择了一个最好的结果。Ensemble的ROUGE比单模型的效果好大概一个点。
猿辅导正在招聘:服务器端、前端后端、算法、机器学习、深度学习、产品、设计、运营都有需求,感兴趣的同学欢迎发送简历给HR:recruit@fenbi.com。
Q&A
语言的Transfer Learning里面两个RNN隐层的贡献,ELMO的贡献实际上是COVE的贡献比较大吗?
其实我们公司主要是在做SQuAD的,3月6号我们的SQuAD得到一个排名之后,花了大概半个月的时间做MS-MRACO的语料,所以在MS-MRACO这个语料上没有做非常细的一些结果分析。
在SQuAD上,COVE这个语料,通过机器翻译预训练RNN的隐层大概可以提升1.5%左右,就是F1的值可以提高1.5%,语言模型可以提高2%左右,也就是提高两个点的F1。
你们有这么多的任务,每个任务选择一个什么样的权重?关于这个任务的Loss函数是怎么设计的?
这个Loss函数,实际上也是用Softmax,去计算Loss。关于每个任务的权重,我们主要的任务是1,然后辅助的任务的话一般是0.1或者0.2。
关于平滑函数的选择
我们在平滑函数里面,因为Span的得分是依据指针网络的结果,我们通过Softmax算出来start概率和end概率之后,每一个候选答案的差异实际上就会非常大,所以我们大概是开了四次方。
多任务怎样调每个task?
多任务应该是调task的权重,主要任务是1的权重,其他的任务就是0.1和0.2,没有做过多的调整。
训练时间有多长?机器是怎样的?
训练大概是花了三天的时间。因为语言模型是最慢的,算ELMO语言模型的时候非常慢,大概是要花三天,大概有20个epoch左右。
相关学习资源
以上就是此次猿辅导柳景明带来分享的全部内容,在量子位公众号(QbitAI)界面回复“180419”可获得完整版PPT以及视频回放链接。
P.S. 量子位·吃瓜社将持续带来线上的技术分享,欢迎大家关注~
— 完 —
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。

量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态



