ThunderNet | Two-stage形式的目标检测也可很快而且精度很高

一
导读
在移动平台上进行实时通用目标检测是一项至关重要但具有挑战性的计算机视觉任务。然而,以往基于cnn的检测器面临着巨大的计算成本,这阻碍了它们在计算受限的情况下进行实时推断。
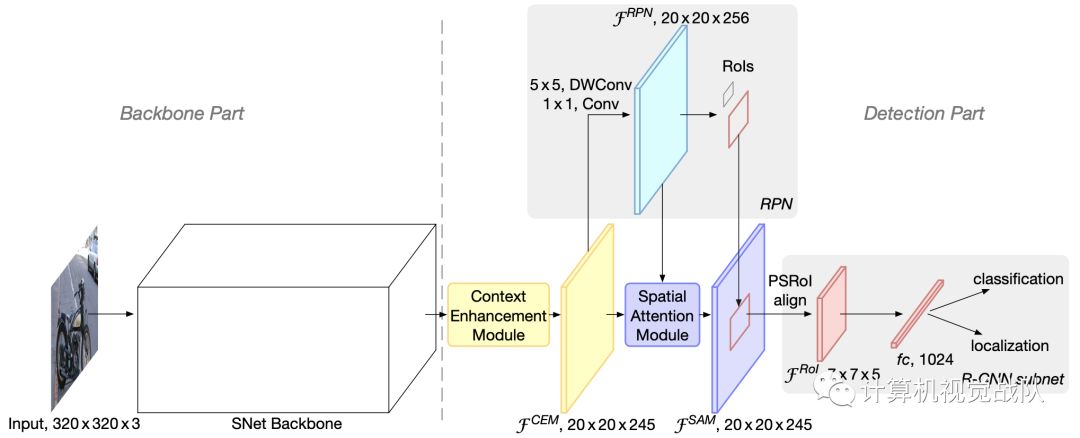
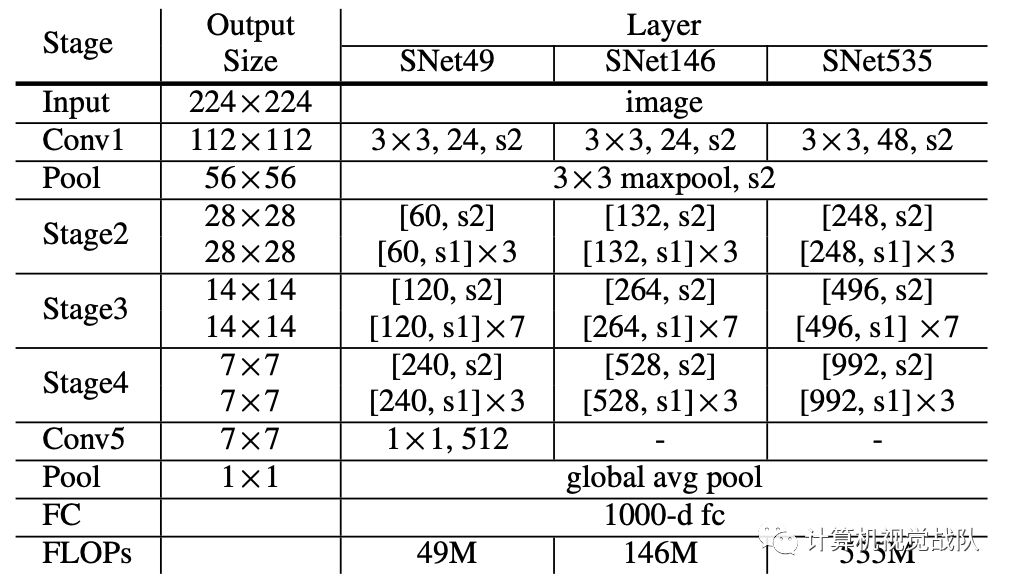
今天,我们说的这个研究了two-stage检测器在实时通用检测中的有效性,提出了一种名为ThunderNet的轻量级的two-stage检测器。在主干部分,分析了以往轻量级主干网的不足,提出了一种面向目标检测的轻量级主干网络。在检测部分,开发了一种非常有效的RPN和detection head设计。为了产生更多的判别特征表示,设计了两个有效的体系结构块:上下文增强模块和空间注意力模块。
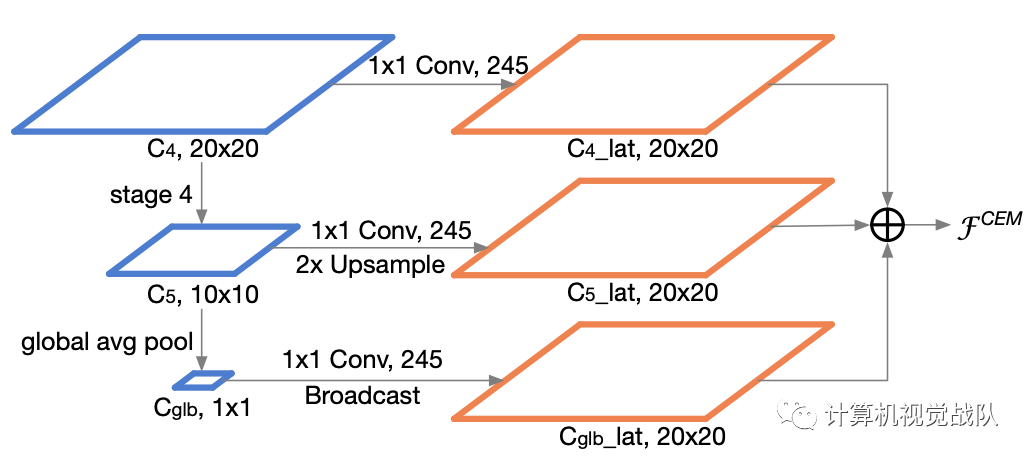
Context Enhancement Module (CEM)
Spatial Attention Module (SAM)
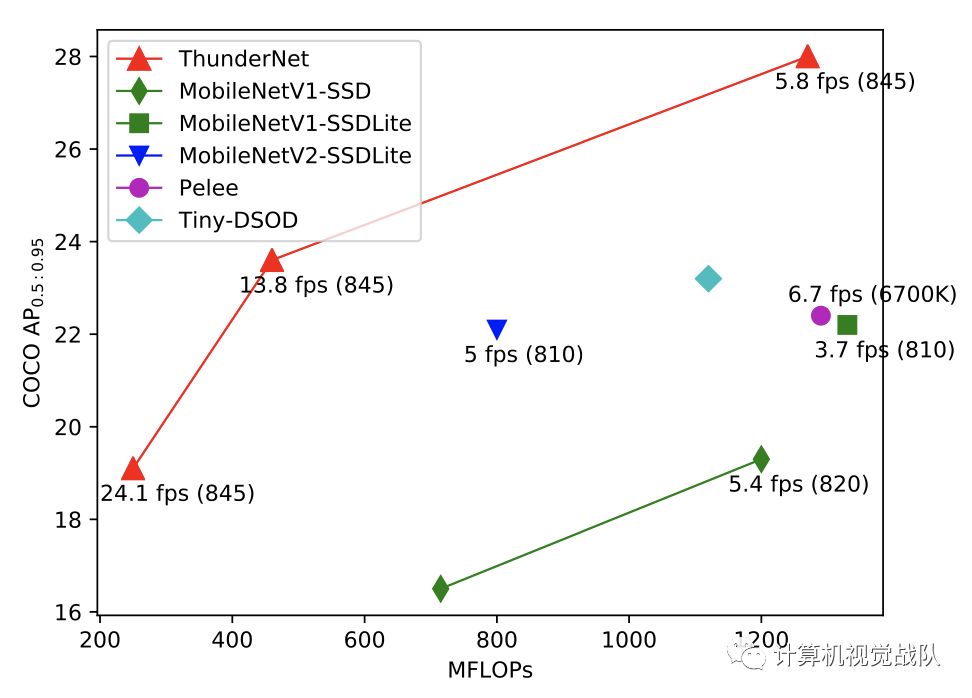
最后,还研究了输入分辨率、主干网络和detection head之间的平衡。与轻量级one-stage检测器相比,ThunderNet在Pascal、VOC和COCO基准上仅占计算量的40%,实现了更好的性能。没有bells和whistles,新模型在基于ARM设备上运行为24.1 fps。这是第一个在ARM平台上报告的实时检测器。
背景介绍

新框架
Input Resolution
two-stage检测器的输入分辨率通常很大,例如FPN使用800×800像素的输入。它带来了许多优点,但也带来了巨大的计算成本。为了提高推理速度,ThunderNet采用320×320像素的输入分辨率。此外,在实践中,观察到输入分辨率应该与主干网的能力相匹配。大输入的小主干和小输入的大主干都不是最优的。
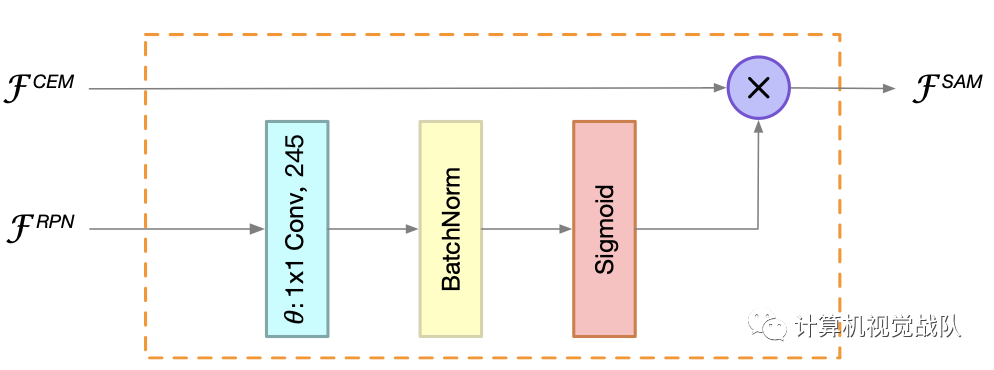
Spatial Attention Module
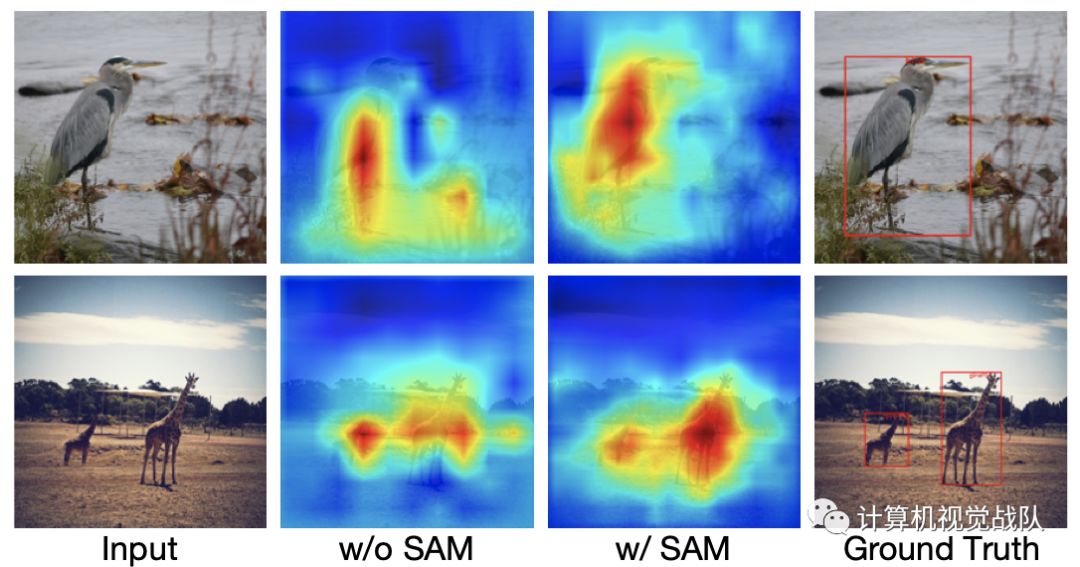
在ROI warping过程中,将背景区域中的特征扩展为小区域和前景区域变大。然而,与大型模型相比,由于ThunderNet使用了轻量级的主干和较小的输入图像,因此网络本身很难学习到合适的特征分布。
为此设计了一个计算友好型空间注意力模块(SAM),在ROI对空间维数进行warping之前,可以显式地重新加权特征图。SAM的核心思想是利用RPN中的知识来细化特征图的特征分布。RPN被训练用于在GT的超分辨下识别前景区域。因此,RPN中的中间特征可以用来区分前景特征和背景特征。
实验结果
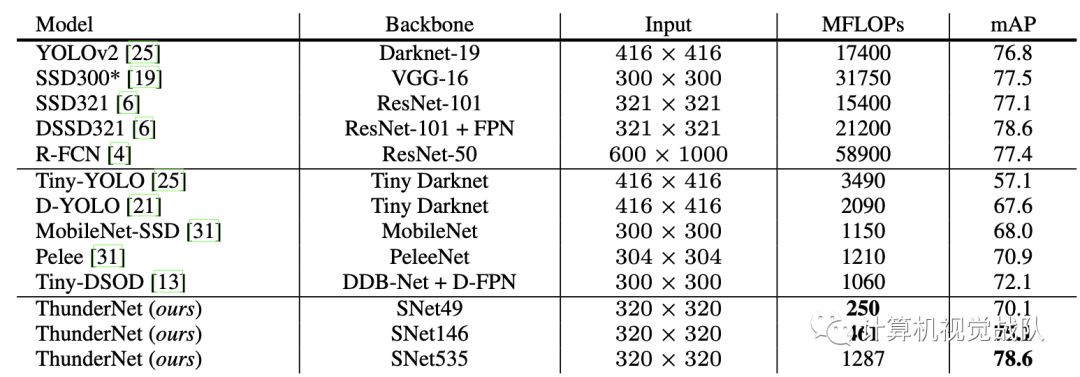
PASCAL VOC数据集由来自20个类的自然图像组成。这些网络是在VOC2007训练和VOC2012训练的联合集合上进行训练的,在VOC2007测试中重新获得了single-model的结果,结果如下表所示:
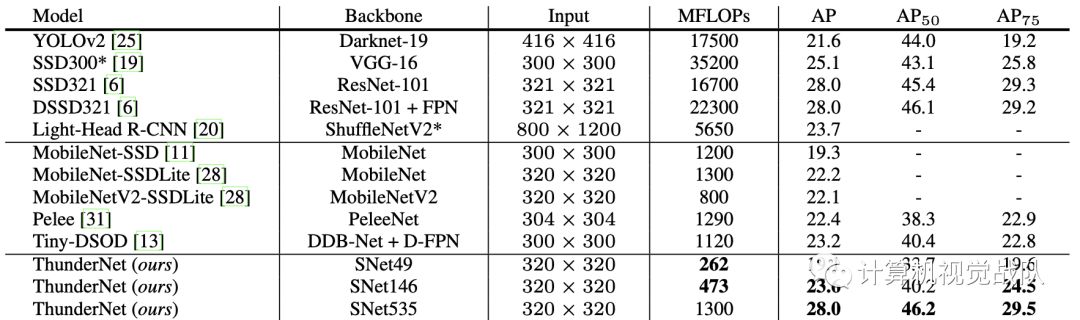
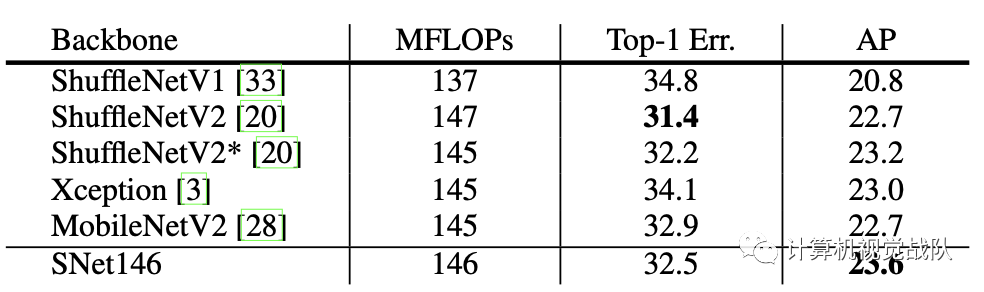
下表是在COCO数据集的结果:
检测结果可视化


END
如果想加入我们“计算机视觉战队”,请扫二维码加入学习群。计算机视觉战队主要涉及机器学习、深度学习等领域,由来自于各校的硕博研究生组成的团队,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。
我们开创一段时间的“计算机视觉协会”知识星球,也得到很多同学的认可,我们定时会推送实践型内容与大家分享,在星球里的同学可以随时提问,随时提需求,我们都会及时给予回复及给出对应的答复。

微信学习讨论群也可以加入,我们会第一时间在该些群里预告!

