卡耐基梅隆大学提出新型「自适应」技术,可提高「个性化神经机器翻译」质量

作者:Paul Michel、Graham Neubig
「雷克世界」编译:嗯~是阿童木呀
导语:现如今,随着人工智能的发展,机器翻译在一定程度上取得了很大的进展,但是大家都知道,语言的产生取决于演讲者或作者,它可能会反映诸如工作、性别、角色、方言等个人特征,也可能涉及诸如技术、法律、宗教等将要谈及的话题。而对于当前的神经机器翻译(Neural Machine Translation,NMT)系统来说,其中不包含关于演讲者的任何明确信息,从而这迫使模型隐式地学习这些特征。最近,美国卡耐基梅隆大学(Carnegie Mellon University)的Paul Michel和Graham Neubig教授提出了一种新型的自适应技术,能够显著提高神经机器翻译的精确度,并能够在目标文本中更好地反映演讲者的特征,从而实现“个性化神经机器翻译”。
在世界上,可以说每个人都会说或会写自己的母语,但受很多因素的影响,他们所倾向于谈论的内容大多是有关他们的性别、社会地位或地理来源。当试图执行机器翻译(Machine TranslationMT)的时候,这些变化对系统应该如何执行翻译有着重大影响,但是这并不能被标准的“一体适用”(one-size-fits-all)模型很好地捕捉到。在本文中,我们提出了一种简单且参数有效的自适应技术,它只需要直接或通过因式近似(factored approximation)来将输出softmax的偏差适应于MT系统的每个特定用户。用三种语言进行TED演讲的实验结果表明了翻译精确度的提高,并能够在目标文本中更好地反映演讲者的特征。
一般来说,语言的产生取决于演讲者或作者,它是否反映了个人特征(例如工作、性别、角色、方言)或倾向于讨论的话题(例如技术、法律、宗教)。当前的神经机器翻译(Neural Machine Translation,NMT)系统不包含关于演讲者的任何明确信息,而这迫使模型隐式地学习这些特征。这是一种用于捕捉个人间差异的相对来说比较困难和间接的方式,在某些情况下,如果没有外部上下文,这是不可能实现的(见表1,Mirkin等人于2015年提出)。

表1:样本展示,其中演讲者的信息会影响英语-法语的翻译
在最近的一些研究中包含了关于作者的个人信息,如个性(Mirkin等人于2015年提出)、性别(Rabinovich等人于2017年提出)或礼貌文雅性(Sennrich等人于2016年提出),但这些方法只能处理哪些特征具有明确标签的现象。我们的研究调查了我们该如何有效地对与说话者相关的变化进行建模以改进NMT模型的性能表现。
特别地,考虑到对于任何特定的演讲者来说都只提供少量的训练样本,所以我们有意向对我们的NMT系统加以改进。我们提议将这个任务作为一个域自适应问题加以处理,其中,里面包含了大量的域,而每个域中拥有非常少量的数据,在这样的环境中,我们可以期望域自适应的传统方法能够将所有模型参数调整为次优。我们所提出的解决方案涉及将演讲者的特定变化建模为softmax层中的附加偏差向量,在其中,我们可以直接学习这种偏差,或者通过一个将每个用户视为几个原型偏向量混合的因式分解模型来进行学习偏差。
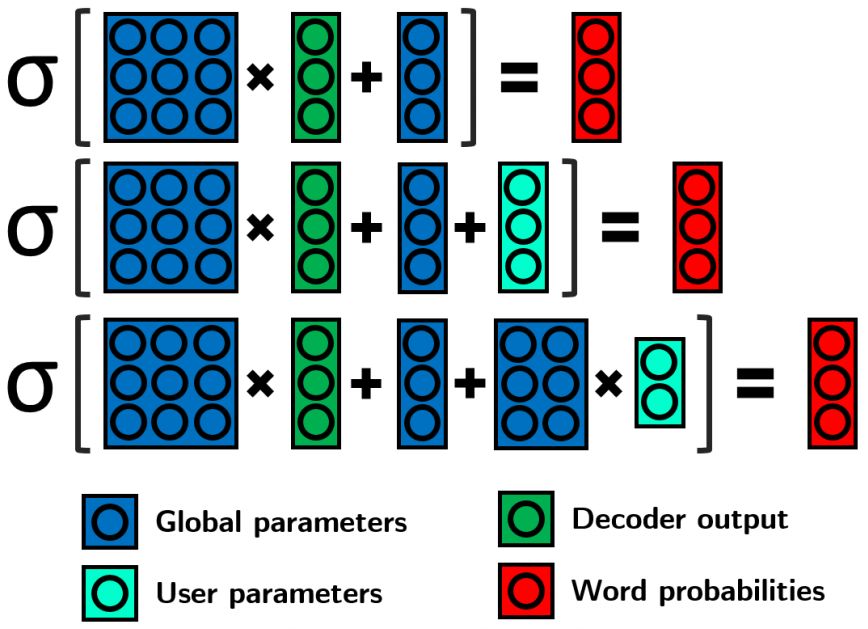
图1:我们针对softmax层的不同自适应模型的图形表示 从上到下依次为:基本softmax、完全偏差softmax、事实偏差softmax
为了更好地进行实验,我们构建了一个新的带有演讲者注释的TED演讲数据集(SATED),用以对我们所提出的方法加以验证。自适应实验结果表明,将演讲者信息明确地纳入到模型中可以提高翻译质量和演讲者特征的精确度。
可以这样说,用于MT的域自适应技术通常依赖于数据选择(Moore和Lewis于2010年、Li等人于2010年、Chen等人于2017年、Wang等人于2017年提出)、调优(Luong和Manning于2015年、Miceli Barone等人于2017年提出),或者将域名标签添加到NMT输入中(Chu等人于2017年提出)。除此之外,还有一些方法可以对测试集中每个句子的模型参数进行微调(Li等人于2016年提出),以及对根据人类后期编辑进行自适应的方法(Turchi等人于2017年提出)。尽管这些方法遵循我们的基线自适应策略来调整所有参数。对于迁移学习,也有部分更新方法,尽管语言对之间的迁移任务非常不同(Zoph等人于2016年提出)。
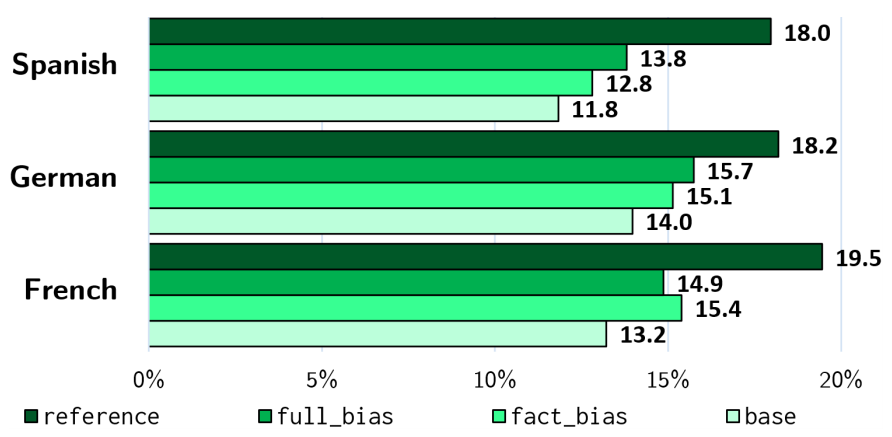
图2:我们连续的n-gram模型的演讲者分类精确度。
Mima等人(于1997年进行)的开创性研究引入了多种方法以便将各种关于演讲者角色、等级、性别和对话域的信息整合到基于规则的MT系统中。在数据驱动系统的上下文中,以往的研究将特定的特征(如礼貌文雅性或性别)视为域自适应模型中的“域”,并应用了自适应技术,例如在温和的礼貌中加入“礼貌标签”(Sennrich等人于2016年提出),或者做数据选择以创建用于训练的性别特定语料库(Rabinovich等人于2017年提出)。可以说,上述方法与我们的方法大有不同,不同之处在于它们需要明确的信号(性别、礼貌等等),它们需要标记(手动或自动),并且还要处理有限数量的“域”(≈2),而我们的方法需要对演讲者进行注释,并且必须将其扩展到更多的“域”中(≈1,800)。
在本文中,我们已经解释并激发了在NMT系统中对演讲者进行明确建模的挑战,然后提出了两个模型以参数有效的方式来实现这一点。我们把这个问题作为一种极端的域自适应形式,并且表明,即使在自适应一小部分参数(softmax偏差,小于所有参数的0.1%)时,也能够使得该模型通过翻译更好地反映个人语言的变化。
我们通过进一步的实验结果表明,特定于任何人的参数数量可以减少到10个,而仍然能够保留比某些语言对的基线更好的分数,从而使其在具有潜在数百万不同用户的实际应用中加以应用。
相关代码资源
该存储库包含《用于个性化神经机器翻译的极端自适应技术》论文中所涉及的相关代码。
数据
本文中所使用的数据是SATED数据集,可点击链接查看。
此外,论文中所涉及的附加实验是在来自于论文《个性化机器翻译:保留原作者特征》中性别注释的europarl语料库,可点击链接查看。
你可以通过运行下面的代码下载所有数据:
# SATED
wget http://www.cs.cmu.edu/~pmichel1/hosting/sated-release-0.9.0.tar.gz
tar xvzf sated-release-0.9.0.tar.gz
# Europarl
https://www.kaggle.com/ellarabi/europarl-annotated-for-speaker-gender-and-age/downloads/europarl-annotated-for-speaker-gender-and-age.zip
unzip europarl-annotated-for-speaker-gender-and-age.zip
要求
该项目是用Dynet进行编码的。它应该用的是2.0.3版本,你可以通过运行下面的代码安装该版本:
pip install dynet==2.0.3
原文链接:https://arxiv.org/pdf/1805.01817.pdf
未来智能实验室是人工智能学家与科学院相关机构联合成立的人工智能,互联网和脑科学交叉研究机构。
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)云脑研究计划,构建互联网(城市)云脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”



