2018年自然语言取得不错的研究有哪些?
在上一年里自然语言处理出现许多令人兴奋的研究成果。从概念到实战项目都有涉及,它们的创造为 NLP(自然语言处理英语缩写) 注入了新鲜的活力。其中最突出的就是机器翻译与预训练语言模型,机器翻译已经由去年的 Seq2Seq 变成今年大量使用 Transformer,而预训练语言模型则是从 ELMo 到 BERT 进行了深远的发展。
预训练语言模型
很多人认为自然语言处理预训练的意义不是特别大,都感觉直接在特定任务上做训练可能效果会更好。但是随着计算机视觉领域中预训练模型的广泛使用,很多 NLP 的研究者也在思考是不是能有一种方法,它可以将通用的语言知识迁移到不同的 NLP 任务中。在实践过程中大家开始逐渐选定了语言模型,首先它是一种无监督方式,所以训练样本很容易获取。其次语言模型能预测一个词序列是人类话语的概率,因此某种意义上它包含了通用的语言知识。因此在 2018 年中,使用预训练语言模型可能是 NLP 领域最显著的趋势,它可以利用从无监督文本中学习到的「语言知识」,并迁移到各种 NLP 任务中。
这些预训练模型有很多,包括 ELMo、ULMFiT、OpenAI Transformer 和 BERT,其中又以 BERT 最具代表性,它在 11 项 NLP 任务中都获得当时最佳的性能。不过目前有 9 项任务都被微软的新模型超过。
ULMFiT

ULMFiT来自论文Universal Language Model Fine-tuning for Text Classification,它是一个预训练模型,同时用Python进行了开源。论文已经经过了同行评议,并且将在ACL 2018上作报告。
项目链接: nlp.fast.ai/category/classification.html
如上接提供了对论文方法的深度讲解视频,以及所用到的Python模块、与训练模型和搭建自己模型的脚本。
ULMFiT 由 Sebastian Ruder 和 fast.ai 的 Jeremy Howard 设计,是首个将迁移学习应用于 NLP 的框架。ULMFiT 表示 Universal Language Model Fine-Tuning(通用语言模型微调)。ULMFiT 真的实现了「通用」,该框架可用于几乎所有 NLP 任务。
该论文的下载地址:https://arxiv.org/pdf/1801.06146.pdf
同时可以在其项目链接中找到其源码。
ULMFiT 最好的地方在于我们不用再从头训练模型了。研究者把最难的部分做好了,直接将他们做好的模型用到自己的项目中即可。ULMFiT 在六个文本分类任务上优于之前最优的方法。
ULMFiT 主要可以分为三个阶段:
在通用领域实现语言模型的预训练
在目标任务实现语言模型的微调
在目标任务的分类器微调
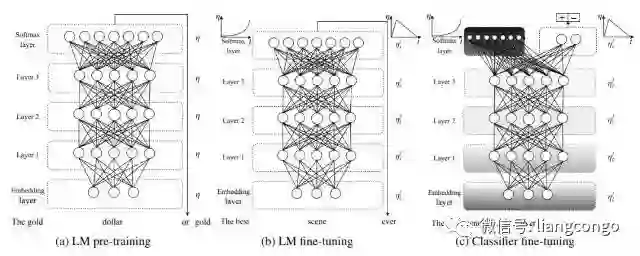
如上所示,ULMFiT 主要由三阶段组成。(a)中的预训练语言模型能捕获自然语言的一般特征,而(b)中的语言模型会使用判别性的微调(Discr)和斜三角式的学习率来进行调整,它将在目标任务上学习到特定的特征。最后(c)表示分类器在目标任务上的微调,其中灰色表示不固定权重的阶段,而黑色表示固定权重的阶段,这样能保留低级表示而适应地调整高级表示。
感兴趣的读者可参考以下内容:
https://github.com/prateekjoshi565/ULMFiT_Text_Classification
http://nlp.fast.ai/category/classification.html
ELMo
ELMo 是 Embeddings from Language Models 的缩写。ELMo 一经发布即引起了机器学习社区的关注,它使用语言模型来获取每个单词的词嵌入,同时考虑单词在句子或段落中的语境。这种添加了语境信息的词表征可以表示复杂的语言知识,因此也就可以编码整个句子的信息。
论文:Deep contextualized word representations
论文链接:https://arxiv.org/pdf/1802.05365.pdf
具体而言,研究者使用从双向 LSTM 中得到的向量,该 LSTM 是使用正向和反向两个语言模型(LM)在大型文本语料库上训练得到的。用这种方式组合内部状态可以带来丰富的词表征。研究者使用内在评价进行评估,结果显示更高级别的 LSTM 状态捕捉词义的语境依赖方面(如它们不经修改就可以执行监督式词义消歧任务,且表现良好),而较低级别的状态建模句法结构(如它们可用于词性标注任务)。同时揭示所有这些信号是非常有益的,可以帮助学得的模型选择对每个任务最有帮助的半监督信号。
与 ULMFiT 类似,ELMo 极大提升了在大量 NLP 任务上的性能,如情感分析和问答任务。如下展示了 ELMo 在不同 NLP 任务中的效果,将 ELMo 加入到已有的自然语言系统将显著提升模型效果。
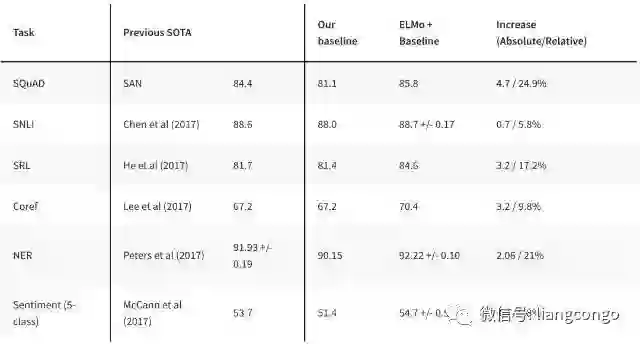
更多信息及预训练 ELMo 模型可查看:https://allennlp.org/elmo
NAACL 2018 | 最佳论文:艾伦人工智能研究所提出新型深度语境化词表征
BERT
BERT 是一种新型语言表征模型——来自 Transformer 的双向编码器表征。与最近的语言表征模型不同,BERT 旨在基于所有层的左、右语境来预训练深度双向表征。BERT 是首个在大批句子层面和 token 层面任务中取得当前最优性能的基于微调的表征模型,其性能超越许多使用任务特定架构的系统,刷新了 11 项 NLP 任务的当前最优性能记录。
BERT 的的核心过程是它会先从数据集抽取两个句子,其中第二句是第一句的下一句的概率是 50%,这样就能学习句子之间的关系。其次随机去除两个句子中的一些词,并要求模型预测这些词是什么,这样就能学习句子内部的关系。最后再将经过处理的句子传入大型 Transformer 模型,并通过两个损失函数同时学习上面两个目标就能完成训练。
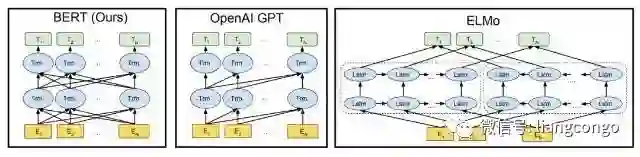
如上所示为不同预训练模型的架构,BERT 可以视为结合了 OpenAI GPT 和 ELMo 优势的新模型。其中 ELMo 使用两条独立训练的 LSTM 获取双向信息,而 OpenAI GPT 使用新型的 Transformer 和经典语言模型只能获取单向信息。BERT 的主要目标是在 OpenAI GPT 的基础上对预训练任务做一些改进,以同时利用 Transformer 深度模型与双向信息的优势。
这种「双向」的来源在于 BERT 与传统语言模型不同,它不是在给定所有前面词的条件下预测最可能的当前词,而是随机遮掩一些词,并利用所有没被遮掩的词进行预测。
更详细的论文解读可以查看:谷歌终于开源 BERT 代码:3 亿参数量,机器之心全面解读
此外,BERT 的开源项目非常有诚意,谷歌研究团队开放了好几种预训练模型,它们从英语到汉语支持多种不同的语言。很多开发者在这些 BERT 预训练语言模型上做二次开发,并在不同的任务上获得很多提升。
BERT开源项目地址: https://github.com/google-research/bert
机器翻译
在 2018 年里,神经机器翻译似乎有了很大的改变,以前用 RNN 加上注意力机制打造的 Seq2Seq 模型好像都替换为了 Tramsformer。大家都在使用更大型的 Transformer、更高效的 Transformer 组件。例如阿里根据最近的一些新研究对标准 Transformer 模型进行一些修正。这些修正首先体现在将 Transformer 中的 Multi-Head Attention 替换为多个自注意力分支,其次他们采用了一种编码相对位置的表征以扩展自注意力机制,并令模型能更好地理解序列元素间的相对距离。
有道翻译也采用了 Transformer,他们同样会采取一些修正,包括对单语数据的利用、模型结构的调整、训练方法的改进等。例如在单语数据的利用上,他们尝试了回译和对偶学习等策略,在模型结构上采用了相对位置表征等。所以总的而言,尽管 Transformer 在解码速度和位置编码等方面有一些缺点,但它仍然是当前效果最好的神经机器翻译基本架构。
Sebastian Ruder 非常关注无监督机器翻译模型,如果无监督机器翻译模型是能行得通的,那么这个想法本身就很惊人,尽管无监督翻译的效果很可能远比有监督差。在 EMNLP 2018 中,有一篇论文在无监督翻译上更进一步提出了很多改进,并获得极大的提升。Ruder 笔记中提到了以下这篇论文:
论文:Phrase-Based & Neural Unsupervised Machine Translation
论文链接:https://arxiv.org/abs/1804.07755
这篇论文很好地提炼出了无监督 MT 的三个关键点:优良的参数初始化、语言建模和通过回译建模反向任务。这三种方法在其它无监督场景中也有使用,例如建模反向任务会迫使模型达到循环一致性,这种一致性已经应用到了很多任务,读者最熟悉的可能是 CycleGAN。该论文还对两种语料较少的语言做了大量的实验与评估,即英语-乌尔都语和英语-罗马尼亚语。
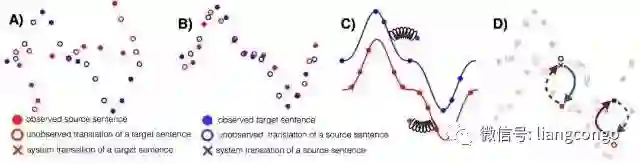
无监督 MT 的三个主要原则:A)两种单语数据集、B)参数初始化、C)语言建模、D)回译。
这篇论文获得了 EMNLP 2018 的最佳长论文奖,它在遵循上面三个主要原则的情况下简化了结构和损失函数,得到的模型优于以前的方法,并且更易于训练和调整。
谷歌 Duplex
2018 谷歌 I/O 开发者大会正式介绍了一种进行自然语言对话的新技术 Google Duplex。这种技术旨在完成预约等特定任务,并使系统尽可能自然流畅地实现对话,使用户能像与人对话那样便捷。Duplex 基于循环神经网络和 TensorFlow Extended(TFX)在匿名电话会话数据集上进行训练。这种循环网络使用谷歌自动语音识别(ASR)技术的输出作为输入,包括语音的特征、会话历史和其它会话参数。谷歌会为每一个任务独立地训练一个理解模型,但所有任务都能利用共享的语料库。此外,谷歌还会使用 TFX 中的超参数优化方法优化模型的性能。
如下所示,输入语音将输入到 ASR 系统并获得输出,在结合 ASR 的输出与语境信息后可作为循环神经网络的输入。这一深度 RNN 最终将基于输入信息输出对应的响应文本,最后响应文本可传入文本转语音(TTS)系统完成对话。RNN 的输出与 TTS 系统对于生成流畅自然的语音非常重要,这也是 Duplex 系统关注的核心问题。
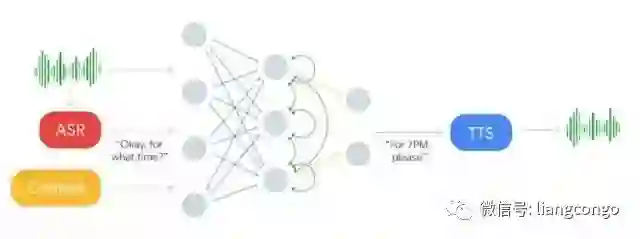
在 Duplex 系统的语音生成部分,谷歌结合了拼接式的 TTS 系统和合成式的 TTS 系统来控制语音语调,即结合了 Tacotron 和 WaveNet。
@顿数
版权声明
本文版权归《顿数》,转载请自行联系。


点击下方阅读原文了解课程详情
历史文章推荐:
从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史
SFFAI分享 | 曹杰:Rotating is Believing
SFFAI分享 | 黄怀波 :自省变分自编码器理论及其在图像生成上的应用
AI综述专栏 | 深度神经网络加速与压缩
SFFAI分享 | 田正坤 :Seq2Seq模型在语音识别中的应用
SFFAI 分享 | 王克欣 : 详解记忆增强神经网络
SFFAI报告 | 常建龙 :深度卷积网络中的卷积算子研究进展
点击下方阅读原文了解课程详情↓↓
若您觉得此篇推文不错,麻烦点点好看↓↓