机器之心年度盘点:2018年重大研究与开源项目
机器之心原创
作者:思源、刘晓坤
2018 年即将结束,要问今年深度学习领域有什么要关注的进展,恐怕首先想到的就是 Deepmind 的 BigGAN 和 Google 的 BERT。这两项进展有一些共同点:除了弱监督或无监督,那就是大,数据大,模型大,计算大,算法改动没那么大,主要靠计算。
但是除了它们,今年还是有很多非常美的想法,例如强行解积分的强大流模型 Glow、基于图结构的广义神经网络,以及拥有连续层级的神经常微分方程。它们为深度学习开拓了新方向,也为未来提供了更多选择。
在这篇文章中,机器之心从想法到实践介绍了 2018 年令人瞩目的研究工作,它们共同构建了机器学习的当下。我们主要按领域从模型到开源工具展开,其中算法或模型的选择标准主要是效果和潜力,而开源工具的选择主要凭借 GitHub 的收藏量与效果。本文的目录如下所示:
自然语言处理
预训练语言模型
机器翻译
谷歌 Duplex
生成模型
大大的 GAN
流模型
神经网络新玩法
图神经网络
神经常微分方程
计算机视觉
视觉迁移学习
强化学习与游戏
徳扑
星际争霸
Dota
量子计算
绝对界限
相对界限
开源工具
强化学习框架 Dopamine
图网络库(Graph Nets library)
图神经网络框架 DGL
Auto Keras
TransmogrifAI
目标检测框架 Detectron
NLP 建模框架 PyText
BERT 开源实现
大规模稀疏框架 XDL
面向前端的 TensorFlow.js
自然语言处理
在即将过去的 2018 年中,自然语言处理有很多令人激动的想法与工具。从概念观点到实战训练,它们为 NLP 注入了新鲜的活力。其中最突出的就是机器翻译与预训练语言模型,其中机器翻译已经由去年的 Seq2Seq 到今年大量使用 Transformer,而预训练语言模型更是从 ELMo 到 BERT 有了长足发展。
预训练语言模型
大概在前几年,很多人认为预训练的意义不是特别大,都感觉直接在特定任务上做训练可能效果会更好。但是随着计算机视觉领域中预训练模型的广泛使用,很多 NLP 的研究者也在思考是不是能有一种方法,它可以将通用的语言知识迁移到不同的 NLP 任务中。
很快大家就选定了语言模型,首先它是一种无监督方式,所以训练样本很容易获取。其次语言模型能预测一个词序列是人类话语的概率,因此某种意义上它包含了通用的语言知识。因此在 2018 年中,使用预训练语言模型可能是 NLP 领域最显著的趋势,它可以利用从无监督文本中学习到的「语言知识」,并迁移到各种 NLP 任务中。
这些预训练模型有很多,包括 ELMo、ULMFiT、OpenAI Transformer 和 BERT,其中又以 BERT 最具代表性,它在 11 项 NLP 任务中都获得当时最佳的性能。不过目前有 9 项任务都被微软的新模型超过。
ULMFiT
ULMFiT 由 Sebastian Ruder 和 fast.ai 的 Jeremy Howard 设计,是首个将迁移学习应用于 NLP 的框架。ULMFiT 表示 Universal Language Model Fine-Tuning(通用语言模型微调)。ULMFiT 真的实现了「通用」,该框架可用于几乎所有 NLP 任务。
论文:Universal Language Model Fine-tuning for Text Classification
论文地址:https://arxiv.org/pdf/1801.06146.pdf
ULMFiT 最好的地方在于我们不用再从头训练模型了。研究者把最难的部分做好了,直接将他们做好的模型用到自己的项目中即可。ULMFiT 在六个文本分类任务上优于之前最优的方法。
ULMFiT 主要可以分为三个阶段:
在通用领域实现语言模型的预训练
在目标任务实现语言模型的微调
在目标任务的分类器微调

如上所示,ULMFiT 主要由三阶段组成。(a)中的预训练语言模型能捕获自然语言的一般特征,而(b)中的语言模型会使用判别性的微调(Discr)和斜三角式的学习率来进行调整,它将在目标任务上学习到特定的特征。最后(c)表示分类器在目标任务上的微调,其中灰色表示不固定权重的阶段,而黑色表示固定权重的阶段,这样能保留低级表示而适应地调整高级表示。
感兴趣的读者可参考以下内容:
https://github.com/prateekjoshi565/ULMFiT_Text_Classification
http://nlp.fast.ai/category/classification.html
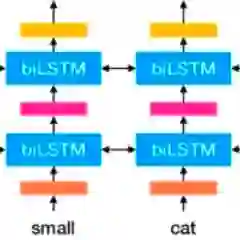
ELMo
ELMo 是 Embeddings from Language Models 的缩写。ELMo 一经发布即引起了机器学习社区的关注,它使用语言模型来获取每个单词的词嵌入,同时考虑单词在句子或段落中的语境。这种添加了语境信息的词表征可以表示复杂的语言知识,因此也就可以编码整个句子的信息。
论文:Deep contextualized word representations
论文链接:https://arxiv.org/pdf/1802.05365.pdf
具体而言,研究者使用从双向 LSTM 中得到的向量,该 LSTM 是使用正向和反向两个语言模型(LM)在大型文本语料库上训练得到的。用这种方式组合内部状态可以带来丰富的词表征。研究者使用内在评价进行评估,结果显示更高级别的 LSTM 状态捕捉词义的语境依赖方面(如它们不经修改就可以执行监督式词义消歧任务,且表现良好),而较低级别的状态建模句法结构(如它们可用于词性标注任务)。同时揭示所有这些信号是非常有益的,可以帮助学得的模型选择对每个任务最有帮助的半监督信号。
与 ULMFiT 类似,ELMo 极大提升了在大量 NLP 任务上的性能,如情感分析和问答任务。如下展示了 ELMo 在不同 NLP 任务中的效果,将 ELMo 加入到已有的自然语言系统将显著提升模型效果。
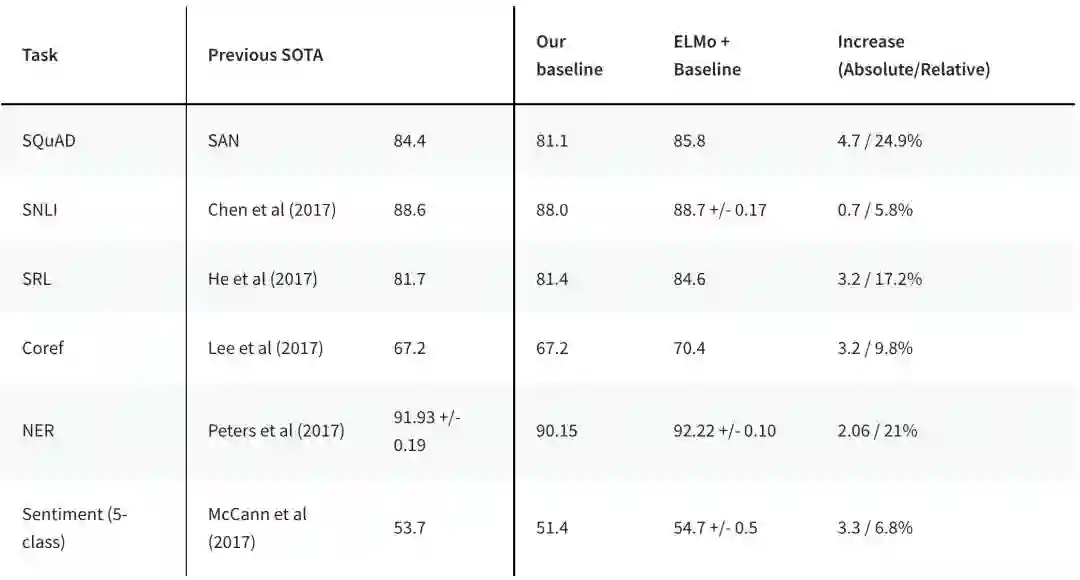
更多信息及预训练 ELMo 模型可查看:https://allennlp.org/elmo
NAACL 2018 | 最佳论文:艾伦人工智能研究所提出新型深度语境化词表征
BERT
BERT 是一种新型语言表征模型——来自 Transformer 的双向编码器表征。与最近的语言表征模型不同,BERT 旨在基于所有层的左、右语境来预训练深度双向表征。BERT 是首个在大批句子层面和 token 层面任务中取得当前最优性能的基于微调的表征模型,其性能超越许多使用任务特定架构的系统,刷新了 11 项 NLP 任务的当前最优性能记录。
机器之心曾解读过 BERT 的的核心过程,它会先从数据集抽取两个句子,其中第二句是第一句的下一句的概率是 50%,这样就能学习句子之间的关系。其次随机去除两个句子中的一些词,并要求模型预测这些词是什么,这样就能学习句子内部的关系。最后再将经过处理的句子传入大型 Transformer 模型,并通过两个损失函数同时学习上面两个目标就能完成训练。
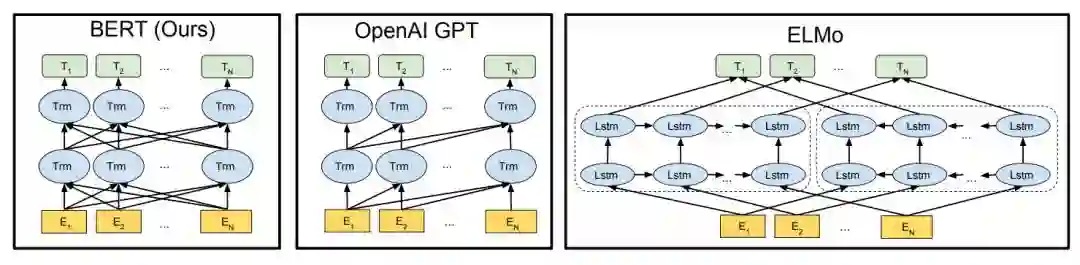
如上所示为不同预训练模型的架构,BERT 可以视为结合了 OpenAI GPT 和 ELMo 优势的新模型。其中 ELMo 使用两条独立训练的 LSTM 获取双向信息,而 OpenAI GPT 使用新型的 Transformer 和经典语言模型只能获取单向信息。BERT 的主要目标是在 OpenAI GPT 的基础上对预训练任务做一些改进,以同时利用 Transformer 深度模型与双向信息的优势。
这种「双向」的来源在于 BERT 与传统语言模型不同,它不是在给定所有前面词的条件下预测最可能的当前词,而是随机遮掩一些词,并利用所有没被遮掩的词进行预测。
更详细的论文解读可以查看:谷歌终于开源 BERT 代码:3 亿参数量,机器之心全面解读
此外,BERT 的开源项目非常有诚意,谷歌研究团队开放了好几种预训练模型,它们从英语到汉语支持多种不同的语言。很多开发者在这些 BERT 预训练语言模型上做二次开发,并在不同的任务上获得很多提升,BERT 开源项目将放在文章后面,并与其它开源库一起介绍。
机器翻译
在 2018 年里,神经机器翻译似乎有了很大的改变,以前用 RNN 加上注意力机制打造的 Seq2Seq 模型好像都替换为了 Tramsformer。大家都在使用更大型的 Transformer、更高效的 Transformer 组件。例如阿里根据最近的一些新研究对标准 Transformer 模型进行一些修正。这些修正首先体现在将 Transformer 中的 Multi-Head Attention 替换为多个自注意力分支,其次他们采用了一种编码相对位置的表征以扩展自注意力机制,并令模型能更好地理解序列元素间的相对距离。
有道翻译也采用了 Transformer,他们同样会采取一些修正,包括对单语数据的利用、模型结构的调整、训练方法的改进等。例如在单语数据的利用上,他们尝试了回译和对偶学习等策略,在模型结构上采用了相对位置表征等。所以总的而言,尽管 Transformer 在解码速度和位置编码等方面有一些缺点,但它仍然是当前效果最好的神经机器翻译基本架构。
Sebastian Ruder 非常关注无监督机器翻译模型,如果无监督机器翻译模型是能行得通的,那么这个想法本身就很惊人,尽管无监督翻译的效果很可能远比有监督差。在 EMNLP 2018 中,有一篇论文在无监督翻译上更进一步提出了很多改进,并获得极大的提升。Ruder 笔记中提到了以下这篇论文:
论文:Phrase-Based & Neural Unsupervised Machine Translation
论文链接:https://arxiv.org/abs/1804.07755
这篇论文很好地提炼出了无监督 MT 的三个关键点:优良的参数初始化、语言建模和通过回译建模反向任务。这三种方法在其它无监督场景中也有使用,例如建模反向任务会迫使模型达到循环一致性,这种一致性已经应用到了很多任务,读者最熟悉的可能是 CycleGAN。该论文还对两种语料较少的语言做了大量的实验与评估,即英语-乌尔都语和英语-罗马尼亚语。
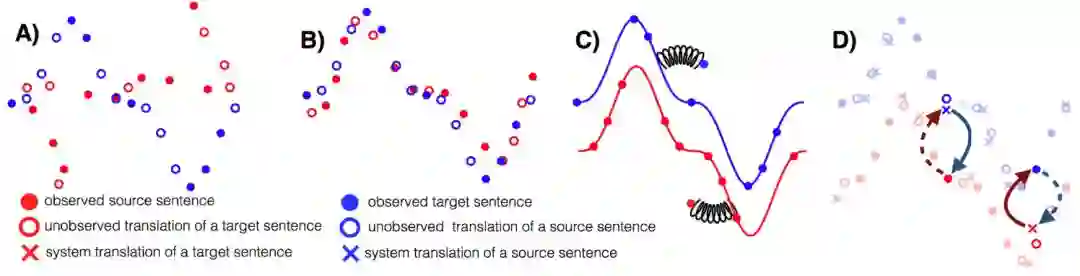
无监督 MT 的三个主要原则:A)两种单语数据集、B)参数初始化、C)语言建模、D)回译。
这篇论文获得了 EMNLP 2018 的最佳长论文奖,它在遵循上面三个主要原则的情况下简化了结构和损失函数,得到的模型优于以前的方法,并且更易于训练和调整。
谷歌 Duplex
2018 谷歌 I/O 开发者大会正式介绍了一种进行自然语言对话的新技术 Google Duplex。这种技术旨在完成预约等特定任务,并使系统尽可能自然流畅地实现对话,使用户能像与人对话那样便捷。Duplex 基于循环神经网络和 TensorFlow Extended(TFX)在匿名电话会话数据集上进行训练。这种循环网络使用谷歌自动语音识别(ASR)技术的输出作为输入,包括语音的特征、会话历史和其它会话参数。谷歌会为每一个任务独立地训练一个理解模型,但所有任务都能利用共享的语料库。此外,谷歌还会使用 TFX 中的超参数优化方法优化模型的性能。
如下所示,输入语音将输入到 ASR 系统并获得输出,在结合 ASR 的输出与语境信息后可作为循环神经网络的输入。这一深度 RNN 最终将基于输入信息输出对应的响应文本,最后响应文本可传入文本转语音(TTS)系统完成对话。RNN 的输出与 TTS 系统对于生成流畅自然的语音非常重要,这也是 Duplex 系统关注的核心问题。
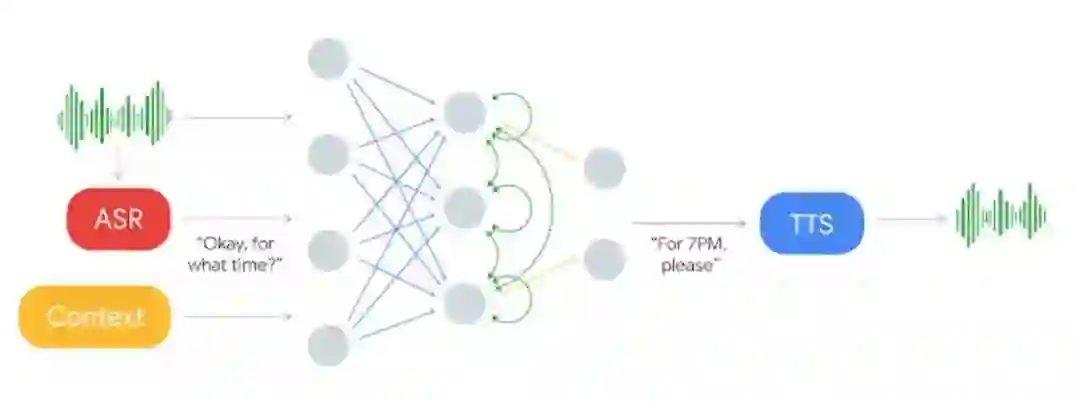
在 Duplex 系统的语音生成部分,谷歌结合了拼接式的 TTS 系统和合成式的 TTS 系统来控制语音语调,即结合了 Tacotron 和 WaveNet。
生成模型
生成对抗网络在 2018 年仍然是研究的重点,我们不仅看到可以生成高分辨率(1024×1024)图像的模型,还可以看到那些以假乱真的生成图像。此外,我们还很兴奋能看到一些新的生成模型,它们没有采用对抗式的训练方式,其主要代表就是流模型 Glow。
大大的 GAN
今年 9 月份,DeepMind 团队创造出「史上最强 GAN」,该研究被接收为 ICLR 2019 的 oral 论文。很多学者惊呼:不敢相信这样高质量的图像竟是 AI 生成出来的。
论文:LARGE SCALE GAN TRAINING FOR HIGH FIDELITY NATURAL IMAGE SYNTHESIS
论文地址:https://arxiv.org/pdf/1809.11096.pdf

BigGAN 生成图像的目标和背景都高度逼真、边界自然,并且图像插值每一帧都相当真实,简直能称得上「创造物种的 GAN」。当在 128x128 分辨率的 ImageNet 上训练时,BigGAN 可以达到 166.3 的 Inception 分数(IS),而之前的最佳 IS 仅为 52.52。
研究者还成功地在 256x256 分辨率和 512x512 分辨率的 ImageNet 上训练了 BigGAN,并得到非常逼真的图像。但这么好的效果,是靠巨大的计算力来推动。在原论文中,DeepMind 表示 BigGAN 会在谷歌 TPU v3 pod 上训练,且根据任务使用不同的核心数,128x128 的图像使用 128 个核心数(64 块芯片),512x512 的图像使用 512 个核心数(256 块芯片)。
此外,今年 12 月,英伟达提出了另一种高精度 GAN。这款新型 GAN 生成器架构借鉴了风格迁移研究,可对高级属性(如姿势、身份)进行自动学习和无监督分割,且生成图像还具备随机变化(如雀斑、头发)。
论文:A Style-Based Generator Architecture for Generative Adversarial Networks
论文链接:https://arxiv.org/pdf/1812.04948.pdf
英伟达提出的这种基于风格的生成器能构建非常高分辨率的人脸图像,即 1024×1024 分辨率的图像,详情可查看以下视频:
学界 | 史上最强 GAN 图像生成器,Inception 分数提高两倍
流模型
目前,生成对抗网络 GAN 被认为是在图像生成等任务上最为有效的方法,越来越多的学者正朝着这一方向努力:在计算机视觉顶会 CVPR 2018 上甚至有 8% 的论文标题中包含 GAN。今年来自 OpenAI 的研究科学家 Diederik Kingma 与 Prafulla Dhariwal 却另辟蹊径,他们提出了基于流的生成模型 Glow。据介绍,该模型不同于 GAN 与 VAE,在生成图像任务上也达到了令人惊艳的效果。
该研究一经发表,立刻引起了机器学习社区的注意,很多研究者表示:终于,我们有了 GAN 以外的优秀生成模型!
论文:Glow: Generative Flow with Invertible 1×1 Convolutions
论文地址:https://d4mucfpksywv.cloudfront.net/research-covers/glow/paper/glow.pdf
OpenAI 创造的 Glow 是一种使用可逆 1×1 卷积的可逆生成模型,它可以生成逼真的高分辨率图像,支持高效率采样,并能发现用于操作数据属性的特征。目前,OpenAI 已经发布了该模型的代码,并开放了在线可视化工具,供人们试用。

详细的内容可参考机器之心的介绍性文章与苏剑林发布在 PaperWeekly 的解读:
神经网络新玩法
今年有很多研究从理论分析方面或结合其它领域来扩展深度学习,其中最突出的就是 DeepMind 和谷歌大脑等研究机构提出的图网络(Graph Network),以及多伦多大学陈天琦等研究者提出的神经常微分方程。
前者提出的图网络是一种新的 AI 模块,即基于图结构的广义神经网络,图网络推广了以前各种对图进行操作的神经网络方法。借助微分方程,后者提出的 ODEnet 将神经网络离散的层级连续化了,因此反向传播也不再需要一点一点传、一层一层更新参数。
图网络
图+深度学习一直都有很多研究工作,但今年最引人瞩目的是图网络(Graph Network),它由 DeepMind、谷歌大脑、MIT 和爱丁堡大学等公司和机构的 27 位科学家共同提出。
论文:Relational inductive biases, deep learning, and graph networks
论文地址:https://arxiv.org/pdf/1806.01261.pdf
该论文提出的图网络(GN)框架定义了一类对图结构表征进行关系推理的函数。该 GN 框架泛化并扩展了多种图神经网络、MPNN 和 NLNN 方法,并支持从简单的构建模块建立复杂的架构。注意,这里避免了在「图网络」中使用「神经」术语,以反映它可以用函数而不是神经网络来实现,虽然在这里关注的是神经网络实现。
目前图网络在监督学习、半监督学习和无监督学习等领域都有探索,因为它不仅能利用图来表示丰富的结构关系,同时还能利用神经网络强大的拟合能力。
一般图网络将图作为输入,并返回一张图以作为输入。其中输入的图有 edge- (E )、node- (V ) 和 global-level (u) 属性,输入也有相同的结构,只不过会使用更新后的属性。如下展示了输入图、对图实现的计算及输出图,更详细的内容请参考原论文。

DeepMind 开源图网络库,一种结合图和神经网络的新方法
神经常微分方程
在今年 NeruIPS 2018 中,来自多伦多大学的陈天琦等研究者成为最佳论文的获得者。他们提出了一种名为神经常微分方程的模型,这是一种新型深度神经网络。神经常微分方程不拘于对已有架构的修修补补,它完全从另外一个角度考虑如何以连续的方式借助神经网络对数据建模。
神经常微分方程走了另一条道路,它使用神经网络参数化隐藏状态的导数,而不是如往常那样直接参数化隐藏状态。这里参数化隐藏状态的导数就类似构建了连续性的层级与参数,而不再是离散的层级。因此参数也是一个连续的空间,我们不需要再分层传播梯度与更新参数。
具体而言若我们在层级间加入更多的层,且最终趋向于添加了无穷层时,神经网络就连续化了。我们可以将这种连续变换形式化地表示为一个常微分方程:
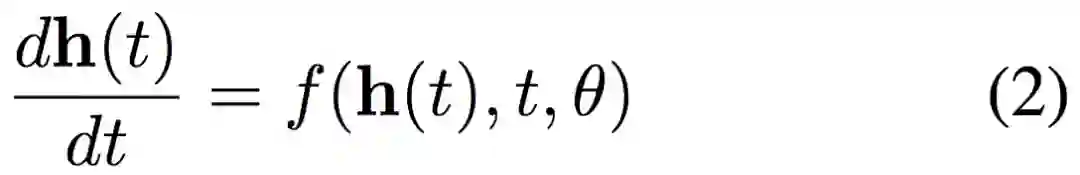
如果从导数定义的角度来看,当 t 的变化趋向于无穷小时,隐藏状态的变化 dh(t) 可以通过神经网络建模。当 t 从初始一点点变化到终止,那么 h(t) 的改变最终就代表着前向传播结果。这样利用神经网络参数化隐藏层的导数,就确确实实连续化了神经网络层级。
现在若能得出该常微分方程的数值解,那么就相当于完成了前向传播。也就是说若 h(0)=X 为输入图像,那么终止时刻的隐藏层输出 h(T) 就为推断结果。这是一个常微分方程的初值问题,可以直接通过黑箱的常微分方程求解器(ODE Solver)解出来。而这样的求解器又能控制数值误差,因此我们总能在计算力和模型准确度之间做权衡。
如下所示,残差网络只不过是用一个离散的残差连接代替 ODE Solver。
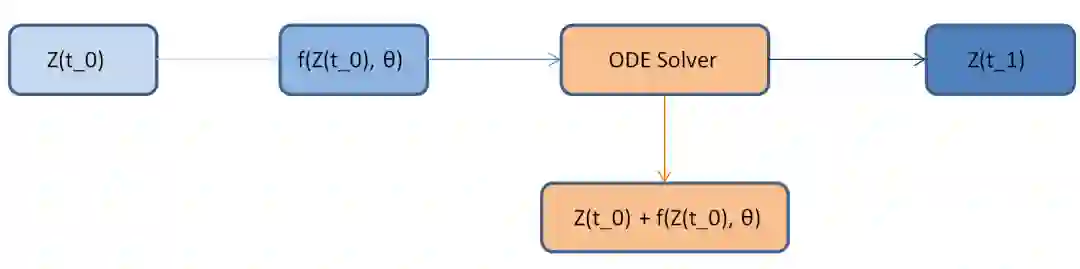
更详细的论文解读可查看:硬核 NeruIPS 2018 最佳论文,一个神经了的常微分方程
计算机视觉
视觉迁移学习
人类的视觉具备多种多样的能力,计算机视觉界基于此定义了许多不同的视觉任务。长远来看,计算机视觉着眼于解决大多数甚至所有视觉任务,但现有方法大多尝试将视觉任务逐一击破。这种方法造成了两个问题:数据量大和冗余计算。
如果能有效测量并利用视觉任务之间的关联来避免重复学习,就可以用更少的数据学习一组任务。Taskonomy 是一项量化不同视觉任务之间关联、并利用这些关联来最优化学习策略的研究,相关论文获得了 CVPR 2018 的最佳论文奖。
如果两个视觉任务 A、B 具有关联性,那么在任务 A 中习得的表征理应可为解决任务 B 提供有效的统计信息。通过迁移学习,Taskonomy 计算了 26 个不同视觉任务之间的一阶以及高阶关联。例如对于 10 个视觉问题,利用 Taskonomy 提供的学习策略最大可以减少 2/3 的训练数据量。
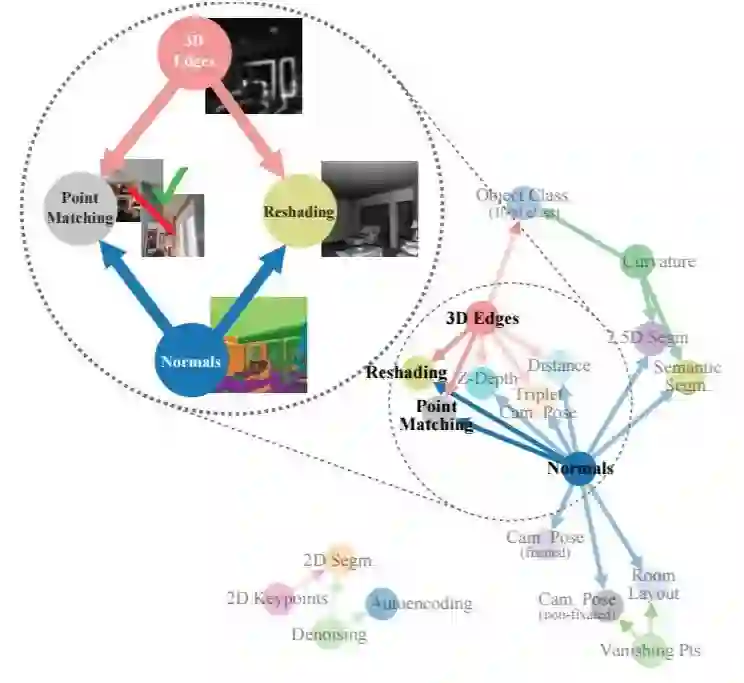
由 Taskonomy 发现的一个示例任务结构。例如,从图中可以发现通过将曲面法线估计器和遮挡边缘检测器学习到的特征结合起来,用少量标注数据就能快速训练用于重描影和点匹配的优质网络。
抱歉我们今天想介绍的这篇论文,刚刚中了 CVPR 2018 最佳论文
CVPR 2018 最佳论文作者亲笔解读:研究视觉任务关联性的 Taskonomy
强化学习与游戏
博弈论存在两种类型:完美信息博弈和不完美信息博弈。
不完美信息博弈是指,博弈中的一个参与者不能知道其它参与者的所有行动信息,比如德扑。如果将环境也考虑在内,参与者可能对环境的所知信息也是不完美的,比如 MOBA(多人在线战术竞技游戏,包括星际争霸、Dota 等)。
围棋、国际象棋都属于完美信息博弈,它们显然不是今年的焦点。而德扑、星际争霸和 Dota 都在今年取得了引人注目的成果。
德扑
2017 年 11 月,来自 CMU 博士生 Noam Brown 和教授 Tuomas Sandholm 的一篇论文确证获得了 NeurIPS 2017 的最佳论文奖。
而在去年年初,在宾夕法尼亚州匹兹堡的 Rivers 赌场,CMU 开发的 Libratus 人工智能系统击败人类顶级职业玩家。此次比赛共持续 20 天,由 4 名人类职业玩家 Jason Les、Dong Kim、Daniel McAulay 和 Jimmy Chou 对战人工智能程序 Libratus。在整个赛程中,他们总共对玩 12 万手,争夺 20 万美元的奖金。最终的结果是「比赛过程中,人类选手整体上从未领先过。」
Sandholm 教授的获奖论文,正是 Libratus 的技术解读。他们针对德扑的不完美信息博弈的特点,提出了一种无论在理论上还是在实践上都超越了之前方法的子博弈求解技术。Libratus 也是第一个能在一对一无限注德州扑克单挑中打败顶尖人类选手的 AI。
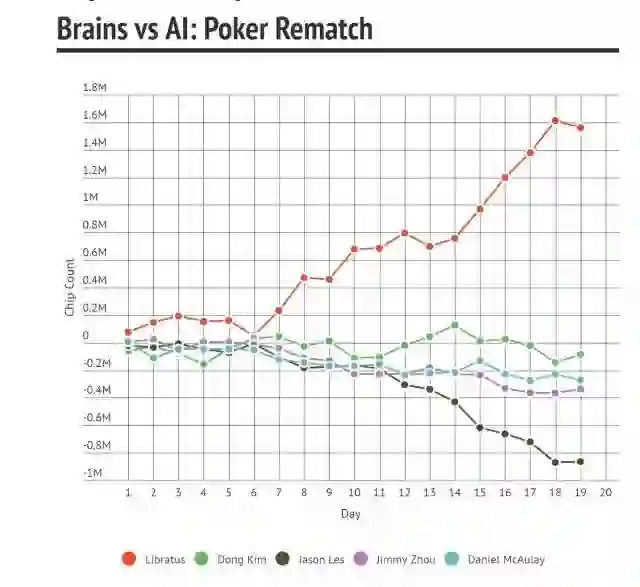
Libratus 在 2017 年 Brain vs. AI 大赛中的表现。
Libratus 并没有使用深度学习方法,最主要的算法是 CFR,这是一种类似强化学习 self-play 的算法,但其还考虑了未被选择的假设动作的收益。
由于序贯博弈在更深层阶段计算成本高昂,Libratus 在前半场需要数百万核心时间和数 TB 内存规模的资源。为此,他们在今年 5 月份又提出了一种在博弈的早期阶段就对深度有限(depth-limited)的子博弈进行求解的新方法,实现了新的德扑 AI——Modicum,其只需要一台笔记本电脑的算力就可以打败业内顶尖的 Baby Tartanian8(2016 计算机扑克冠军)和 Slumbot(2018 年计算机扑克冠军)。
关于 Libratus 和 AlphaGo 的对比,Noam Brown 曾经表示两者解决的是不同的问题,不能直接对比:围棋属于完美信息博弈,德扑属于不完美信息博弈。而在不完美信息博弈领域中,Noam Brown 曾表示下一个突破很可能是在星际争霸和 Dota(机智)。
NIPS 2017 最佳论文出炉:CMU「冷扑大师」不完美信息博弈研究获奖
一台笔记本打败超算:CMU 冷扑大师团队提出全新德扑 AI Modicum
星际争霸
由于观察空间和动作空间巨大、局部观察(不完美信息博弈)、多智能体同时游戏、长期决策等因素,《星际争霸 II》被认为是最难用 AI 攻克的游戏。在这种设置下,研究人员还是不得不求助于深度学习和强化学习的结合。
今年,AI 界在《星际争霸 II》可谓收获颇丰。至少在特定设置下,我们已经攻克了全场游戏。实现这一目标的包括腾讯 AI Lab、南京大学和伯克利。
今年 9 月,腾讯 AI Lab、罗切斯特大学和西北大学联合提出了 TStarBots,在「深海暗礁地图,虫族 1 对 1」设置下在《星际争霸 II》全场游戏中打败了难度为 1-10 级的内置 bot,其中 8、9、10 级的内置 bot 允许作弊行为。这是首个能够在《星际争霸 II》全场游戏中击败内置 bot 的智能体。

TStarBot1 和 TStarBot2 智能体在不同难度等级下和内置 AI 比赛的胜率(100%)。
同样在 9 月,南京大学也在《星际争霸 II》上取得了突破。研究者让智能体通过观察人类专业选手游戏录像来学习宏动作,然后通过强化学习训练进一步的运营、战斗策略。他们还利用课程学习让智能体在难度渐进的条件下逐步习得越来越复杂的性能。在 L-7 难度的神族对人族游戏中,智能体取得了 93% 的胜率。这种架构也具有通用性更高的特点。
今年 11 月,伯克利在《星际争霸 II》中提出了一种新型模块化 AI 架构,该架构可以将决策任务分到多个独立的模块中。在虫族对虫族比赛中对抗 Harder(level 5)难度的暴雪 bot,该架构达到了 94%(有战争迷雾)的胜率。和 TStarBots 类似,他们也提出了分层、模块化架构,并手工设计了宏指令动作。伯克利的研究者解释道,二者不同之处在于,他们的智能体是在模块化架构下仅通过自我对抗及与几个脚本智能体对抗来训练的,直到评估阶段才见到内建 bot。
三项研究各有千秋,对架构设计的考量围绕着通用-专用权衡的主题,并且都抓住了宏指令(宏动作)定义的关键点,展示了分层强化学习的有效性。完全依靠深度学习和强化学习仍然不够,结合人类定义的规则可以更有效地约束智能体的行为。至于可迁移性方面,或许南京大学提出的方法更具一般性。
首次!腾讯的人工智能在星际争霸 2 中打败了「开挂」内建 AI
Dota
2017 年 8 月,OpenAI 在 Dota2 TI 决赛现场以 1 对 1 solo 的方式击败了「Dota 2」世界顶级玩家。
今年,OpenAI 准备征服 5 v 5 团队赛,可谓吊足了大众的胃口。在正式征战 TI 8 之前,OpenAI 陆续预演了好几场热身赛,并接连带来惊喜。今年 6 月,OpenAI 宣布他们的 AI bot 在 5 v 5 团队赛中击败业余人类玩家,达到 4000 分水平。在 8 月初首次公开的基准测试赛中,OpenAI Five 以 2:1 的战绩击败了准职业玩家。
通过用机器学习取代硬编码,并结合训练环境随机化扩大探索空间,得到鲁棒的强化学习策略网络,OpenAI 去年借此攻克了 Dota 中的一个小游戏 Kiting,并成功迁移到了 1 v 1 模式中。而要进一步扩展到 5 v 5 团队战,最关键的一步就是扩大算力规模。OpenAI 最终使用了 128,000 CPU 核和 256 个 GPU 来支持算力,让 AI 每天自我博弈成千上万盘游戏,每天累计游戏时间达到 180 年。
人们原先认为,进行长时间和巨大探索空间的学习需要借助层级强化学习。然而,OpenAI 的结果表明,至少以足够的规模和合理的探索方式运行的时候,一般的强化学习方法也能收获奇效。
关于观察空间,OpenAI 将 Dota2 世界表征为一个由 2 万个数值组成的列表;关于动作空间,OpenAI 设置了一个包含 8 个枚举值的列表,bot 根据这个列表的输出采取行动。
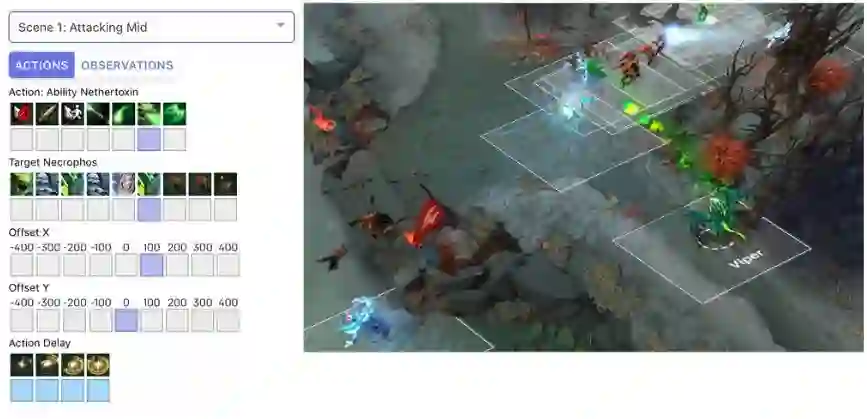
OpenAI Five 的每一个 bot 都配置了一个 LSTM 来生成事件记忆,通过近端策略优化来进行自我对抗,并合理分配对手来避免策略模式匮乏。通过给未来奖励设置合理的指数衰减,OpenAI Five 可以控制 bot 关注长期或者短期的奖励。OpenAI Five 还设置了一个很巧妙的「团队精神」参数,在训练过程中逐渐从 0 增加到 1,可以让 bot 从关注个人奖励过渡到团队奖励,也就是从学习个人基本技能到学习团队作战策略。在某种程度上,这也可以说是一种隐含的层级强化学习。
OpenAI Five 从随机参数开始,这些 bot 却能从盲目游走演变出 Dota 老司机非常熟悉的经典技能,令人惊叹。
在收获赞誉的同时,对 OpenAI Five 的质疑也铺天盖地而来。
尽管是从随机参数开始训练,但 OpenAI Five 在严格意义上并不能说是「从零开始」训练,并且其游戏条件和人类玩家也有很大的不同。OpenAI Five 的 bot 的观察输入并不是游戏界面的直接呈现,而是通过 API 读取的结构化数据(也就是那 2 万个数值组成的列表),各种距离度量都可以轻易完成,这和人类玩家的度量方式显然大不相同,并具有精度和速度上的优势。当然,目前的视觉强化学习仍然处于初步阶段。而出现这些质疑也是合理的,毕竟攻克一个游戏相对于迁移到现实世界而言,仍然只是个小问题。
关于英雄池的限制问题这里就不讨论了,感兴趣的读者可以参考机器之心的报道。
在 8 月末的 TI 8 正式比赛中,OpenAI Five 却遭遇两场连败,尴尬收场。
至于下一步,OpenAI 是否会考虑《星际争霸 II》AI 广泛采用的层级强化学习呢?此外,以和玩家相同的游戏界面作为观察输入进行视觉强化学习,这样的结果是不是更能让人信服呢?我们,再等等吧。
OpenAI 人工智能 1v1 击败 Dota2 最强玩家:明年开启 5v5 模式
Dota 2 被攻陷!OpenAI 人工智能 5V5 模式击败人类玩家(4000 分水平)
毫无还手之力!OpenAI 人工智能 5v5 击败超凡 5 玩家(6600 水平)
面对最菜 TI 战队,OpenAI 在 Dota2 上输的毫无还手之力
深度 | 嵌入技术在 Dota2 人工智能战队 OpenAI Five 中的应用
量子计算
量子计算在理论上超越了经典计算,却给经典机器学习算法带来了灵感。
绝对界限
计算机科学家 Ran Raz 和 Avishay Tal 证明只有量子计算机可以解决 forrelation 问题,而传统计算机却永远无法解决。从计算复杂度的角度来讲就是,他们找到了一个属于 BQP、而不属于 PH 的问题。其中,PH 涵盖了任何可能的传统计算机所能解决的问题,BQP 涵盖了量子计算机可以解决的所有问题。
科学家早就证明 BQP 包含 P,但一直未能证明是否真包含 P。而 P∈NP∈PH,现在 Ran Raz 和 Avishay Tal 的结果也顺带证明了 BQP 真包含 P。
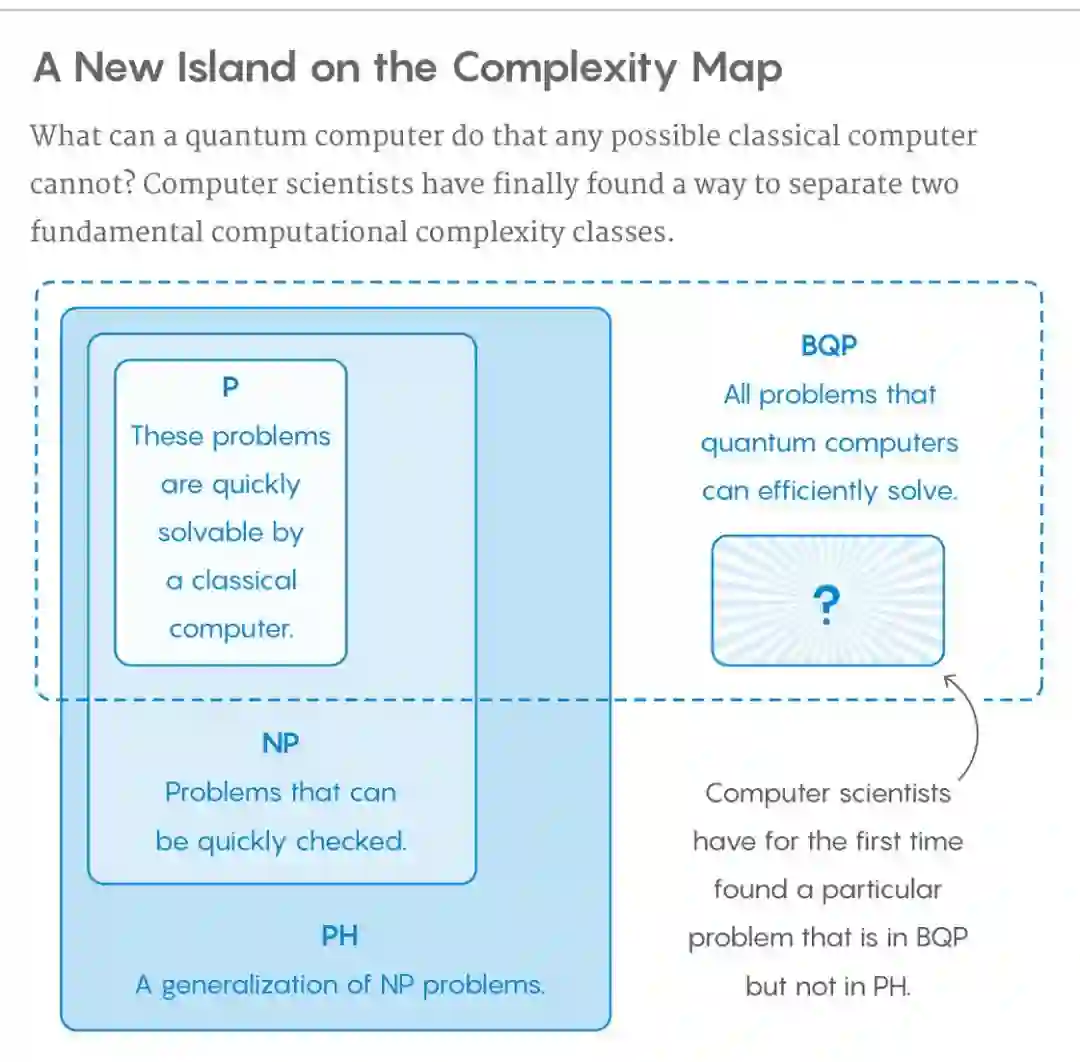
这个结果的意义还在于,即使将来人们证明 P=NP,传统计算机和量子计算机之间仍然存在根本的区别。
相对界限
来自 UT Austin 的 Ewin Tang 提出了一种非常高效的「Quantum inspired」经典推荐系统算法,相比于之前的最快经典算法有指数级提高,并和量子推荐系统算法的速度相当。Tang 的结果让人们看到了另一条路径,即使传统计算和量子计算存在绝对的界限,但对于具体的问题,还是可能找到类似计算复杂度的解法。毕竟这种界限的证明只是存在性的。在距离量子计算机实用还很遥远的当下,或许「量子快速算法的经典化」是更值得探索的一个方向。就在近期,Tang 再次证明了低秩矩阵的量子矩阵求逆算法也存在有效的经典变体。

开源工具与库
在过去的 2018 年中,不仅理论上有很多突破,实践上也有非常多的开源工作。这些开源工作不仅包括已有项目的更新,同时还包括针对新想法的新项目。前者主要体现在 PyTorch 1.0、Julia 1.0 和 PaddlePaddle 1.0 等的发布,后者主要体现在 TensorFlow.js、Detectron、PyText 和 Auto Keras 等新项目的开源。
在这一部分中,我们主要关注今年发布的新项目,其它优秀项目的重大更新并不会包含在内。
强化学习框架 Dopamine
在过去几年里,强化学习研究取得了多方面的显著进展。然而,大多数现有强化学习框架并不同时具备可让研究者高效迭代 RL 方法的灵活性和稳定性,因此探索新的研究方向可能短期内无法获得明显的收益。因此谷歌介绍了一款基于 TensorFlow 的新框架,旨在为强化学习研究者及相关人员提供具备灵活性、稳定性及复现性的工具。
项目地址:https://github.com/google/dopamine
该框架的灵感来自于大脑中奖励–激励行为的主要组成部分「多巴胺」(Dopamine),这反映了神经科学和强化学习研究之间的密切联系,该框架旨在支持能够推动重大发现的推测性研究。
业界 |「多巴胺」来袭!谷歌推出新型强化学习框架 Dopamine
除了谷歌发布的这种具有易用性和可复用性的 RL 框架,在强化学习领域中,OpenAI 还发布了 Spinning Up。它是一份完整的教学资源,旨在让所有人熟练掌握深度强化学习方面的技能。Spinning Up 包含清晰的 RL 代码示例、习题、文档和教程。

项目地址:https://spinningup.openai.com/en/latest/
从 Zero 到 Hero,OpenAI 重磅发布深度强化学习资源
图网络库(Graph Nets library)
DeepMind 开源的这个项目主要是依据他们在 6 月份发表的论文《Relational inductive biases, deep learning, and graph networks》,他们在该论文中将深度学习与贝叶斯网络进行了融合,并提出了一种具有推理能力的概率图模型。
项目地址:https://github.com/deepmind/graph_nets
图网络库可以用 TensorFlow 和 Sonnet 快速构建图网络,它还包含一些 demo,展示了如何创建、操作及训练图网络以在最短路径搜索任务、排序任务和物理预测任务中进行图结构数据推理。每个 demo 使用相同的图网络结构,该结构可以凸显该方法的复杂性。
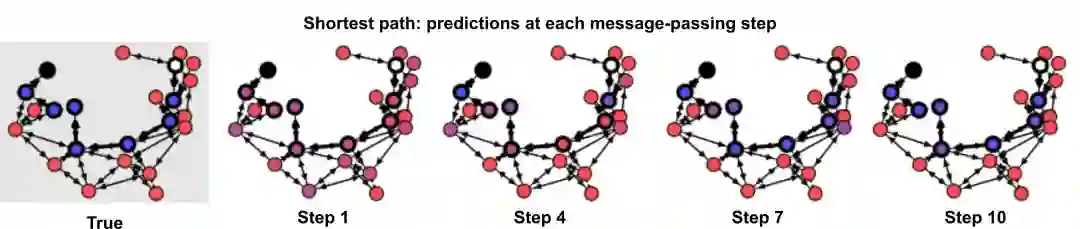
资源 | DeepMind 开源图网络库,一种结合图和神经网络的新方法
图神经网络框架 DGL
目前摆在深度学习面前有一个很现实的问题,即如何设计「既快又好」的深度神经网络?也许更加动态和稀疏的模型会是答案所在。可见,不论是数据还是模型,「图」应该成为一个核心概念。
基于这些思考,NYU、AWS 开发了 Deep Graph Library(DGL),一款面向图神经网络以及图机器学习的全新框架。
项目地址:https://github.com/jermainewang/dgl
目前 DGL 提供了 10 个示例模型,涵盖了单静态图、多图和巨图三种类别。其中除了 TreeLSTM,其余都是 2017 年以后新鲜出炉的图神经网络,其中包括几个逻辑上相当复杂的生成模型(DGMG、JTNN)。他们还尝试用图计算的方式重写传统模型比如 Capsule 和 Universal Transformer,让模型简单易懂,帮助进一步扩展思路。
NYU、AWS 联合推出:全新图神经网络框架 DGL 正式发布
Auto Keras
AutoKeras 是一个由易用深度学习库 Keras 编写的开源 Python 包。AutoKeras 使用 ENAS——神经网络自动架构搜索的高效新版本。AutoKeras 包可通过 pip install autokeras 快速安装,然后你就可以免费在准备好在的数据集上做你自己专属的架构搜索。
项目地址:https://github.com/jhfjhfj1/autokeras
因为所有的代码都是开源的,所以如果你想实现真正的自定义,你甚至可以利用其中的参数。所有代码都来自 Keras,所以代码深入浅出,能帮助开发人员快速准确地创建模型,并允许研究人员深入研究架构搜索。
终结谷歌每小时 20 美元的 AutoML!开源的 AutoKeras 了解下
TransmogrifAI
软件行业巨头 Salesforce 开源了其 AutoML 库 TransmogrifAI。TransmogrifAI 是一个基于 Scala 语言和 SparkML 框架构建的库,只需短短的几行代码,数据科学家就可以完成自动化数据清理、特征工程和模型选择工作,得到一个性能良好的模型,然后进行进一步的探索和迭代。
项目地址:https://github.com/salesforce/TransmogrifAI
TansmogrifAI 为我们带来了巨大的改变,它使数据科学家在生产中使用最少的手动调参就能部署数千个模型,将训练一个性能优秀模型的平均时间从数周减少到几个小时。
Salesforce 开源 TransmogrifAI:用于结构化数据的端到端 AutoML 库
最后,AutoML 类的工作在 18 年还有很多,不过要分清楚这些概念,可以读一读下面的文章:
观点 | AutoML、AutoKeras...... 这四个「Auto」的自动机器学习方法你分得清吗?
目标检测框架 Detectron
今年 Facebook 开源的目标检测框架 Detectron 目前已有超过 1.8W 的收藏量,它构建于 Caffe2 之上,目前支持大量顶尖目标检测算法。其中包括 Mask R-CNN(ICCV 2017 最佳论文)和 Focal Loss for Dense Object Detection(ICCV 2017 最佳学生论文)。
项目地址:https://github.com/facebookresearch/Detectron
目前 Detectron 已经包括检测、分割和关键点检测等众多任务的顶尖算法,且一旦训练完成,这些计算机视觉模型可被部署在云端或移动设备上。下图展示了 Model Zoo 中 Mask-R-CNN 关键点检测的基线结果,它还有很多任务与模型。
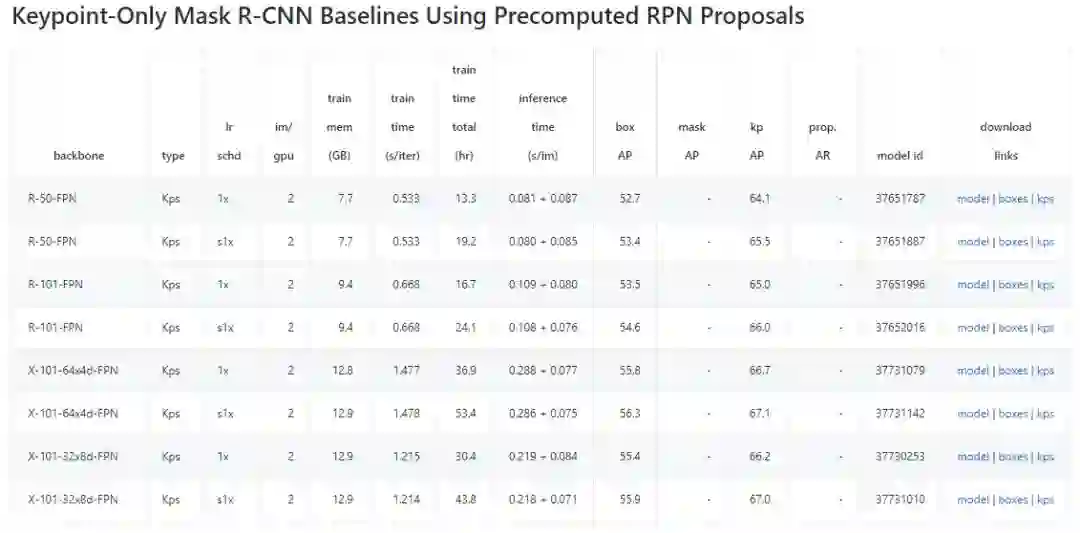
机器之心曾介绍过 Detectron,读者可以阅读以下文章了解详情:
资源 | 整合全部顶尖目标检测算法:FAIR 开源 Detectron
专栏 | 从论文到测试:Facebook Detectron 开源项目初探
专栏 | Detectron 精读系列之一:学习率的调节和踩坑
与此同时,商汤和港中文今年 10 月份联合开源了 mmdetection,它是一个基于 PyTorch 的开源目标检测工具包。该工具包支持 Mask RCNN 等多种流行的检测框架,读者可在 PyTorch 环境下测试不同的预训练模型及训练新的检测分割模型。
资源 | 一个基于 PyTorch 的目标检测工具箱,商汤联合港中文开源 mmdetection
NLP 建模框架 PyText
为了降低人们创建、部署自然语言处理系统的难度,Facebook 开源了一个建模框架——PyText,它模糊了实验与大规模部署之间的界限。PyTex 是 Facebook 正在使用的主要自然语言处理(NLP)建模框架,每天为 Facebook 及其应用程序系列的用户提供超过 10 亿次 AI 任务处理。这一框架基于 PyTorch,可以 1)简化工作流程,加快实验进度;2)提供一大批预构建的模型架构和用于文本处理和词汇管理的工具,以促进大规模部署;3)提供利用 PyTorch 生态系统的能力,包括由 NLP 社区中的研究人员、工程师预构建的模型和工具。利用该框架,Facebook 在几天内就实现了 NLP 模型从理念到完整实施的整个过程,还部署了依赖多任务学习的复杂模型。
Yann LeCun 对此介绍道,「PyText 是一个工业级的开源 NLP 工具包,可用于在 PyTorch 中开发 NLP 模型,并通过 ONNX 部署。其预训练模型包括文本分类、序列标注等。」
项目地址:https://github.com/facebookresearch/pytext
参考文章:Facebook 开源 NLP 建模框架 PyText,从论文到产品部署只需数天
做自然语言处理,词嵌入基本是绕不开的步骤,各种任务都需要归结到词层面才能继续计算。因此对于国内自然语言处理的研究者而言,中文词向量语料库是需求很大的资源。为此,北京师范大学等机构的研究者开源了「中文词向量语料库」,该库包含经过数十种用各领域语料(百度百科、维基百科、人民日报 1947-2017、知乎、微博、文学、金融、古汉语等)训练的词向量,涵盖各领域,且包含多种训练设置。
中文词向量项目地址:https://github.com/Embedding/Chinese-Word-Vectors
该项目提供使用不同表征(稀疏和密集)、上下文特征(单词、n-gram、字符等)以及语料库训练的中文词向量(嵌入)。我们可以轻松获得具有不同属性的预训练向量,并将它们用于各类下游任务。
BERT 开源实现
尽管如前所述 BERT 的效果惊人,但预训练所需要的计算力同样惊人,一般的开发者基本就不要想着能复现了。BERT 的作者在 Reddit 上也表示预训练的计算量非常大,Jacob 说:「OpenAI 的 Transformer 有 12 层、768 个隐藏单元,他们使用 8 块 P100 在 8 亿词量的数据集上训练 40 个 Epoch 需要一个月,而 BERT-Large 模型有 24 层、2014 个隐藏单元,它们在有 33 亿词量的数据集上需要训练 40 个 Epoch,因此在 8 块 P100 上可能需要 1 年?16 Cloud TPU 已经是非常大的计算力了。」
但是,谷歌团队开源了 BERT 的预训练模型,我们可以将它们用于不同的 NLP 任务。这节省了我们大量计算力,同时还能提升已有模型的效果,因此做 NLP 任务前,你可以先用预训练的 BERT 试试水?
BERT 实现地址:https://github.com/google-research/bert

其实目前已经有很多开发者将 BERT 预训练模型应用到它们自己的项目中,包括抽取句向量、句子相似性判断或情感分析等,下面两篇文章简单介绍了如何将 BERT 预训练模型迁移到你的项目中:
大规模稀疏框架 XDL
今年 12 月,阿里巴巴开源了其应用于自身广告业务的算法框架 X-Deep Learning(XDL)。该框架非常擅长处理高维稀疏数据,对构建推荐、搜索和广告系统非常有优势。此外,阿里还配套发布了一系列官方模型,它们都是阿里在实际业务或产品中采用的高效模型。
项目地址:https://github.com/alibaba/x-deeplearning
XDL 团队表示它主要在三个层面上对通用框架有比较大的提升:
首先是对大规模稀疏性数据的建设;
其次是结构化的计算流;
最后在结构化的计算流基础上,模型的分布也需要结构化。
机器之心采访了 XDL 团队,并对该框架有一个详细的介绍,感兴趣的读者可查阅:
阿里开源首个 DL 框架,新型 XDL 帮你搞定大规模稀疏数据
面向前端的 TensorFlow.js
在 TenosrFlow 开发者峰会 2018 中,TensorFlow 团队表示基于网页的 JavaScript 库 TensorFlow.js 现在已经能训练并部署机器学习模型。我们可以使用神经网络的层级 API 构建模型,并在浏览器中使用 WebGL 创建复杂的数据可视化应用。此外 Node.js 很快就会发布,它能为网站模型提供 GPU、TPU 等快速训练与推断的方法。
项目地址:https://js.tensorflow.org/
在 TensorFlow.js 中,我们可以使用最底层的 JavaScript 线性代数库或最高级的 API 在浏览器上开发模型,也能基于浏览器运行已训练的模型。因此,它可以充分利用浏览器和计算机的计算资源实现非常多的机器学习应用。例如在网页端训练一个模型来识别图片或语音、训练一个模型以新颖的方式玩游戏或构建一个能创造钢琴音乐的神经网络等。
TensorFlow 发布面向 JavaScript 开发者的机器学习框架 TensorFlow.js
最后,2018 年开源的开源工作实在是太多了,还有很多优秀的开源工作,例如小米开源的移动端框架 MACE 和英特尔开源的 nGraph 编译器。这里只是从不同的角度介绍少量的开源工作,读者也可以在留言中写出 2018 年你认为最重要的开源工作。