2018年AI和ML(NLP、计算机视觉、强化学习)技术总结和2019年趋势

来源:网络大数据
1、简介
过去几年一直是人工智能爱好者和机器学习专业人士最幸福的时光。因为这些技术已经发展成为主流,并且正在影响着数百万人的生活。各国现在都有专门的人工智能规划和预算,以确保在这场比赛中保持优势。
数据科学从业人员也是如此,这个领域正在发生很多事情,你必须要跑的足够的快才能跟上时代步伐。回顾历史,展望未来一直是我们寻找方向的最佳方法。
这也是我为什么想从数据科学从业者的角度退一步看一下人工智能的一些关键领域的发展,它们突破了什么?2018年发生了什么?2019年会发生什么?

我将在本文中介绍自然语言处理(NLP)、计算机视觉、工具库、强化学习、走向合乎正道的人工智能。
2、自然语言处理(NLP)

让机器分析单词和句子似乎是一个梦想,就算我们人类有时候也很难掌握语言的细微差别,但2018年确实是NLP的分水岭。
我们看到了一个又一个显著的突破:ULMFiT、ELMO、OpenAI的Transformer和Google的BERT等等。迁移学习(能够将预训练模型应用于数据的艺术)成功应用于NLP任务,为无限可能的应用打开了大门。让我们更详细地看一下这些关键技术的发展。
ULMFiT
ULMFiT由Sebastian Ruder和fast.ai的Jeremy Howard设计,它是第一个在今年启动的NLP迁移学习框架。对于没有经验的人来说,它代表通用语言的微调模型。Jeremy和Sebastian让ULMFiT真正配得上Universal这个词,该框架几乎可以应用于任何NLP任务!
想知道对于ULMFiT的最佳部分以及即将看到的后续框架吗?事实上你不需要从头开始训练模型!研究人员在这方面做了很多努力,以至于你可以学习并将其应用到自己的项目中。ULMFiT可以应用六个文本分类任务中,而且结果要比现在最先进的方法要好。
你可以阅读Prateek Joshi关于如何开始使用ULMFiT以解决任何文本分类问题的优秀教程。
ELMO
猜一下ELMo代表着什么吗?它是语言模型嵌入的简称,是不是很有创意? ELMo一发布就引起了ML社区的关注。
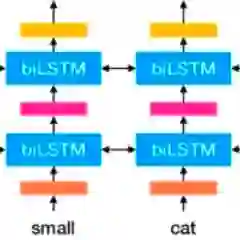
ELMo使用语言模型来获取每个单词的嵌入,同时还考虑其中单词是否适合句子或段落的上下文。上下文是NLP的一个重要领域,大多数人以前对上下文都没有很好的处理方法。ELMo使用双向LSTM来创建嵌入,如果你听不懂-请参考这篇文章,它可以让你很要的了解LSTM是什么以及它们是如何工作的。
与ULMFiT一样,ELMo显着提高了各种NLP任务的性能,如情绪分析和问答,在这里了解更多相关信息。
BERT
不少专家声称BERT的发布标志着NLP的新时代。继ULMFiT和ELMo之后,BERT凭借其性能真正击败了竞争对手。正如原论文所述,“BERT在概念上更简单且更强大”。BERT在11个NLP任务中获得了最先进的结果,在SQuAD基准测试中查看他们的结果:
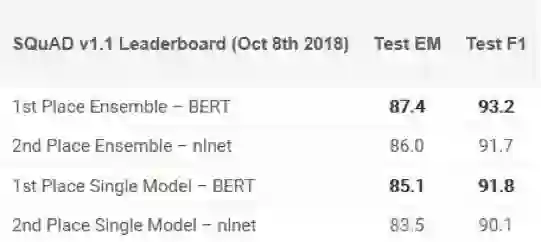
有兴趣入门吗?你可以使用PyTorch实现或Google的TensorFlow代码尝试在自己的计算机上得出结果。
我很确定你想知道BERT代表什么,它实际上是Transformers的双向编码器表示,如果你能够领悟到这些,那很不错了。
PyText
Facebook开源了深度学习NLP框架PyText,它在不久之前发布,但我仍然要测试它,但就早期的评论来说非常有希望。根据FB发表的研究,PyText使会话模型的准确性提高了10%,并且缩短了训练时间。
PyText实际上落后于Facebook其他一些产品,如FB Messenger。如果你对此有兴趣。你可以通过GitHub下载代码来自行尝试。
2019年NLP趋势:
塞巴斯蒂安·罗德讲述了NLP在2019年的发展方向,以下是他的想法:
预训练的语言模型嵌入将无处不在,不使用它们的模型将是罕见的。
我们将看到可以编码专门信息的预训练模型,这些信息是对语言模型嵌入的补充。
我们将看到有关多语言应用程序和跨语言模型的成果。特别是,在跨语言嵌入的基础上,我们将看到深度预训练的跨语言表示的出现。
3、计算机视觉

这是现在深度学习中最受欢迎的领域,我觉得我们已经完全获取了计算机视觉中容易实现的目标。无论是图像还是视频,我们都看到了大量的框架和库,这使得计算机视觉任务变得轻而易举。
我们今年在Analytics Vidhya花了很多时间研究这些概念的普通化。你可以在这里查看我们的计算机视觉特定文章,涵盖从视频和图像中的对象检测到预训练模型列表的相关文章,以开始你的深度学习之旅。
以下是我今年在CV中看到的最佳开发项目:
如果你对这个美妙的领域感到好奇,那么请继续使用我们的“使用深度学习的计算机视觉”课程开始你的旅程。
BigGAN的发布
在2014年,Ian Goodfellow设计了GAN,这个概念产生了多种多样的应用程序。年复一年,我们看到原始概念为了适应实际用例正在慢慢调整,直到今年,仍然存在一个共识:机器生成的图像相当容易被发现。
但最近几个月,这个现象已经开始改变。或许随着BigGAN的创建,该现象或许可以彻底消失,以下是用此方法生成的图像:

除非你拿显微镜看,否则你将看不出来上面的图片有任何问题。毫无疑问GAN正在改变我们对数字图像(和视频)的感知方式。
Fast.ai的模型18分钟内在ImageNet上被训练
这是一个非常酷的方向:大家普遍认为需要大量数据以及大量计算资源来执行适当的深度学习任务,包括在ImageNet数据集上从头开始训练模型。我理解这种看法,大多数人都认为在之前也是如此,但我想我们之前都可能理解错了。
Fast.ai的模型在18分钟内达到了93%的准确率,他们使用的硬件48个NVIDIA V100 GPU,他们使用fastai和PyTorch库构建了算法。

所有的这些放在一起的总成本仅为40美元! 杰里米在这里更详细地描述了他们的方法,包括技术。这是属于每个人的胜利!
NVIDIA的vid2vid技术
在过去的4-5年里,图像处理已经实现了跨越式发展,但视频呢?事实证明,将方法从静态框架转换为动态框架比大多数人想象的要困难一些。你能拍摄视频序列并预测下一帧会发生什么吗?答案是不能!
NVIDIA决定在今年之前开源他们的方法,他们的vid2vid方法的目标是从给定的输入视频学习映射函数,以产生输出视频,该视频以令人难以置信的精度预测输入视频的内容。

你可以在这里的GitHub上试用他们的PyTorch实现。
2019年计算机视觉的趋势:
就像我之前提到的那样,在2019年可能看到是改进而不是发明。例如自动驾驶汽车、面部识别算法、虚拟现实算法优化等。就个人而言,我希望看到很多研究在实际场景中实施,像CVPR和ICML这样的会议描绘的这个领域的最新成果,但这些项目在现实中的使用有多接近?
视觉问答和视觉对话系统最终可能很快就会如他们期盼的那样首次亮相。虽然这些系统缺乏概括的能力,但希望我们很快就会看到一种综合的多模式方法。
自监督学习是今年最重要的创新,我可以打赌明年它将会用于更多的研究。这是一个非常酷的学习线:标签可以直接根据我们输入的数据确定,而不是浪费时间手动标记图像。
4、工具和库
工具和库是数据科学家的基础。我参与了大量关于哪种工具最好的辩论,哪个框架会取代另一个,哪个库是经济计算的缩影等等。
但有一点共识--我们需要掌握该领域的最新工具,否则就有被淘汰的风险。 Python取代其他所有事物并将自己打造成行业领导者的步伐就是这样的例子。 当然,其中很多都归结为主观选择,但如果你不考虑最先进的技术,我建议你现在开始,否则后果可能将不可预测。那么成为今年头条新闻的是什么?我们来看看吧!
PyTorch 1.0
什么是PyTorch?我已经多次在本文中提到它了,你可以在Faizan Shaikh的文章中熟悉这个框架。

这是我最喜欢的关于深度学习文章之一!当时TensorFlow很缓慢,这为PyTorch打开了大门快速获得深度学习市场。我在GitHub上看到的大部分代码都是PyTorch实现的。这并非因为PyTorch非常灵活,而是最新版本(v1.0)已经大规模应用到许多Facebook产品和服务,包括每天执行60亿次文本翻译。PyTorch的使用率在2019年上升,所以现在是加入的好时机。
AutoML—自动机器学习
AutoML在过去几年中逐渐取得进展。RapidMiner、KNIME、DataRobot和H2O.ai等公司都发布了非常不错的产品,展示了这项服务的巨大潜力。你能想象在ML项目上工作,只需要使用拖放界面而无需编码吗?这种现象在未来并不太遥远。但除了这些公司之外,ML / DL领域还有一个重要的发布-Auto Keras!

它是一个用于执行AutoML任务的开源库。其背后的目的是让没有ML背景的领域专家进行深度学习。请务必在此处查看,它准备在未来几年内大规模运行。
TensorFlow.js-浏览器中的深度学习
我们一直都喜欢在最喜欢的IDE和编辑器中构建和设计机器学习和深度学习模型。如何迈出一步,尝试不同的东西?我将要介绍如何在你的网络浏览器中进行深度学习!由于TensorFlow.js的发布,已成为现实。

TensorFlow.js主要有三个优点/功能:
1.使用JavaScript开发和创建机器学习模型;
2.在浏览器中运行预先存在的TensorFlow模型;
3.重新创建已有的模型;
2019年的AutoML趋势
我个人特别关注AutoML,为什么?因为我认为未来几年它将成为数据科学领域真正的游戏规则改变者。跟我有同样想法的人是H2O.ai的Marios Michailidis、Kaggle Grandmaster,他们都对AutoML有很高期望:
机器学习继续成为未来最重要的趋势之一,鉴于其增长速度,自动化是最大化其价值的关键,是充分利用数据科学资源的关键。它可以应用到的领域是无限的:信用、保险、欺诈、计算机视觉、声学、传感器、推荐、预测、NLP等等,能够在这个领域工作是一种荣幸。AutoML趋势:
提供智能可视化和解释,以帮助描述和理解数据;
查找/构建/提取给定数据集的更好特征;
快速建立更强大/更智能的预测模型;
通过机器学习可解释性弥补这些模型的黑匣子建模和生产之间的差距;
促进这些模型落地生产;
5、强化学习

如果我不得不选择一个我看到的渗透更多领域的技术,那就是强化学习。除了不定期看到的头条新闻之外,我还在社区中了解到,它太注重数学,并且没有真正的行业应用程序可供专一展示。
虽然这在某种程度上是正确的,但我希望看到的是明年更多来自RL的实际用例。我在每月GitHub和Reddit排序系列中,我倾向于至少保留一个关于RL的存储库或讨论,至少围绕该主题的讨论。
OpenAI已经发布了一个非常有用的工具包,可以让初学者从这个领域开始。
OpenAI在深度强化学习中的应用

如果RL的研究进展缓慢,那么围绕它的教育材料将会很少。但事实上,OpenAI已经开放了一些关于这个主题的精彩材料。他们称这个项目为“Spinning Up in Deep RL”,你可以在这里阅读所有相关内容。它实际上是非常全面RL的资源列表,这里有很多材料包括RL术语、如何成为RL研究者、重要论文列表、一个记录完备的代码存储库、甚至还有一些练习来帮助你入门。
如果你打算开始使用RL,那么现在开始!
Google Dopamine
为了加速研究并让社区更多的参与强化学习,Google AI团队开源了Dopamine,这是一个TensorFlow框架,旨在通过它来使更灵活和可重复性来构建RL模型。
你可以在此GitHub存储库中找到整个训练数据以及TensorFlow代码(仅15个Python notebooks!)。这是在受控且灵活的环境中进行简单实验的完美平台,听起来像数据科学家的梦想。
2019年强化学习趋势
Xander Steenbrugge是DataHack Summit的代表,也是ArxivInsights频道的创始人,他非常擅长强化学习。以下是他对RL当前状态的看法以及2019年的预期:
我目前看到RL领域的三个主要问题:
样本复杂性(代理需要查看/收集以获得的经验数量);
泛化和转移学习(训练任务A,测试相关任务B);
分层RL(自动子目标分解);
我相信前两个问题可以通过与无监督表示学习相关的类似技术来解决。目前在RL中,我们正在使用稀疏奖励信号训练深度神经网络,从原始输入空间(例如像素)映射到端到端方式的动作(例如,使用反向传播)。
我认为能够促进强化学习快速发展的道路是利用无监督的表示学习(自动编码器、VAE、GAN)将凌乱的高维输入空间(例如像素)转换为低维“概念”空间。
人工智能:符合伦理才更重要
想象一下由算法统治的世界,算法决定了人类采取的每一个行动。这不是一个美好的场景,对吗?AI中的伦理规范是Analytics Vidhya一直热衷于讨论的话题。
今年有相当多的组织因为Facebook的剑桥分析公司丑闻和谷歌内部普遍关于设计武器新闻丑闻而遭受危机。没有一个开箱即用的解决方案或一个适合所有解决方案来处理AI的伦理方面。它需要一种细致入微的方法,并结合领导层提出的结构化路径。让我们看看今年出现的重大政策:GDPR。
GDPR如何改变游戏规则
GDPR或通用数据保护法规肯定会对用于构建AI应用程序的数据收集方式产生影响。GDPR的作用是以确保用户可以更好地控制他们的数据。那么这对AI有何影响?我们可以想象一下,如果数据科学家没有数据(或足够数据),那么构建任何模型都会还没开始就失败。
2019年的AI伦理趋势预期
这是一个灰色的领域。就像我提到的那样,没有一个解决方案可以解决这个问题。我们必须聚集在一起,将伦理问题整合到AI项目中。那么我们怎样才能实现这一目标呢?正如Analytics Vidhya的创始人兼首席执行官Kunal Jain在2018年DataHack峰会上的演讲中所强调的那样:我们需要确定一个其他人可以遵循的框架。
结束语
有影响力!这是2018年来描述AI最佳的词汇。今年我成为ULMFiT的狂热用户,我也很期待BERT。
未来智能实验室是人工智能学家与科学院相关机构联合成立的人工智能,互联网和脑科学交叉研究机构。
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)云脑研究计划,构建互联网(城市)云脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”