周志华:“深”为什么重要,以及还有什么深的网络

来源:AI科技评论
本文约11000字,建议阅读20分钟。


一、深度学习就等于深度神经网络吗?


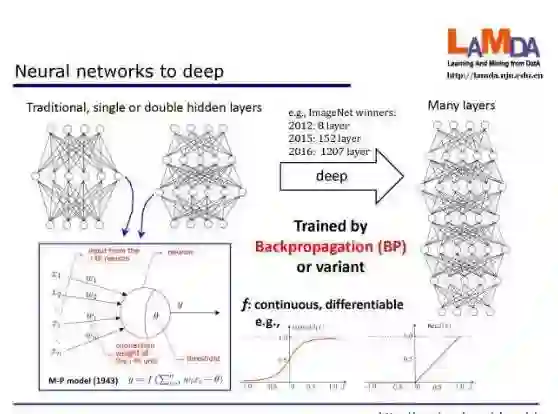
二、为什么深的模型是有效的?


三、深度神经网络有效性的三点猜测
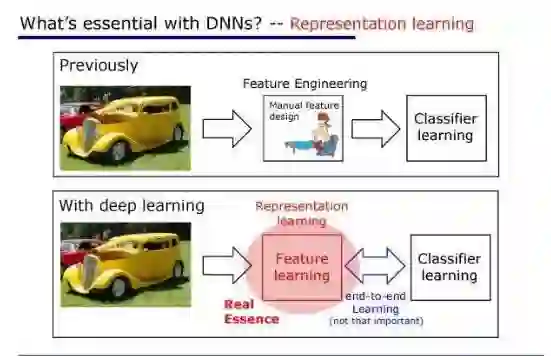
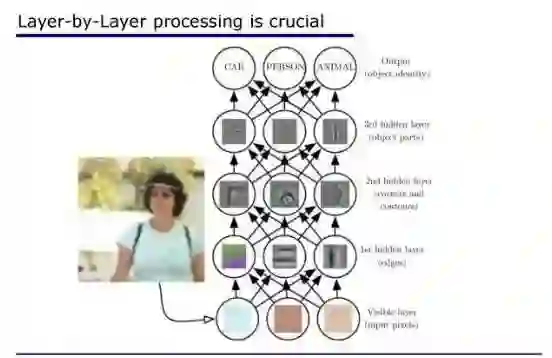

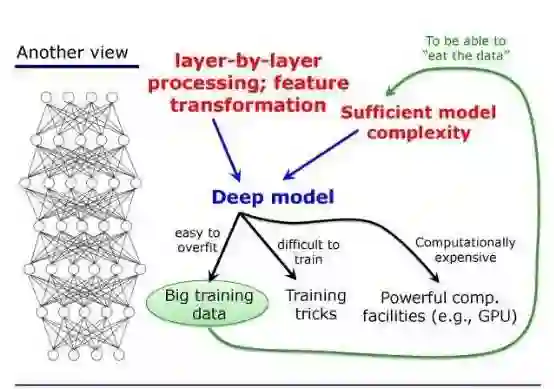
四、深度神经网络不是唯一选择
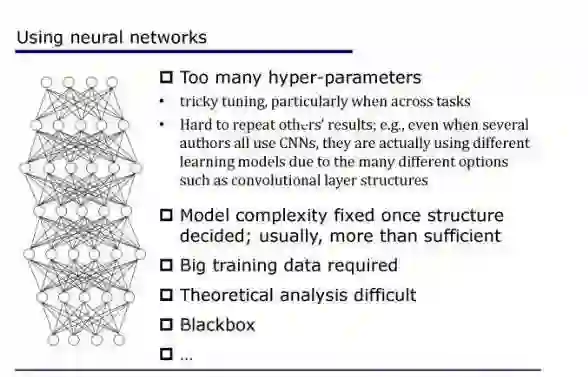
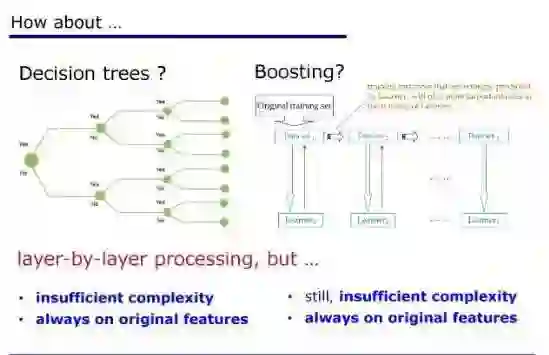
五、需要探索深度学习之外的方法

六、一个成果:gcForest


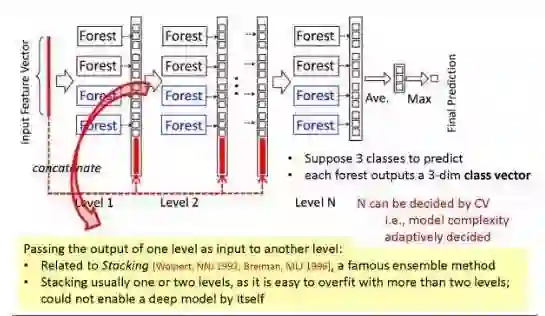
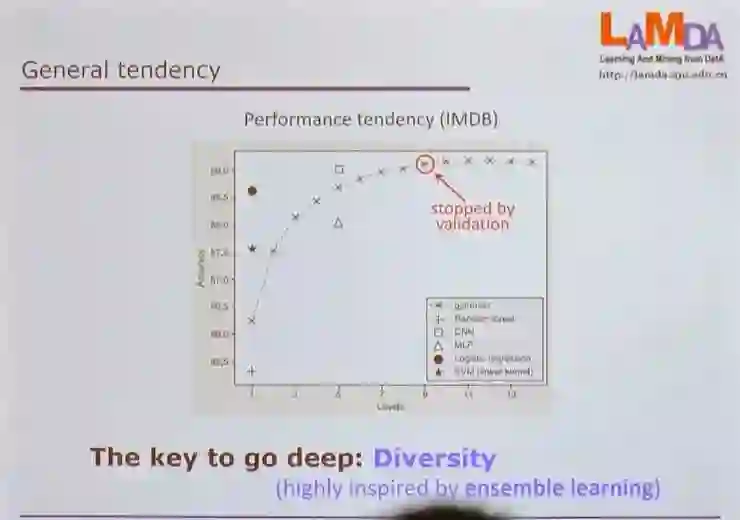
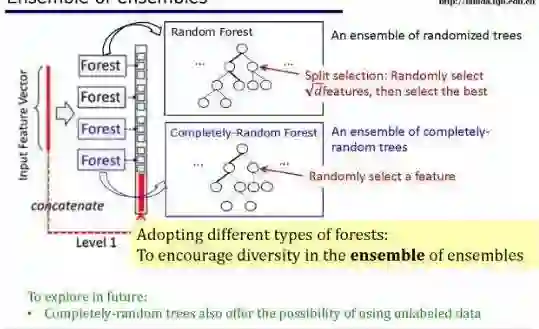
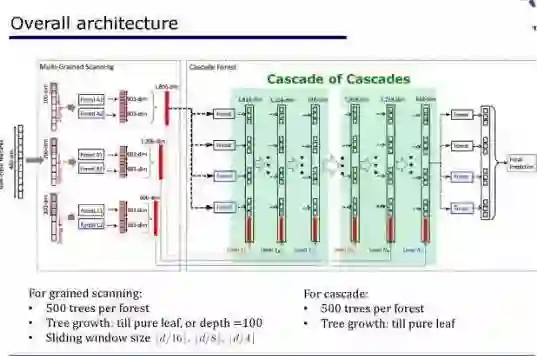

七、gcForest 前途如何

八、gcForest 面临的挑战

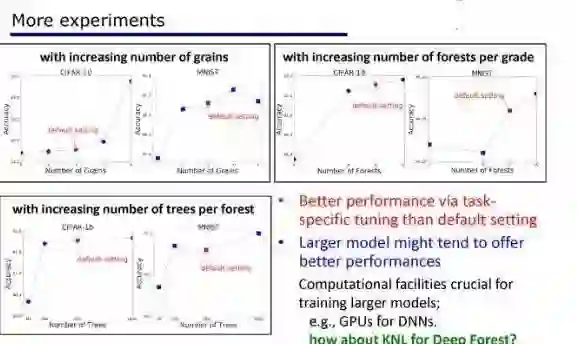

编辑:于腾凯
校对:林亦霖

登录查看更多
相关内容





相关VIP内容
相关资讯
相关论文