【图网络】为什么说图网络是 AI 的未来?
产业智能官:图神经网络为阿里认为是一九年十大核心技术之一,GNN解决了深度学习不可解释的黑洞难题,并提供了因果机理关系解决方案。

新智元专栏
作者:邓侃
编辑:闻菲
【新智元导读】图神经网络(Graph NN)是近来的一大研究热点,尤其是DeepMind提出的“Graph Networks”,号称有望让深度学习实现因果推理。但这篇论文晦涩难懂,复星集团首席AI科学家、大数医达创始人邓侃博士,在清华俞士纶教授团队对GNN综述清晰分类的基础上,解析DeepMind“图网络”的意义。
- 1 -
回顾 2018 年机器学习的进展,2018年6月 DeepMind 团队发表的论文 “Relational inductive biases, deep learning, and graph networks”,是一篇重要的论文,引起业界热议。
随后,很多学者沿着他们的思路,继续研究,其中包括清华大学孙茂松团队。他们于2018年12月,发表了一篇综述,题目是“Graph neural networks: A review of methods and applications”。
2019年1月,俞士纶教授团队,也写了一篇综述,这篇综述的覆盖面更全面,题目是“A Comprehensive Survey on Graph Neural Networks”。

俞士纶教授团队综述GNN,来源:arxiv
DeepMind 团队的这篇论文,引起业界这么热烈的关注,或许有三个原因:
声望:自从 AlphaGo 战胜李世乭以后,DeepMind 享誉业界,成为机器学习业界的领军团队,DeepMind 团队发表的论文,受到同行普遍关注;
开源:DeepMind 团队发表论文 [1] 以后不久,就在 Github 上开源了他们开发的软件系统,项目名称叫 Graph Nets [4];
主题:声望和开源,都很重要,但是并不是被业界热议的最主要的原因。最主要的原因是主题,DeepMind 团队研究的主题是,如何用深度学习方法处理图谱。
- 2 -
图谱 (Graph) 由点 (Node) 和边 (Edge) 组成。
图谱是一个重要的数学模型,可以用来解决很多问题。
譬如我们把城市地铁线路图当成图谱,每个地铁站就是一个点,相邻的地铁站之间的连线就是边,输入起点到终点,我们可以通过图谱的计算,计算出从起点到终点,时间最短、换乘次数最少的行程路线。
又譬如 Google 和百度的搜索引擎,搜索引擎把世界上每个网站的每个网页,都当成图谱中的一个点。每个网页里,经常会有链接,引用其它网站的网页,每个链接都是图谱中的一条边。哪个网页被引用得越多,就说明这个网页越靠谱,于是,在搜索结果的排名也就越靠前。
图谱的操作,仍然有许多问题有待解决。
譬如输入几亿条滴滴司机行进的路线,每条行进路线是按时间排列的一连串(时间、GPS经纬度)数组。如何把几亿条行进路线,叠加在一起,构建城市地图?
不妨把地图也当成一个图谱,每个交叉路口,都是一个点,连接相邻的两个交叉路口,是一条边。
貌似很简单,但是细节很麻烦。
举个例子,交叉路口有很多形式,不仅有十字路口,还有五角场、六道口,还有环形道立交桥——如何从多条路径中,确定交叉路口的中心位置?

日本大阪天保山立交桥,你能确定这座立交桥的中心位置吗?
- 3 -
把深度学习,用来处理图谱,能够扩大我们对图谱的处理能力。
深度学习在图像和文本的处理方面,已经取得了巨大的成功。如何扩大深度学习的成果,使之应用于图谱处理?
图像由横平竖直的像素矩阵组成。如果换一个角度,把每个像素视为图谱中的一个点,每个像素点与它周边的 8 个相邻像素之间都有边,而且每条边都等长。通过这个视角,重新审视图像,图像是广义图谱的一个特例。
处理图像的诸多深度学习手段,都可以改头换面,应用于广义的图谱,譬如 convolution、residual、dropout、pooling、attention、encoder-decoder 等等。这就是深度学习图谱处理的最初想法,很朴实很简单。
虽然最初想法很简单,但是深入到细节,各种挑战层出不穷。每种挑战,都意味着更强大的技术能力,都孕育着更有潜力的应用场景。
深度学习图谱处理这个研究方向,业界没有统一的称谓。
强调图谱的数学属性的团队,把这个研究方向命名为 Geometric Deep Learning。孙茂松团队和俞士纶团队,强调神经网络在图谱处理中的重要性,强调思想来源,他们把这个方向命名为 Graph Neural Networks。DeepMind 团队却反对绑定特定技术手段,他们使用更抽象的名称,Graph Networks。
命名不那么重要,但是用哪种方法去梳理这个领域的诸多进展,却很重要。把各个学派的目标定位和技术方法,梳理清楚,有利于加强同行之间的相互理解,有利于促进同行之间的未来合作。
- 4 -
俞士纶团队把深度学习图谱处理的诸多进展,梳理成 5 个子方向,非常清晰好懂。
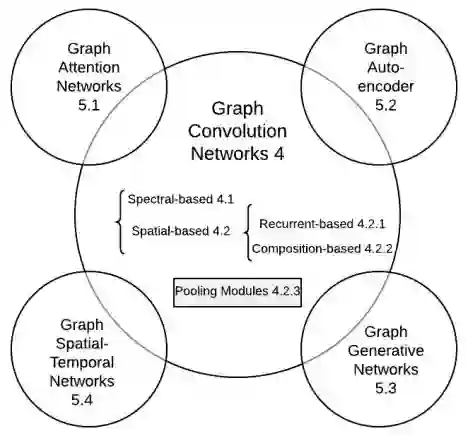
俞士纶团队把深度学习图谱处理梳理成 5 个子方向,来源:论文 A Comprehensive Survey on Graph Neural Networks
Graph Convolution Networks
Graph Attention Networks
Graph Embedding
Graph Generative Networks
Graph Spatial-temporal Networks
先说 Graph Convolution Networks (GCNs)。
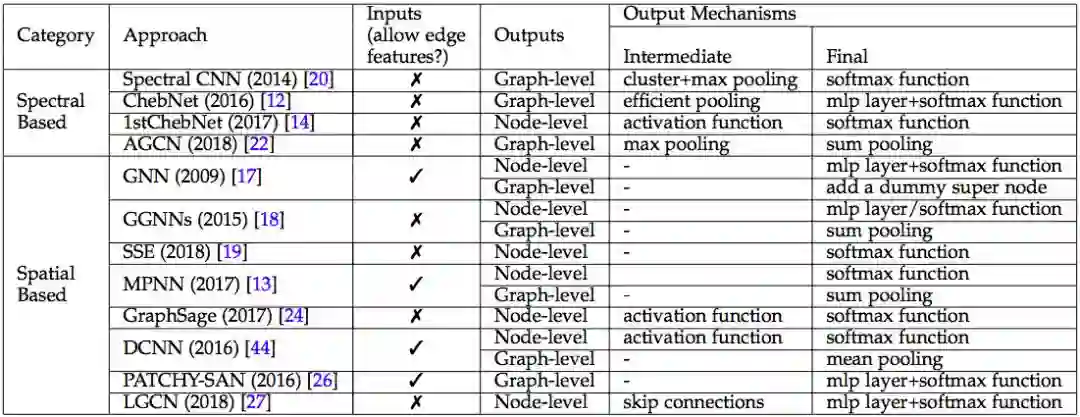
GCN 类别汇总,来源:论文 A Comprehensive Survey on Graph Neural Networks
GCN 把 CNN 诸般武器,应用于广义图谱。CNN 主要分为四个任务,
点与点之间的融合。在图像领域,点与点之间的融合主要通过卷积技术 (convolution) 来实现。在广义图谱里,点与点之间的关系,用边来表达。所以,在广义图谱里,点点融合,有比卷积更强大的办法。Messsage passing [5] 就是一种更强大的办法。
分层抽象。CNN 使用 convolution 的办法,从原始像素矩阵中,逐层提炼出更精炼更抽象的特征。更高层的点,不再是孤立的点,而是融合了相邻区域中其它点的属性。融合邻点的办法,也可以应用于广义图谱中。
特征提炼。CNN 使用 pooling 等手段,从相邻原始像素中,提炼边缘。从相邻边缘中,提炼实体轮廓。从相邻实体中,提炼更高层更抽象的实体。CNN 通常把 convolution 和 pooling 交替使用,构建结构更复杂,功能更强大的神经网络。对于广义图谱,也可以融汇 Messsage passing 和 Pooling,构建多层图谱。
输出层。CNN 通常使用 softmax 等手段,对整张图像进行分类,识别图谱的语义内涵。对于广义图谱来说,输出的结果更多样,不仅可以对于整个图谱,输出分类等等结果。而且也可以预测图谱中某个特定的点的值,也可以预测某条边的值。
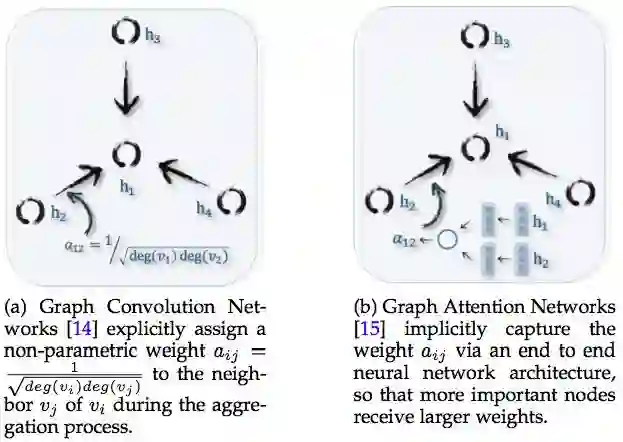
GCN 和Graph Attention Networks 的区别 来源:论文 A Comprehensive Survey on Graph Neural Networks
Graph Attention Networks 要解决的问题,与 GCN 类似,区别在于点点融合、多层抽象的方法。
Graph Convolution Networks 使用卷积方式,实现点点融合和分层抽象。Convolution 卷积方式仅仅适用于融合相邻的点,而 attention 聚焦方式却不限于相邻的点,每个点可以融合整个图谱中所有其它点,不管是否相邻,是否融合如何融合,取决于点与点之间的关联强弱。
Attention 能力更强大,但是对于算力的要求更高,因为需要计算整个图谱中任意两个点之间的关联强弱。所以 Graph Attention Networks 研究的重点,是如何降低计算成本,或者通过并行计算,提高计算效率。
- 5 -
Graph Embedding 要解决的问题,是给图谱中每个点每条边,赋予一个数值张量。图像不存在这个问题,因为像素天生是数值张量。但是,文本由文字词汇语句段落构成,需要把文字词汇,转化成数值张量,才能使用深度学习的诸多算法。
如果把文本中的每个文字或词汇,当成图谱中的一个点,同时把词与词之间的语法语义关系,当成图谱中的一条边,那么语句和段落,就等同于行走在文本图谱中的一条行进路径。
如果能够给每个文字和词汇,都赋予一个贴切的数值张量,那么语句和段落对应的行进路径,多半是最短路径。
有多种实现 Graph Embedding 的办法,其中效果比较好的办法是 Autoencoder。用 GCN 的办法,把图谱的点和边转换成数值张量,这个过程称为编码 (encoding),然后通过计算点与点之间的距离,把数值张量集合,反转为图谱,这个过程称为解码 (decoding)。通过不断地调参,让解码得到的图谱,越来越趋近于原始图谱,这个过程称为训练。
Graph Embedding 给图谱中的每个点每条边,赋予贴切的数值张量,但是它不解决图谱的结构问题。
如果输入大量的图谱行进路径,如何从这些行进路径中,识别哪些点与哪些点之间有连边?难度更大的问题是,如果没有行进路径,输入的训练数据是图谱的局部,以及与之对应的图谱的特性,如何把局部拼接成图谱全貌?这些问题是 Graph Generative Networks 要解决的问题。
Graph Generative Networks 比较有潜力的实现方法,是使用 Generative Adversarial Networks (GAN)。
GAN 由生成器 (generator) 和辨别器 (discriminator) 两部分构成:1. 从训练数据中,譬如海量行进路径,生成器猜测数据背后的图谱应该长什么样;2. 用生成出来的图谱,伪造一批行进路径;3. 从大量伪造的路径和真实的路径中,挑选几条路径,让辨别器识别哪几条路径是伪造的。
如果辨别器傻傻分不清谁是伪造路径,谁是真实路径,说明生成器生成出的图谱,很接近于真实图谱。
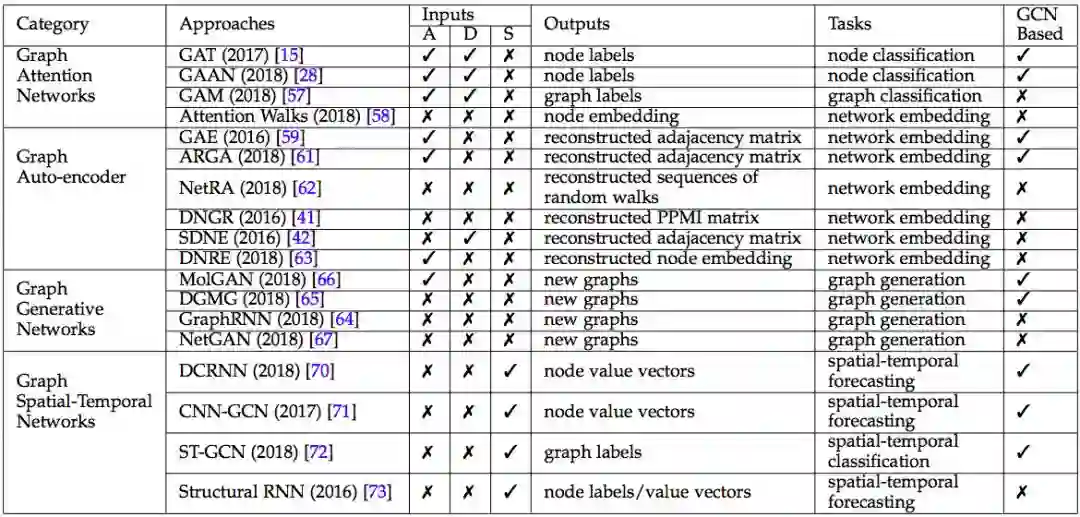
GCN 以外的其他 4 种图谱神经网络,来源:论文 A Comprehensive Survey on Graph Neural Networks
- 6 -
以上我们讨论了针对静态图谱的若干问题,但是图谱有时候是动态的,譬如地图中表现的道路是静态的,但是路况是动态的。
如何预测春节期间,北京天安门附近的交通拥堵情况?解决这个问题,不仅要考虑空间 spatial 的因素,譬如天安门周边的道路结构,也要考虑时间 temporal 的因素,譬如往年春节期间该地区交通拥堵情况。这就是 Graph Spatial-temporal Networks 要解决的问题之一。
Graph Spatial-temporal Networks 还能解决其它问题,譬如输入一段踢球的视频,如何在每一帧图像中,识别足球的位置?这个问题的难点在于,在视频的某些帧中,足球有可能是看不见的,譬如被球员的腿遮挡了。
解决时间序列问题的通常思路,是 RNN,包括 LSTM 和 GRU 等等。
DeepMind 团队在 RNN 基础上,又添加了编码和解码 (encoder-decoder) 机制。
- 7 -
在 DeepMind 团队的这篇论文里[1],他们声称自己的工作,“part position paper, part review, and part unification”,既是提案,又是综述,又是融合。这话怎么理解?

DeepMind联合谷歌大脑、MIT等机构27位作者发表重磅论文,提出“图网络”(Graph network),将端到端学习与归纳推理相结合,有望解决深度学习无法进行关系推理的问题。
前文说到,俞士纶团队把深度学习图谱处理的诸多进展,梳理成 5 个子方向:1) Graph Convolution Networks、2) Graph Attention Networks、3) Graph Embedding、4) Graph Generative Networks、5) Graph Spatial-temporal Networks。
DeepMind 团队在 5 个子方向中着力解决后 4 个方向,分别是 Graph Attention Networks、Graph Embedding、Graph Generative Networks 和 Graph Spatial-temporal Networks。他们把这四个方向的成果,“融合”成统一的框架,命名为 Graph Networks。
在他们的论文中,对这个四个子方向沿途的诸多成果,做了“综述”,但是并没有综述 Graph Convolution Networks 方向的成果。然后他们从这四个子方向的诸多成果中,挑选出了他们认为最有潜力的方法,形成自己的“提案”,这就是他们开源的代码 [4]。
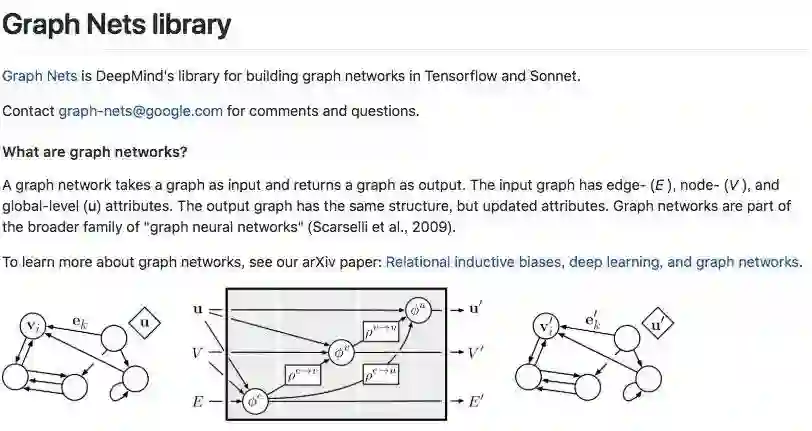
DeepMind在2018年10月开源的Graph Nets library,用于在TensorFlow中构建简单而强大的关系推理网络。来源:github.com/deepmind/graph_nets
虽然论文中,他们声称他们的提案解决了四个子方向的问题,但是查看他们开源的代码,发现其实他们着力解决的是后两个子方向,Graph Attention Networks 和 Graph Spatial-temporal Networks。
DeepMind 的思路是这样的:首先,把 [5] 的 message passing 点点融合的机制,与 [6] 图谱全局的聚焦机制相结合,构建通用的 graph block 模块;其次,把 LSTM 要素融进 encoder-decoder 框架,构建时间序列机制;最后,把 graph block 模块融进 encoder-decoder 框架,形成 Graph Spatial-temporal Networks 通用系统。
- 8 -
为什么 DeepMind 的成果很重要?事关四件大事。
一、深度学习过程的解释
从原理上讲,深度学习譬如 CNN 的成果,来自于对图像的不断抽象。也就是,从原始的像素矩阵中,抽象出线段。从首尾相连的相邻线段中,抽象出实体的轮廓。从轮廓抽象出实体,从实体抽象出语义。
但是,如果窥探 CNN 每一层的中间结果,实际上很难明确,究竟是哪一层的哪些节点,抽象出了轮廓,也不知道哪一层的哪些节点,抽象出了实体。总而言之,CNN 的网络结构是个迷,无法明确地解释网络结构隐藏的工作过程的细节。
无法解释工作过程的细节,也就谈不上人为干预。如果 CNN 出了问题,只好重新训练。但重新训练后的结果,是否能达到期待的效果,无法事先语料。往往按下葫芦浮起瓢,解决了这个缺陷,却引发了其它缺陷。
反过来说,如果能明确地搞清楚 CNN 工作过程的细节,就可以有针对性地调整个别层次的个别节点的参数,事先人为精准干预。
二、小样本学习
深度学习依赖训练数据,训练数据的规模通常很大,少则几万,多大几百万。从哪里收集这么多训练数据,需要组织多少人力去对训练数据进行标注,都是巨大挑战。
如果对深度学习的过程细节,有更清晰的了解,我们就可以改善卷积这种蛮力的做法,用更少的训练数据,训练更轻巧的深度学习模型。
卷积的过程,是蛮力的过程,它对相邻的点,无一遗漏地不分青红皂白地进行卷积处理。
如果我们对点与点之间的关联关系,有更明确的了解,就不需要对相邻的点,无一遗漏地不分青红皂白地进行卷积处理。只需要对有关联的点,进行卷积或者其它处理。
根据点与点之间的关联关系,构建出来的网络,就是广义图谱。广义图谱的结构,通常比 CNN 网络更加简单,所以,需要的训练数据量也更少。
三、迁移学习和推理
用当今的 CNN,可以从大量图片中,识别某种实体,譬如猫。
但是,如果想给识别猫的 CNN 扩大能力,让它不仅能识别猫,还能识别狗,就需要额外的识别狗的训练数据。这是迁移学习的过程。
能不能不提供额外的识别狗的训练数据,而只是用规则这样的方式,告诉电脑猫与狗的区别,然后让电脑识别狗?这是推理的目标。
如果对深度学习过程有更精准的了解,就能把知识和规则,融进深度学习。
从广义范围说,深度学习和知识图谱,是机器学习阵营中诸多学派的两大主流学派。迄今为止,这两大学派隔岸叫阵,各有胜负。如何融合两大学派,取长补短,是困扰学界很久的难题。把深度学习延伸到图谱处理,给两大学派的融合,带来了希望。
四、空间和时间的融合,像素与语义的融合
视频处理,可以说是深度学习的最高境界。
视频处理融合了图像的空间分割,图像中实体的识别,实体对应的语义理解。
多帧静态图像串连在一起形成视频,实际上是时间序列。同一个实体,在不同帧中所处的位置,蕴含着实体的运动。运动的背后,是物理定律和语义关联。
如何从一段视频,总结出文本标题。或者反过来,如何根据一句文本标题,找到最贴切的视频。这是视频处理的经典任务,也是难度超大的任务。
参考文献
Relational inductive biases, deep learning, and graph networks,https://arxiv.org/abs/1806.01261
Graph neural networks: A review ofmethods and applications,https://arxiv.org/abs/1812.08434
A Comprehensive Survey on Graph Neural Networks,https://arxiv.org/abs/1901.00596
Graph nets,https://github.com/deepmind/graph_nets
Neural message passing for quantum chemistry,https://arxiv.org/abs/1704.01212
Non-local neural networks,https://arxiv.org/abs/1711.07971
【CNN已老,GNN来了】DeepMind、谷歌大脑、MIT等27位作者重磅论文,图网络让深度学习也能因果推理
新智元报道
来源:Arxiv; Quanta Magazine等
编辑:闻菲,刘小芹
【新智元导读】DeepMind联合谷歌大脑、MIT等机构27位作者发表重磅论文,提出“图网络”(Graph network),将端到端学习与归纳推理相结合,有望解决深度学习无法进行关系推理的问题。

作为行业的标杆,DeepMind的动向一直是AI业界关注的热点。最近,这家世界最顶级的AI实验室似乎是把他们的重点放在了探索“关系”上面,6月份以来,接连发布了好几篇“带关系”的论文,比如:
关系归纳偏置(Relational inductive bias for physical construction in humans and machines)
关系深度强化学习(Relational Deep Reinforcement Learning)
关系RNN(Relational Recurrent Neural Networks)
论文比较多,但如果说有哪篇论文最值得看,那么一定选这篇——《关系归纳偏置、深度学习和图网络》。
这篇文章联合了DeepMind、谷歌大脑、MIT和爱丁堡大学的27名作者(其中22人来自DeepMind),用37页的篇幅,对关系归纳偏置和图网络(Graph network)进行了全面阐述。
DeepMind的研究科学家、大牛Oriol Vinyals颇为罕见的在Twitter上宣传了这项工作(他自己也是其中一位作者),并表示这份综述“pretty comprehensive”。

有很不少知名的AI学者也对这篇文章做了点评。
曾经在谷歌大脑实习,从事深度强化学习研究的Denny Britz说,他很高兴看到有人将图(Graph)的一阶逻辑和概率推理结合到一起,这个领域或许会迎来复兴。

芯片公司Graphcore的创始人Chris Gray评论说,如果这个方向继续下去并真的取得成果,那么将为AI开创一个比现如今的深度学习更加富有前景的基础。

康纳尔大学数学博士/MIT博士后Seth Stafford则认为,图神经网络(Graph NNs)可能解决图灵奖得主Judea Pearl指出的深度学习无法做因果推理的核心问题。
那么,这篇论文是关于什么的呢?DeepMind的观点和要点在这一段话里说得非常清楚:
这既是一篇意见书,也是一篇综述,还是一种统一。我们认为,如果AI要实现人类一样的能力,必须将组合泛化(combinatorial generalization)作为重中之重,而结构化的表示和计算是实现这一目标的关键。
正如生物学里先天因素和后天因素是共同发挥作用的,我们认为“人工构造”(hand-engineering)和“端到端”学习也不是只能从中选择其一,我们主张结合两者的优点,从它们的互补优势中受益。
在论文里,作者探讨了如何在深度学习结构(比如全连接层、卷积层和递归层)中,使用关系归纳偏置(relational inductive biases),促进对实体、对关系,以及对组成它们的规则进行学习。
他们提出了一个新的AI模块——图网络(graph network),是对以前各种对图进行操作的神经网络方法的推广和扩展。图网络具有强大的关系归纳偏置,为操纵结构化知识和生成结构化行为提供了一个直接的界面。
作者还讨论了图网络如何支持关系推理和组合泛化,为更复杂、可解释和灵活的推理模式打下基础。
2018年初,承接NIPS 2017有关“深度学习炼金术”的辩论,深度学习又迎来了一位重要的批评者。
图灵奖得主、贝叶斯网络之父Judea Pearl,在ArXiv发布了他的论文《机器学习理论障碍与因果革命七大火花》,论述当前机器学习理论局限,并给出来自因果推理的7大启发。Pearl指出,当前的机器学习系统几乎完全以统计学或盲模型的方式运行,不能作为强AI的基础。他认为突破口在于“因果革命”,借鉴结构性的因果推理模型,能对自动化推理做出独特贡献。

在最近的一篇访谈中,Pearl更是直言,当前的深度学习不过只是“曲线拟合”(curve fitting)。“这听起来像是亵渎……但从数学的角度,无论你操纵数据的手段有多高明,从中读出来多少信息,你做的仍旧只是拟合一条曲线罢了。”
如何解决这个问题?DeepMind认为,要从“图网络”入手。
大数医达创始人、CMU博士邓侃为我们解释了DeepMind这篇论文的研究背景。
邓侃博士介绍,机器学习界有三个主要学派,符号主义(Symbolicism)、连接主义(Connectionism)、行为主义(Actionism)。
符号主义的起源,注重研究知识表达和逻辑推理。经过几十年的研究,目前这一学派的主要成果,一个是贝叶斯因果网络,另一个是知识图谱。
贝叶斯因果网络的旗手是 Judea Pearl 教授,2011年的图灵奖获得者。但是据说 2017年 NIPS 学术会议上,老爷子演讲时,听众寥寥。2018年,老爷子出版了一本新书,“The Book of Why”,为因果网络辩护,同时批判深度学习缺乏严谨的逻辑推理过程。而知识图谱主要由搜索引擎公司,包括谷歌、微软、百度推动,目标是把搜索引擎,由关键词匹配,推进到语义匹配。
连接主义的起源是仿生学,用数学模型来模仿神经元。Marvin Minsky 教授因为对神经元研究的推动,获得了1969年图灵奖。把大量神经元拼装在一起,就形成了深度学习模型,深度学习的旗手是 Geoffrey Hinton 教授。深度学习模型最遭人诟病的缺陷,是不可解释。
行为主义把控制论引入机器学习,最著名的成果是强化学习。强化学习的旗手是 Richard Sutton 教授。近年来Google DeepMind 研究员,把传统强化学习,与深度学习融合,实现了 AlphaGo,战胜当今世界所有人类围棋高手。
DeepMind 前天发表的这篇论文,提议把传统的贝叶斯因果网络和知识图谱,与深度强化学习融合,并梳理了与这个主题相关的研究进展。
在这里,有必要对说了这么多的“图网络”做一个比较详细的介绍。当然,你也可以跳过这一节,直接看后面的解读。
在《关系归纳偏置、深度学习和图网络》这篇论文里,作者详细解释了他们的“图网络”。图网络(GN)的框架定义了一类用于图形结构表示的关系推理的函数。GN 框架概括并扩展了各种的图神经网络、MPNN、以及 NLNN 方法,并支持从简单的构建块(building blocks)来构建复杂的结构。
GN 框架的主要计算单元是 GN block,即 “graph-to-graph” 模块,它将 graph 作为输入,对结构执行计算,并返回 graph 作为输出。如下面的 Box 3 所描述的,entity 由 graph 的节点(nodes),边的关系(relations)以及全局属性(global attributes)表示。
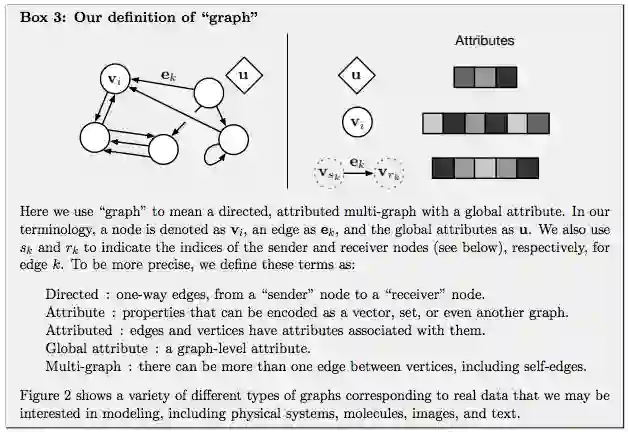
论文作者用 “graph” 表示具有全局属性的有向(directed)、有属性(attributed)的 multi-graph。一个节点(node)表示为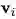
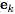
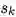
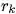
Directed:单向,从 “sender” 节点指向 “receiver” 节点。
Attribute:属性,可以编码为矢量(vector),集合(set),甚至另一个图(graph)
Attributed:边和顶点具有与它们相关的属性
Global attribute:graph-level 的属性
Multi-graph:顶点之间有多个边
GN 框架的 block 的组织强调可定制性,并综合表示所需关系归纳偏置(inductive biases)的新架构。
用一个例子来更具体地解释 GN。考虑在任意引力场中预测一组橡胶球的运动,它们不是相互碰撞,而是有一个或多个弹簧将它们与其他球(或全部球)连接起来。我们将在下文的定义中引用这个运行示例,以说明图形表示和对其进行的计算。
“graph” 的定义
在我们的 GN 框架中,一个 graph 被定义为一个 3 元组的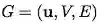
u 表示一个全局属性;例如,u 可能代表重力场。
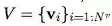
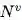
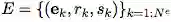
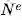
算法 1:一个完整的 GN block 的计算步骤

GN block 的内部结构
一个 GN block 包含三个 “update” 函数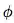
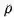
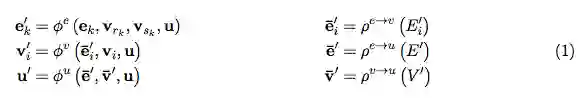
其中:
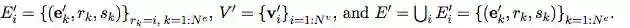
图:GN block 中的 Updates。蓝色表示正在 update 的元素,黑色表示 update 中涉及的其他元素
要把知识图谱和深度学习相结合,邓侃博士认为有几大难点。
1. 点向量:
知识图谱由点和边构成,点(node)用来表征实体(entity),实体又包含属性(attribute)和属性的值(value)。传统知识图谱中的实体,通常由概念符号构成,譬如自然语言的词汇。
传统知识图谱中的边,连接两个单点,也就是两个实体,边表达的是关系,关系的强弱,由权重表达,传统知识图谱的边的权重,通常是常数。
如果想把传统知识图谱与深度学习相融合,首先要做的是实现点的可微分化。用数值化的词向量来替代自然语言的词汇,是实现点的可微分化的有效方法,通常的做法是用语言模型来分析大量的文本,给每个词汇找到最贴合上下文语义的词向量。但在图谱中,传统的词向量的生成算法,不十分奏效,需要改造。
2. 超点:
前文说到,传统知识图谱中的边,连接两个单点,表达两个单点之间的关系。这个假定制约了图谱的表达能力,因为在很多场景下,多个单点组合在一起,才与其它单点或者单点组合,存在关系。我们把单点组合,称之为超点(hyper-node)。
问题是哪些单点组合在一起构成超点?人为的先验指定,当然是一个办法。从大量训练数据中,通过 dropout 或者 regulation 算法,自动学习出超点的构成,也是一个思路。
3. 超边:
传统的知识图谱中的边,表达了点与点之间的关系,关系的强弱由权重表达,通常权重是个常数。但在很多场景下,权重并非是常数。随着点的取值不同,边的权重也发生变化,而且很可能是非线性变化。
用非线性函数来表达图谱的边,称为超边(hyper-edge)。
深度学习模型可以用于模拟非线性函数。所以,知识图谱中每条边都是一个深度学习模型。模型的输入是若干个单点组成的超点,模型的输出是另一个超点。如果把每个深度学习模型,视为一棵树,根是输入,叶子是输出。那么鸟瞰整个知识图谱,实际上是深度学习模型的森林。
4. 路径:
训练知识图谱,包括训练点向量,超点、和超边的时候,一条训练数据往往是在图谱中行走的一条路径,通过拟合海量的路径,获得最贴切的点向量、超点和超边。
用拟合路径来训练图谱,存在的一个问题是,训练过程与过程结束后的评价,两者的脱节。打个比方,给你若干篇文章的提纲,以及相应的范文,让你学习如何写作文。拟合的过程,强调逐字逐句的模仿。但是评价文章的好坏,重点并不在于字句的亦步亦趋,而在于通篇文章的顺畅。
如何解决训练过程与最终评价的脱节?很有潜力的办法,是用强化学习。强化学习的精髓,在于把最终的评价,通过回溯和折现的方法,给路径过程中每一个中间状态,评估它的潜力。
但是强化学习面临的困难,在于中间状态的数量不可太多。当状态数量太多时,强化学习的训练过程,无法收敛。解决收敛问题的办法,是用一个深度学习模型,来估算所有状态的潜力值。换句话说,不需要估算所有状态的潜力值,而只需要训练一个模型的有限参数。
DeepMind 前天发表的这篇文章,提议把深度强化学习与知识图谱等相融合,并梳理了大量的相关研究。但是,论文并没有明确说明 DeepMind 偏向于哪一种具体方案。
或许,针对不同应用场景会有不同方案,并没有通用的最佳方案。
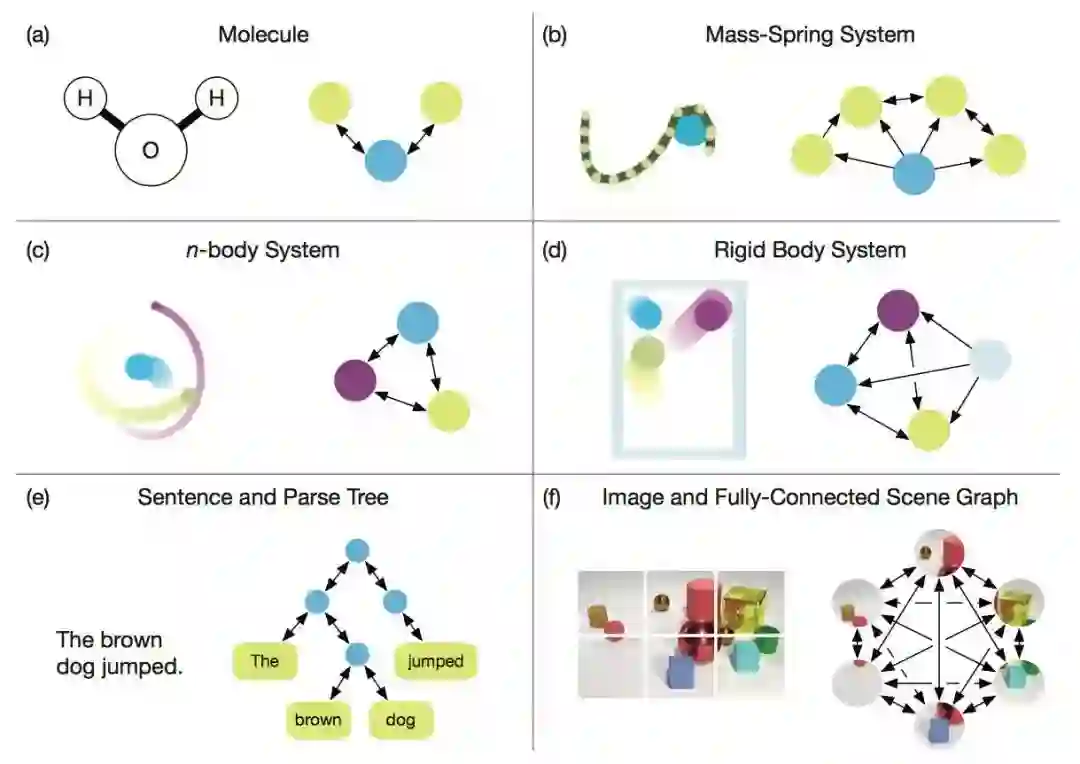
许多重要的现实世界数据集都是以图或网络的形式出现,比如社交网络、知识图谱,万维网等等。 目前,已有越来越多的研究者开始关注神经网络模型对这种结构化数据集的处理。
结合DeepMind、谷歌大脑等发表的一系列的关于图深度学习的论文,是否预示“图深度学习”是下一个AI算法热点?
总之,先从这篇论文看起吧。

地址:https://arxiv.org/pdf/1806.01261.pdf
参考资料
Judea Pearl采访:https://www.quantamagazine.org/to-build-truly-intelligent-machines-teach-them-cause-and-effect-20180515/
图卷积网络:http://tkipf.github.io/graph-convolutional-networks/
关系RNN:https://arxiv.org/pdf/1806.01822v1.pdf
关系深度强化学习:https://arxiv.org/abs/1806.01830
关系归纳偏置https://arxiv.org/pdf/1806.01203.pdf
CNN已老,GNN来了!清华大学孙茂松组一文综述GNN
新智元报道
来源:Arxiv 编辑:文强,肖琴,大明
新智元报道
【新智元导读】深度学习无法进行因果推理,而图模型(GNN)或是解决方案之一。清华大学孙茂松教授组发表综述论文,全面阐述GNN及其方法和应用,并提出一个能表征各种不同GNN模型中传播步骤的统一表示。文中图表,建议高清打印过塑贴放手边作参考。
深度学习的最大软肋是什么?
这个问题的回答仁者见仁,但图灵奖得主Judea Pearl大概有99.9%的几率会说,是无法进行因果推理。
对于这个问题,业界正在进行积极探索,而其中一个很有前景的方向就是图神经网络(Graph Neural Network, GNN)。
最近,清华大学孙茂松教授组在 arXiv 发布了论文 Graph Neural Networks: A Review of Methods and Applications,作者对现有的GNN模型做了详尽且全面的综述。

作者:周界*、崔淦渠*、张正彦*,杨成,刘知远,孙茂松
“图神经网络是连接主义与符号主义的有机结合,不仅使深度学习模型能够应用在图这种非欧几里德结构上,还为深度学习模型赋予了一定的因果推理能力。”论文的共同第一作者周界说。
“在深度学习方法的鲁棒性与可解释性受到质疑的今天,图神经网络可能为今后人工智能的发展提供了一个可行的方向。”
GNN最近在深度学习领域受到了广泛关注。然而,对于想要快速了解这一领域的研究人员来说,可能会面临着模型复杂、应用门类众多的问题。
“本文希望为读者提供一个更高层次的视角,快速了解GNN领域不同模型的动机与优势。”周界告诉新智元:“同时,通过对不同的应用进行分类,方便不同领域的研究者快速了解将GNN应用到不同领域的文献。”
毫不夸张地说,论文中的图表对于想要了解学习GNN乃至因果推理等方向的研究者来说,简直应该高清打印过塑然后贴在墙上以作参考——
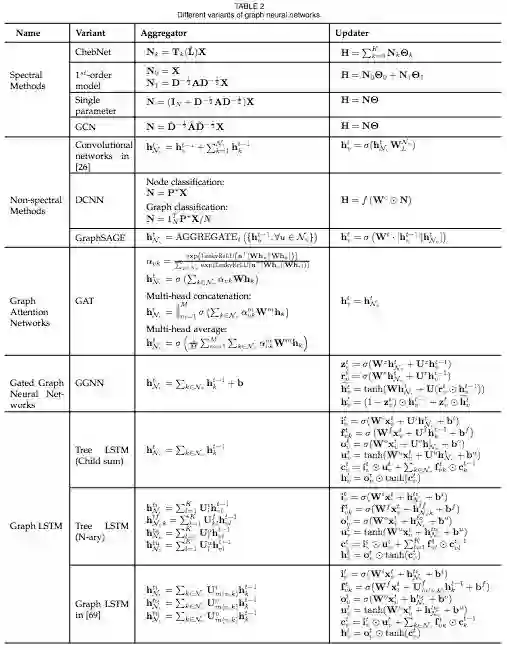
GNN的各种变体,通过比对各自的 aggregator & updater,就能轻松分辨不同的GNN模型。这只是这篇综述强大图表的一个示例。
在内容上,模型方面,本文从GNN原始模型的构建方式与存在的问题出发,介绍了对其进行不同改进的GNN变体,包括如何处理不同的图的类型、如何进行高效的信息传递以及如何加速训练过程。最后介绍了几个近年来提出的通用框架,它们总结概括了多个现有的方法,具有较强的表达能力。
在应用上,文章将GNN的应用领域分为了结构化场景、非结构化场景以及其他场景并介绍了诸如物理、化学、图像、文本、图生成模型、组合优化问题等经典的GNN应用。
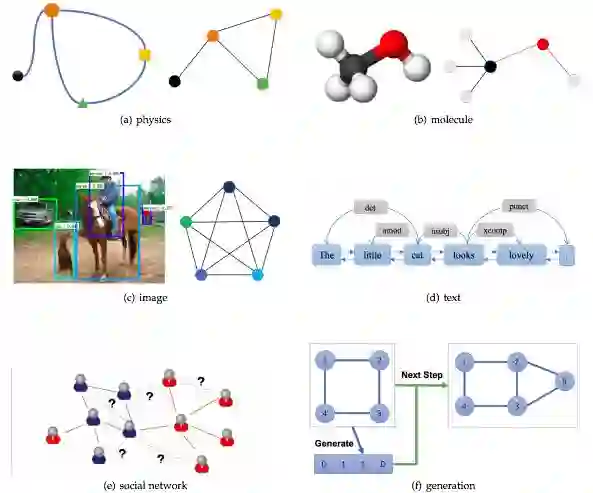
典型应用场景介绍
文章最后提出了四个开放性问题,包括如何处理堆叠多层GNN造成的平滑问题,如何处理动态变化的图结构,如何使用通用的方法处理非结构化的数据以及如何将其扩展到更大规模的网络上。
作者还整理了一个GNN论文列表:
https://github.com/thunlp/GNNPapers
以下是新智元对这篇综述的部分摘译,点击阅读原文查看 arXiv 论文。
GNN的概念首先是在F. Scarselli等人的论文The graph neural network model(F. Scarselli et. al. 2009)中提出的。在这里,我们描述了原始的GNN,并列举了原始GNN在表示能力和训练效率方面的局限性。
接着,我们介绍了几种不同的GNN变体,这些变体具有不同的图形类型,利用不同的传播函数和训练方法。
最后,我们介绍了三个通用框架,分别是message passing neural network (MPNN),non-local neural network (NLNN),以及graph network(GN)。MPNN结合了各种图神经网络和图卷积网络方法;NLNN结合了几种“self-attention”类型的方法;而图网络GN可以概括本文提到的几乎所有图神经网络变体。
图神经网络
如前所述,图神经网络(GNN)的概念最早是Scarselli等人在2009年提出的,它扩展了现有的神经网络,用于处理图(graph)中表示的数据。在图中,每个节点是由其特性和相关节点定义的。
虽然实验结果表明,GNN是建模结构化数据的强大架构,但原始GNN仍存在一些局限性。
首先,对于固定节点,原始GNN迭代更新节点的隐藏状态是低效的。如果放宽了固定点的假设,我们可以设计一个多层的GNN来得到节点及其邻域的稳定表示。
其次,GNN在迭代中使用相同的参数,而大多数流行的神经网络在不同的层中使用不同的参数,这是一种分层特征提取方法。此外,节点隐藏状态的更新是一个顺序过程,可以从RNN内核(如GRU 和 LSTM)中获益。
第三,在边上也有一些无法在原始GNN中建模的信息特征。此外,如何学习边的隐藏状态也是一个重要的问题。
最后,如果我们把焦点放在节点的表示上而不是图形上,就不适合使用固定点,因为在固定点上的表示的分布在数值上是平滑的,区分每个节点的信息量也比较少。
在这一节,我们提出图神经网络的几种变体。首先是在不同图类型上运行的变体,这些变体扩展了原始模型的表示能力。其次,我们列出了在传播步骤进行修改(卷积、门机制、注意力机制和skip connection)的几种变体,这些模型可以更好地学习表示。最后,我们描述了使用高级训练方法的标题,这些方法提高了训练效率。
图2概述了GNN的不同变体。
一览GNN的不同变体
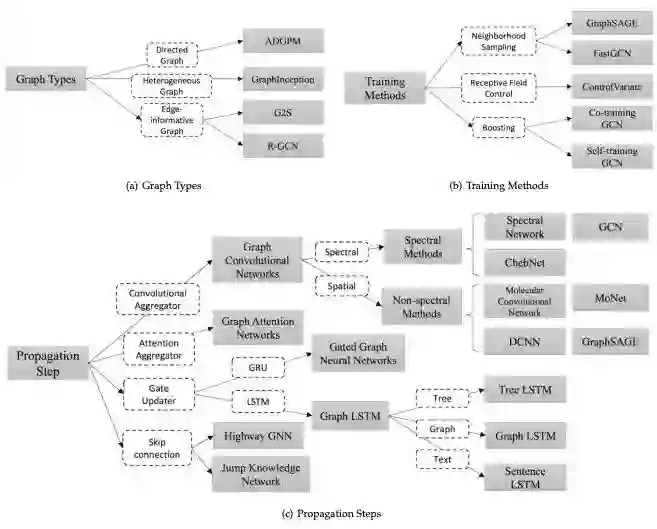
图的类型(Graph Types)
在原始GNN中,输入的图由带有标签信息的节点和无向的边组成,这是最简单的图形格式。然而,世界上有许多不同的图形。这里,我们将介绍一些用于建模不同类型图形的方法。
图类型的变体
有向图(Directed Graphs )
图形的第一个变体是有向图。无向边可以看作是两个有向边,表明两个节点之间存在着关系。然而,有向边比无向边能带来更多的信息。例如,在一个知识图中,边从head实体开始到tail实体结束,head实体是tail实体的父类,这表明我们应该区别对待父类和子类的信息传播过程。有向图的实例有ADGPM (M. Kampffmeyer et. al. 2018)。
异构图(Heterogeneous Graphs)
图的第二个变体是异构图,异构图有几种类型的节点。处理异构图最简单的方法是将每个节点的类型转换为与原始特征连接的一个one-hot特征向量。异构图如GraphInception。
带边信息的图(Edge-informative Graph)
图的另外一个变体是,每条边都有信息,比如权值或边的类型。例如G2S和R-GCN。
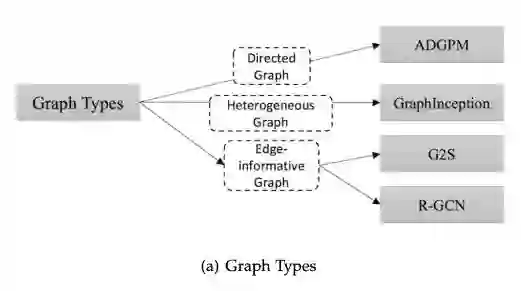
使用不同训练方法的图变体
训练方法变体
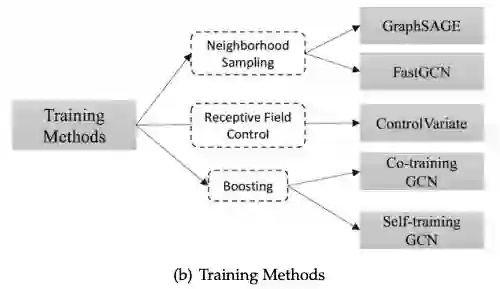
在传播步骤进行修改的GNN变体
传播步骤变体
除了图神经网络的不同变体之外,我们还介绍了几个通用框架,旨在将不同的模型集成到一个框架中。
J. Gilmer等人(J. Gilmer et. al. 2017)提出了消息传递神经网络(message passing neural network, MPNN),统一了各种图神经网络和图卷积网络方法。
X. Wang等人(X. Wang et. al. 2017)提出了非局部神经网络(non-local neural network, NLNN),它结合了几种“self-attention”风格的方法。
P. W. Battaglia等人(P. W. Battaglia et. al. 2018)提出了图网络(graph network, GN),它统一了统一了MPNN和NLNN方法以及许多其他变体,如交互网络(Interaction Networks),神经物理引擎(Neural Physics Engine),CommNet,structure2vec,GGNN,关系网络(Relation Network),Deep Sets和Point Net。
尽管GNN在不同领域取得了巨大成功,但值得注意的是,GNN模型还不能在任何条件下,为任何图任务提供令人满意的解决方案。这里,我们将陈述一些开放性问题以供进一步研究。
浅层结构
传统的深度神经网络可以堆叠数百层,以获得更好的性能,因为更深的结构具备更多的参数,可以显著提高网络的表达能力。然而,GNN总是很浅,大多数不超过三层。
实验显示,堆叠多个GCN层将导致过度平滑,也就是说,所有顶点将收敛到相同的值。尽管一些研究人员设法解决了这个问题,但这仍然是GNN的最大局限所在。设计真正的深度GNN对于未来的研究来说是一个令人兴奋的挑战,并将对进一步深入理解GNN做出相当大的贡献。
动态图形另一个具有挑战性的问题是如何处理具有动态结构的图形。静态图总是稳定的,因此对其进行建模是可行的,而动态图引入了变化的结构。当边和节点出现或消失时,GNN不能自适应地做出改变。目前对动态GNN的研究也在积极进行中,我们认为它是一般GNN的具备稳定性和自适应性的重要里程碑。
非结构性场景
我们讨论了GNN在非结构场景中的应用,但我们没有找到从原始数据中生成图的最佳方法。在图像域中,一些研究可以利用CNN获取特征图,然后对其进行上采样,形成超像素作为节点,还有的直接利用一些对象检测算法来获取对象节点。在文本域中,有些研究使用句法树作为句法图,还有的研究采用全连接图。因此,关键是找到图生成的最佳方法,使GNN在更广泛的领域发挥更大的作用。
可扩展性问题
如何将嵌入式算法应用于社交网络或推荐系统这类大规模网络环境,是几乎所有图形嵌入算法面对的一个致命问题,GNN也不例外。对GNN进行扩展是很困难的,因为涉及其中的许多核心流程在大数据环境中都要消耗算力。
这种困难体现在几个方面:首先,图数据并不规则,每个节点都有自己的邻域结构,因此不能批量化处理。其次,当存在的节点和边数量达到数百万时,计算图的拉普拉斯算子也是不可行的。此外,我们需要指出,可扩展性的高低,决定了算法是否能够应用于实际场景。目前已经有一些研究提出了解决这个问题的办法,我们正在密切关注这些新进展。
在过去几年中,GNN已经成为图领域机器学习任务的强大而实用的工具。这一进展有赖于表现力,模型灵活性和训练算法的进步。在本文中,我们对图神经网络进行了全面综述。对于GNN模型,我们引入了按图类型、传播类型和训练类型分类的GNN变体。
此外,我们还总结了几个统一表示不同GNN变体的通用框架。在应用程序分类方面,我们将GNN应用程序分为结构场景、非结构场景和其他18个场景,然后对每个场景中的应用程序进行详细介绍。最后,我们提出了四个开放性问题,指出了图神经网络的主要挑战和未来的研究方向,包括模型深度、可扩展性、动态图处理和对非结构场景的处理能力。
掌握图神经网络GNN基本,看这篇文章就够了

新智元报道
来源:towardsdatascience
作者:黃功詳 Steeve Huang 编辑:肖琴
【新智元导读】图神经网络(GNN)在各个领域越来越受欢迎,本文介绍了图神经网络的基本知识,以及两种更高级的算法:DeepWalk和GraphSage。
最近,图神经网络 (GNN) 在各个领域越来越受到欢迎,包括社交网络、知识图谱、推荐系统,甚至生命科学。
GNN 在对图形中节点间的依赖关系进行建模方面能力强大,使得图分析相关的研究领域取得了突破性进展。本文旨在介绍图神经网络的基本知识,以及两种更高级的算法:DeepWalk 和 GraphSage。
在讨论 GNN 之前,让我们先了解一下什么是图 (Graph)。在计算机科学中,图是由两个部件组成的一种数据结构:顶点 (vertices) 和边 (edges)。一个图 G 可以用它包含的顶点 V 和边 E 的集合来描述。
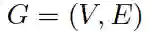
边可以是有向的或无向的,这取决于顶点之间是否存在方向依赖关系。
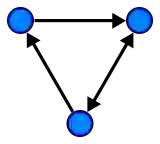
一个有向的图 (wiki)
顶点通常也被称为节点 (nodes)。在本文中,这两个术语是可以互换的。
图神经网络是一种直接在图结构上运行的神经网络。GNN 的一个典型应用是节点分类。本质上,图中的每个节点都与一个标签相关联,我们的目的是预测没有 ground-truth 的节点的标签。
本节将描述 The graph neural network model (Scarselli, F., et al., 2009) [1] 这篇论文中的算法,这是第一次提出 GNN 的论文,因此通常被认为是原始 GNN。
在节点分类问题设置中,每个节点 v 的特征 x_v 与一个 ground-truth 标签 t_v 相关联。给定一个部分标记的 graph G,目标是利用这些标记的节点来预测未标记的节点的标签。它学习用包含邻域信息的 d 维向量 h_v 表示每个节点。即:
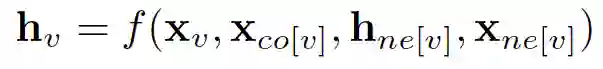
其中 x_co[v] 表示与 v 相连的边的特征,h_ne[v] 表示 v 相邻节点的嵌入,x_ne[v] 表示v 相邻节点的特征。函数 f 是将这些输入映射到 d 维空间上的过渡函数。由于我们要寻找 h_v 的唯一解,我们可以应用 Banach 不动点定理,将上面的方程重写为一个迭代更新过程。

H 和 X 分别表示所有 h 和 x 的串联。
通过将状态 h_v 和特性 x_v 传递给输出函数 g,从而计算 GNN 的输出。
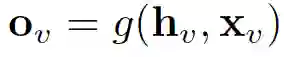
这里的 f 和 g 都可以解释为前馈全连接神经网络。L1 loss 可以直接表述为:
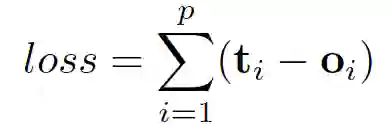
可以通过梯度下降进行优化。
然而,原始 GNN 存在三个主要局限性:
如果放宽 “不动点” (fixed point)的假设,那么可以利用多层感知器学习更稳定的表示,并删除迭代更新过程。这是因为,在原始论文中,不同的迭代使用转换函数 f 的相同参数,而 MLP 的不同层中的不同参数允许分层特征提取。
它不能处理边缘信息 (例如,知识图中的不同边缘可能表示节点之间的不同关系)
不动点会阻碍节点分布的多样性,不适合学习表示节点。
为了解决上述问题,研究人员已经提出了几个 GNN 的变体。不过,它们不是本文的重点。
DeepWalk [2] 是第一个提出以无监督的方式学习节点嵌入的算法。
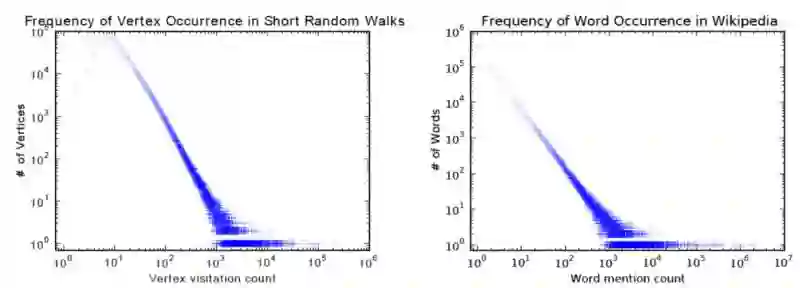
它在训练过程中非常类似于词汇嵌入。其动机是 graph 中节点和语料库中单词的分布都遵循幂律,如下图所示:
该算法包含两个步骤:
在 graph 中的节点上执行 random walks,以生成节点序列
运行 skip-gram,根据步骤 1 中生成的节点序列,学习每个节点的嵌入
在 random walks 的每个时间步骤中,下一个节点从上一个节点的邻节点均匀采样。然后将每个序列截断为长度为 2|w| + 1 的子序列,其中 w 表示 skip-gram 中的窗口大小。
本文采用 hierarchical softmax 来解决由于节点数量庞大而导致的 softmax 计算成本高昂的问题。为了计算每个单独输出元素的 softmax 值 , 我们必须计算元素 k 的所有 e ^ xk。
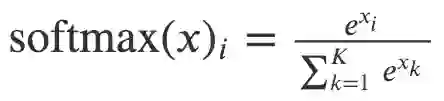
Softmax 的定义
因此,原始 softmax 的计算时间为 O(|V|),其中 V 表示图中顶点的集合。
分层 softmax 利用二叉树来处理这个问题。在这个二叉树中,所有的叶子 (下图中的 v1, v2,…v8) 都表示 graph 中的顶点。在每个内部节点中,都有一个二元分类器来决定选择哪条路径。要计算给定顶点 v_k 的概率,只需计算从根节点到叶节点 v_k 路径上每一个子路径的概率。由于每个节点的子节点的概率之和为 1,所以所有顶点的概率之和为 1的特性在分层 softmax 中仍然保持不变。由于二叉树的最长路径是 O(log(n)),其中 n表示叶节点的数量,因此一个元素的计算时间现在减少到 O(log|V|)。

Hierarchical Softmax
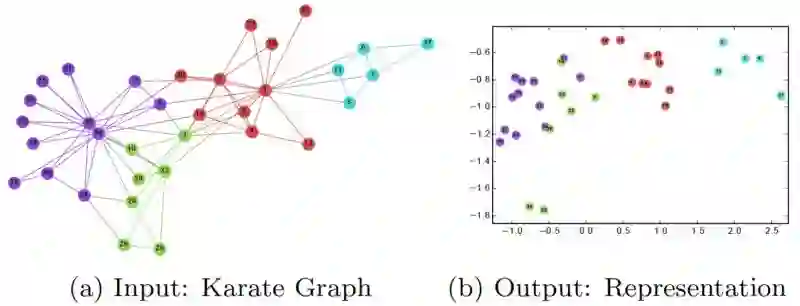
在训练完 DeepWalk GNN 之后,模型已经学习了每个节点的良好表示,如下图所示。不同的颜色表示输入图中的不同标签。我们可以看到,在输出图 (2 维嵌入) 中,具有相同标签的节点被聚集在一起,而具有不同标签的大多数节点都被正确地分开了。
然而,DeepWalk 的主要问题是缺乏泛化能力。每当一个新节点出现时,它必须重新训练模型以表示这个节点。因此,这种 GNN 不适用于图中节点不断变化的动态图。
GraphSage 提供了解决上述问题的办法,以一种归纳的方式学习每个节点的嵌入。
具体地说,GraphSage 每个节点由其邻域的聚合 (aggregation) 表示。因此,即使图中出现了在训练过程中没有看到的新节点,它仍然可以用它的邻近节点来恰当地表示。
下面是 GraphSage算法:

外层循环表示更新迭代的数量,而 h ^ k_v 表示更新迭代 k 时节点 v 的潜在向量。在每次更新迭代时,h ^ k_v 的更新基于一个聚合函数、前一次迭代中 v 和 v 的邻域的潜在向量,以及权重矩阵 W ^ k。
论文中提出了三种聚合函数:
1. Mean aggregator:
mean aggregator 取一个节点及其所有邻域的潜在向量的平均值。
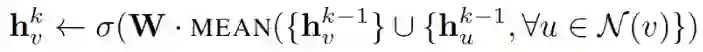
与原始方程相比,它删除了上面伪代码中第 5 行中的连接运算。这种运算可以看作是一种 “skip-connection”,在论文后面的部分中,证明了这在很大程度上可以提高模型的性能。
2. LSTM aggregator:
由于图中的节点没有任何顺序,因此它们通过对这些节点进行排列来随机分配顺序。
3. Pooling aggregator:
这个运算符在相邻集上执行一个 element-wise 的 pooling 函数。下面是一个 max-pooling 的示例:
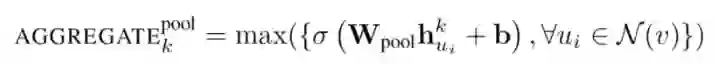
论文使用 max-pooling 作为默认的聚合函数。
损失函数定义如下:
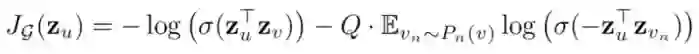
其中 u 和 v 在固定长度的 random walk 中共存,而 v_n 是不与 u 共存的负样本。这种损失函数鼓励距离较近的节点具有相似的嵌入,而距离较远的节点则在投影空间中被分离。通过这种方法,节点将获得越来越多的关于其邻域的信息。
GraphSage 通过聚合其附近的节点,可以为看不见的节点生成可表示的嵌入。它允许将节点嵌入应用到涉及动态图的域,其中图的结构是不断变化的。例如,Pinterest 采用了GraphSage 的扩展版本 PinSage 作为其内容发现系统的核心。
本文中,我们学习了图神经网络、DeepWalk 和 GraphSage 的基础知识。GNN 在复杂图结构建模方面的强大功能确实令人惊叹。鉴于其有效性,我相信在不久的将来,GNN将在 AI 的发展中发挥重要作用。
[1] Scarselli, Franco, et al. "The graph neural network model.”
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.1015.7227&rep=rep1&type=pdf
[2] Perozzi, Bryan, Rami Al-Rfou, and Steven Skiena. "Deepwalk: Online learning of social representations.”
http://www.perozzi.net/publications/14_kdd_deepwalk.pdf
[3] Hamilton, Will, Zhitao Ying, and Jure Leskovec. "Inductive representation learning on large graphs.”
https://www-cs-faculty.stanford.edu/people/jure/pubs/graphsage-nips17.pdf


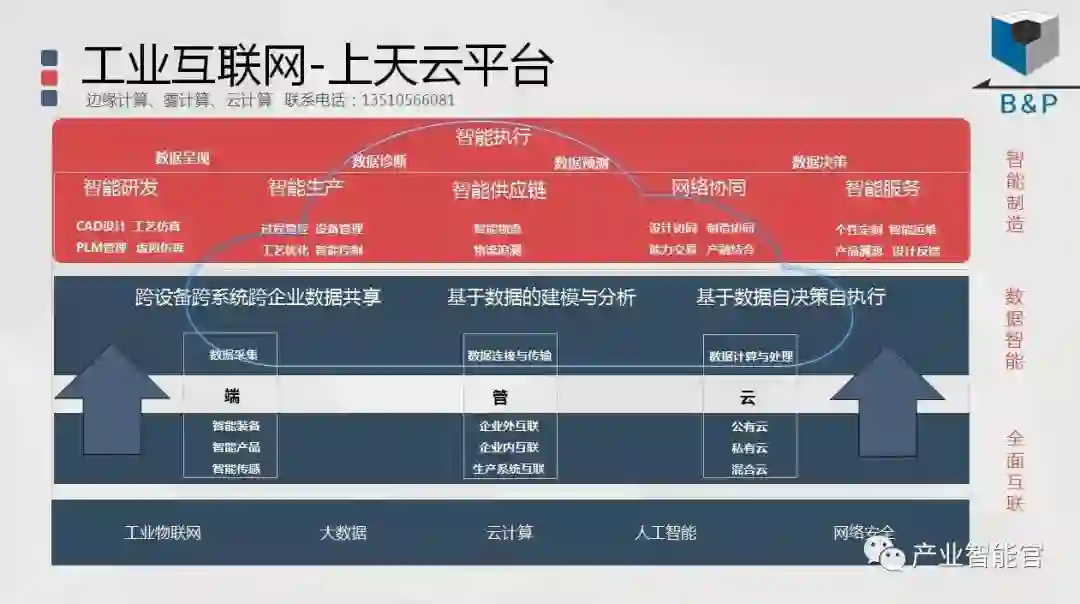
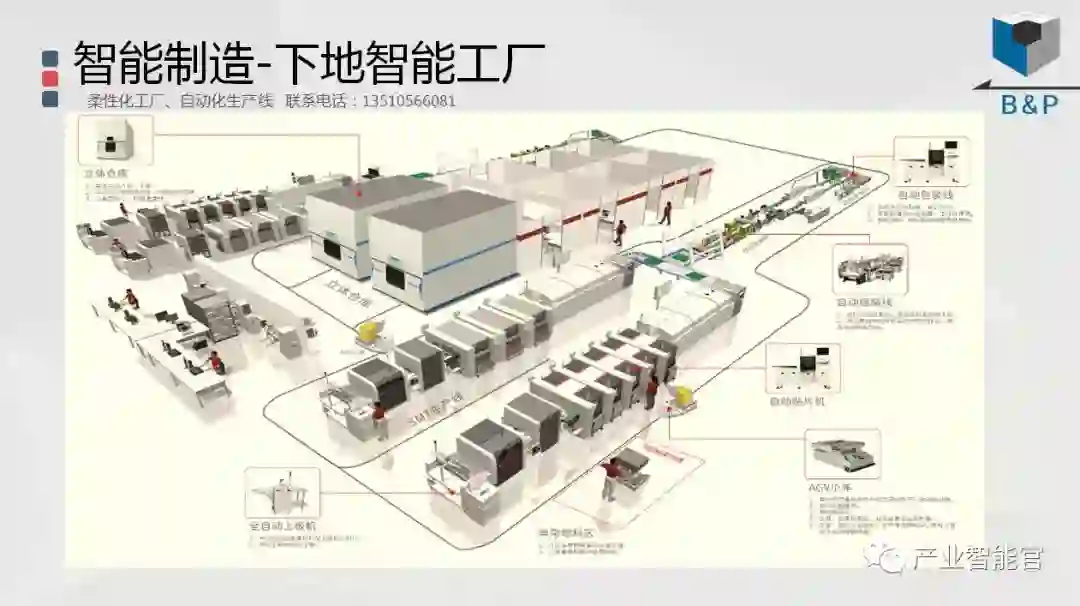
工业互联网
产业智能官 AI-CPS
加入知识星球“产业智能研究院”:先进产业OT(工艺+自动化+机器人+新能源+精益)技术和新一代信息IT技术(云计算+大数据+物联网+区块链+人工智能)深度融合,在场景中构建状态感知-实时分析-自主决策-精准执行-学习提升的机器智能认知计算系统;实现产业转型升级、DT驱动业务、价值创新创造的产业互联生态链。
版权声明:产业智能官(ID:AI-CPS)推荐的文章,除非确实无法确认,我们都会注明作者和来源,涉权烦请联系协商解决,联系、投稿邮箱:erp_vip@hotmail.com。



